目录:
Spring AI 框架介绍
Spring AI 对话模型
Spring AI 图像模型
Spring AI是一个面向人工智能工程的应用框架。它的目标是将Spring生态系统的设计原则(如可移植性和模块化设计)应用于AI领域,并推广使用pojo作为AI领域应用的构建模块。
概述
Spring AI 现在(2024/12)已经支持语言,图像,语音类的生成式AI模型。
GPT类的模型特点是预训练,这种预训练将AI转变为一个通用的开发工具,而不需要广泛的机器学习或模型训练背景。
Prompts
提示词是基于语言的输入的基础,指导人工智能模型产生特定的输出。
制定高效的提示词既是一门艺术,也是一门科学。ChatGPT设计出来是为了与人类对话的。这与使用SQL之类的东西来“问问题”有很大的不同。人们必须像与人交流一样来与AI模型交流。由于这种交互是如此的重要,现在已经出现了“提示词工程”这种术语,专门描述在提示词方面的研究。高效的提示词可以极大提高输出结果的准确性。
分享提示已经变成了公共实践,当前学术界正在积极地研究这个问题。很多提示词是反直觉的,比如最近的一篇研究论文显示,一个非常高效的提示词短语是: “深呼吸,循序渐进地来解决这个问题”。到目前为止,我们还不完全了解如何最有效地利用该技术的前几次迭代,例如ChatGPT 3.5,更不用说最新的版本了。
提示词模版
创建有效的提示涉及建立请求上下文,并用特定于用户输入的值替换请求的部分内容。
在Spring AI中,提示框模板可以比作Spring MVC架构中的“视图”。模型对象,通常是java.util.Map,用于填充模板中的占位符。“渲染”后的字符串成为提供给AI模型的提示的内容。
发送给模型的提示的特定数据格式有很大的变化。提示符最初是简单的字符串,现在已经发展到包括多个消息,其中每个消息中的每个字符串表示模型的一个不同角色。
嵌入
嵌入(Embedding)是一种将文本(如单词、短语、句子或文档)转换为数字向量表示的方法。这种向量化表示捕捉了文本的语义信息,使得模型能够以数学形式理解和操作自然语言。
嵌入的工作原理是将文本、图像和视频转换为称为向量的浮点数数组。嵌入后的向量通常是实数值(如 [0.1, -0.3, 0.7]),这些向量能够反映文本在语义空间中的相对位置。
嵌入的核心目的是捕捉文本的语义关系和上下文信息,从而支持各种NLP任务,例如:
- 语义相似度:两个语义上相近的单词或句子,其嵌入向量在空间中的距离较小。
- 分类和聚类:嵌入向量可以作为特征,用于分类或聚类任务。
- 搜索和推荐:通过计算嵌入之间的距离或相似度,找到相关内容。
在ChatGPT中,嵌入用于以下方面:
- 语言理解:模型将用户输入转化为嵌入,理解语义信息以生成相关回答。
- 知识存储:嵌入帮助模型在回答时调用相关的上下文或知识点。
- 搜索增强:通过嵌入匹配用户输入和知识库中的相关内容,提高生成回答的准确性。
举个例子, 假设模型生成了以下嵌入:
- “猫”:[0.21, -0.19, 0.37, …]
- “狗”:[0.20, -0.18, 0.36, …]
- “桌子”:[0.05, 0.33, -0.15, …]
通过计算余弦相似度或欧几里得距离,可以发现"猫"和"狗"的向量更加相似,而与"桌子"差异较大。
作为探索AI的Java开发人员,没有必要理解这些向量表示背后复杂的数学理论或特定的实现。对它们在AI系统中的角色和功能的基本了解就足够了,特别是当您将AI功能集成到应用程序中时。
Tokens
Tokens是AI模型工作的基石。在输入时,模型将单词转换为tokens,然后在输出时又将tokens转换成单词。
在英语中,一个token大约相当于一个单词的75%。作为参考,莎士比亚全集约90万字,可以翻译成约120万个tokens。
也许更为重要的是,Tokens = Money。在受托管的AI模型的上下文中,你的花费取决于使用的tokens的数量。不管是输入还是输出,都计入token的数量。
另外,模型也有token限制,具体来说就是一次API调用会限制处理的文本的数量。这就是所谓的上下文窗口。如果文本超过这个限制,将不会被模型处理。
