SpringBoot学习系列(十一)------SpringBoot访问数据库
前言
在项目开发中,数据库的访问是必不可少的,对于数据访问层,无论是SQL还是NoSql,SpringBoot默认采用整合Spring Data的方式进行统一处理,添加了大量的自动配置,屏蔽了很多设置.引入各种Template或Repository来简化我们对数据访问层的操作,对我们来说只需要进行简单的设置即可.
正文
1.使用IDEA构建一个简单的SpringBoot应用
我们先用IDEA创建一个SringBoot应用,引入web组件,jdbc组件
2.使用jdbc
在SpringBoot的配置文件中配置好数据源,我们就可以查看默认的数据库连接:
spring.datasource.url = jdbc:mysql://127.0.0.1:3306/tale?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8
spring.datasource.username = root
spring.datasource.password = 123456
spring.datasource.driverClassName = com.mysql.jdbc.Driver
在测试类中测试连接:
@Autowired
DataSource dataSource;
@Test
public void contextLoads() throws SQLException {
System.out.println(dataSource.getClass());
Connection connection = dataSource.getConnection();
System.out.println(connection);
connection.close();
}
可以看到控制台打印:
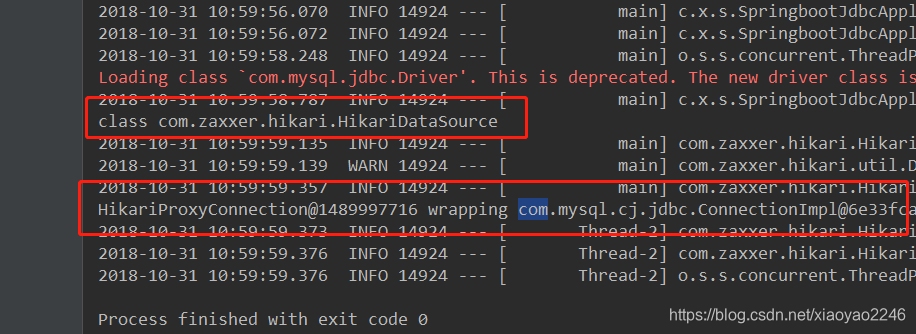
可以看到,SpringBoot2.0+使用的默认数据源是:com.zaxxer.hikari.HikariDataSource
它还支持以下数据源:dbcp2,tomcat
我们查看DataSourceConfiguration这个类,可以看到它还支持自定义数据源:
abstract class DataSourceConfiguration {
DataSourceConfiguration() {
}
protected static <T> T createDataSource(DataSourceProperties properties, Class<? extends DataSource> type) {
return properties.initializeDataSourceBuilder().type(type).build();
}
@ConditionalOnMissingBean({DataSource.class})
@ConditionalOnProperty(
name = {"spring.datasource.type"}
)
static class Generic {
Generic() {
}
@Bean
public DataSource dataSource(DataSourceProperties properties) {
return properties.initializeDataSourceBuilder().build();
}
}
@ConditionalOnClass({BasicDataSource.class})
@ConditionalOnMissingBean({DataSource.class})
@ConditionalOnProperty(
name = {"spring.datasource.type"},
havingValue = "org.apache.commons.dbcp2.BasicDataSource",
matchIfMissing = true
)
static class Dbcp2 {
Dbcp2() {
}
@Bean
@ConfigurationProperties(
prefix = "spring.datasource.dbcp2"
)
public BasicDataSource dataSource(DataSourceProperties properties) {
return (BasicDataSource)DataSourceConfiguration.createDataSource(properties, BasicDataSource.class);
}
}
@ConditionalOnClass({HikariDataSource.class})
@ConditionalOnMissingBean({DataSource.class})
@ConditionalOnProperty(
name = {"spring.datasource.type"},
havingValue = "com.zaxxer.hikari.HikariDataSource",
matchIfMissing = true
)
static class Hikari {
Hikari() {
}
@Bean
@ConfigurationProperties(
prefix = "spring.datasource.hikari"
)
public HikariDataSource dataSource(DataSourceProperties properties) {
HikariDataSource dataSource = (HikariDataSource)DataSourceConfiguration.createDataSource(properties, HikariDataSource.class);
if (StringUtils.hasText(properties.getName())) {
dataSource.setPoolName(properties.getName());
}
return dataSource;
}
}
@ConditionalOnClass({org.apache.tomcat.jdbc.pool.DataSource.class})
@ConditionalOnMissingBean({DataSource.class})
@ConditionalOnProperty(
name = {"spring.datasource.type"},
havingValue = "org.apache.tomcat.jdbc.pool.DataSource",
matchIfMissing = true
)
static class Tomcat {
Tomcat() {
}
@Bean
@ConfigurationProperties(
prefix = "spring.datasource.tomcat"
)
public org.apache.tomcat.jdbc.pool.DataSource dataSource(DataSourceProperties properties) {
