python爬虫详解
1、基本概念
1.1、什么是爬虫
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。例如:传统的通用搜索引擎AltaVista,Yahoo!和Google等,作为一个辅助人们检索信息的工具也存在着一定的局限性,通用搜索引擎的目标是尽可能大的网络覆盖率,返回的结果包含大量用户不关心的网页,为了解决上述问题,定向抓取相关网页资源的爬虫应运而生。
由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取网页并分析,已成为主流的爬取策略。只要你能通过浏览器访问的数据都可以通过爬虫获取,爬虫的本质是模拟浏览器打开网页,获取网页中我们想要的那部分数据。
1.2、Python为什么适合爬虫
因为python的脚本特性,python易于配置,对字符的处理也非常灵活,加上python有丰富的网络抓取模块,所以两者经常联系在一起。
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize。
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
1.3、Python爬虫组成部分
Python爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib(Python官方内置标准库)包括需要登录、代理、和cookie,requests(第三方包)
网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
应用程序:就是从网页中提取的有用数据组成的一个应用。
1.4、URI和URL的概念
在了解爬虫前,我们还需要了解一下什么是URL?
1.4.1、网页、网站、网络服务器、搜素引擎
网页:一份网页文档是交给浏览器显示的简单文档。这种文档是由超文本标记语言HTML来编写的,网页文档可以插入各种各样不同类型的资源:
- 样式信息 — 控制页面的观感
- 脚本— 为页面添加交互性
- 多媒体— 图像,音频,和视频
网络上所有可用的网页都可以通过一个独一无二的地址访问到。要访问一个页面,只需在你的浏览器地址栏中键入页面的地址,即URL。
网站:网站是共享唯一域名的相互链接的网页的集合。给定网站的每个网页都提供了明确的链接—一般都是可点击文本的形式—允许用户从一个网页跳转到另一个网页。要访问网站,请在浏览器地址栏中输入域名,浏览器将显示网站的主要网页或主页。
网络服务器:一个网络服务器是一台托管一个或多个网站的计算机。 "托管"意思是所有的网页和它们的支持文件在那台计算机上都可用。网络服务器会根据每位用户的请求,将任意网页从托管的网站中发送到任意用户的浏览器中。别把网站和网络服务器弄混了。例如,当你听到某人说:"我的网站没有响应",这实际上指的是网络服务器没响应,并因此导致网站不可用。
搜索引擎:搜索引擎是一个特定类型的网站,用以帮助用户在其他网站中寻找网页。例如:有Google, Bing, Yandex, DuckDuckGo等等。浏览器是一个接收并显示网页的软件,搜索引擎则是一个帮助用户从其他网站中寻找网页的网站。
1.4.2、什么是URL
早在1989年,网络发明人蒂姆·伯纳斯 - 李(Tim Berners-Lee)就提出了网站的三大支柱:
1)URL ,跟踪Web文档的地址系统
2)HTTP,一个传输协议,以便在给定URL时查找文档
3)HTML, 允许嵌入超链接的文档格式
Web的最初目的是提供一种简单的方式来访问,阅读和浏览文本文档。从那时起,网络已经发展到提供图像,视频和二进制数据的访问,但是这些改进几乎没有改变三大支柱。
在Web之前,很难访问文档并从一个文档跳转到另一个文档。WWW(World Wide Web,万维网)简称为3W,使用统一资源定位符(URL)来标志WWW上的各种文档。
完整的工作流程如下∶
1)Web用户使用浏览器(指定URL)与Web服务器建立连接,并发送浏览请求。
2)Web服务器把URL转换为文件路径,并返回信息给 Web浏览器。
3)通信完成,关闭连接。
HTTP:超文本传送协议(HTTP)是在客户程序(如浏览器)与WWW服务器程序之间进行交互所使用的协议。HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接,它使用TCP连接进行可靠传输,服务器默认监听在80端口。
URL:代表统一资源定位器。URL 只不过是 Web 上给定的唯一资源的地址。理论上,每个有效的 URL 都指向一个唯一的资源。此类资源可以是 HTML 页面、CSS 文档、图像等。

URL的组成:
1)协议部分(http:):它表示浏览器必须使用的协议来请求资源(协议是在计算机网络中交换或传输数据的一套方法),通常对于网站,协议是 HTTPS 或 HTTP(其不安全版本)。这里使用的是HTTP协议,在"HTTP"后面的“//”为分隔符;
2)域名部分(www.example.com):一个URL中,也可以直接使用IP地址;
3)端口部分(80):域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口(默认端口可以省略)。
4)资源路径:资源路径包含,虚拟目录部分和文件名部分
虚拟目录部分(/path/to/):从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。
文件名部分(myfile.html):从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分。
6)参数部分(key1=value1&key2=value2):从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。
7)锚部分(SomewhereInTheDocument):从“#”开始到最后,都是锚部分。锚点代表资源内的一种“书签”,为浏览器提供显示位于该“书签”位置的内容的方向。例如,在 HTML 文档中,浏览器将滚动到定义锚点的位置;在视频或音频文档上,浏览器将尝试转到锚点所代表的时间。
URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。
1.5、引入模块
在进行爬虫时,我们会用到一些模块,怎么去使用这些模块呢?
模块(module):就是用来从逻辑上组织Python代码(变量、函数、类),本质就是py文件,提供代码的可维护性,Python使用import来导入模块,如果没有基础的可以先看这篇文章:https://blog.csdn.net/xiaoxianer321/article/details/116723566。
导入模块:
#导入内置模块
import sys
#导入标准库
import os
#导入第三方库(需要安装:pip install bs4)
import bs4
from bs4 import BeautifulSoup
print(os.getcwd()) #打印当前工作目录
#import bs4 导入整个模块
print(bs4.BeautifulSoup.getText)
#from bs4 import BeautifulSoup 导入指定模块的部分属性至当前工作空间
print(BeautifulSoup.getText)安装方式1:在终端中使用命令
安装方式二:pycharm在设置中安装
我们大概会用到以下这些模块:
import urllib.request,urllib.error #定制URL,获取网页数据
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文件匹配
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作2、urllib库详解
Python3 中将 Python2 中的 urllib 和 urllib2 两个库整合为一个 urllib 库,所以现在一般说的都是 Python3 中的 urllib 库,它是python3内置标准库,不需要额外安装。
urllib的四个模块:
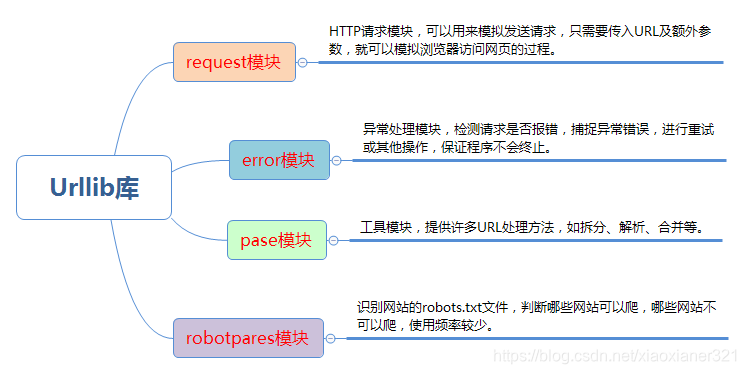
2.1、request模块
request模块提供了最基本的构造 HTTP 请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理authenticaton(授权验证),redirections(重定向),cookies(浏览器Cookies)以及其它内容。
2.1.1、urllib.request.urlopen() 函数
打开一个url方法,返回一个文件对象HttpResponse。urlopen默认会发送get请求,当传入data参数时,则会发起POST请求。
语法:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
参数说明:
url:请求的 url,也可以是request对象
data:请求的 data,如果设置了这个值,那么将变成 post 请求,如果要传递一个字典,则应该用urllib.parse模块的urlencode()函数编码;
timeout:设置网站的访问超时时间句柄对象;
cafile和capath:用于 HTTPS 请求中,设置 CA 证书及其路径;
cadefault:忽略*cadefault*参数;
context:如果指定了*context*,则它必须是一个ssl.SSLContext实例。
urlopen() 返回对象HTTPResponse提供的方法和属性:
1)read()、readline()、readlines()、fileno()、close():对 HTTPResponse 类型数据进行操作;
2)info():返回 HTTPMessage 对象,表示远程服务器 返回的头信息 ;
3)getcode():返回 HTTP 状态码 geturl():返回请求的 url;
4)getheaders():响应的头部信息;
5)status:返回状态码;
6)reason:返回状态的详细信息.案例一:使用urlopen()函数抓取百度
import urllib.request
url = "http://www.baidu.com/"
res = urllib.request.urlopen(url) # get方式请求
print(res) # 返回HTTPResponse对象<http.client.HTTPResponse object at 0x00000000026D3D00>
# 读取响应体
bys = res.read() # 调用read()方法得到的是bytes对象。
print(bys) # <!DOCTYPE html><!--STATUS OK-->\n\n\n <html><head><meta...
print(bys.decode("utf-8")) # 获取字符串内容,需要指定解码方式,这部分我们放到html文件中就是百度的主页
# 获取HTTP协议版本号(10 是 HTTP/1.0, 11 是 HTTP/1.1)
print(res.version) # 11
# 获取响应码
print(res.getcode()) # 200
print(res.status) # 200
# 获取响应描述字符串
print(res.reason) # OK
# 获取实际请求的页面url(防止重定向用)
print(res.geturl()) # http://www.baidu.com/
# 获取响应头信息,返回字符串
print(res.info()) # Bdpagetype: 1 Bdqid: 0x803fb2b9000fdebb...
