
文章目录
Flink的重点架构原理
一、Flink的定义
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。
二、Flink架构体系
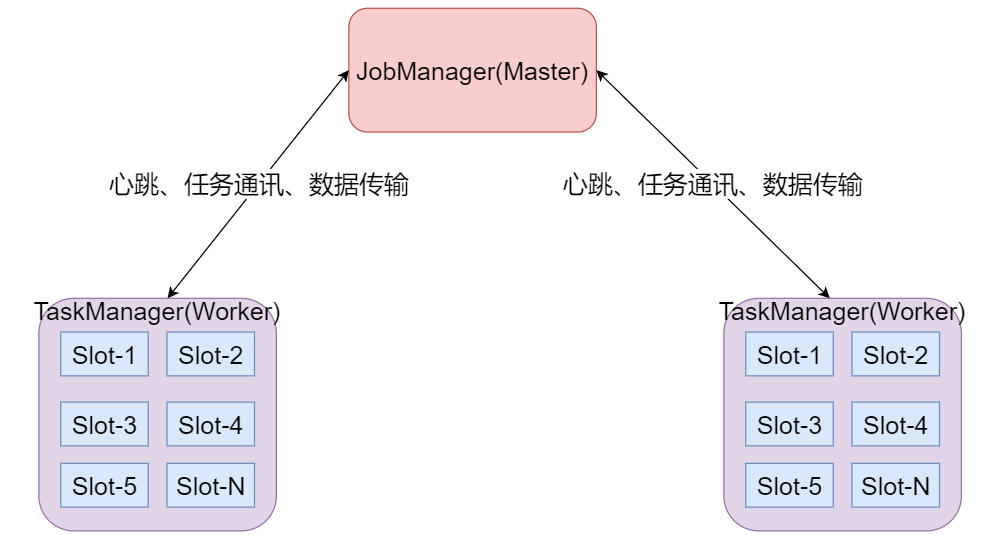
JobManager处理器:
也称之为Master,用于协调分布式执行,它们用来调度task,协调检查点,协调失败时恢复等。Flink运行时至少存在一个master处理器,如果配置高可用模式则会存在多个master处理器,它们其中有一个是leader,而其他的都是standby。
TaskManager处理器:
也称之为Worker,用于执行一个dataflow的task(或者特殊的subtask)、数据缓冲和data stream的交换,Flink运行时至少会存在一个worker处理器。
Slot 任务执行槽位:
-
物理概念,一个TM(TaskManager)内会划分出多个Slot,1个Slot内最多可以运行1个Task(Subtask)或一组由Task(Subtask)组成的任务链。
-
多个Slot之间会共享平分当前TM的内存空间
-
Slot是对一个TM的资源进行固定分配的工具,每个Slot在TM启动后,可以获得固定的资源
-
比如1个TM是一个JVM进程,如果有6个Slot,那么这6个Slot平分这一个JVM进程的资源
-
但是因为在同一个进程内,所以线程之间共享TCP连接、内存数据等,效率更高(Slot之间交流方便)
Task:
任务,每一个Flink的Job会根据情况(并行度、算子类型)将一个整体的Job划分为多个Task
Subtask:
-
子任务,一个Task可以由一个或者多个Subtask组成,一个Task有多少个Subtask取决于这个Task的并行度
-
也就是,每一个Subtask就是当前Task任务并行的一个线程
-
如,当前Task并行度为8,那么这个Task会有8个Subtask(8个线程并行执行这个Task)
并行度:
-
并行度就是一个Task可以分成多少个Subtask并行执行的一个参数
-
这个参数是动态的,可以在任务执行前进行分配,而非Slot分配,TM启动就固定了
-