org.apache.tomcat.jdbc.pool.DataSource dataSource = (org.apache.tomcat.jdbc.pool.DataSource)DataSourceConfiguration.createDataSource(properties, org.apache.tomcat.jdbc.pool.DataSource.class);
DatabaseDriver databaseDriver = DatabaseDriver.fromJdbcUrl(properties.determineUrl());
String validationQuery = databaseDriver.getValidationQuery();
if (validationQuery != null) {
dataSource.setTestOnBorrow(true);
dataSource.setValidationQuery(validationQuery);
}
return dataSource;
}
}
}
它的自定义数据源是这样定义的:
@ConditionalOnMissingBean({DataSource.class})
@ConditionalOnProperty(
name = {"spring.datasource.type"}
)
static class Generic {
Generic() {
}
@Bean
public DataSource dataSource(DataSourceProperties properties) {
return properties.initializeDataSourceBuilder().build();
}
}
其次,我们可以将建表以及插入数据的sql脚本放在指定的目录,这样项目在启动的时候会自动建表:
-
默认情况下,将脚本命名为
schema.sql或者schema-all.sql,并放在resource目录下就可以 -
如果要自己指定文件名,需要在配置文件中配置一个属性来指定文件名:
spring: datasource: schema: ‐ classpath:department.sql //该属性的值是个列表,我们可以指定多个文件 //在SPringBoot2.0以后,如果要运行sql脚本 还需要加入下面这个配置 initialization-mode: always
SpringBoot默认整合了JdbcTemplate操作数据库,我们可以直接使用:
@Controller
public class HelloController {
@Autowired
private JdbcTemplate jdbcTemplate;
@ResponseBody
@RequestMapping("/map")
public Map<String, Object> map() {
List<Map<String, Object>> maps = jdbcTemplate.queryForList("select * from t_contents");
for (Map<String, Object> map : maps
) {
System.out.println(map);
}
return maps.get(0);
}
}
页面访问:

3.整合Druid数据源
在日常的项目开发中,我们一般不会是用原生的JDBC来操作数据库,笔主经常遇到的就是我们阿里的Druid,在这里我们也来这个Druid到SpringBoot项目中.
-
引入pom依赖
首先在项目的pom.xml中引入Druid的坐标依赖,可以直接从maven仓库中搜索到.
<!-- https://mvnrepository.com/artifact/com.alibaba/druid --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.10</version> </dependency> -
在application.yml或者properties文件中配置数据源
使用type属性来指定我们使用的数据源
spring: datasource: driver-class-name: com.mysql.jdbc.Driver username: root password: 123456 url: jdbc:mysql://127.0.0.1:3306/tale?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8 type: com.alibaba.druid.pool.DruidDataSource除了这些参数,Druid还提供了很多的属性配置:
initialSize: 5 minIdle: 5 maxActive: 20 maxWait: 60000 timeBetweenEvictionRunsMillis: 60000 minEvictableIdleTimeMillis: 300000 validationQuery: SELECT 1 FROM DUAL testWhileIdle: true testOnBorrow: false testOnReturn: false poolPreparedStatements: true # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 filters: stat,wall,log4j maxPoolPreparedStatementPerConnectionSize: 20 useGlobalDataSourceStat: true connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500当然,如果直接在配置文件中引入这些是不行的,因为默认的属性不会绑定这些参数,我们需要自定定义一个DataSource来绑定参数,可如下操作:
/** * 配置Driud数据源 */ @Configuration public class DruidConfig { @Bean //下面的注解表示将属性文件中前缀是spring.datasource的属性绑定到当前数据源 @ConfigurationProperties(prefix = "spring.datasource") public DataSource druid() { return new DruidDataSource(); } /** * druid的强大在于有一套完整的监控配置,我们可以在这里配置一下,配置druid的后台监控需要配置 * 一个servlet,我们可以直接使用servletRegistrationBean来配置,配置的servlet的名称 * 是statViewServlet, */ @Bean public ServletRegistrationBean statViewServlet() { ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*"); //可以在这个servlet中设置参数来定义后台的一些参数 Map<String, String> initParms = new HashMap<>(); //配置登录用户名 initParms.put("loginUsername", "admin"); //配置密码 initParms.put("loginPassword", "123456"); //配置访问权限,默认是所有都能访问 