# 获取响应头信息,返回二元元组列表
print(res.getheaders()) # [('Bdpagetype', '1'), ('Bdqid', '0x803fb2b9000fdebb'),...]
print(res.getheaders()[0]) # ('Bdpagetype', '1')
# 获取特定响应头信息
print(res.getheader(name="Content-Type")) # text/html;charset=utf-8
在简单的了解了一下使用urllib.request.urlopen(url)函数,会返回一个HTTPResponse对象,对象中包含了请求后响应的各项信息。
请求url最常见的方式莫过于发送get请求或post请求,为了更方便的看到效果,我们可以使用这个网站http://httpbin.org/来测试我们的请求。
案例二:get请求
我们在http://httpbin.org/网站,发送一个get测试请求:
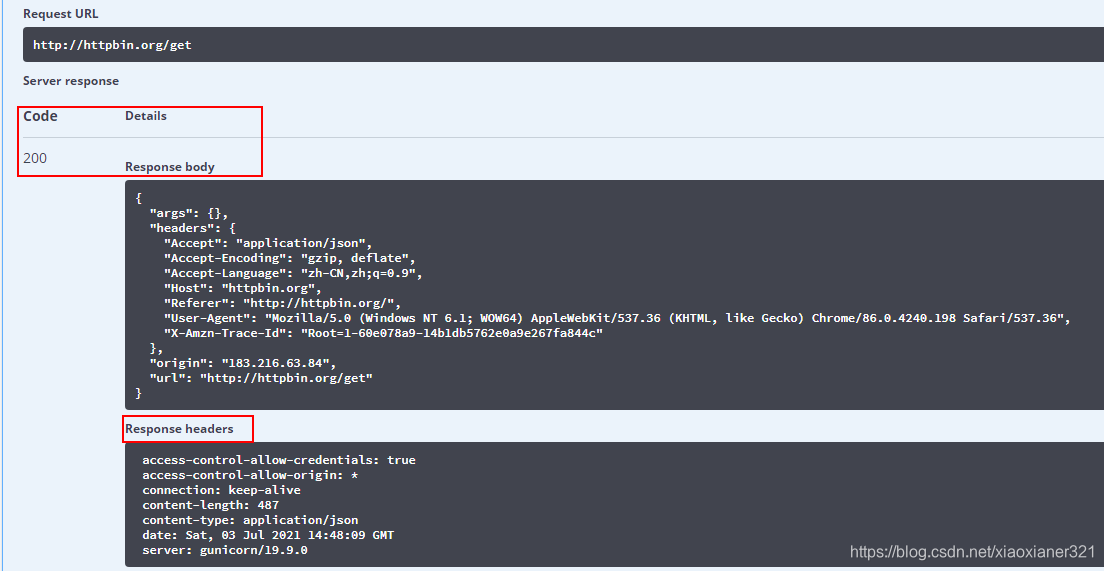
然后我们在使用python模拟浏览器发送一个get请求
import urllib.request
# 请求的URL
url = "http://httpbin.org/get"
# 模拟浏览器打开网页(get请求)
res = urllib.request.urlopen(url)
print(res.read().decode("utf-8"))请求结果如下:
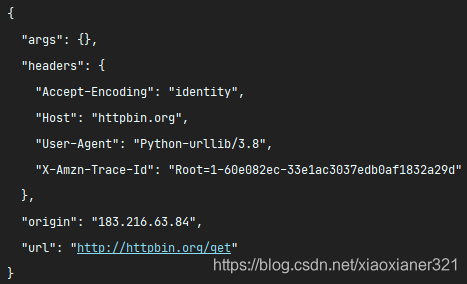
我们会发现python模拟浏览器的请求很像。
案例三:pos请求
import urllib.request
import urllib.parse
url = "http://httpbin.org/post"
# 按POST请求的格式封装数据,请求内容,需要传递data
data = bytes(urllib.parse.urlencode({"hello": "world"}), encoding="utf-8")
res = urllib.request.urlopen(url, data=data)
# 输出响应结果
print(res.read().decode("utf-8"))模拟浏览器发出的请求(提交的数据会以form表单的形式发送出去),响应结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"hello": "world"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.8",
"X-Amzn-Trace-Id": "Root=1-60e0754e-7ea455cc757714f14db8f2d2"
},
"json": null,
"origin": "183.216.63.84",
"url": "http://httpbin.org/post"
}
案例四: 伪装Headers
通过上面的案例,不难发现使用urllib发送的请求,比较不同的地方是:"User-Agent",使用urllib发送的会有一个默认的Headers:User-Agent: Python-urllib/3.8。所以遇到一些验证User-Agent的网站时,有可能会直接拒绝爬虫,因此我们需要自定义Headers把自己伪装的像一个浏览器一样。
其实我们使用抓包工具也能看到http请求,使用抓包工具,抓取未指定请求头的get请求如下:
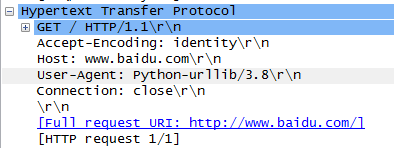
而我直接使用谷歌浏览器时,使用抓包工具获取到的User-Agent如下:

当然也可以直接在浏览器中查看:
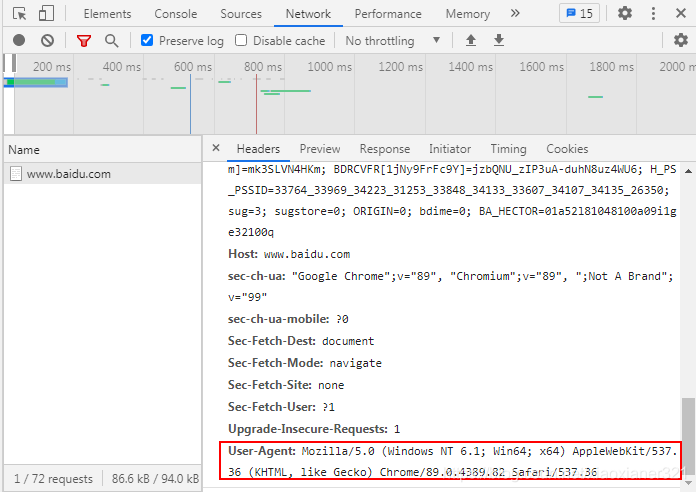
例如:我去爬取豆瓣网时:
import urllib.request
url = "http://douban.com"
resp = urllib.request.urlopen(url)
print(resp.read().decode('utf-8'))
返回错误:反爬虫
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 418:
HTTP 418 I'm a teapot客户端错误响应代码表示服务器拒绝煮咖啡,因为它是一个茶壶。这个错误是对1998年愚人节玩笑的超文本咖啡壶控制协议的引用。自定义Headers:
import urllib.request
url = "http://douban.com"
# 自定义headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
req = urllib.request.Request(url, headers=headers)
# urlopen(也可以是request对象)
print(urllib.request.urlopen(req).read().decode('utf-8')) # 获取字符串内容,需要指定解码方式当我再次使用抓包工具,抓取指定请求头的get请求,结果如下:

案例五:设置请求超时时间
我们在爬取网页时,难免会遇到请求超时,或者无法响应的网址,为了提高代码的健壮性,我可以设置请求超时时间。
import urllib.request,urllib.error
url = "http://httpbin.org/get"
try:
resp = urllib.request.urlopen(url, timeout=0.01)
print(resp.read().decode('utf-8'))
except urllib.error.URLError as e:
print("time out")
输出:time out
2.1.2、urllib.request.urlretrieve() 函数
urlretrieve()函数的作用是直接将远程的数据下载到本地
# 语法:
urlretrieve(url, filename=None, reporthook=None, data=None)
# 参数说明
url:传入的网址
filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据)
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度
data:指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header表示服务器的响应头
使用案例:
import urllib.request
url = "http://www.hao6v.com/"
filename = "C:\\Users\\Administrator\\Desktop\\python_3.8.5\\电影.html"
def callback(blocknum,blocksize,totalsize):
"""
@blocknum:目前为此传递的数据块数量
@blocksize:每个数据块的大小,单位是byte,字节
@totalsize:远程文件的大小
"""
if totalsize == 0:
percent = 0
else:
percent = blocknum * blocksize / totalsize
if percent > 1.0:
percent = 1.0
percent = percent * 100
print("download : %.2f%%" % (percent))
local_filename, headers= urllib.request.urlretrieve(url, filename, callback)
案例效果:
2.2、error模块
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
2.2.1、HTTP协议(RFC2616)状态码定义
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。
状态代码的第一个数字代表当前响应的类型:
1xx消息——请求已被服务器接收,继续处理
2xx成功——请求已成功被服务器接收、理解、并接受
3xx重定向——需要后续操作才能完成这一请求
4xx请求错误——4xx类的状态码用于看起来客户端有错误的情况下,请求含有词法错误或者无法被执行
5xx服务器错误——由数字“5”打头的响应状态码表示服务器已经明显处于错误的状况下或没有能力执行请求,或在处理某个正确请求时发生错误。
部分状态码如下:
| 状态码 | 定义 |
| 100 | 继续。客户端应该继续它的请求。该间歇响应用于提醒客户端服务器已经接收和接受请求的开 始部分。 客户端应该继续发送请求的剩余部分, 或者如果请求已经发送完了, 就乎略该响应。 服务器在请求完成后必须发送最终响应。 |
| 101 | 切换协议。 |
| 200 | OK。请求已经成功。该响应返回的信息取决于请求中使用的方法,例如: GET与所请求资源相对应的实体将在响应中发送; HEAD 与所请求资源相对应的实体头部将在响应中发送,而没有消息体; POST描述或包含行为结果的实体; TRACE 包含终点服务器收到的请求消息的实体。 |
| 201 | 创建。请求全部成功,且创建了新资源。原始服务器必须在返回 201 状态码之前创建资源。 如果该行为不能立即实施,服务器应该代之以202(Accepted)响应。 |
| 202 | 请求已经接受处理,但是处理还没有完成。 |
| 203 | 实体头部中返回的元信息不是在原始服务器有效的确定集合, 而是从本地或第三方拷贝 收集的。现在的集合可能是原始版本的子集或超集。 |
| 204 | 服务器已经完成请求,但不需要返回实体,且可能希望返回更新的元信息。响应可能包 括新的或更新的元信息,通过实体头部的形式。如果存在这些头部,则应该与所请求变量相 关。 |
| 205 | 重置内容。服务器已经完成请求且用户代理应该复位引起请求发送的文档视图。 |
| 300 | 多重选项。所请求的资源符合表述集合中的任何一个,每个都有它自己的特殊位置。代理驱动的协 商信息提供给用户(或用户代理)来选择喜欢的表述,并重定向请求到它的位置。 |
| 301 | 所请求的资源已经指定到一个新的永久 URI, 且将来任何对该资源的引用都应该使用所 返回的 URI 之一。 |
| 302 | 所请求的资源临时存在于不同的 URI。 |
| 303 | 请求的响应可以在不同的URI中发现,且应该使用GET方法到该资源来获取它。 |
| 307 | 临时重定向 |
| 400 | 服务器不能理解请求,由于畸形的语法。 |
| 403 | 服务器理解请求, 但拒绝完成它。 认证也没用, 请求不该重复。 |
| 404 | 未找到。服务器不能发现匹配Request-URI的任何东西。 |
| 408 | 请求超时 |
| 500 | 服务器错误 |
| 503 | 服务不可用 |
| 504 | 网关超时 |
| 505 | HTTP版本不支持 |
2.2.2、 urllib.error.URLError
import urllib.request,urllib.error
try:
url = "http://www.baidus.com"
resp = urllib.request.urlopen(url)
print(resp.read().decode('utf-8'))
# except urllib.error.HTTPError as e:
# print("请检查url是否正确")
# URLError是urllib.request异常的超类
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)案例效果:

URLError,为urllib.request 所引发的基础异常类,这里打印出来的403,就是urllib.error.HTTPError,另外还有一个ContentTooShortError,此异常会在 urlretrieve() 函数检测到已下载的数据量小于期待的数据量(由 Content-Length 头给定)时被引发。
2.3、parse 模块
urllib.parse 模块提供了很多解析和组建 URL 的函数。下面只列出了部分
解析url的函数:urllib.parse.urlparse、urllib.parse.urlsplit、urllib.parse.urldefrag
组件url的函数:urllib.parse.urlunparse、urllib.parse.urljoin
查询参数的构造与解析:urllib.parse.urlencode、urllib.parse.parse_qs、
urllib.parse.parse_qsl2.3.1、urllib.parse.urlparse