一个Task可以获得的最大并行度取决于整个Flink环境的可用Slot数量,也就是如果有8个Slot,那么最大并行度也就是8,设置的再大也没有意义
三、Flink核心特性
-
批流一体化
-
同时支持高吞吐、低延迟、高性能
-
支持事件时间(Event Time)概念
-
支持有状态计算
-
支持高度灵活的窗口(Window)操作
-
基于轻量级分布式快照(Snapshot)实现的容错
-
基于JVM实现独立的内存管理
-
Save Points (保存点)
-
多层级API
四、Flink应用场景
-
实时智能推荐
-
复杂事件处理
-
实时欺诈检测
-
实时数仓与ETL
-
流数据分析
-
实时报表分析
五、Flink任务提交过程
-
启动Flink集群首先会启动JobManager,Standalone集群模式下同时启动TaskManager,该模式资源也就固定;其他集群部署模式会根据提交任务来动态启动TaskManager;
-
当在客户端提交任务后,客户端会将任务转换成JobGraph提交给JobManager;
-
JobManager首先启动Dispatcher用于分发作业,运行Flink WebUI提供作业执行信息;
-
Dispatcher启动后会启动JobMaster并将JobGraph提交给JobMaster,JobMaster会将JobGraph转换成可执行的ExecutionGraph。
-
JobMaster向对应的资源管理器ResourceManager为当前任务申请Slot资源;
-
在Standalone资源管理器中会直接找到启动的TaskManager来申请Slot资源,如果资源不足,那么任务执行失败;
-
其他资源管理器会启动新的TaskManager,新启动的TaskManager会向ResourceManager进行注册资源,然后ResourceManager再向TaskManager申请Slot资源,如果资源不足会启动新的TaskManager来满足资源;
-
TaskManager为对应的JobMaster offer Slot资源;
-
JobMaster将要执行的task发送到对应的TaskManager上执行,TaskManager之间可以进行数据交换。
六、Flink任务提交模式
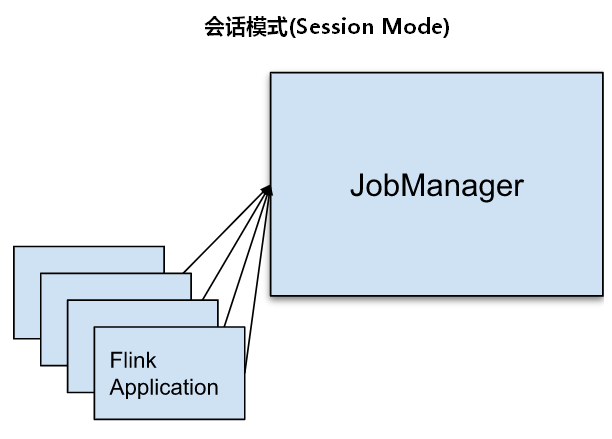