举例来说,ChatCPT3 的token限制为4K,GPT4则有多个选择,可以是8K,16K或32K。Anthropic的Claude AI模型具有100K token限制,而Meta最近的研究创建了一个1M token限制的模型。
注意,token的限制是输入和输出一起算的
结构化输出
通常情况下,即使你要求 AI 模型输出JSON格式,但实际上它还是字符串。另外,要求“输出JSON”本身也不是一个准确的提示词。
这种复杂性导致了一个专门领域的出现,包括创建提示以产生预期的输出,然后将生成的简单字符串转换为用于应用程序集成的可用数据结构,如下图所示:
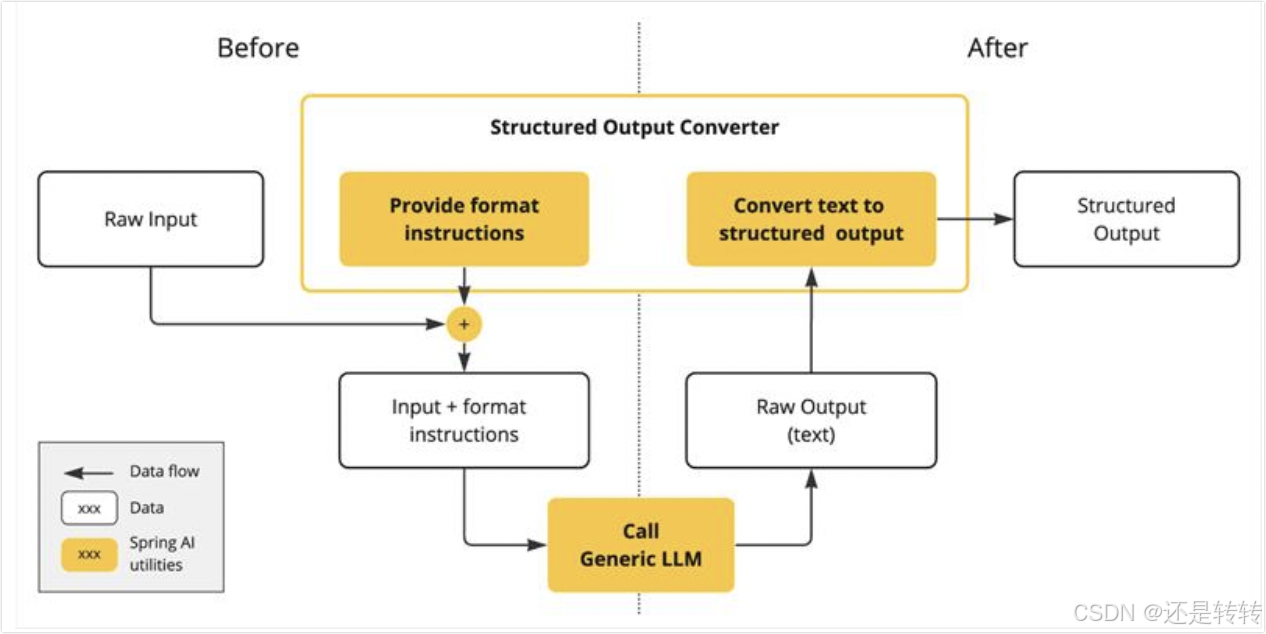
结构化输出转换采用精心设计的提示,通常需要与模型进行多次交互才能实现所需的格式。
训练你的AI模型
如何让AI模型拥有它没有被培训过的知识呢?
GPT3.5和早期的4.0版本的知识库更新到2021年9月。后续的改进版GPT4包含更新到23年10月的知识。某些版本具备实时联网功能,可以获取实时信息。
定制AI模型主要有三种技术手段。
- 微调(Fine Tuning)
在现有大模型的基础上,使用特定领域的数据进行二次训练,以调整模型的权重,提升其在特定任务上的表现。如构建医疗、法律行业的问答系统。但这种方式不适用于GPT这种规模太大的模型。
- 提示填充(Prompt Stuffing)
另外一种比较实际的方案是在提示词中填充你的数据。具体来说,就是将额外信息嵌入到提示中,以改进模型的回答或引导其生成目标输出,比如扩展上下文范围、提供更多相关背景,甚至注入具体的任务指令。
Spring AI 中的提示填充即所谓的RAG(Retrieval Augmented Generation,检索增强生成)
- 函数调用
通过AI模型解释用户的意图并将其映射到与定义的函数接口上,从而触发响应的逻辑或操作。
检索增强生成
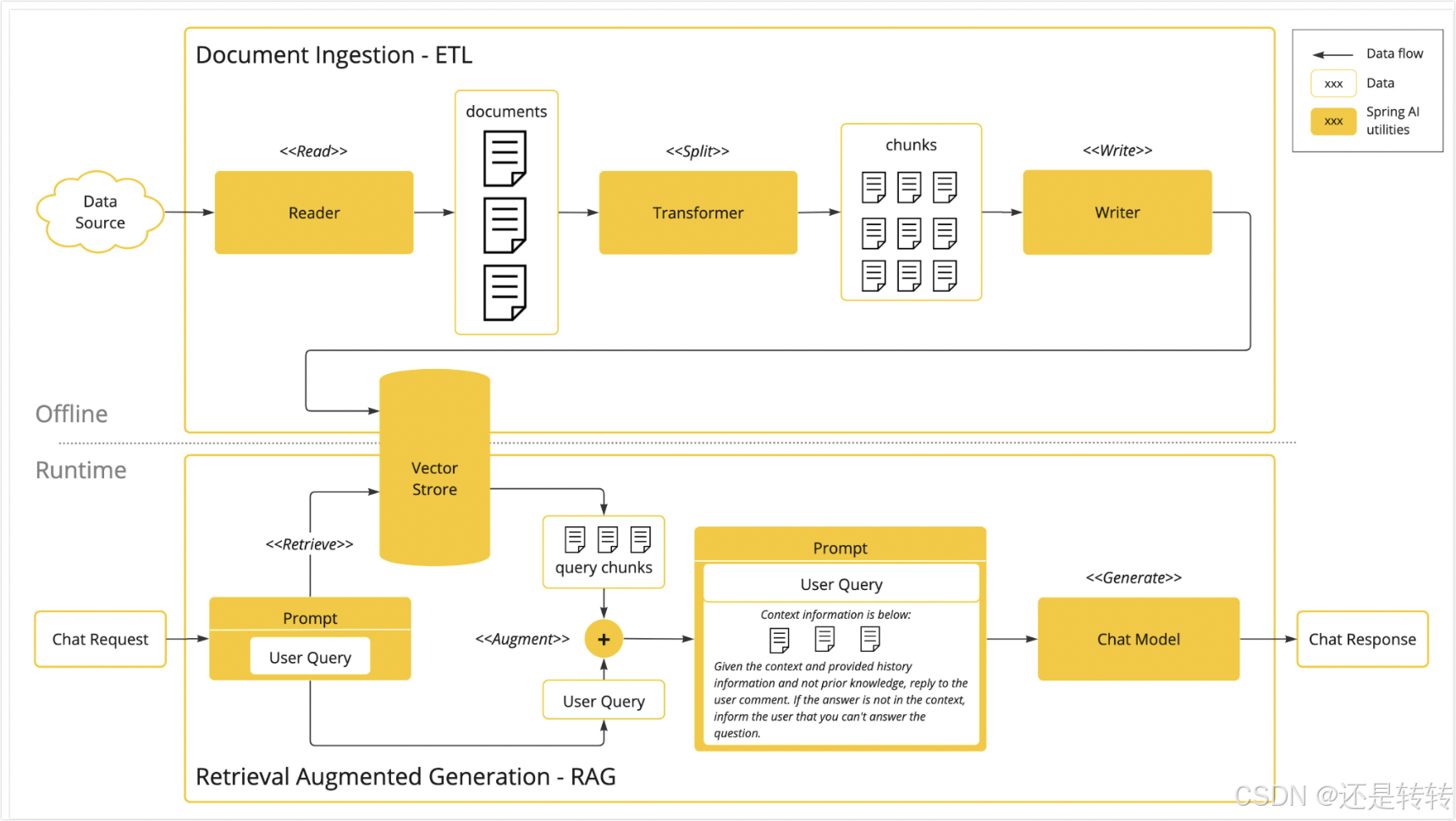
Spring AI 中使用了Retrieval Augmented Generation 来实现提示填充。RAG主要包括两个阶段,一是检索阶段,在用户提出问题时,系统会通过搜索引擎、数据库查询或向量检索等技术,从外部知识库(如文档集合、数据库、网页等)中提取相关信息。二是生成阶段,使用生成式AI模型接收用户输入和检索到的信息,并根据二者生成答案。如下图所示:
其中offline部分是离线生成外部知识库的过程,runtime部分就是将用户问题与检索到的信息传入模型并返回生成结果的过程。
函数调用
大型语言模型在训练后是冻结的,这会导致知识陈旧,并且无法访问或修改外部数据。
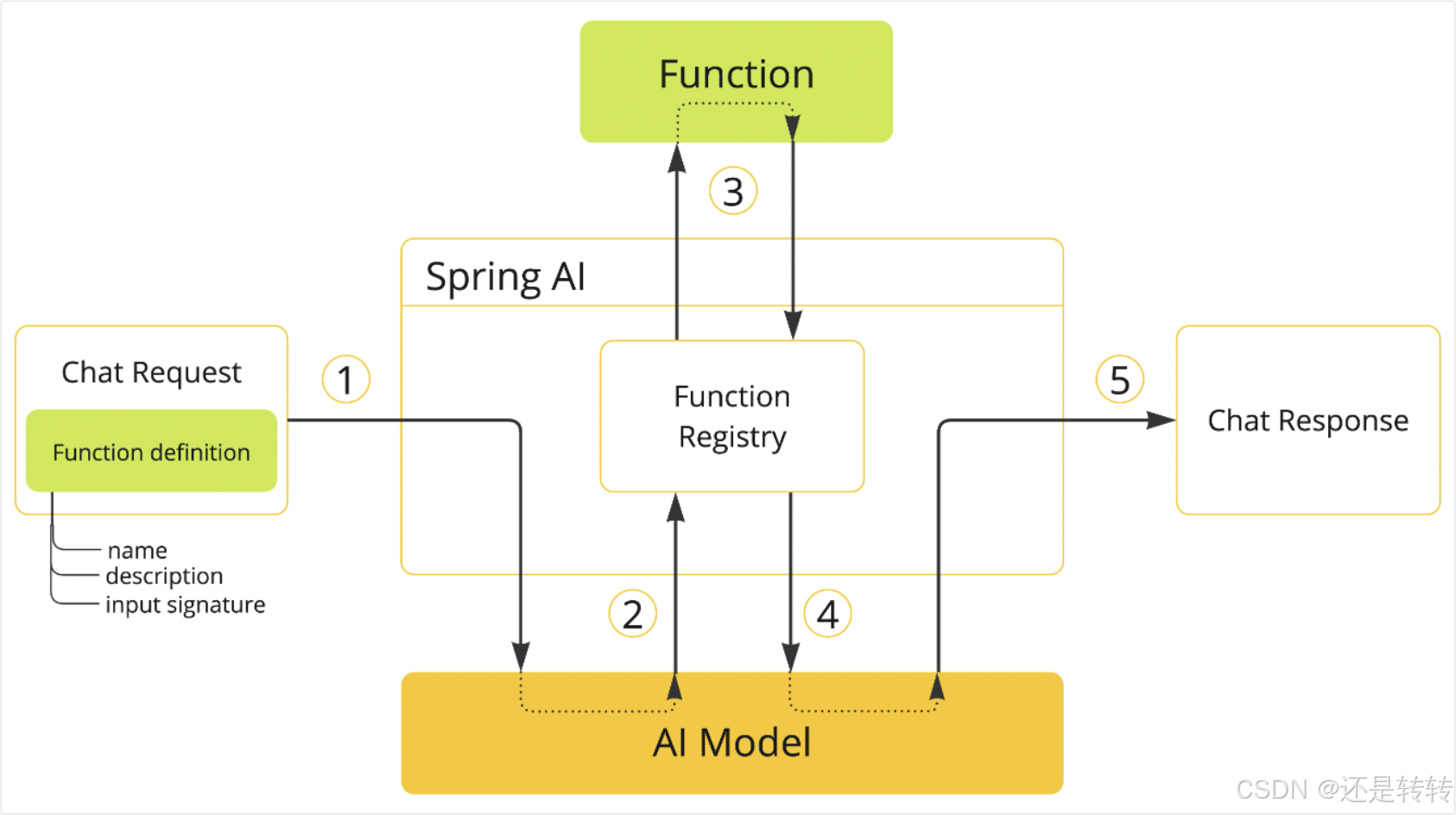
函数调用机制可以解决这些缺点。它允许您注册自己的函数,以将大型语言模型连接到外部系统的api。这些系统可以为llm提供实时数据并代表它们执行数据处理操作。
Spring AI 极大简化了为支持函数调用而需要编写的代码。它为你处理函数调用的对话,你可以通过@Bean的形式提供函数,然后在提示选项中提供函数的bean名来激活该函数。此外,你也可以在单个提示符中定义和引用多个函数。如下所示:
结果评价
高效评价 AI 模型的输出结果对问题的准确性和有效性是非常重要的。这个评估过程包括分析生成的响应是否与用户的意图和查询的上下文一致。可以用来衡量响应质量的指标包括:相关性、连贯性和事实正确性。
其中一种方法是同时呈现用户的请求和 AI 模型的响应,查询该响应是否与提供的数据一致。进一步地,引入向量数据库存储的补充信息,提供额外上下文来支持评估过程。
Spring AI 提供了一个名为Evaluator API 的工具,用于自动化模型响应的评估过程。当然,目前只提供了一些基础评估策略。
开启你的 Spring AI 之旅
你可以通过 Spring Initializr 来创建你的 Spring AI 项目,也可以手动创建。
或者直接从github上下载demo:
- OpenAI:github.com/rd-1-2022/ai-openai-helloworld
- Azure OpenAI:github.com/rd-1-2022/ai-azure-openai-helloworld 或者 github.com/Azure-Samples/spring-ai-azure-workshop
下面以ai-azure-openai-helloworld为例,下载到本地后,配置好的你的api-key和endpoint。有的模型还需要额外设置一下temperature: 1。
temperature是一个用来控制生成式AI模型输出内容随机性的重要参数。数值越小,随机性越低。数值越大,随机性越高。
运行项目,访问curl localhost:8080/ai/simple即可。
Chat Client
ChatClient为与AI模型通信提供了流畅的API,它同时支持同步和流式编程模型。
创建ChatClient
下面是一个例子:
@RestController
class MyController {
private final ChatClient chatClient;
public MyController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping("/ai")
String generation(String userInput) {
return this.chatClient.prompt()
.user(userInput)
.call()
.content();
}
}
ChatClient.Builder是自动装配的bean,直接注入使用即可。
也可以禁用ChatClient.Builder 的自动装配:spring.ai.chat.client.enabled=false。这在联合使用多种对话模型时是很有用的。此时可以通过编程式生成:
ChatModel myChatModel = ... // usually autowired
ChatClient.Builder builder = ChatClient.builder(this.myChatModel);
// or create a ChatClient with the default builder settings:
ChatClient chatClient = ChatClient.create(this.myChatModel);
流式 API 和 Response
你可以通过三种方式来创建链式API:prompt(),prompt(Prompt prompt) 和 prompt(String content)。
AI模型的返回类型是ChatResponse定义的,其中包括response的元数据,如该response所使用的tokens数量:
ChatResponse chatResponse = chatClient.prompt()
.user("Tell me a joke")
.call()
.chatResponse();
返回Entity
可以通过entity方法将返回的内容映射成对象实体,如下所示:
record ActorFilms(String actor, List<String> movies) {}
ActorFilms actorFilms = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call() // send request to AI model
.entity(ActorFilms.class);
流式响应
stream() 方法可以让结果异步返回:
Flux<String> output = chatClient.prompt()
.user("Tell me a joke")
.stream()
.content(); // string content response
当然,也可以直接通过异步的Flux<ChatResponse> chatResponse()来获得异步返回。