initParms.put("allow", ""); //配置拒绝访问的ip initParms.put("deny", ""); bean.setInitParameters(initParms); return bean; } /** * 要使用druid的后台监控功能,还可以配置一个filter,它的名称是webStatFilter * */ @Bean public FilterRegistrationBean webStatFilter() { FilterRegistrationBean bean = new FilterRegistrationBean(); bean.setFilter(new WebStatFilter()); Map<String, String> initParms = new HashMap<>(); //不拦截的资源 initParms.put("exclusions", "*.js,*.css,/druid/*"); bean.setInitParameters(initParms); //要拦截的请求 bean.setUrlPatterns(Arrays.asList("/*")); return bean; } }启动项目,访问
localhost:8080/druid,就可以直接跳转到登录页面,使用我们在servlet中配置的账号登录就可以登录Druid的后台了:
4.整合Mybatis
-
使用注解整合Mybatis
首先引入mybatis的maven坐标:
<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.3.1</version> </dependency>创建对应的javeBean和Mapper:
public class User { private int id; private String userName; //省略set,get }/** * 用户表对应的mapper */ @Mapper //mapper注解指定这个接口是mybatis的mapper,且将此接口加入容器 public interface UserMapper { /** * 通过id查询user对象 * @param id 主键 * @return user对象 */ @Select("select * from user where id=#{id}") User queryUserById(int id); @Options(useGeneratedKeys = true, keyProperty = "id") //options用来定义主键返回,keyProperty指定主键对应的属性 @Insert("insert into user (userName) values (#{userName})") int insert(User user); }在controller层定义好对应的映射:
@GetMapping("/user/{id}") @ResponseBody public User queryUser(@PathVariable("id") int id) { User user = userMapper.queryUserById(id); return user; } @GetMapping("/user") @ResponseBody public User insertUser(User user) { userMapper.insert(user); return user; }如上做完以后就可以访问页面了,如果需要配置数据库映射的时候使用驼峰命名的规则,可以自定义一个配置规则:
@org.springframework.context.annotation.Configuration public class MyBatisConfig { @Bean public ConfigurationCustomizer configurationCustomizer(){ return new ConfigurationCustomizer(){ @Override public void customize(Configuration configuration) { configuration.setMapUnderscoreToCamelCase(true); } }; } }如果我们的Mapper文件太多,不想一个个写
@Mapper注解,也可以直接在启动类上使用以下方式来扫描包路径下的所有mapper:@SpringBootApplication @MapperScan(value = "mapper文件所在的包路径, ex:com.xiaojian.mapper") public class SpringbootJdbcApplication { public static void main(String[] args) { SpringApplication.run(SpringbootJdbcApplication.class, args); } } -
使用配置文件整合Mybatis
使用配置文件来整合Mybatis也很简单,只需要将sql定义在xml文件中即可,再写Mybatis的核心配置文件就可以,我们可以在SpringBoot的配置文件中指定Mybatis的配置文件和Mapper映射文件的位置:
mybatis: config‐location: classpath:mybatis/mybatis‐config.xml 指定全局配置文件的位置 mapper‐locations: classpath:mybatis/mapper/*.xml 指定sql映射文件的位置
5.整合JPA
引入jpa相关的pom依赖
-
编写一个实体类和数据库中的表对应
//使用JPA注解配置映射关系 @Entity //告诉JPA这是一个实体类(和数据表映射的类) @Table(name = "tbl_user") //@Table来指定和哪个数据表对应;如果省略默认表名就是user; public class User { @Id //这是一个主键 @GeneratedValue(strategy = GenerationType.IDENTITY)//自增主键 private Integer id; @Column(name = "last_name",length = 50) //这是和数据表对应的一个列 private String lastName; @Column //省略默认列名就是属性名 private String email; -
编写一个xxxRepository接口来操作对应的表
//继承JpaRepository来完成对数据库的操作,JpaRepository继承了CrudRepository和Page类的功能,既可以进行正常的增删改查,也可以进行分页 public interface UserRepository extends JpaRepository<User,Integer> { } -
还需要在配置文件中配置:
spring: jpa: hibernate: # 更新或者创建数据表结构 ddl‐auto: update # 控制台显示SQL show‐sql: true
完成以上配置以后就可以在controller层写对应的方法来操作数据.
总结
SpringBoot对数据访问的问题就记录这些,在实际的运用中,还有一些高级的功能没有说到,以后会逐渐补充~~