# 语法
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)
scheme:设置默认值
allow_fragments:是否允许fragment将URL解析成 ParseResult 对象。对象中包含了六个元素:也就是我们前面说过的url的组成,只不过urlparse函数,将其解析成6个元素。
| 属性 | 索引 | 值 | 值(如果不存在) |
|---|---|---|---|
|
| 0 | URL协议 | scheme 参数 |
|
| 1 | 网络位置部分(域名) | 空字符串 |
|
| 2 | 分层路径 | 空字符串 |
|
| 3 | 最后路径元素的参数 | 空字符串 |
|
| 4 | 查询参数 | 空字符串 |
|
| 5 | 片段识别 | 空字符串 |
使用案例:
import urllib.parse
url = "http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2#SomewhereIntheDocument"
parsed_result = urllib.parse.urlparse(url)
print(parsed_result)
print('协议-scheme :', parsed_result.scheme)
print('域名-netloc :', parsed_result.netloc)
print('路径-path :', parsed_result.path)
print('路径参数-params :', parsed_result.params)
print('查询参数-query :', parsed_result.query)
print('片段-fragment:', parsed_result.fragment)
print('用户名-username:', parsed_result.username)
print('密码-password:', parsed_result.password)
print('主机名-hostname:', parsed_result.hostname)
print('端口号-port :', parsed_result.port)
输出结果:
ParseResult(scheme='http', netloc='www.example.com:80', path='/path/to/myfile.html', params='', query='key1=value&key2=value2', fragment='SomewhereIntheDocument')
协议-scheme : http
域名-netloc : www.example.com:80
路径-path : /path/to/myfile.html
路径参数-params :
查询参数-query : key1=value&key2=value2
片段-fragment: SomewhereIntheDocument
用户名-username: None
密码-password: None
主机名-hostname: www.example.com
端口号-port : 802.3.2、urllib.parse.urlsplit
这类似于urlparse,所不同的是, urlsplit() 并不会把路径参数(params) 从 路径(path) 中分离出来。此函数返回一个名为tuple的5项:(协议、域名、路径、查询、片段标识符)
使用案例:
import urllib.parse
url = "http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2#SomewhereIntheDocument"
# urlsplit分割,唯一的区别就是不会把params拆分出来
parsed_result = urllib.parse.urlsplit(url)
print(parsed_result)
print('协议-scheme :', parsed_result.scheme)
print('域名-netloc :', parsed_result.netloc)
print('路径-path :', parsed_result.path)
# parsed_result.params 没有这项
print('查询参数-query :', parsed_result.query)
print('片段-fragment:', parsed_result.fragment)
print('用户名-username:', parsed_result.username)
print('密码-password:', parsed_result.password)
print('主机名-hostname:', parsed_result.hostname)
print('端口号-port :', parsed_result.port)2.3.3、urllib.parse.urlsplit
urllib.parse.urldefrag,如果url包含片段标识符,则返回修改后的url版本(不包含片段标识符),并将片段标识符作为单独的字符串返回。如果url中没有片段标识符,则返回原url和空字符串。
使用案例:
import urllib.parse
url = "http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2#SomewhereIntheDocument"
parsed_result = urllib.parse.urldefrag(url)
print(parsed_result)
# DefragResult(url='http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2', fragment='SomewhereIntheDocument')
url1 = "http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2"
parsed_result1 = urllib.parse.urldefrag(url1)
print(parsed_result1)
# 输出结果:
# DefragResult(url='http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2', fragment='SomewhereIntheDocument')
# DefragResult(url='http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2', fragment='')
2.3.4、urllib.parse.urlunparse
urlunparse()接收一个列表的参数,而且列表的长度是有要求的,是必须六个参数以上,否则抛出异常。
import urllib.parse
url_compos = ('http', 'www.example.com:80', '/path/to/myfile.html', 'params2', 'query=key1=value&key2=value2', 'SomewhereIntheDocument')
print(urllib.parse.urlunparse(url_compos))
# 输出结果:
# http://www.example.com:80/path/to/myfile.html;params2?query=key1=value&key2=value2#SomewhereIntheDocument2.3.5、urllib.parse.urljoin
import urllib.parse
# 连接两个参数的url, 将第二个参数中缺的部分用第一个参数的补齐,如果第二个有完整的路径,则以第二个为主。
print(urllib.parse.urljoin('https://movie.douban.com/', 'index'))
print(urllib.parse.urljoin('https://movie.douban.com/', 'https://accounts.douban.com/login'))
# 输出结果:
# https://movie.douban.com/index
# https://accounts.douban.com/login
2.3.6、urllib.parse.urlencode
可以将一个 dict 转换成合法的查询参数。
import urllib.parse
query_args = {
'name': 'dark sun',
'country': '中国'
}
query_args = urllib.parse.urlencode(query_args)
print(query_args)
# 输出结果
# name=dark+sun&country=%E4%B8%AD%E5%9B%BD2.3.7、urllib.parse.parse_qs
解析作为字符串参数提供的查询字符串,数据作为字典返回。字典键是唯一的查询变量名,值是每个名称的值列表。
import urllib.parse
query_args = {
'name': 'dark sun',
'country': '中国'
}
query_args = urllib.parse.urlencode(query_args)
print(query_args) # name=dark+sun&country=%E4%B8%AD%E5%9B%BD
print(urllib.parse.parse_qs(query_args)) # 返回字典
print(urllib.parse.parse_qsl(query_args)) # 返回列表
# 输出结果
# {'name': ['dark sun'], 'country': ['中国']}
# [('name', 'dark sun'), ('country', '中国')]2.4、robotparser模块
此模块提供了一个单独的类 RobotFileParser,它可以回答关于某个特定用户代理是否能在 Web 站点获取发布 robots.txt 文件的 URL 的问题。(/robots.txt该文件是一个简单的基于文本的访问控制系统,文件向网络机器人提供有关其网站的说明,什么机器人可以访问,哪些链接不可以访问)
3、BeautifulSoup4
学了urllib标准库之后,我们已经能爬到些比较正常的网页源码(html文档)了,但这离结果还差一步——就是如何筛选我们想要的数据,这时候BeautifulSoup库就来了,BeautifulSoup目前最新版本为BeautifulSoup4。
3.1、BeautifulSoup4的简介及使用
3.1.1、BeautifulSoup4的简介
Beautiful Soup 官方定义:是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。(官网文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/)
BeautifulSoup本身支持Python标准库中的HTML解析器,但若想使BeautifulSoup使用html5lib/lxml 解析器解析器,可以使用下面方法。(官方推荐:使用lxml作为解析器,因为效率更高。)
pip install html5lib
pip install lxml3.1.2、BeautifulSoup4的使用
BeautifulSoup(markup, features)接受两个参数:
第一个参数(markup):文件对象或字符串对象
第二个参数(features):解析器,未指定则使用python标准解析器(html.parser),但会产警告
from bs4 import BeautifulSoup # 导入BeautifulSoup4库
# 未指定就使用html.parser这个python标准解析器 BeautifulSoup(markup, "html.parser") 未指定会产生警告 GuessedAtParserWarning: No parser was explicitly specified
# BeautifulSoup 第一个参数接受:一个文件对象或字符串对象
soup1 = BeautifulSoup(open("C:\\Users\\Administrator\\Desktop\\python_3.8.5\\电影.html"))
soup2 = BeautifulSoup("<html>hello python</html>") # 得到文档的对象
print(type(soup2)) # <class 'bs4.BeautifulSoup'>
print(soup1) # <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ....