6.1、会话模式(Session Mode)
Session模式下我们首先会启动一个集群,保持一个会话,这个会话中通过客户端提交作业,集群启动时所有的资源都已经确定,所以所有的提交的作业会竞争集群中的资源。这种模式适合单个作业规模小、执行时间短的大量作业。
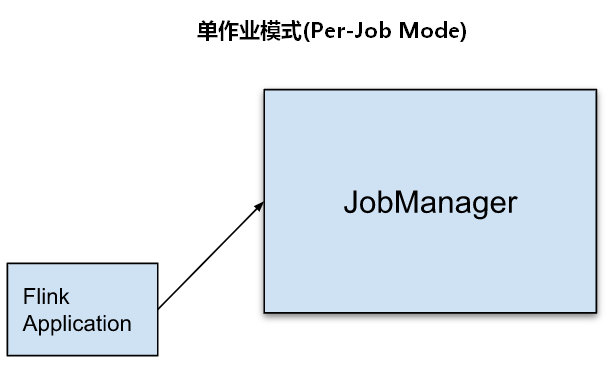
6.2、单作业模式(Per-Job Mode)
为了更好的隔离资源,Per-job模式是每提交一个作业会启动一个集群,集群只为这个作业而生,这种模式下客户端运行应用程序,然后启动集群,作业被提交给JobManager,进而分发给TaskManager执行,作业执行完成之后集群就会关闭,所有资源也会释放。
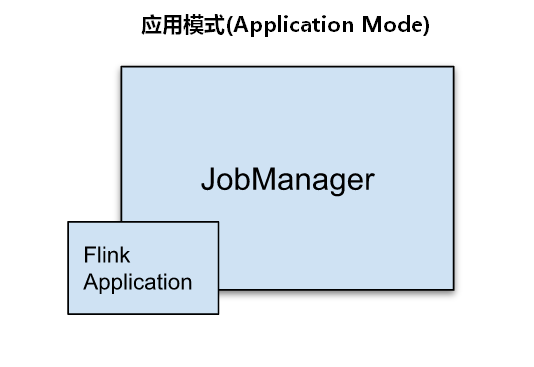
6.3、应用模式(Application Mode)
Application模式与Per-job类似,只是不需要客户端,每个Application提交之后就会启动一个JobManager,也就是创建一个集群,这个JobManager只为执行这一个Flink Application而存在,Application中的多个job都会共用该集群,Application执行结束之后JobManager也就关闭了。这种模式下一个Application会动态创建自己的专属集群(JobManager),所有任务共享该集群,不同Application之间是完全隔离的,在生产环境中建议使用Application模式提交任务。
三者区别总结:
-
Session 模式是先有Flink集群后再提交任务,任务在客户端提交运行,提交的多个作业共享Flink集群;
-
Per-Job模式和Application模式都是提交Flink任务后创建集群;
-
Per-Job模式通过客户端提交Flink任务,每个Flink任务对应一个Flink集群,每个任务有很好的资源隔离性;
-
Application模式是在JobManager上执行main方法,为每个Flink的Application创建一个Flink集群,如果该Application有多个任务,这些Flink任务共享一个集群。
七、Flink术语
7.1、Application与Job