根据以上介绍可知,对AI 模型的调用分为同步和异步两种方式,前者使用call方法,后者使用stream方法。原始的返回内容应该是ChatResponse类型,其中包括了各种元数据。可以通过content方法仅仅只返回字符串类型,也可以通过entity方法来返回对象实体。
默认设置
如果通过默认设置的方式来创建ChatClient,那使用起来就比较简单了。
首先在配置类中创建chatClient:
@Configuration
class Config {
@Bean
ChatClient chatClient(ChatClient.Builder builder) {
return builder.defaultSystem("You are a friendly chat bot that answers question in the voice of a Pirate")
.build();
}
}
然后调用这个chatClient:
@RestController
class AIController {
private final ChatClient chatClient;
AIController(ChatClient chatClient) {
this.chatClient = chatClient;
}
@GetMapping("/ai/simple")
public Map<String, String> completion(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("completion", this.chatClient.prompt().user(message).call().content());
}
}
在 SpringAI 中,默认的系统文本指的是在与 AI 模型交互时,发送给模型的初始说明或上下文信息。系统文本通常用于指导模型的行为,例如确定其回答的风格、角色或语气。这是通过设定一个隐式的“系统消息”来完成的,类似于在 OpenAI 的 Function Calling 中使用的 System Role Messages。
带参数的默认系统文本
修改默认的系统文本如下:
@Configuration
class Config {
@Bean
ChatClient chatClient(ChatClient.Builder builder) {
return builder.defaultSystem("You are a friendly chat bot that answers question in the voice of a {voice}")
.build();
}
}
调用:
@RestController
class AIController {
private final ChatClient chatClient;
AIController(ChatClient chatClient) {
this.chatClient = chatClient;
}
@GetMapping("/ai")
Map<String, String> completion(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message, String voice) {
return Map.of("completion",
this.chatClient.prompt()
.system(sp -> sp.param("voice", voice))
.user(message)
.call()
.content());
}
}
其他默认配置项
在ChatClient级别,你可以指定默认的提示词配置,如