print(soup2) # <html><head></head><body>hello python</body></html>
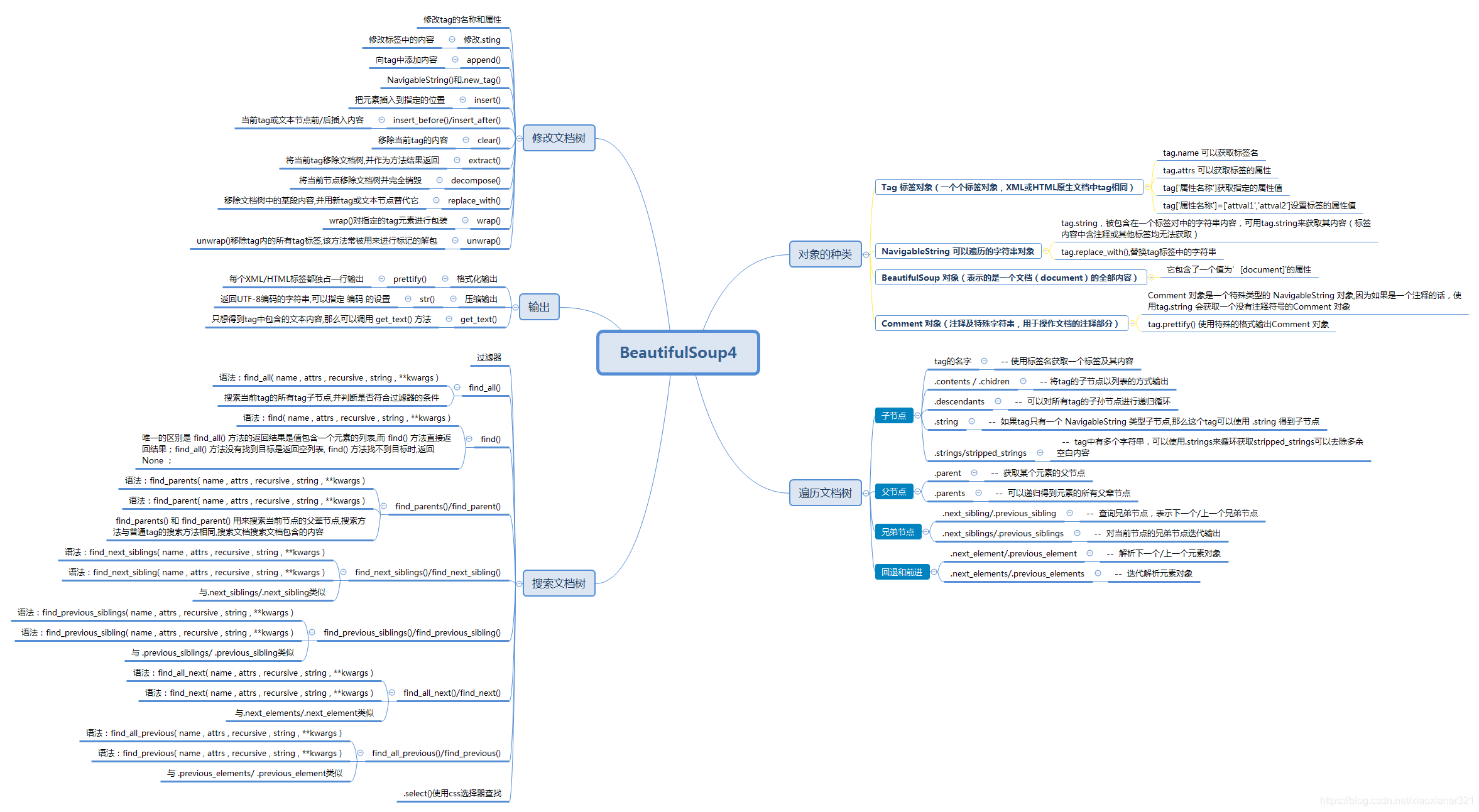
3.2、对象的种类
BeautifulSoup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment 。
3.2.1、Tag 标签对象
Tag有很多方法和属性,在 遍历文档树 和 搜索文档树 中有详细解释.现在介绍一下tag中最重要的属性: name和attribute。
3.2.2、NavigableString 对象(可以遍历的字符串)
被包含在一个标签对中的字符串内容,可用tag.string来获取其内容(标签内容中含注释或其他标签均无法获取)
3.2.3、BeautifulSoup 对象
表示的是一个文档(document)的全部内容
3.2.4、Comment 对象(注释及特殊字符串)
Comment 对象是一个特殊类型的 NavigableString 对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦。
使用案例:
from bs4 import BeautifulSoup
# 导入BeautifulSoup4库
# python 标准解析器 未指定就使用这个 BeautifulSoup(markup, "html.parser")
soup2 = BeautifulSoup("<html>"
"<p class='boldest'>我是p标签<b>hello python</b></p>"
"<!--我是标签外部的内容注释-->"
"<p class='boldest2'><!--我p标签内的注释-->我是独立的p标签</p>"
"<a><!--我a标签内的注释-->我是链接</a>"
"<h1><!--这是一个h1标签的注释--></h1>"
"</html>",
"html5lib") # 得到文档的对象
# Tag 标签对象
print(type(soup2.p)) # 输出Tag对象<class 'bs4.element.Tag'>
print(soup2.p.name) # 输出Tag标签对象的名称
print(soup2.p.attrs) # 输出第一个p标签的属性信息:{'class': ['boldest']}
soup2.p['class'] = ['boldest', 'boldest1']
print(soup2.p.attrs) # {'class': ['boldest', 'boldest1']}
# NavigableString 可以遍历的字符串对象
print(type(soup2.b.string)) # <class 'bs4.element.NavigableString'>
print(soup2.b.string) # hello python
print(soup2.a.string) # None 存在注释或者其他标签内容均无法获取
print(soup2.b.string.replace_with("hello world")) # replace_with()方法可替换标签中的内容
print(soup2.b.string) # hello world
# BeautifulSoup 对象
print(type(soup2)) # <class 'bs4.BeautifulSoup'>
print(soup2) # <html><head></head><body><p class="boldest">我是p标签<b>hello python</b></p><!--我是标签外部的内容注释--><p><!--我p标签内的注释-->我是独立的p标签</p></body></html>
print(soup2.name) # [document]
# Comment 注释及特殊字符串(是一个特殊类型的 NavigableString 对象)
print(type(soup2.h1.string)) # <class 'bs4.element.Comment'>
print(soup2.h1.string) # 这是一个h1标签的注释 (利用 .string 来输出它的内容,注释符被去除了,不是我们想要的)
print(soup2.h1.prettify()) # 会以特殊格式输出:<h1> <!--这是一个h1标签的注释--> </h1>
3.3、对象属性-遍历文档
3.3.1、子节点
| 属性(BeautifulSoup对象) | 描述 |
| .tag标签名 | 使用标签名获取一个标签及其内容 |
| .contents / .chidren | 将tag的子节点以列表的方式输出 |
| .descendants | 可以对所有tag的子孙节点进行递归循环 |
| .string | 如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点 |
| .strings/stripped_strings | tag中有多个字符串,可以使用.strings来循环获取stripped_strings可以去除多余空白内容 |
使用案例:
from bs4 import BeautifulSoup
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>I’m the title</title>
</head>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>
<b>我是一个段落...</b>
我是第一段
我是第二段
<b>我是另一个段落</b>
我是第一段
</p>
<a>我是一个链接</a>
</div>
<div>
<p>picture</p>
<img src="example.png"/>
</div>
</div>
</body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
print(soup.head.name) # soup.head可以获取标签,获取标签名 - 输出:head
print(soup.head.contents) # 将tag的子节点以列表的方式输出--输出:['\n ', <meta charset="utf-8"/>, '\n ', <title>I’m the title</title>, '\n ']
print(soup.head.contents[1]) # <meta charset="utf-8"/>
print(soup.head.children) # list_iterator object
for child in soup.head.children:
print(child) # <meta charset="utf-8"/> <title>I’m the title</title>
# 标签中的内容其实也是一个节点 使用contents和children无法直接获取间接节点中的内容,但是.descendants 属性可以
for child in soup.head.descendants:
print(child) # <meta charset="utf-8"/> <title>I’m the title</title> I’m the title
print(soup.head.title.string) # 输出:I’m the title 注:title中有其他节点或者注释都无法获取
print(soup.body.div.div.p.strings) # 使用.string-None 使用.strings 获得generator object
for string in soup.body.div.div.p.stripped_strings: # stripped_strings 可以去除多余空白内容
print(repr(string)) # '我是一个段落...'