无论处理批数据还是处理流数据我们都可以使用Flink提供好的Operator(算子)来转换处理数据,一个完整的Flink程序代码叫做一个Flink Application。一个完整的Flink Application一般由Source(数据来源)、Transformation(转换)、Sink(数据输出)三部分组成,Flink中一个或者多个Operator(算子)组合对数据进行转换形成Transformation,一个Flink Application 开始于一个或者多个Source,结束于一个或者多个Sink。
一个Flink Application中可以有多个Flink Job,每次调用execute()或者executeAsyc()方法可以触发一个Flink Job ,一个Flink Application中可以执行多次以上两个方法来触发多个job执行。但往往我们在编写一个Flink Application时只需要一个Job即可。

7.2、DataFlow数据流图
一个Flink Job 执行时会按照Source、Transformatioin、Sink顺序来执行,这就形成了Stream DataFlow(数据流图),数据流图是整体展示Flink作业执行流程的高级视图,通过WebUI我们可以看到提交应用程序的DataFlow。
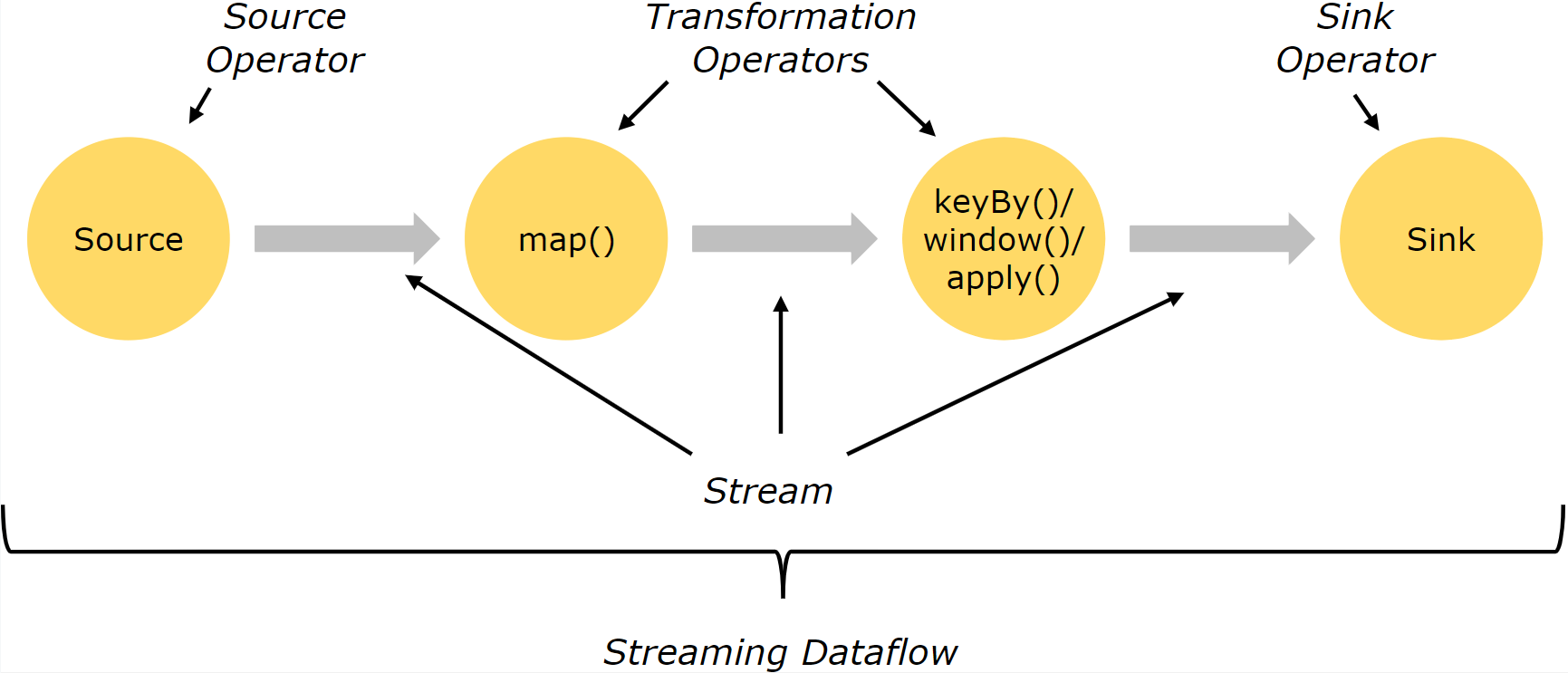
通常Operator算子和Transformation转换之间是一对一的关系,有时一个Transformation转换中包含多个Operator,形成一个算子链,这主要取决于数据之间流转关系和并行度是否相同。
7.3、Subtask子任务与并行度
在集群中运行Flink代码本质上是以并行和分布式方式来执行,这样可以提高处理数据的吞吐量和速度,处理一个Flink流过程中涉及多个Operator,每个Operator有一个或者多个Subtask(子任务),不同的Operator的Subtask个数可以不同,一个Operator有几个Subtask就代表当前算子的并行度(Parallelism)是多少,Subtask在不同的线程、不同的物理机或不同的容器中完全独立执行。
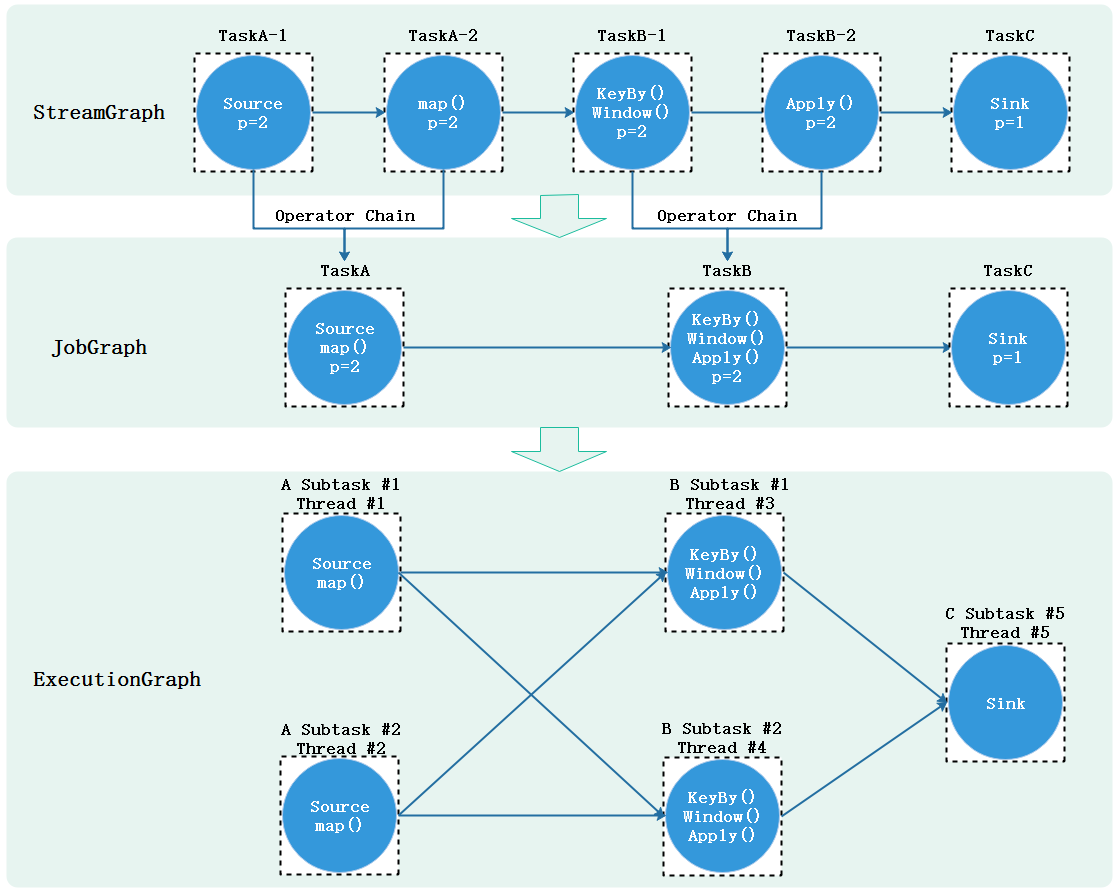