defaultOptions(ChatOptions chatOptions): 可以传入通用ChatOptions的配置,也可以传入特定模型,如OpenAiChatOptions配置。defaultFunction(String name, String description, java.util.function.Function<I, O> function):三个参数分别表示函数名,函数描述和模型要调用的函数本身。defaultFunctions(String… functionNames):在应用上下文中定义的函数bean的名称。defaultUser(String text),defaultUser(Resource text),defaultUser(Consumer<UserSpec> userSpecConsumer): 用于定义用户文本。Consumer<UserSpec>允许你用lambda表达式来指定用户文本和其他默认参数。defaultAdvisors(Advisor… advisor):在与 AI 模型交互的过程中拦截请求或响应,修改相应的数据。QuestionAnswerAdvisor实现通过在提示词里附加与用户文本相关的上下文信息来支持检索增强生成(RAG)模式。
这些方法去掉default前缀,就是相应的自定义方法了,可以用来覆盖默认值。
Advisors
在Spring AI 中,Advisors 是用于拦截和增强AI 操作行为的组件。可以将其看作是一种中间件机制,允许开发者在 AI 请求的处理流程中插入自定义逻辑,以调整默认行为或实现特定需求。
ChatClient的流式API提供了AdvisorSpec接口用来配置advisors。如下所示:
interface AdvisorSpec {
AdvisorSpec param(String k, Object v);
AdvisorSpec params(Map<String, Object> p);
AdvisorSpec advisors(Advisor... advisors);
AdvisorSpec advisors(List<Advisor> advisors);
}
advisors根据添加的先后顺序执行。
检索增强生成(Retrieval Augmented Generation)
向量数据库中存储了AI模型不知道的数据。当用户发送一个请求时,QuestionAnswerAdvisor 会从向量数据库中查询与用户问题相关的信息,然后将其附加到用户文本中,供 AI 模型来生成响应。如下所示:
ChatResponse response = ChatClient.builder(chatModel)
.build().prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults()))
.user(userText)
.call()
.chatResponse();
动态过滤表达式
在运行时更新过滤表达式如下:
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults()))
.build();
// Update filter expression at runtime
String content = this.chatClient.prompt()
.user("Please answer my question XYZ")
.advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "type == 'Spring'"))
.call()
.content();
FILTER_EXPRESSION 参数可以让你动态过滤搜索结果。
对话记忆
接口ChatMemory表示对话历史记录的存储。其中包含添加会话消息,获取会话消息和删除会话记录等方法。
该接口有两个实现,分别是 InMeomoryChatMemory和CassandraChatMemory,前者是内存存储,后者是持久化存储。
ChatMemory典型的使用场景:
- 用户多次提问,需要 AI 基于历史记录给出精准回答。
- 用户在一个会话中完成一个多步骤任务,需要 AI 模型保存中间步骤数据。
- 跨会话记忆,将用户的偏好和历史交互持久化,以便在后续会话中为用户提供个性化体验。
- 调试与分析,开发者可以通过ChatMemory 检查对话历史,分析AI 的生成为行为是否符合预期。
很多advisor实现均使用了ChatMemory接口来将会话历史添加到提示词中,只不是细节不通而已。如MessageChatMemoryAdvisor , PromptChatMemoryAdvisor ,VectorStoreChatMemoryAdvisor 。
日志
SimpleLoggerAdvisor 是一个记录request和response的日志advisor,开启如下:
ChatResponse response = ChatClient.create(chatModel).prompt()
.advisors(new SimpleLoggerAdvisor())
.user("Tell me a joke?")
.call()
.chatResponse();
// set up the log level
loggging.level.org.springframework.ai.chat.client.advisor=DEBUG
你可以定制日志格式:
SimpleLoggerAdvisor(
Function<AdvisedRequest, String> requestToString,
Function<ChatResponse, String> responseToString
)
SimpleLoggerAdvisor customLogger = new SimpleLoggerAdvisor(
request -> "Custom request: " + request.userText,
response -> "Custom response: " + response.getResult()
);
Advisors API
正如上文介绍,Spring AI 中的Advisors是用于拦截和增强AI操作行为的组件。可以将其看作是一种中间件机制,允许开发者在 AI 请求的处理流程中插入自定义逻辑,以调整默认行为或实现特定需求。如QuestionAnswerAdvisor 可用于检索增强生成(RAG),MessageChatMemoryAdvisor 用于对话记忆设置,SimpleLoggerAdvisor 用于日志记录等。
下面是advisor的配置方式示例:
var chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory), // chat-memory advisor
new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults()) // RAG advisor
)
.build();
String response = this.chatClient.prompt()
// Set advisor parameters at runtime
.advisors(advisor -> advisor.param("chat_memory_conversation_id", "678")
.param("chat_memory_response_size", 100))
.user(userText)
.call()
.content();
推荐在builder的defaultAdvisors()方法中注册advisors。
核心组件
Advisors的核心组件包括:
CallAroundAdvisor和CallAroundAdvisorChain:用于非流式调用场景StreamAroundAdvisor和StreamAroundAdvisorChain:用于流式调用场景AdvisedRequest:用于处理请求提示词AdvisedResponse:用于处理模型的返回
如下图所示:
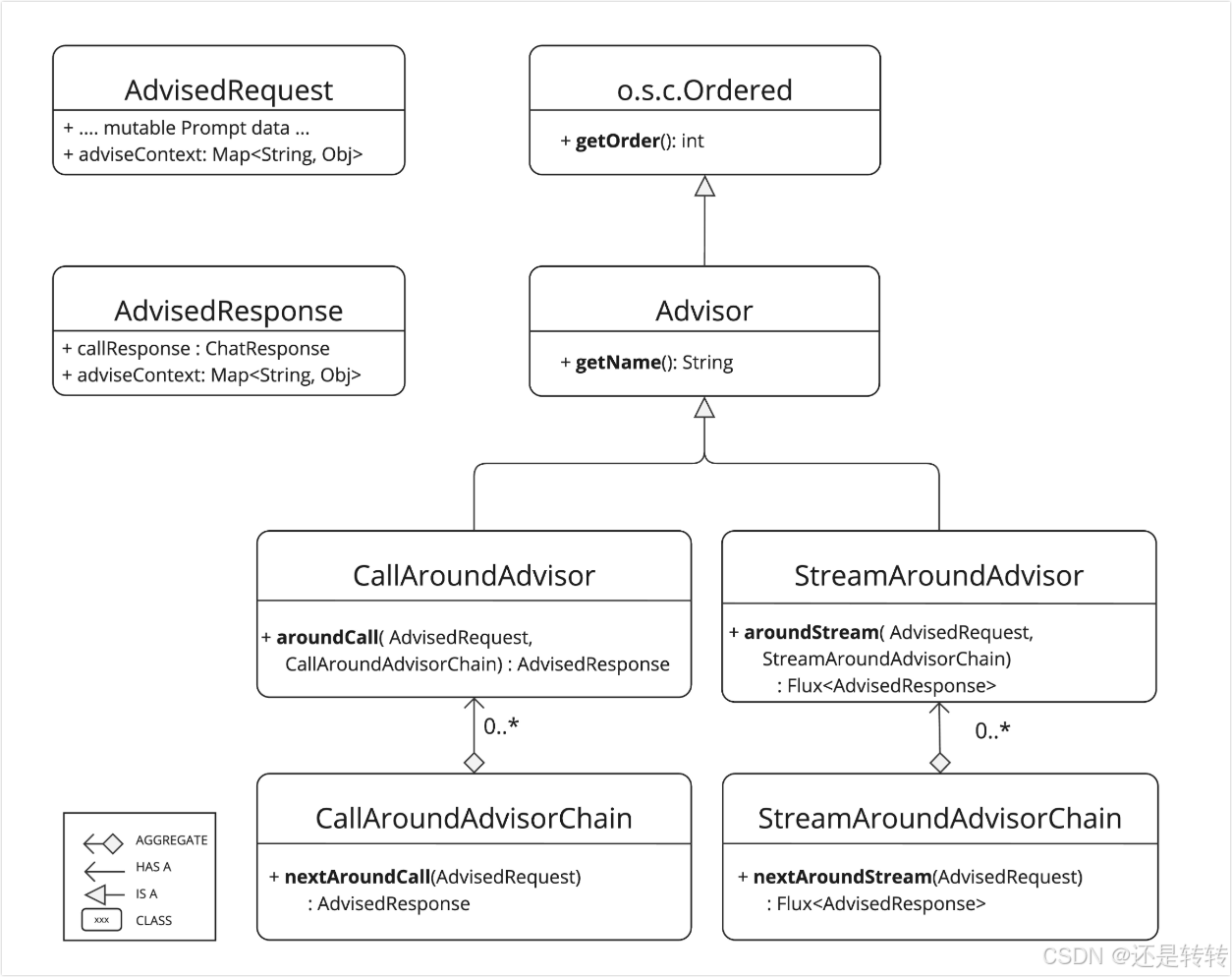
其中CallAroundAdvisorChain 类的nextAroundCall() 方法和StreamAroundAdvisorChain 类中的nextAroundStream() 方法是关键方法,主要负责对请求进行检查,定制化和增强处理,并调用advisor链上的下一个实体。检查响应结果。如果在此过程中出现异常或错误,则会阻塞请求或者抛出异常。
在顶层的Ordered类中,getOrder()方法的返回值决定了链上的advisor的执行顺序,值越小优先级越高。Advisor类的getName()方法返回了每个advisor的唯一名称。Advisors与Chat模型的交互如下所示:
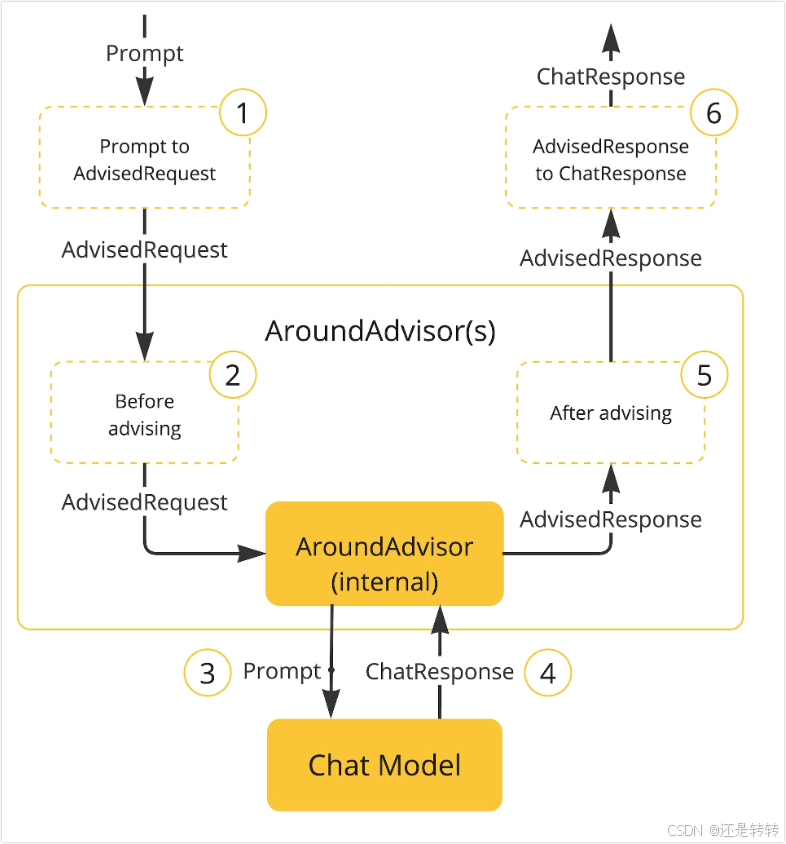
大致说明如下:
- Spring AI 会根据用户输入创建一个
AdvisedRequest,其中advisor上下文AdvisorContext是一个空对象。 - 请求经过链上的advisors依次处理。
- 最后一个advisor是由Spring AI 自动添加的,负责将请求发送给对话模型。
- 对话模型生成响应结果,并传递回advisors链,最终转换成
AdvisedResponse,其中包括AdvisorContext对象,此时这个上下文对象是有内容的。
实现一个Advisor
如果想实现一个advisor,只需要实现CallAroundAdvisor或StreamAroundAdvisor接口即可。
下面实现一个日志advisor来记录AdvisedRequest 和AdvisedResponse 的内容。
Logging Advisor
代码如下:
public class SimpleLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
private static final Logger logger = LoggerFactory.getLogger(SimpleLoggerAdvisor.class);
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return 0;
}
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
logger.debug("BEFORE: {}", advisedRequest);
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
logger.debug("AFTER: {}", advisedResponse);
return advisedResponse;
}
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
logger.debug("BEFORE: {}", advisedRequest);
Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);
return new MessageAggregator().aggregateAdvisedResponse(advisedResponses,
advisedResponse -> logger.debug("AFTER: {}", advisedResponse));
}
}
Re2 Advisor
"Re-Reading improvement Reasoning in Large Language Models"这篇文章介绍了一种称为Re-Reading (Re2)的技术,它可以提高大型语言模型的推理能力。Re2技术需要像下面这样增加输入提示:
{Input_Query}
Read the question again: {Input Query}
下面是一个使用Re2的实例:
public class ReReadingAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
private AdvisedRequest before(AdvisedRequest advisedRequest) {
Map<String, Object> advisedUserParams = new HashMap<>(advisedRequest.userParams());
advisedUserParams.put("re2_input_query", advisedRequest.userText());
return AdvisedRequest.from(advisedRequest)
.withUserText("""
{re2_input_query}
Read the question again: {re2_input_query}
""")
.withUserParams(advisedUserParams)
.build();
}
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
return chain.nextAroundCall(this.before(advisedRequest));
}
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
return chain.nextAroundStream(this.before(advisedRequest));
}
@Override
public int getOrder() {
return 0;
}
@Override
public String getName() {
return this.getClass().getSimpleName();
}
}
内置的Advisors
Spring AI 框架内置了很多advisors。如前文介绍过的对话记忆相关的MessageChatMemoryAdvisor , PromptChatMemoryAdvisor ,VectorStoreChatMemoryAdvisor ,还有检索增强生成相关的QuestionAnswerAdvisor ,防止生成有害信息的SafeGuardAdvisor等。
API 兼容性
Spring AI 的Advisor 从 1.0 M2 升级到 M3 的过程经历了一些重大变更。
Advisor接口
在1.0 M2中,RequestAdvisor和ResponseAdvisor是独立的接口,其中:
RequestAdvisor在ChatModel.call和ChatModel.stream方法之前调用。ResponseAdvisor在这些方法之后调用。
在1.0 M3中,这些接口被 CallAroundAdvisor 和 StreamAroundAdvisor 代替。
另外,之前作为ResponseAdvisor的一部分的StreamResponseMode ,在M3中被移除了。
上下文Map处理
在1.0 M2中,上下文 map 是一个独立的方法参数。且这个map是可变的,沿着advisoor链传递。
在1.0 M3中,上下文 map 变成了AdvisedRequest 和 AdvisedResponse 的一部分,且是不可变的。如果要更新上下文,需要用updateContext 方法,创建一个新的不可变map。如下所示:
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
this.advisedRequest = advisedRequest.updateContext(context -> {
context.put("aroundCallBefore" + getName(), "AROUND_CALL_BEFORE " + getName()); // Add multiple key-value pairs
context.put("lastBefore", getName()); // Add a single key-value pair
return context;
});
// Method implementation continues...
}
参考资料
[1]. https://docs.spring.io/spring-ai/reference/concepts.html