# '我是第一段\n 我是第二段'
# '我是另一个段落'
# '我是第一段'3.3.2、父节点
| 属性 | 描述 |
| .parent | 获取某个元素的父节点 |
| .parents | 可以递归得到元素的所有父辈节点 |
使用案例:
from bs4 import BeautifulSoup
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>I’m the title</title>
</head>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>
<b>我是一个段落...</b>
我是第一段
我是第二段
<b>我是另一个段落</b>
我是第一段
</p>
<a>我是一个链接</a>
</div>
<div>
<p>picture</p>
<img src="example.png"/>
</div>
</div>
</body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
title = soup.head.title
print(title.parent) # 输出父节点
# <head>
# <meta charset="utf-8"/>
# <title>I’m the title</title>
# </head>
print(title.parents) # generator object PageElement.parents
for parent in title.parents:
print(parent) # 输出head父节点 和 html父节点3.3.3、兄弟节点
| 属性 | 描述 |
| .next_sibling | 查询兄弟节点,表示下一个兄弟节点 |
| .previous_sibling | 查询兄弟节点,表示上一个兄弟节点 |
| .next_siblings | 对当前节点的兄弟节点迭代输出(下) |
| .previous_siblings | 对当前节点的兄弟节点迭代输出(上) |
使用案例:
from bs4 import BeautifulSoup
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>I’m the title</title>
</head>
<body>
<div>
<p>
<b id=“b1”>我是第一个段落</b><b id=“b2”>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b>
</p>
<a>我是一个链接</a>
</div>
</body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
p = soup.body.div.p.b
print(p) # <b id="“b1”">我是第一个段落</b>
print(p.next_sibling) # <b id="“b2”">我是第二个段落</b>
print(p.next_sibling.previous_sibling) # <b id="“b1”">我是第一个段落</b>
print(p.next_siblings) # generator object PageElement.next_siblings
for nsl in p.next_siblings:
print(nsl) # <b id="“b2”">我是第二个段落</b>
# <b id="“b3”">我是第三个段落</b>
# <b id="“b4”">我是第四个段落</b>3.3.4、回退和前进
| 属性 | 描述 |
| .next_element | 解析下一个元素对象 |
| .previous_element | 解析上一个元素对象 |
| .next_elements | 迭代解析元素对象 |
| .previous_elements | 迭代解析元素对象 |
使用案例:
from bs4 import BeautifulSoup
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>I’m the title</title>
</head>
<body>
<div>
<p>
<b id=“b1”>我是第一个段落</b><b id=“b2”>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b>
</p>
<a>我是一个链接<h3>h3</h3></a>
</div>
</body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
p = soup.body.div.p.b
print(p) # <b id="“b1”">我是第一个段落</b>
print(p.next_element) # 我是第一个段落
print(p.next_element.next_element) # <b id="“b2”">我是第二个段落</b>
print(p.next_element.next_element.next_element) # 我是第二个段落
for element in soup.body.div.a.next_element: # 对:我是一个链接 字符串的遍历
print(element)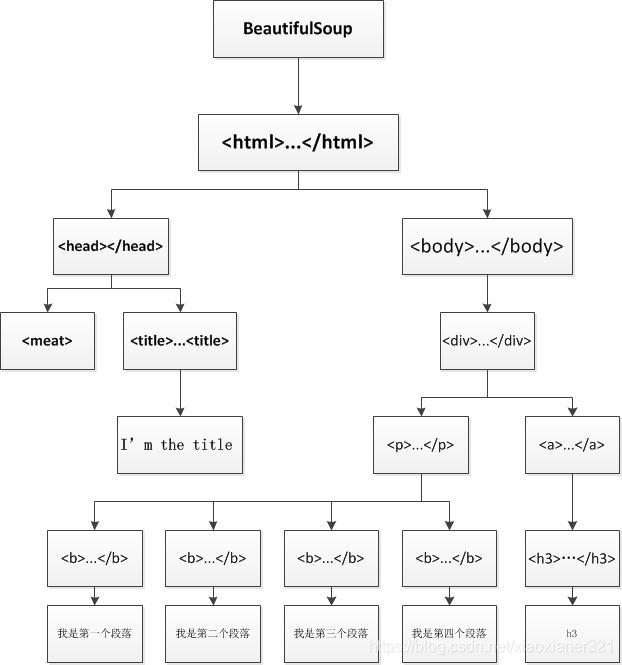
注:next_element,会把标签中的内容,也会认为是一个节点。例如:案例中取a节点的next_element,则是一个字符串(我是一个链接)
3.4、对象的属性和方法-搜索文档树
这里的搜索文档,其实就是按照某种条件去搜索过滤文档,过滤的规则,往往会使用搜索的API,或者我们也可以自定义正则/过滤器,去搜索文档。
3.4.1、find_all()
最简单的过滤器是字符串.在搜索方法中传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容。
语法:find_all( name , attrs , recursive , string , **kwargs ) 返回列表list
find_all( name , attrs , recursive , string , **kwargs )
参数说明:
name:查找所有名字为 name 的tag(name可以是字符串,也可以是列表)
attrs: 对标签属性值的检索字符串,可标注属性检索
recursive: 是否对子孙全部检索,默认True
string: <>…</>中字符串区域的检索字符串使用案例:
from bs4 import BeautifulSoup
import re
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title id="myTitle">I’m the title</title>
</head>
<body>
<div>
<p>
<b id=“b1” class="bcl1">我是第一个段落</b><b>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b>
</p>
<a href="www.temp.com">我是一个链接<h3>h3</h3></a>
<div id="dv1">str</div>
</div>
</body>
</html>'''
# 语法:find_all( name , attrs , recursive , string , **kwargs )
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
# 第一个参数name,可以是一个标签名也可以是列表
print(soup.findAll('b')) # 返回包含b标签的列表 [<b id="“b1”">我是第一个段落</b>, <b id="“b2”">我是第二个段落</b>, <b id="“b3”">我是第三个段落</b>, <b id="“b4”">我是第四个段落</b>]
print(soup.findAll(['a', 'h3'])) # 按列表匹配多个 [<a href="www.temp.com">我是一个链接<h3>h3</h3></a>, <h3>h3</h3>]
# 第二个参数attrs,可以指定参数名字,也可以不指定
print(soup.findAll('b', 'bcl1')) # 匹配class='bcl1'的b标签[<b class="bcl1" id="“b1”">我是第一个段落</b>]
print(soup.findAll(id="myTitle")) # 指定id [<title id="myTitle">I’m the title</title>]
print(soup.find_all("b", attrs={"class": "bcl1"})) # [<b class="bcl1" id="“b1”">我是第一个段落</b>]
print(soup.findAll(id=True)) # 匹配所有有id属性的标签
# 第三个参数recursive 默认True 如果只想搜索tag的直接子节点,可以使用参数 recursive=False
print(soup.html.find_all("title", recursive=False)) # [] recursive=False。找html的直接子节点,是head,所以找不到title
# 第四个参数string
print(soup.findAll('div', string='str')) # [<div id="dv1">str</div>]
print(soup.find(string=re.compile("我是第二个"))) # 搜索我是第二个段落
# 其他参数 limit 参数
print(soup.findAll('b', limit=2)) # 当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果,[<b class="bcl1" id="“b1”">我是第一个段落</b>, <b>我是第二个段落</b>]
3.4.2、find()
find()与find_all() 的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果(即找到了就不再找,只返第一个匹配的),find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None。
语法:find( name , attrs , recursive , string , **kwargs )
使用案例:
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
# 第一个参数name,可以是一个标签名也可以是列表
print(soup.find('b')) # 返回<b class="bcl1" id="“b1”">我是第一个段落</b>,只要找到一个即返回
# 第二个参数attrs,可以指定参数名字,也可以不指定
print(soup.find('b', 'bcl1')) # <b class="bcl1" id="“b1”">我是第一个段落</b>
print(soup.find(id="myTitle")) # <title id="myTitle">I’m the title</title>
print(soup.find("b", attrs={"class": "bcl1"})) # <b class="bcl1" id="“b1”">我是第一个段落</b>
print(soup.find(id=True)) # 匹配到第一个<title id="myTitle">I’m the title</title>
# 第三个参数recursive 默认True 如果只想搜索tag的直接子节点,可以使用参数 recursive=False
print(soup.html.find("title", recursive=False)) # None recursive=False。找html的直接子节点,是head,所以找不到title
# 第四个参数string
print(soup.find('div', string='str')) # [<div id="dv1">str</div>]
print(soup.find(string=re.compile("我是第二个"))) # 我是第二个段落3.4.3、find_parents() 和 find_parent()
find_parents() 和 find_parent() 用来搜索当前节点的父辈节点。
语法:
find_parents( name , attrs , recursive , string , **kwargs )
find_parent( name , attrs , recursive , string , **kwargs )
3.4.4、find_next_siblings() 和 find_next_sibling()
find_next_siblings() 方法返回所有符合条件的后面的兄弟节点,find_next_sibling() 只返回符合条件的后面的第一个tag节点;
语法:
find_next_siblings( name , attrs , recursive , string , **kwargs )
find_next_sibling( name , attrs , recursive , string , **kwargs )
3.4.5、find_previous_siblings() 和 find_previous_sibling()
通过 .previous_siblings 属性对当前tag的前面解析。find_previous_siblings() 方法返回所有符合条件的前面的兄弟节点,find_previous_sibling() 方法返回第一个符合条件的前面的兄弟节点;
语法:
find_previous_siblings( name , attrs , recursive , string , **kwargs )
find_previous_sibling( name , attrs , recursive , string , **kwargs )
3.4.6、find_all_next() 和 find_next()
find_all_next() 方法返回所有符合条件的节点,find_next() 方法返回第一个符合条件的节点。
语法:
find_all_next( name , attrs , recursive , string , **kwargs )
find_next( name , attrs , recursive , string , **kwargs )
3.4.7、find_all_previous() 和 find_previous()
find_all_previous() 方法返回所有符合条件的节点元素,find_previous() 方法返回第一个符合条件的节点元素。
语法:
find_all_previous( name , attrs , recursive , string , **kwargs )
find_previous( name , attrs , recursive , string , **kwargs )