上图下半部分是多并行度DataFlow视图,Source、Map、KeyBy等操作有2个并行度,对应2个subtask分布式执行,Sink操作并行度为1,只有一个subtask,一共有7个Subtask,每个Subtask处理的数据也经常说成处理一个分区(Stream Partition)的数据。 一个 Flink Application 的并行度通常认为是所有Operator中最大的并行度 。上图中的Application并行度就为2。
7.4、Operator Chains 算子链
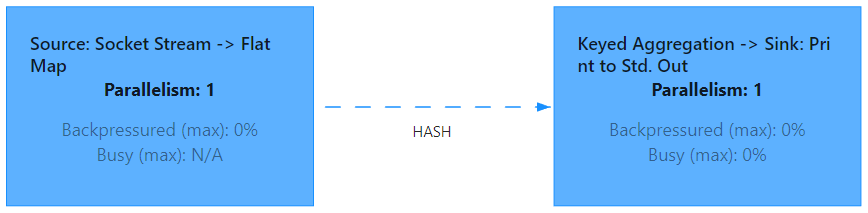
在Flink作业中,用户可以指定Operator Chains(算子链)将相关性非常强的算子操作绑定在一起,这样能够让转换过程上下游的Task数据处理逻辑由一个Task执行,进而避免因为数据在网络或者线程间传输导致的开销,减少数据处理延迟提高数据吞吐量。默认情况下,Flink开启了算子链。例如:下图流处理程序Source/map就形成了一个算子链,keyBy/window/apply形成了以算子链,分布式执行中原本需要多个task执行的情况由于有了算子链减少到由5个Subtask分布式执行即可。
一个数据流在算子之间传递数据可以是一对一(One-to-one)的模式传递,也可以是重分区(Redistributing)的模式传递,两者区别如下:
-
One-to-one:
一对一传递模式(例如上图中的Source和map()算子之间)保留了元素的分区和顺序,类似Spark中的窄依赖。这意味着map()算子的subtask[1]处理的数据全部来自Source的subtask[1]产生的数据,并且顺序保持一致。例如:map、filter、flatMap这些算子都是One-to-one数据传递模式。
-
Redistributing:
重分区模式(如上面的map()和keyBy/window之间,以及keyBy/window和Sink之间)改变了流的分区,这种情况下数据流向的分区会改变,类似于Spark中的宽依赖。每个算子的subtask将数据发送到不同的目标subtask,这取决于使用了什么样的算子操作,例如keyBy()是分组操作,会根据key的哈希值对数据进行重分区,再如,window/apply算子操作的并行度为2,流向了并行度为1的sink操作,这个过程需要通过rebalance操作将数据均匀发送到下游Subtask中。这些传输方式都是重分区模式(Redistributing)。