这些其实和前面的属性用法类似,但是比属性又多了像find_all()一样的参数。这里就不再详细介绍了,可以看官网的API。
3.4.8、CSS选择器查找
Beautiful Soup支持大部分的CSS选择器,在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数, 即可使用CSS选择器的语法找到tag。
使用案例:
from bs4 import BeautifulSoup
import re
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title id="myTitle">I’m the title</title>
</head>
<body>
<div>
<p>
<b id=“b1” class="bcl1">我是第一个段落</b><b>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b>
</p>
<a href="www.temp.com">我是一个链接<h3>h3</h3></a>
<div id="dv1">str</div>
</div>
</body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
print(soup.select("html head title")) # [<title id="myTitle">I’m the title</title>]
print(soup.select("body a")) # [<a href="www.temp.com">我是一个链接<h3>h3</h3></a>]
print(soup.select("#dv1")) # [<div id="dv1">str</div>]
3.5、对象的属性和方法-修改文档树
3.5.1、修改tag的名称和属性
使用案例:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', "html5lib")
tag = soup.b
tag.name = "blockquote"
print(tag) # <blockquote class="boldest">Extremely bold</blockquote>
tag['class'] = 'veryBold'
tag['id'] = 1
print(tag) # <blockquote class="veryBold" id="1">Extremely bold</blockquote>
del tag['id'] # 删除属性3.5.2、修改 .string
tag的 .string 属性赋值,就相当于用当前的标签中的内容
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', "html5lib")
tag = soup.b
tag.string = "replace"
print(tag) # <b class="boldest">replace</b>3.5.3、append()
向tag中添加内容
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', "html5lib")
tag = soup.b
tag.append(" append")
print(tag) # <b class="boldest">Extremely bold append</b>3.5.4、NavigableString() 和 .new_tag()
from bs4 import BeautifulSoup, NavigableString, Comment
soup = BeautifulSoup('<div><b class="boldest">Extremely bold</b></div>', "html5lib")
tag = soup.div
new_string = NavigableString('NavigableString')
tag.append(new_string)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString</div>
new_comment = soup.new_string("Nice to see you.", Comment)
tag.append(new_comment)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString<!--Nice to see you.--></div>
# 添加标签,推荐使用工厂方法new_tag
new_tag = soup.new_tag("a", href="http://www.example.com")
tag.append(new_tag)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString<!--Nice to see you.--><a href="http://www.example.com"></a></div>
3.5.5、insert()
把元素插入到指定的位置
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup,"html5lib")
tag = soup.a
tag.insert(1, "but did not endorse ") # 和append的区别就是.contents属性获取不一致
print(tag) # <a href="http://example.com/">I linked to but did not endorse <i>example.com</i></a>
print(tag.contents) # ['I linked to ', 'but did not endorse ', <i>example.com</i>]3.5.6、insert_before() 和 insert_after()
当前tag或文本节点前/后插入内容
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to</a>'
soup = BeautifulSoup(markup, "html5lib")
tag = soup.new_tag("i")
tag.string = "Don't"
soup.a.string.insert_before(tag)
print(soup.a) # <a href="http://example.com/"><i>Don't</i>I linked to</a>
soup.a.i.insert_after(soup.new_string(" ever "))
print(soup.a) # <a href="http://example.com/"><i>Don't</i> ever I linked to</a>
3.5.7、clear()
移除当前tag的内容
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to</a>'
soup = BeautifulSoup(markup, "html5lib")
tag = soup.a
tag.clear()
print(tag) # <a href="http://example.com/"></a>3.5.8、extract()
将当前tag移除文档树,并作为方法结果返回
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
a_tag = soup.a
i_tag = soup.i.extract()
print(a_tag) # <a href="http://example.com/">I linked to </a>
print(i_tag) # <i>example.com</i> 我们移除的内容3.5.9、decompose()
将当前节点移除文档树并完全销毁
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
a_tag = soup.a
soup.i.decompose()
print(a_tag) # <a href="http://example.com/">I linked to </a>3.5.10、replace_with()
移除文档树中的某段内容,并用新tag或文本节点替代它
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
new_tag = soup.new_tag("b")
new_tag.string = "example.net"
soup.a.i.replace_with(new_tag)
print(soup.a) # <a href="http://example.com/">I linked to <b>example.net</b></a>
3.5.11、wrap()和unwrap()
wrap()对指定的tag元素进行包装,unwrap()移除tag内的所有tag标签,该方法常被用来进行标记的解包
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
a_tag = soup.a
a_tag.i.unwrap()
print(a_tag) # <a href="http://example.com/">I linked to example.com</a>
soup2 = BeautifulSoup("<p>I wish I was bold.</p>", "html5lib")
soup2.p.string.wrap(soup2.new_tag("b"))
print(soup2.p) # <p><b>I wish I was bold.</b></p>3.6、输出
3.6.1、格式化输出
prettify() 方法将Beautiful Soup的文档树格式化后以Unicode编码输出,每个XML/HTML标签都独占一行。
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
print(soup) # <html><head></head><body><a href="http://example.com/">I linked to <i>example.com</i></a></body></html>
print(soup.prettify()) #<html>
# <head>
# </head>
# <body>
# <a href="http://example.com/">
# I linked to
# <i>
# example.com
# </i>
# </a>
# </body>
# </html>3.6.2、压缩输出
如果只想得到结果字符串,不重视格式,那么可以对一个 BeautifulSoup 对象或 Tag 对象使用Python的str() 方法。
3.6.3、get_text()只输出tag中的文本内容
如果只想得到tag中包含的文本内容,那么可以调用 get_text() 方法。
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to <i>example.com</i>点我</a>'
soup = BeautifulSoup(markup, "html5lib")
print(soup) # <html><head></head><body><a href="http://example.com/">I linked to <i>example.com</i></a></body></html>
print(str(soup)) # <html><head></head><body><a href="http://example.com/">I linked to <i>example.com</i>点我</a></body></html>
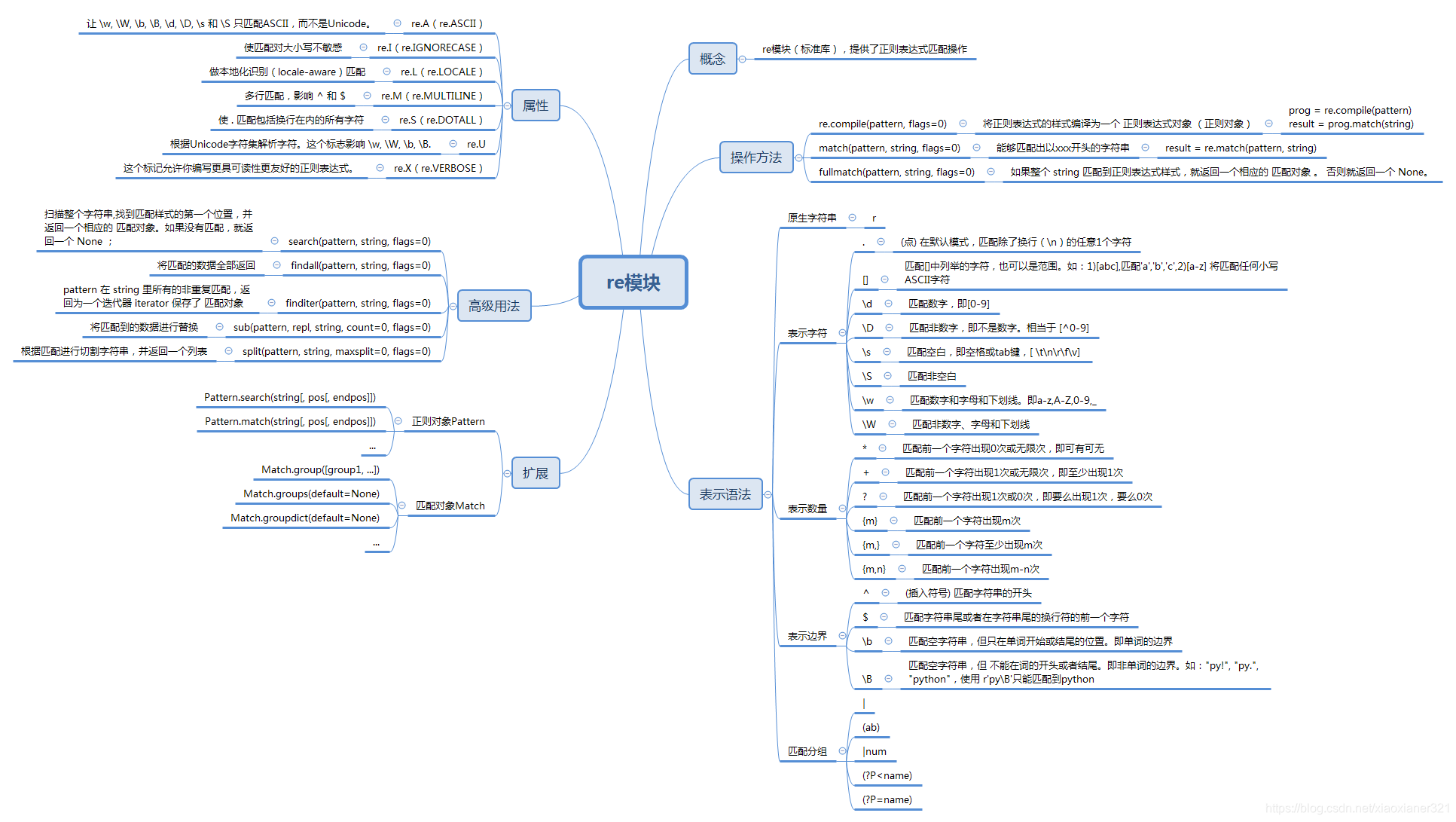
print(soup.get_text()) # I linked to example.com4、re标准库(模块)
BeautifulSoup库,重html文档中筛选我们想要的数据,但这些数据可能还有很多更细致的内容,比如,我们取到的是不是我们想要的链接、是不是我们需要提取的邮箱数据等等,为了更细致精确的提取数据,那么正则来了。
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在其他语言中,我们也经常会接触到正则表达式。
使用案例:
import re
# 创建正则对象
pat = re.compile('\d{2}') #出现2次数字的
# search 在任意位置对给定的正则表达式模式搜索第一次出现的匹配情况
s = pat.search("12abc")
print(s.group()) # 12
# match 从字符串起始部分对模式进行匹配
m = pat.match('1224abc')
print(m.group()) # 12
# search 和 match 的区别 匹配的位置不也一样
s1 = re.search('foo', 'bfoo').group()
print(s1) # foo
try:
m1 = re.match('foo','bfoo').group() # AttributeError
except:
print('匹配失败') # 匹配失败
# 原生字符串(\B 不是以py字母结尾的)
allList = ["py!", "py.", "python"]
for li in allList:
# re.match(正则表达式,要匹配的字符串)
if re.match(r'py\B', li):
print(li) # python
# findall()
s = "apple Apple APPLE"
print(re.findall(r'apple', s)) # ['apple']
print(re.findall(r'apple', s, re.I)) # ['apple', 'Apple', 'APPLE']
# sub()查找并替换
print(re.sub('a', 'A', 'abcdacdl')) # AbcdAcdl
5、实践案例
我们以豆瓣https://movie.douban.com/top250网站为例,去爬取电影信息。
5.1、第一步使用urllib库获取网页
首先,我们分析一下这个网页的结构,是一个还算比较规则的网页,每页25条,一共10页。
我们点击第一页:url = https://movie.douban.com/top250?start=0&filter=
我们点击第二页:url = https://movie.douban.com/top250?start=25&filter=
我们点击第三页:url = https://movie.douban.com/top250?start=50&filter=
import urllib.request, urllib.error
# 定义基础url,发现规律,每页最后变动的是start=后面的数字
baseurl = "https://movie.douban.com/top250?start="