7.5、执行图
Flink代码提交到集群执行时最终会被转换成task分布式的在各个节点上运行,在前面提到DataFlow是一个Flink应用程序执行的高级视图,展示了Flink应用程序执行的总体流程,在Flink底层由DataFlow最终转换成执行的task的过程还涉及一些对象转换。下图以一个普通的Flink处理数据流程展示了一个Flink任务提交到集群后内部对象转换关系和流程,其中每个虚线框代表一个task,p代表并行度,这里假设为2。
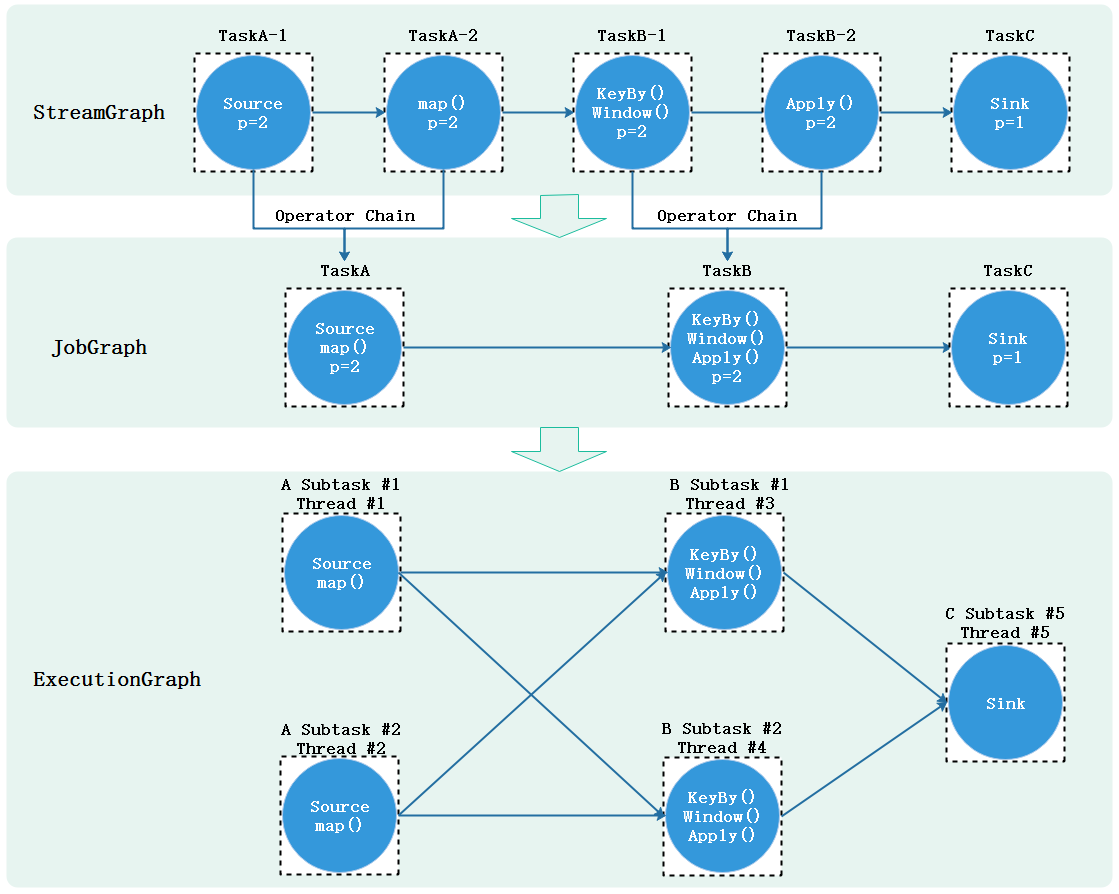
首先编写好的代码提交后在客户端会按照Transformation转换成StreamGraph(任务流图),StreamGraph是没有经过任何优化的流图,展示的是程序整体执行的流程。StreamGraph进而会按照默认的Operator Chains算子链合规则转换成JobGraph(作业图),在JobGraph中会将并行度相同且数据流转关系为One-to-one关系的算子合并在一起由一个Task进行处理原本2个Task处理的逻辑,这一步转换一般也是在客户端进行。JobGraph会被提交给JobManager,最终由JobManager中JobMaster转换成ExecutionGraph(执行图),ExecutionGraph中会按照每个算子并行度来划分对应的Subtask,每个Subtask最终再次被转换成其他可以部署的对象发送到TaskManager上执行。
结论:
-
在Flink中一个Task一般对应的就是一个算子或者多个算子逻辑。多个算子逻辑经过Operator Chains优化后也是由一个Task执行的。
-
Flink分布式运行中,Task会按照并行度划分成多个Subtask,每个Subtask由一个Thread线程执行,多个Subtask分布在不同的线程不同节点形成Flink分布式的执行。
-
Subtask是Flink任务调度的基本单元。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