# 定义一个函数getHtmlByURL,得到指定url网页的内容
def geturl(url):
# 自定义headers(伪装,告诉豆瓣服务器,我们是什么类型的机器,以免被反爬虫)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
# 利用Request类来构造自定义头的请求
req = urllib.request.Request(url, headers=headers)
# 定义一个接收变量,用于接收
html = ""
try:
# urlopen()方法的参数,发送给服务器并接收响应
resp = urllib.request.urlopen(req)
# urlopen()获取页面内容,返回的数据格式为bytes类型,需要decode()解码,转换成str类型
html = resp.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
def main():
print(geturl(baseurl + "0"))
if __name__ == "__main__":
main()第一步:我们已经成功获取到了指定的网页内容;
5.2、第二步使用BeautifulSoup和re库解析数据
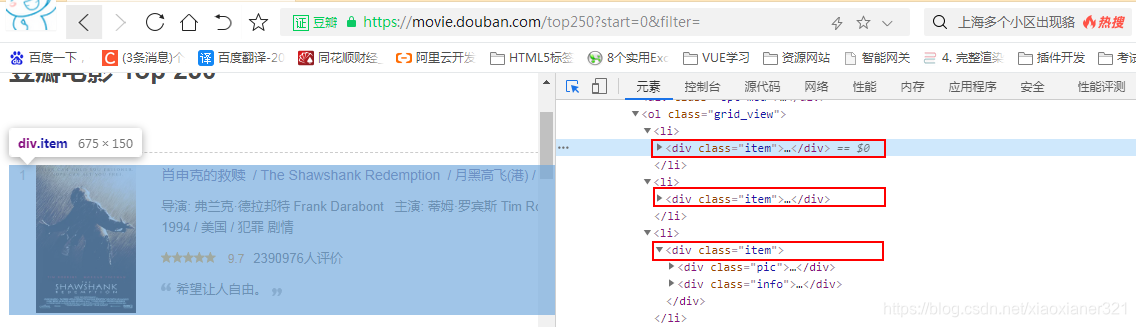
5.2.1、定位数据块
我们发现,我们需要的数据都在<li></li>标签中一个叫<div class="item"></div>中
import urllib.request, urllib.error
from bs4 import BeautifulSoup
import re
# 定义基础url,发现规律,每页最后变动的是start=后面的数字
baseurl = "https://movie.douban.com/top250?start="
# 定义一个函数getHtmlByURL,得到指定url网页的内容
def geturl(url):
# 自定义headers(伪装,告诉豆瓣服务器,我们是什么类型的机器,以免被反爬虫)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
# 利用Request类来构造自定义头的请求
req = urllib.request.Request(url, headers=headers)
# 定义一个接收变量,用于接收
html = ""
try:
# urlopen()方法的参数,发送给服务器并接收响应
resp = urllib.request.urlopen(req)
# urlopen()获取页面内容,返回的数据格式为bytes类型,需要decode()解码,转换成str类型
html = resp.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 定义一个函数,并解析这个网页
def analysisData(url):
# 获取指定网页
html = geturl(url)
# 指定解析器解析html,得到BeautifulSoup对象
soup = BeautifulSoup(html, "html5lib")
# 定位我们的数据块在哪
for item in soup.findAll('div', class_="item"):
print(item)
return ""
def main():
print(analysisData(baseurl + "0"))
if __name__ == "__main__":
main()输出的第一个数据块:
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
</a>
</div>
<div class="info">
<div class="hd">
<a class="" href="https://movie.douban.com/subject/1292052/">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span content="10.0" property="v:best"></span>
<span>2390982人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
<div class="item">5.2.2、使用正则解析数据块
import urllib.request, urllib.error
from bs4 import BeautifulSoup
import re
# 定义基础url,发现规律,每页最后变动的是start=后面的数字
baseurl = "https://movie.douban.com/top250?start="
# 定义一个函数getHtmlByURL,得到指定url网页的内容
def geturl(url):
# 自定义headers(伪装,告诉豆瓣服务器,我们是什么类型的机器,以免被反爬虫)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
# 利用Request类来构造自定义头的请求
req = urllib.request.Request(url, headers=headers)
# 定义一个接收变量,用于接收
html = ""
try:
# urlopen()方法的参数,发送给服务器并接收响应
resp = urllib.request.urlopen(req)
# urlopen()获取页面内容,返回的数据格式为bytes类型,需要decode()解码,转换成str类型
html = resp.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 定义正则对象获取指定的内容
# 提取链接(链接的格式都是<a href="开头的)
findLink = re.compile(r'<a href="(.*?)">')
# 提取图片
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S让 '.' 特殊字符匹配任何字符,包括换行符;
# 提取影片名称
findTitle = re.compile(r'<span class="title">(.*)</span>')
# 提取影片评分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# 提取评价人数
findJudge = re.compile(r'<span>(\d*)人评价</span>')
# 提取简介
inq = re.compile(r'<span class="inq">(.*)</span>')
# 提取相关内容
findBd = re.compile(r'<p class="">(.*)</p>(.*)<div', re.S)
# 定义一个函数,并解析这个网页
def analysisData(baseurl):
# 获取指定网页
html = geturl(baseurl)
# 指定解析器解析html,得到BeautifulSoup对象
soup = BeautifulSoup(html, "html5lib")
dataList = []
# 定位我们的数据块在哪
for item in soup.find_all('div', class_="item"):
# item 是 bs4.element.Tag 对象,这里将其转换成字符串来处理
item = str(item)
# 定义一个列表 来存储每一个电影解析的内容
data = []
# findall返回的是一个列表,这里提取链接
link = re.findall(findLink, item)[0]
data.append(link) # 添加链接
img = re.findall(findImgSrc, item)[0]
data.append(img) # 添加图片链接
title = re.findall(findTitle, item)
# 一般都有一个中文名 一个外文名
if len(title) == 2:
# ['肖申克的救赎', '\xa0/\xa0The Shawshank Redemption']
titlename = title[0] + title[1].replace(u'\xa0', '')
else:
titlename = title[0] + ""
data.append(titlename) # 添加标题
pf = re.findall(findRating, item)[0]
data.append(pf)
pjrs = re.findall(findJudge, item)[0]
data.append(pjrs)
# 有的可能没有
inqInfo = re.findall(inq, item)
if len(inqInfo) == 0:
data.append(" ")
else:
data.append(inqInfo[0])
bd = re.findall(findBd, item)[0]
# [('\n 导演: 弗兰克·德拉邦特 Frank Darabont\xa0\xa0\xa0主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>\n 1994\xa0/\xa0美国\xa0/\xa0犯罪 剧情\n ', '\n\n \n ')]
bd[0].replace(u'\xa0', '').replace('<br/>', '')
bd = re.sub('<\\s*b\\s*r\\s*/\\s*>', "", bd[0])
bd = re.sub('(\\s+)?', '', bd)
data.append(bd)
dataList.append(data)
return dataList
def main():
print(analysisData(baseurl + "0"))
if __name__ == "__main__":
main()
第一页解析结果:后面需要对analysisData稍加改造,将豆瓣Top250的10页进行处理
[['https://movie.douban.com/subject/1292052/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg', '肖申克的救赎/The Shawshank Redemption', '9.7', '2391074', '希望让人自由。', '导演:弗兰克·德拉邦特FrankDarabont主演:蒂姆·罗宾斯TimRobbins/...1994/美国/犯罪剧情'],
['https://movie.douban.com/subject/1291546/', 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2561716440.jpg', '霸王别姬', '9.6', '1780355', '风华绝代。', '导演:陈凯歌KaigeChen主演:张国荣LeslieCheung/张丰毅FengyiZha...1993/中国大陆中国香港/剧情爱情同性'],
['https://movie.douban.com/subject/1292720/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2372307693.jpg', '阿甘正传/Forrest Gump', '9.5', '1800723', '一部美国近现代史。', '导演:罗伯特·泽米吉斯RobertZemeckis主演:汤姆·汉克斯TomHanks/...1994/美国/剧情爱情'],
['https://movie.douban.com/subject/1295644/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p511118051.jpg', '这个杀手不太冷/Léon', '9.4', '1971155', '怪蜀黍和小萝莉不得不说的故事。', '导演:吕克·贝松LucBesson主演:让·雷诺JeanReno/娜塔莉·波特曼...1994/法国美国/剧情动作犯罪'],
['https://movie.douban.com/subject/1292722/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p457760035.jpg', '泰坦尼克号/Titanic', '9.4', '1762280', '失去的才是永恒的。 ', '导演:詹姆斯·卡梅隆JamesCameron主演:莱昂纳多·迪卡普里奥Leonardo...1997/美国墨西哥澳大利亚加拿大/剧情爱情灾难'],
['https://movie.douban.com/subject/1292063/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2578474613.jpg', '美丽人生/La vita è bella', '9.6', '1105760', '最美的谎言。', '导演:罗伯托·贝尼尼RobertoBenigni主演:罗伯托·贝尼尼RobertoBeni...1997/意大利/剧情喜剧爱情战争'],
['https://movie.douban.com/subject/1291561/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2557573348.jpg', '千与千寻/千と千尋の神隠し', '9.4', '1877996', '最好的宫崎骏,最好的久石让。 ', '导演:宫崎骏HayaoMiyazaki主演:柊瑠美RumiHîragi/入野自由Miy...2001/日本/剧情动画奇幻'],
['https://movie.douban.com/subject/1295124/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p492406163.jpg', "辛德勒的名单/Schindler's List", '9.5', '918645', '拯救一个人,就是拯救整个世界。', '导演:史蒂文·斯皮尔伯格StevenSpielberg主演:连姆·尼森LiamNeeson...1993/美国/剧情历史战争'],
['https://movie.douban.com/subject/3541415/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2616355133.jpg', '盗梦空间/Inception', '9.3', '1734973', '诺兰给了我们一场无法盗取的梦。', '导演:克里斯托弗·诺兰ChristopherNolan主演:莱昂纳多·迪卡普里奥Le...2010/美国英国/剧情科幻悬疑冒险'],
['https://movie.douban.com/subject/3011091/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p524964039.jpg', "忠犬八公的故事/Hachi: A Dog's Tale", '9.4', '1192778', '永远都不能忘记你所爱的人。', '导演:莱塞·霍尔斯道姆LasseHallström主演:理查·基尔RichardGer...2009/美国英国/剧情'],
['https://movie.douban.com/subject/1889243/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2614988097.jpg', '星际穿越/Interstellar', '9.3', '1408128', '爱是一种力量,让我们超越时空感知它的存在。', '导演:克里斯托弗·诺兰ChristopherNolan主演:马修·麦康纳MatthewMc...2014/美国英国加拿大/剧情科幻冒险'],
['https://movie.douban.com/subject/1292064/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p479682972.jpg', '楚门的世界/The Truman Show', '9.3', '1325913', '如果再也不能见到你,祝你早安,午安,晚安。', '导演:彼得·威尔PeterWeir主演:金·凯瑞JimCarrey/劳拉·琳妮Lau...1998/美国/剧情科幻'],
['https://movie.douban.com/subject/1292001/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2574551676.jpg', "海上钢琴师/La leggenda del pianista sull'oceano", '9.3', '1409712', '每个人都要走一条自己坚定了的路,就算是粉身碎骨。 ', '导演:朱塞佩·托纳多雷GiuseppeTornatore主演:蒂姆·罗斯TimRoth/...1998/意大利/剧情音乐'],
['https://movie.douban.com/subject/3793023/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p579729551.jpg', '三傻大闹宝莱坞/3 Idiots', '9.2', '1583056', '英俊版憨豆,高情商版谢耳朵。', '导演:拉库马·希拉尼RajkumarHirani主演:阿米尔·汗AamirKhan/卡...2009/印度/剧情喜剧爱情歌舞'],
['https://movie.douban.com/subject/2131459/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p1461851991.jpg', '机器人总动员/WALL·E', '9.3', '1113357', '小瓦力,大人生。', '导演:安德鲁·斯坦顿AndrewStanton主演:本·贝尔特BenBurtt/艾丽...2008/美国/科幻动画冒险'],
['https://movie.douban.com/subject/1291549/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p1910824951.jpg', '放牛班的春天/Les choristes', '9.3', '1098339', '天籁一般的童声,是最接近上帝的存在。 ', '导演:克里斯托夫·巴拉蒂ChristopheBarratier主演:热拉尔·朱尼奥Gé...2004/法国瑞士德国/剧情喜剧音乐'],
['https://movie.douban.com/subject/1307914/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2564556863.jpg', '无间道/無間道', '9.3', '1074152', '香港电影史上永不过时的杰作。', '导演:刘伟强/麦兆辉主演:刘德华/梁朝伟/黄秋生2002/中国香港/剧情犯罪惊悚'],
['https://movie.douban.com/subject/25662329/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2614500649.jpg', '疯狂动物城/Zootopia', '9.2', '1555912', '迪士尼给我们营造的乌托邦就是这样,永远善良勇敢,永远出乎意料。', '导演:拜伦·霍华德ByronHoward/瑞奇·摩尔RichMoore主演:金妮弗·...2016/美国/喜剧动画冒险'],
['https://movie.douban.com/subject/1292213/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2455050536.jpg', '大话西游之大圣娶亲/西遊記大結局之仙履奇緣', '9.2', '1283551', '一生所爱。', '导演:刘镇伟JeffreyLau主演:周星驰StephenChow/吴孟达ManTatNg...1995/中国香港中国大陆/喜剧爱情奇幻古装'],
['https://movie.douban.com/subject/5912992/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p1363250216.jpg', '熔炉/도가니', '9.3', '778782', '我们一路奋战不是为了改变世界,而是为了不让世界改变我们。', '导演:黄东赫Dong-hyukHwang主演:孔侑YooGong/郑有美Yu-miJung/...2011/韩国/剧情'],
['https://movie.douban.com/subject/1291841/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p616779645.jpg', '教父/The Godfather', '9.3', '781422', '千万不要记恨你的对手,这样会让你失去理智。', '导演:弗朗西斯·福特·科波拉FrancisFordCoppola主演:马龙·白兰度M...1972/美国/剧情犯罪'],
['https://movie.douban.com/subject/1849031/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2614359276.jpg', '当幸福来敲门/The Pursuit of Happyness', '9.1', '1273152', '平民励志片。 ', '导演:加布里尔·穆奇诺GabrieleMuccino主演:威尔·史密斯WillSmith...2006/美国/剧情传记家庭'],
['https://movie.douban.com/subject/1291560/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2540924496.jpg', '龙猫/となりのトトロ', '9.2', '1062785', '人人心中都有个龙猫,童年就永远不会消失。', '导演:宫崎骏HayaoMiyazaki主演:日高法子NorikoHidaka/坂本千夏Ch...1988/日本/动画奇幻冒险'],
['https://movie.douban.com/subject/3319755/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p501177648.jpg', '怦然心动/Flipped', '9.1', '1511459', '真正的幸福是来自内心深处。', '导演:罗伯·莱纳RobReiner主演:玛德琳·卡罗尔MadelineCarroll/卡...2010/美国/剧情喜剧爱情'],
['https://movie.douban.com/subject/1296141/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p1505392928.jpg', '控方证人/Witness for the Prosecution', '9.6', '378892', '比利·怀德满分作品。', '导演:比利·怀尔德BillyWilder主演:泰隆·鲍华TyronePower/玛琳·...1957/美国/剧情犯罪悬疑']]
5.3、将数据导出excel
import urllib.request, urllib.error
from bs4 import BeautifulSoup
import re
import xlwt
# 定义基础url,发现规律,每页最后变动的是start=后面的数字
baseurl = "https://movie.douban.com/top250?start="
# 定义一个函数getHtmlByURL,得到指定url网页的内容
def geturl(url):
# 自定义headers(伪装,告诉豆瓣服务器,我们是什么类型的机器,以免被反爬虫)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
# 利用Request类来构造自定义头的请求
req = urllib.request.Request(url, headers=headers)
# 定义一个接收变量,用于接收
html = ""
try:
# urlopen()方法的参数,发送给服务器并接收响应
resp = urllib.request.urlopen(req)
# urlopen()获取页面内容,返回的数据格式为bytes类型,需要decode()解码,转换成str类型
html = resp.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 定义正则对象获取指定的内容
# 提取链接(链接的格式都是<a href="开头的)
findLink = re.compile(r'<a href="(.*?)">')
# 提取图片
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S让 '.' 特殊字符匹配任何字符,包括换行符;
# 提取影片名称
findTitle = re.compile(r'<span class="title">(.*)</span>')
# 提取影片评分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# 提取评价人数
findJudge = re.compile(r'<span>(\d*)人评价</span>')
# 提取简介
inq = re.compile(r'<span class="inq">(.*)</span>')
# 提取相关内容
findBd = re.compile(r'<p class="">(.*)</p>(.*)<div', re.S)
# 定义接收10页的列表
dataList = []
# 定义一个函数,并解析这个网页
def analysisData(baseurl):
# 获取指定网页
for i in range(0, 10): # 获取网页选项的函数,10次
url = baseurl + str(i * 25)
html = geturl(url)
# 指定解析器解析html,得到BeautifulSoup对象
soup = BeautifulSoup(html, "html5lib")
# 定位我们的数据块在哪
for item in soup.find_all('div', class_="item"):
# item 是 bs4.element.Tag 对象,这里将其转换成字符串来处理
item = str(item)
# 定义一个列表 来存储每一个电影解析的内容
data = []
# findall返回的是一个列表,这里提取链接
link = re.findall(findLink, item)[0]
data.append(link) # 添加链接
img = re.findall(findImgSrc, item)[0]
data.append(img) # 添加图片链接
title = re.findall(findTitle, item)
# 一般都有一个中文名 一个外文名
if len(title) == 2:
# ['肖申克的救赎', '\xa0/\xa0The Shawshank Redemption']
titlename = title[0] + title[1].replace(u'\xa0', '')
else:
titlename = title[0] + ""
data.append(titlename) # 添加标题
pf = re.findall(findRating, item)[0]
data.append(pf)
pjrs = re.findall(findJudge, item)[0]
data.append(pjrs)
inqInfo = re.findall(inq, item)
if len(inqInfo) == 0:
data.append(" ")
else:
data.append(inqInfo[0])
bd = re.findall(findBd, item)[0]
# [('\n 导演: 弗兰克·德拉邦特 Frank Darabont\xa0\xa0\xa0主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>\n 1994\xa0/\xa0美国\xa0/\xa0犯罪 剧情\n ', '\n\n \n ')]
bd[0].replace(u'\xa0', '').replace('<br/>', '')
bd = re.sub('<\\s*b\\s*r\\s*/\\s*>', "", bd[0])
bd = re.sub('(\\s+)?', '', bd)
data.append(bd)
dataList.append(data)
return dataList
def main():
analysisData(baseurl)
savepath = "C:\\Users\\Administrator\\Desktop\\python_3.8.5\\豆瓣250.xls"
book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建Workbook对象
sheet = book.add_sheet("豆瓣电影Top250", cell_overwrite_ok=True) # 创建工作表
col = ("电影详情链接", "图片链接", "电影中/外文名", "评分", "评论人数", "概况", "相关信息")
print(len(dataList))
for i in range(0, 7):
sheet.write(0, i, col[i])
for i in range(0, 250):
print('正在保存第'+str((i+1))+'条')
data = dataList[i]
for j in range(len(data)):
sheet.write(i + 1, j, data[j])
book.save(savepath)
if __name__ == "__main__":
main()
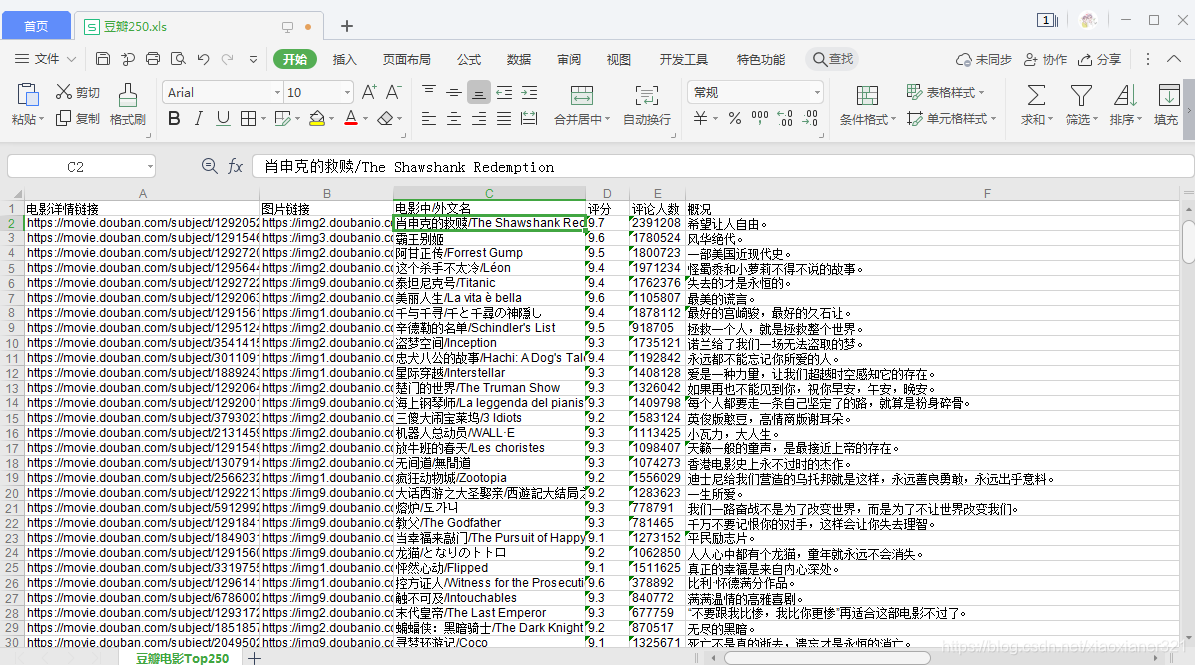
最终效果: