0.摘要
基本是和
x
m
l
xml
xml相关的一些知识,个人感觉用处不是特别大,有需求再细致了解也不迟。
本书的大部分章节都是以样例代码为中心的。但是
x
m
l
xml
xml这章不是;它以数据为中心。最常见的
x
m
l
xml
xml应用为“聚合订阅(
s
y
n
d
i
c
a
t
i
o
n
f
e
e
d
s
syndication\ feeds
syndication feeds)”,它用来展示博客,论坛或者其他会经常更新的网站的最新内容。大多数的博客软件都会在新文章,新的讨论区,或者新博文发布的时候自动生成和更新
f
e
e
d
feed
feed。

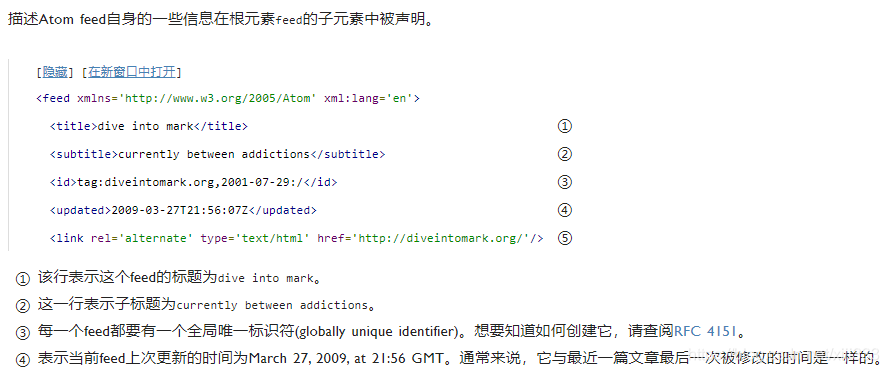
<?xml version='1.0' encoding='utf-8'?>
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title>dive into mark</title>
<subtitle>currently between addictions</subtitle>
<id>tag:diveintomark.org,2001-07-29:/</id>
<updated>2009-03-27T21:56:07Z</updated>
<link rel='alternate' type='text/html' href='http://diveintomark.org/'/>
<link rel='self' type='application/atom+xml' href='http://diveintomark.org/feed/'/>
<entry>
<author>
<name>Mark</name>
<uri>http://diveintomark.org/</uri>
</author>
<title>Dive into history, 2009 edition</title>
<link rel='alternate' type='text/html'
href='http://diveintomark.org/archives/2009/03/27/dive-into-history-2009-edition'/>
<id>tag:diveintomark.org,2009-03-27:/archives/20090327172042</id>
<updated>2009-03-27T21:56:07Z</updated>
<published>2009-03-27T17:20:42Z</published>
<category scheme='http://diveintomark.org' term='diveintopython'/>
<category scheme='http://diveintomark.org' term='docbook'/>
<category scheme='http://diveintomark.org' term='html'/>
<summary type='html'>Putting an entire chapter on one page sounds
bloated, but consider this &mdash; my longest chapter so far
would be 75 printed pages, and it loads in under 5 seconds&hellip;
On dialup.</summary>
</entry>
<entry>
<author>
<name>Mark</name>
<uri>http://diveintomark.org/</uri>
</author>
<title>Accessibility is a harsh mistress</title>
<link rel='alternate' type='text/html'
href='http://diveintomark.org/archives/2009/03/21/accessibility-is-a-harsh-mistress'/>
<id>tag:diveintomark.org,2009-03-21:/archives/20090321200928</id>
<updated>2009-03-22T01:05:37Z</updated>
<published>2009-03-21T20:09:28Z</published>
<category scheme='http://diveintomark.org' term='accessibility'/>
<summary type='html'>The accessibility orthodoxy does not permit people to
question the value of features that are rarely useful and rarely used.</summary>
</entry>
<entry>
<author>
<name>Mark</name>
</author>
<title>A gentle introduction to video encoding, part 1: container formats</title>
<link rel='alternate' type='text/html'
href='http://diveintomark.org/archives/2008/12/18/give-part-1-container-formats'/>
<id>tag:diveintomark.org,2008-12-18:/archives/20081218155422</id>
<updated>2009-01-11T19:39:22Z</updated>
<published>2008-12-18T15:54:22Z</published>
<category scheme='http://diveintomark.org' term='asf'/>
<category scheme='http://diveintomark.org' term='avi'/>
<category scheme='http://diveintomark.org' term='encoding'/>
<category scheme='http://diveintomark.org' term='flv'/>
<category scheme='http://diveintomark.org' term='GIVE'/>
<category scheme='http://diveintomark.org' term='mp4'/>
<category scheme='http://diveintomark.org' term='ogg'/>
<category scheme='http://diveintomark.org' term='video'/>
<summary type='html'>These notes will eventually become part of a
tech talk on video encoding.</summary>
</entry>
</feed>
1.5分钟XML速成
x
m
l
xml
xml是一种描述层次结构化数据的通用方法。
x
m
l
xml
xml文档包含由起始和结束标签(
t
a
g
tag
tag)分隔的一个或多个元素(
e
l
e
m
e
n
t
element
element)。以下也是一个完整的(虽然空洞)
x
m
l
xml
xml文件:

第一行是
f
o
o
foo
foo元素的起始标签。
第二行是
f
o
o
foo
foo元素对应的结束标签。就如写作、数学或者代码中需要平衡括号一样,每一个起始标签必须有对应的结束标签来闭合(匹配)。
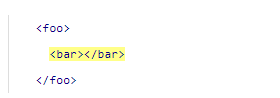
元素可以嵌套到任意层次。位于
f
o
o
foo
foo中的元素
b
a
r
bar
bar可以被称作其子元素。
x
m
l
xml
xml文档中的第一个元素叫做根元素(
r
o
o
t
e
l
e
m
e
n
t
root\ element
root element)。并且每份
x
m
l
xml
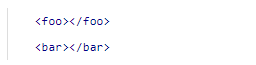
xml文档只能有一个根元素。以下不是一个
x
m
l
xml
xml文档,因为它存在两个“根元素”。
元素可以有其属性(
a
t
t
r
i
b
u
t
e
attribute
attribute),它们是一些名字-值(
n
a
m
e
−
v
a
l
u
e
name-value
name−value)对。属性由空格分隔列举在元素的起始标签中。一个元素中属性名不能重复。属性值必须用引号包围起来。单引号、双引号都是可以。
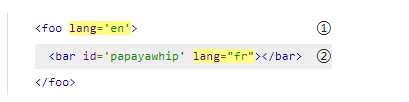
f
o
o
foo
foo元素有一个叫做
l
a
n
g
lang
lang的属性。
l
a
n
g
lang
lang的值为
e
n
en
en。
b
a
r
bar
bar元素则有两个属性,分别为
i
d
id
id和
l
a
n
g
lang
lang。其中
l
a
n
g
lang
lang属性的值为
f
r
fr
fr。它不会与
f
o
o
foo
foo的那个属性产生冲突。每个元素都其独立的属性集。
如果元素有多个属性,书写的顺序并不重要。元素的属性是一个无序的键-值对集,跟
P
y
t
h
o
n
Python
Python中的字典对象一样。另外,元素中属性的个数是没有限制的。
元素可以有其文本内容(
t
e
x
t
c
o
n
t
e
n
t
text\ content
text content)。
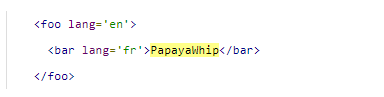
如果某一元素既没有文本内容,也没有子元素,它也叫做空元素。
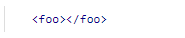
表达空元素有一种简洁的方法。通过在起始标签的尾部添加/字符,我们可以省略结束标签。上一个例子中的
x
m
l
xml
xml文档可以写成这样:

就像
P
y
t
h
o
n
Python
Python函数可以在不同的模块(
m
o
d
u
l
e
s
modules
modules)中声明一样,也可以在不同的名字空间(
n
a
m
e
s
p
a
c
e
namespace
namespace)中声明
x
m
l
xml
xml元素。
x
m
l
xml
xml文档的名字空间通常看起来像
U
R
L
URL
URL。我们可以通过声明
x
m
l
n
s
xmlns
xmlns来定义默认名字空间。名字空间声明跟元素属性看起来很相似,但是它们的作用是不一样的。
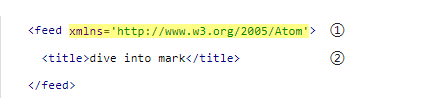
f
e
e
d
feed
feed元素处在名字空间
h
t
t
p
:
/
/
w
w
w
.
w
3.
o
r
g
/
2005
/
A
t
o
m
http://www.w3.org/2005/Atom
http://www.w3.org/2005/Atom中。
t
i
t
l
e
title
title元素也是。名字空间声明不仅会作用于当前声明它的元素,还会影响到该元素的所有子元素。
也可以通过
x
m
l
n
s
:
p
r
e
f
i
x
xmlns:prefix
xmlns:prefix声明来定义一个名字空间并取其名为
p
r
e
f
i
x
prefix
prefix。然后该名字空间中的每个元素都必须显式地使用这个前缀(
p
r
e
f
i
x
prefix
prefix)来声明。
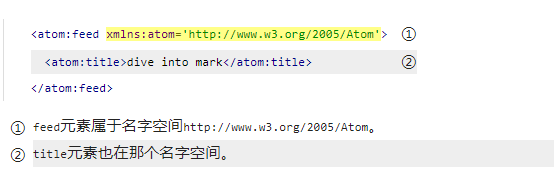
对于
x
m
l
xml
xml解析器而言,以上两个
x
m
l
xml
xml文档是一样的。名字空间 + 元素名 =
x
m
l
xml
xml标识。前缀只是用来引用名字空间的,所以对于解析器来说,这些前缀名(
a
t
o
m
:
atom:
atom:)其实无关紧要的。名字空间相同,元素名相同,属性(或者没有属性)相同,每个元素的文本内容相同,则
x
m
l
xml
xml文档相同。
最后,在根元素之前,字符编码信息可以出现在
x
m
l
xml
xml文档的第一行。这里存在一个两难的局面,直观上来说,解析
x
m
l
xml
xml文档需要这些编码信息,而这些信息又存在于
x
m
l
xml
xml文档中,如果你对
x
m
l
xml
xml如何解决此问题有兴趣,请参阅
x
m
l
xml
xml规范中F章节。

2.Atom Feed的结构
想像一下网络上的博客,或者互联网上任何需要频繁更新的网站,比如CNN.com。该站点有一个标题(“CNN.com”),一个子标题(“Breaking News, U.S., World, Weather, Entertainment & Video News”),包含上次更新的日期(“updated 12:43 p.m. EDT, Sat May 16, 2009”),还有在不同时期发布的文章的列表。每一篇文章也有自己的标题,第一次发布的日期(如果曾经修订过或者改正过某个输入错误,或许也有一个上次更新的日期),并且每篇文章有自己唯一的
U
R
L
URL
URL。
A
t
o
m
Atom
Atom聚合格式被设计成可以包含所有这些信息的标准格式。我的博客无论在设计,主题还是读者上都与CNN.com大不相同,但是它们的基本结构是相同的。CNN.com能做的事情,我的博客也能做…
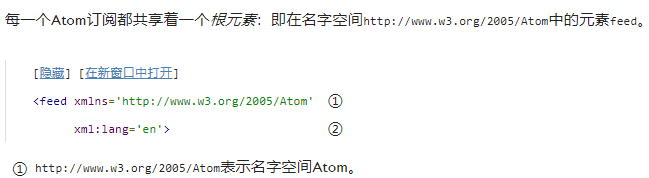
每一个元素都可以包含
x
m
l
:
l
a
n
g
xml:lang
xml:lang属性,它用来声明该元素及其子元素使用的语言。在当前样例中,
x
m
l
:
l
a
n
g
xml:lang
xml:lang在根元素中被声明了一次,也就意味着,整个
f
e
e
d
feed
feed都使用英文。
事情开始变得有趣了…
l
i
n
k
link
link元素没有文本内容,但是它有三个属性:
r
e
l
,
t
y
p
e
rel,type
rel,type和
h
r
e
f
href
href。
r
e
l
rel
rel元素的值能告诉我们链接的类型;
r
e
l
=
rel=
rel='alternate’表示这个链接指向当前
f
e
e
d
feed
feed的另外一个版本。
t
y
p
e
=
type=
type='text/html’表示链接的目标是一个
h
t
m
l
html
html页面。然后目标地址在
h
r
e
f
href
href属性中指出。



⑦
s
u
m
m
a
r
y
summary
summary元素中有这篇文章的概要性描述。(还有一个元素这里没有展示出来,即
c
o
n
t
e
n
t
content
content,我们可以把整篇文章的内容都放在里边。)当前样例中,
s
u
m
m
a
r
y
summary
summary元素含有一个
A
t
o
m
Atom
Atom特有的
t
y
p
e
=
type=
type=’html’属性,它用来告知这份概要为
h
t
m
l
html
html格式,而非纯文本。这非常重要,因为概要内容中包含了
h
t
m
l
html
html中特有的实体(—和…),它们不应该以纯文本直接显示,正确的形式应该为“—”和“…”。
⑧最后就是
e
n
t
r
y
entry
entry元素的结束标记了,它指示文章元数据的结尾。
3.解析XML

①
E
l
e
m
e
n
t
T
r
e
e
①ElementTree
①ElementTree属于
P
y
t
h
o
n
Python
Python标准库的一部分,它的位置为
x
m
l
.
e
t
r
e
e
.
E
l
e
m
e
n
t
T
r
e
e
xml.etree.ElementTree
xml.etree.ElementTree。
②
p
a
r
s
e
(
)
②parse()
②parse()函数是
E
l
e
m
e
n
t
T
r
e
e
ElementTree
ElementTree库的主要入口,它使用文件名或者流对象作为参数。
p
a
r
s
e
(
)
parse()
parse()函数会立即解析完整个文档。如果内存资源紧张,也可以增量式地解析
x
m
l
xml
xml文档。
③
p
a
r
s
e
(
)
③parse()
③parse()函数会返回一个能代表整篇文档的对象。这不是根元素。要获得根元素的引用可以调用
g
e
t
r
o
o
t
(
)
getroot()
getroot()方法。
④
④
④如预期的那样,根元素即
h
t
t
p
:
/
/
w
w
w
.
w
3.
o
r
g
/
2005
/
A
t
o
m
http://www.w3.org/2005/Atom
http://www.w3.org/2005/Atom名字空间中的
f
e
e
d
feed
feed。该字符串表示再次重申了非常重要的一点:
x
m
l
xml
xml元素由名字空间和标签名(也称作本地名(
l
o
c
a
l
n
a
m
e
local\ name
local name))组成。这篇文档中的每个元素都在名字空间
A
t
o
m
Atom
Atom中,所以根元素被表示为
{
h
t
t
p
:
/
/
w
w
w
.
w
3.
o
r
g
/
2005
/
A
t
o
m
}
f
e
e
d
\{http://www.w3.org/2005/Atom\}feed
{http://www.w3.org/2005/Atom}feed。

3.1元素即列表
在
E
l
e
m
e
n
t
T
r
e
e
A
P
I
ElementTree\ API
ElementTree API中,元素的行为就像列表一样。列表中的项即该元素的子元素。
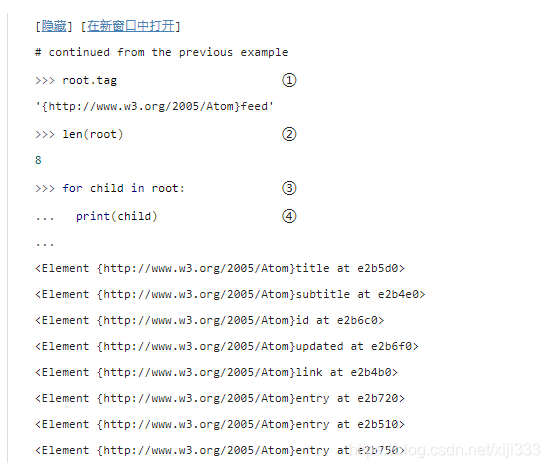
①
①
①紧接前一例子,根元素为
{
h
t
t
p
:
/
/
w
w
w
.
w
3.
o
r
g
/
2005
/
A
t
o
m
}
f
e
e
d
\{http://www.w3.org/2005/Atom\}feed
{http://www.w3.org/2005/Atom}feed。
②
②
②根元素的“长度”即子元素的个数。
③
③
③我们可以像使用迭代器一样来遍历其子元素。
④
④
④从输出可以看到,根元素总共有8个子元素:所有
f
e
e
d
feed
feed级的元数据(
t
i
t
l
e
,
s
u
b
t
i
t
l
e
,
i
d
,
u
p
d
a
t
e
d
title,subtitle,id,updated
title,subtitle,id,updated和
l
i
n
k
link
link),还有紧接着的三个
e
n
t
r
y
entry
entry元素。
也许你已经注意到了,但我还是想要指出来:该列表只包含直接子元素。每一个
e
n
t
r
y
entry
entry元素都有其子元素,但是并没有包括在这个列表中。这些子元素本可以包括在
e
n
t
r
y
entry
entry元素的列表中,但是确实不属于
f
e
e
d
feed
feed的子元素。但是,无论这些元素嵌套的层次有多深,总是有办法定位到它们的;在这章的后续部分我们会介绍两种方法。
3.2属性即字典
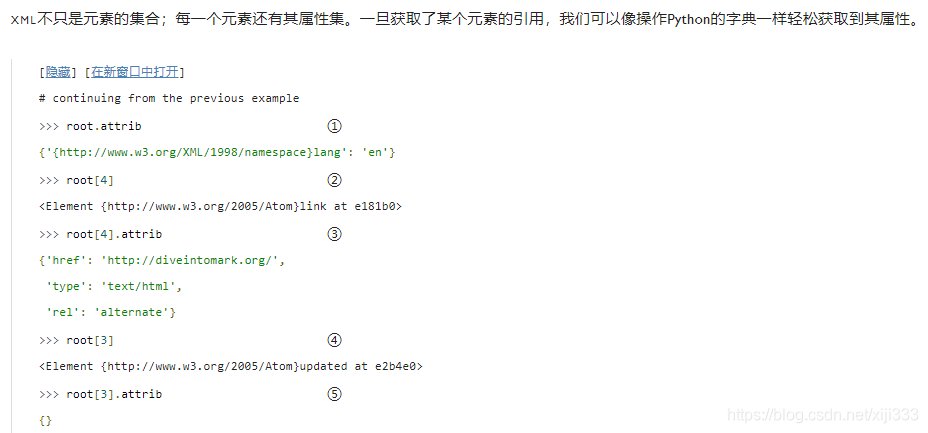
①
a
t
t
r
i
b
①attrib
①attrib是一个代表元素属性的字典。这个地方原来的标记语言是这样描述的:<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>。前缀
x
m
l
xml
xml:指示一个内置的名字空间,每一个
x
m
l
xml
xml不需要声明就可以使用它。
②
②
②第五个子元素 — 以0为起始的列表中即
[
4
]
[4]
[4] — 为元素
l
i
n
k
link
link。
③
l
i
n
k
③link
③link元素有三个属性:
h
r
e
f
href
href,
t
y
p
e
type
type,和
r
e
l
rel
rel。
④
④
④第四个子元素 —
[
3
]
[3]
[3] — 为
u
p
d
a
t
e
d
updated
updated。
⑤
⑤
⑤元素
u
p
d
a
t
e
d
updated
updated没有子元素,所以
.
a
t
t
r
i
b
.attrib
.attrib是一个空的字典对象。
4.在XML文档中查找结点
到目前为止,我们已经“自顶向下“地从根元素开始,一直到其子元素,走完了整个文档。但是许多情况下我们需要找到
x
m
l
xml
xml中特定的元素。
E
t
r
e
e
Etree
Etree也能完成这项工作。
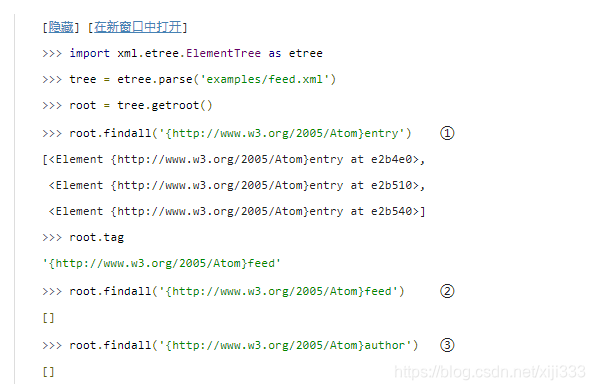
①
f
i
n
d
f
a
l
l
(
)
①findfall()
①findfall()方法查找匹配特定格式的子元素。(关于查询的格式稍后会讲到。)
②
②
②每个元素 — 包括根元素及其子元素 — 都有
f
i
n
d
a
l
l
(
)
findall()
findall()方法。它会找到所有匹配的子元素。但是为什么没有看到任何结果呢?也许不太明显,这个查询只会搜索其子元素。由于根元素
f
e
e
d
feed
feed中不存在任何叫做
f
e
e
d
feed
feed的子元素,所以查询的结果为一个空的列表。
③
③
③这个结果也许也在你的意料之外。在这篇文档中确实存在
a
u
t
h
o
r
author
author元素;事实上总共有三个(每个
e
n
t
r
y
entry
entry元素中都有一个)。但是那些
a
u
t
h
o
r
author
author元素不是根元素的直接子元素。我们可以在任意嵌套层次中查找
a
u
t
h
o
r
author
author元素,但是查询的格式会有些不同。
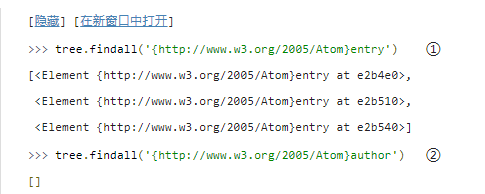
①
①
①为了方便,对象
t
r
e
e
tree
tree(调用
e
t
r
e
e
.
p
a
r
s
e
(
)
etree.parse()
etree.parse()的返回值)中的一些方法是根元素中这些方法的镜像。在这里,如果调用
t
r
e
e
.
g
e
t
r
o
o
t
(
)
.
f
i
n
d
a
l
l
(
)
tree.getroot().findall()
tree.getroot().findall(),则返回值是一样的。
②
②
②也许有些意外,这个查询请求也没有找到文档中的
a
u
t
h
o
r
author
author元素。为什么没有呢?因为它只是
t
r
e
e
.
g
e
t
r
o
o
t
(
)
.
f
i
n
d
a
l
l
(
′
{
h
t
t
p
:
/
/
w
w
w
.
w
3.
o
r
g
/
2005
/
A
t
o
m
}
a
u
t
h
o
r
′
)
tree.getroot().findall('\{http://www.w3.org/2005/Atom\}author')
tree.getroot().findall(′{http://www.w3.org/2005/Atom}author′)的一种简洁表示,即“查询所有是根元素的子元素的
a
u
t
h
o
r
author
author”。因为这些
a
u
t
h
o
r
author
author是
e
n
t
r
y
entry
entry元素的子元素,所以查询没有找到任何匹配的。
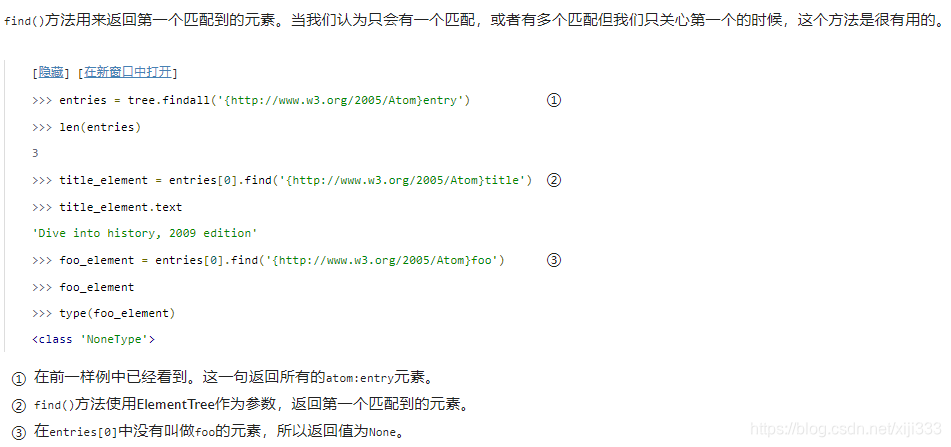
可逮住你了,在这里
f
i
n
d
(
)
find()
find()方法非常容易被误解。在布尔上下文中,如果
E
l
e
m
e
n
t
T
r
e
e
ElementTree
ElementTree元素对象不包含子元素,其值则会被认为是
F
a
l
s
e
False
False(即如果
l
e
n
(
e
l
e
m
e
n
t
)
len(element)
len(element)等于0)。这就意味着
i
f
e
l
e
m
e
n
t
.
f
i
n
d
(
′
.
.
.
′
)
if\ element.find('...')
if element.find(′...′)并非在测试
f
i
n
d
(
)
find()
find()方法是否i找到了匹配项;这条语句是在测试匹配到的元素是否包含子元素!想要测试
f
i
n
d
(
)
find()
find()方法是否返回了一个元素,则需使用
i
f
e
l
e
m
e
n
t
.
f
i
n
d
(
′
.
.
.
′
)
i
s
n
o
t
N
o
n
e
if\ element.find('...')\ is\ not\ None
if element.find(′...′) is not None。

/
/
{
h
t
t
p
:
/
/
w
w
w
.
w
3.
o
r
g
/
2005
/
A
t
o
m
}
l
i
n
k
//\{http://www.w3.org/2005/Atom\}link
//{http://www.w3.org/2005/Atom}link与前一样例很相似,除了开头的两条斜线。这两条斜线告诉
f
i
n
d
a
l
l
(
)
findall()
findall()方法“不要只在直接子元素中查找;查找的范围可以是任意嵌套层次”。
这里几个例子我本地测试结果应该有
5
5
5个……有点迷。

总的来说, E l e m e n t T r e e ElementTree ElementTree的 f i n d a l l ( ) findall() findall()方法是其一个非常强大的特性,但是它的查询语言却让人有些出乎意料。官方描述它为“有限的 X P a t h XPath XPath支持。” X P a t h XPath XPath是一种用于查询 x m l xml xml文档的 W 3 C W3C W3C标准。对于基础地查询来说, E l e m e n t T r e e ElementTree ElementTree与 X P a t h XPath XPath语法上足够相似,但是如果已经会 X P a t h XPath XPath的话,它们之间的差异可能会使你感到不快。现在,我们来看一看另外一个第三方 x m l xml xml库,它扩展了 E l e m e n t T r e e ElementTree ElementTree的 a p i api api以提供对 X P a t h XPath XPath的全面支持。
5.深入lxml
l
x
m
l
lxml
lxml是一个开源的第三方库,以流行的
l
i
b
x
m
l
2
libxml2
libxml2 解析器为基础开发。提供了与
E
l
e
m
e
n
t
T
r
e
e
ElementTree
ElementTree完全兼容的
a
p
i
api
api,并且扩展它以提供了对
X
P
a
t
h
1.0
XPath\ 1.0
XPath 1.0的全面支持,以及改进了一些其他精巧的细节。

对于大型的
x
m
l
xml
xml文档,
l
x
m
l
lxml
lxml明显比内置的
E
l
e
m
e
n
t
T
r
e
e
ElementTree
ElementTree快了许多。如果现在只用到了
E
l
e
m
e
n
t
T
r
e
e
ElementTree
ElementTree的
a
p
i
api
api,并且想要使用其最快的实现(
i
m
p
l
e
m
e
n
t
a
t
i
o
n
implementation
implementation),我们可以尝试导入
l
x
m
l
lxml
lxml,并且将内置的
E
l
e
m
e
n
t
T
r
e
e
ElementTree
ElementTree作为备用。

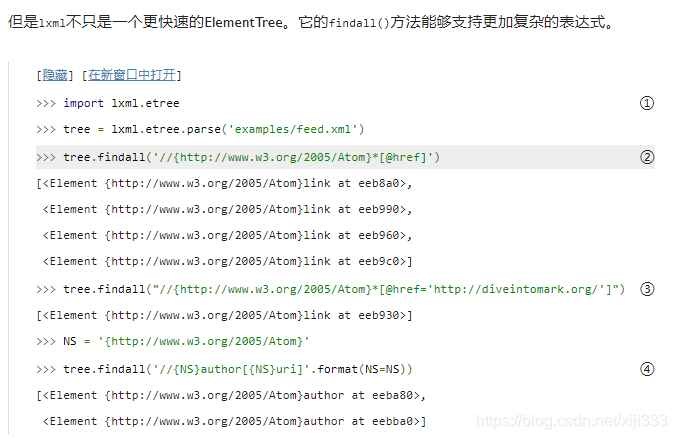
①
①
①在这个样例中,我使用了
i
m
p
o
r
t
l
x
m
l
.
e
t
r
e
e
import\ lxml.etree
import lxml.etree,以强调这些特性只限于
l
x
m
l
lxml
lxml。
②
②
②这一句在整个文档范围内搜索名字空间
A
t
o
m
Atom
Atom中具有
h
r
e
f
href
href属性的所有元素。在查询语句开头的//表示搜索的范围为整个文档(不只是根元素的子元素)。
{
h
t
t
p
:
/
/
w
w
w
.
w
3.
o
r
g
/
2005
/
A
t
o
m
}
\{http://www.w3.org/2005/Atom\}
{http://www.w3.org/2005/Atom}指示搜索范围仅在名字空间
A
t
o
m
Atom
Atom中。 * 表示任意本地名(
l
o
c
a
l
n
a
m
e
local\ name
local name)的元素。
[
@
h
r
e
f
]
[@href]
[@href]表示含有
h
r
e
f
href
href属性。
③
③
③该查询找出所有包含
h
r
e
f
href
href属性并且其值为
h
t
t
p
:
/
/
d
i
v
e
i
n
t
o
m
a
r
k
.
o
r
g
/
http://diveintomark.org/
http://diveintomark.org/的
A
t
o
m
Atom
Atom元素。
④
④
④在简单的字符串格式化后(要不然这条复合查询语句会变得特别长),它搜索名字空间
A
t
o
m
Atom
Atom中包含
u
r
i
uri
uri元素作为子元素的
a
u
t
h
o
r
author
author元素。该条语句只返回了第一个和第二个
e
n
t
r
y
entry
entry元素中的
a
u
t
h
o
r
author
author元素。最后一个
e
n
t
r
y
entry
entry元素中的
a
u
t
h
o
r
author
author只包含有
n
a
m
e
name
name属性,没有
u
r
i
uri
uri。
仍然不够用?
l
x
m
l
lxml
lxml也集成了对任意
X
P
a
t
h
1.0
XPath 1.0
XPath1.0表达式的支持。我们不会深入讲解
X
P
a
t
h
XPath
XPath的语法;那可能需要一整本书!但是我会给你展示它是如何集成到
l
x
m
l
lxml
lxml去的。

①
①
①要查询名字空间中的元素,首先需要定义一个名字空间前缀映射。它就是一个
P
y
t
h
o
n
Python
Python字典对象。
②
②
②这就是一个
X
P
a
t
h
XPath
XPath查询请求。这个
X
P
a
t
h
XPath
XPath表达式目的在于搜索
c
a
t
e
g
o
r
y
category
category元素,并且该元素包含有值为
a
c
c
e
s
s
i
b
i
l
i
t
y
accessibility
accessibility的
t
e
r
m
term
term属性。但是那并不是查询的结果。请看查询字符串的尾端;是否注意到了
/
.
.
/..
/..这一块?它的意思是,“然后返回已经找到的
c
a
t
e
g
o
r
y
category
category元素的父元素。”所以这条
X
P
a
t
h
XPath
XPath查询语句会找到所有包含<category term='accessibility'>作为子元素的条目。
③
X
P
a
t
h
(
)
③XPath()
③XPath()函数返回一个
E
l
e
m
e
n
t
T
r
e
e
ElementTree
ElementTree对象列表。在这篇文档中,只有一个
c
a
t
e
g
o
r
y
category
category元素,并且它的
t
e
r
m
term
term属性值为
a
c
c
e
s
s
i
b
i
l
i
t
y
accessibility
accessibility。
④
X
P
a
t
h
④XPath
④XPath表达式并不总是会返回一个元素列表。技术上说,一个解析了的
x
m
l
xml
xml文档的
d
o
m
dom
dom模型并不包含元素;它只包含结点(
n
o
d
e
node
node)。依据它们的类型,结点可以是元素,属性,甚至是文本内容。
X
P
a
t
h
XPath
XPath查询的结果是一个结点列表。当前查询返回一个文本结点列表:
t
i
t
l
e
title
title元素(
a
t
o
m
:
t
i
t
l
e
atom:title
atom:title)的文本内容(
t
e
x
t
(
)
text()
text()),并且
t
i
t
l
e
title
title元素必须是当前元素的子元素(
.
/
./
./)。
6.生成XML

①
①
①实例化
E
l
e
m
e
n
t
Element
Element类来创建一个新元素。可以将元素的名字(名字空间 + 本地名)作为其第一个参数。当前语句在
A
t
o
m
Atom
Atom名字空间中创建一个
f
e
e
d
feed
feed元素。它将会成为我们文档的根元素。
②
②
②将属性名和值构成的字典对象传递给
a
t
t
r
i
b
attrib
attrib参数,这样就可以给新创建的元素添加属性。请注意,属性名应该使用标准的
E
l
e
m
e
n
t
T
r
e
e
ElementTree
ElementTree格式,
{
n
a
m
e
s
p
a
c
e
}
l
o
c
a
l
n
a
m
e
\{namespace\}localname
{namespace}localname。
③
③
③在任何时候,我们可以使用
E
l
e
m
e
n
t
T
r
e
e
ElementTree
ElementTree的
t
o
s
t
r
i
n
g
(
)
tostring()
tostring()函数序列化任意元素(还有它的子元素)。
这种序列化结果有使你感到意外吗?技术上说,
E
l
e
m
e
n
t
T
r
e
e
ElementTree
ElementTree使用的序列化方法是精确的,但却不是最理想的。在本章开头给出的
x
m
l
xml
xml样例文档中定义了一个默认名字空间(
d
e
f
a
u
l
t
n
a
m
e
s
p
a
c
e
default\ namespace
default namespace)(
x
m
l
n
s
=
′
h
t
t
p
:
/
/
w
w
w
.
w
3.
o
r
g
/
2005
/
A
t
o
m
′
xmlns='http://www.w3.org/2005/Atom'
xmlns=′http://www.w3.org/2005/Atom′)。对于每个元素都在同一个名字空间中的文档 — 比如
A
t
o
m
f
e
e
d
s
Atom\ feeds
Atom feeds — 定义默认的名字空间非常有用,因为只需要声明一次名字空间,然后在声明每个元素的时候只需要使用其本地名即可(<feed>,<link>,<entry>)。除非想要定义另外一个名字空间中的元素,否则没有必要使用前缀。

实际上唯一不同的只是第二个序列化短了几个字符长度。如果我们改动整个样例
f
e
e
d
feed
feed,使每一个起始和结束标签都有一个
n
s
0
:
ns0:
ns0:前缀,这将为每个起始标签增加
4
4
4 个字符 ×
79
79
79 个标签 +
4
4
4 个名字空间声明本身用到的字符,总共
320
320
320个字符。假设我们使用
U
T
F
−
8
UTF-8
UTF−8编码,那将是
320
320
320个额外的字节(使用
g
z
i
p
gzip
gzip压缩以后,大小可以降到
21
21
21个字节,但是,
21
21
21个字节也是字节)。也许对个人来说这算不了什么,但是对于像
A
t
o
m
f
e
e
d
Atom\ feed
Atom feed这样的东西,只要稍有改变就有可能被下载上千次,每一个请求节约的几个字节就会迅速累加起来。
①
①
①首先,定义一个用于名字空间映射的字典对象。其值为名字空间;字典中的键即为所需要的前缀。使用
N
o
n
e
None
None作为前缀来定义默认的名字空间。
②
②
②现在我们可以在创建元素的时候,给
l
x
m
l
lxml
lxml专有的
n
s
m
a
p
nsmap
nsmap参数传值,并且
l
x
m
l
lxml
lxml会参照我们所定义的名字空间前缀。
③
③
③如所预期的那样,该序列化使用
A
t
o
m
Atom
Atom作为默认的名字空间,并且在声明
f
e
e
d
feed
feed元素的时候没有使用名字空间前缀。
④
④
④啊噢… 我们忘了加上
x
m
l
:
l
a
n
g
xml:lang
xml:lang属性。我们可以使用
s
e
t
(
)
set()
set()方法来随时给元素添加所需属性。该方法使用两个参数:标准
E
l
e
m
e
n
t
T
r
e
e
ElementTree
ElementTree格式的属性名,然后,属性值。(该方法不是
l
x
m
l
lxml
lxml特有的,在该样例中,只有
n
s
m
a
p
nsmap
nsmap参数是
l
x
m
l
lxml
lxml特有的,它用来控制序列化输出时名字空间的前缀。)
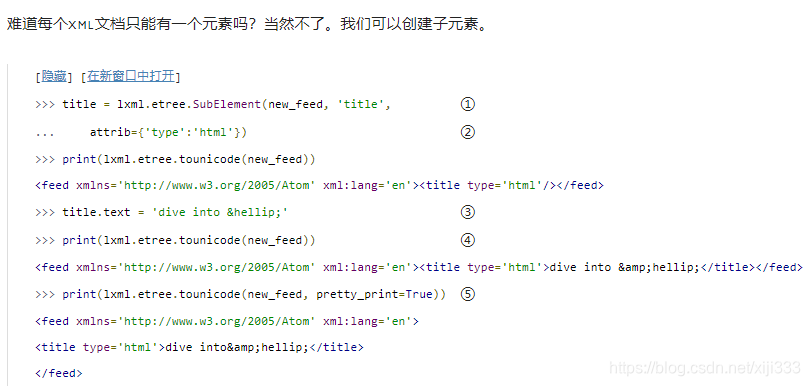
①给已有元素创建子元素,我们需要实例化
S
u
b
E
l
e
m
e
n
t
SubElement
SubElement类。它只要求两个参数,父元素(即该样例中的
n
e
w
_
f
e
e
d
new\_feed
new_feed)和子元素的名字。由于该子元素会从父元素那儿继承名字空间的映射关系,所以这里不需要再声明名字空间前缀。
②我们也可以传递属性字典给它。字典的键即属性名;值为属性的值。
③如预期的那样,新创建的
t
i
t
l
e
title
title元素在
A
t
o
m
Atom
Atom名字空间中,并且它作为子元素插入到
f
e
e
d
feed
feed元素中。由于
t
i
t
l
e
title
title元素没有文件内容,也没有其子元素,所以
l
x
m
l
lxml
lxml将其序列化为一个空元素(使用</>)。
④设定元素的文本内容,只需要设定其
.
t
e
x
t
.text
.text属性。
⑤当前
t
i
t
l
e
title
title元素序列化的时候就使用了其文本内容。任何包含了<或者&符号的内容在序列化的时候需要被转义。
l
x
m
l
lxml
lxml会自动处理转义。
7.解析破损的XML
x m l xml xml规范文档中指出,要求所有遵循 x m l xml xml规范的解析器使用“严厉的(draconian)错误处理”。即,当它们在 x m l xml xml文档中检测到任何编排良好性(wellformedness)错误的时候,应当立即停止解析。编排良好性错误包括不匹配的起始和结束标签,未定义的实体( e n t i t y entity entity),非法的 U n i c o d e Unicode Unicode字符,还有一些只有内行才懂的规则( e s o t e r i c r u l e s esoteric\ rules esoteric rules)。这与其他的常见格式,比如 h t m l html html,形成了鲜明的对比 — 即使忘记了封闭 h t m l html html标签,或者在属性值中忘了转义&字符,我们的浏览器也不会停止渲染一个 W e b Web Web页面。(通常大家认为 h t m l html html没有错误处理机制,这是一个常见的误解。 h t m l html html的错误处理实际上被很好的定义了,但是它比“遇见第一个错误即停止”这种机制要复杂得多。)
一些人(包括我自己)认为 x m l xml xml的设计者强制实行这种严格的错误处理本身是一个失误。请不要误解我;我当然能看到简化错误处理机制的优势。但是在现实中,“编排良好性”这种构想比乍听上去更加复杂,特别是对 x m l xml xml(比如 A t o m f e e d s Atom\ feeds Atom feeds)这种发布在网络上,通过 h t t p http http传播的文档。早在1997年 x m l xml xml就标准化了这种严厉的错误处理,尽管 x m l xml xml已经非常成熟,研究一直表明,网络上相当一部分的 A t o m f e e d s Atom\ feeds Atom feeds仍然存在着编排完整性错误。
所以,从理论上和实际应用两种角度来看,我有理由“不惜任何代价”来解析
x
m
l
xml
xml文档,即,当遇到编排良好性错误时,不会中断解析操作。如果你认为你也需要这样做,
l
x
m
l
lxml
lxml可以助你一臂之力。

因为实体…并没有在
x
m
l
xml
xml中被定义,所以这算作一个错误(它在
h
t
m
l
html
html中被定义)。如果我们尝试使用默认的设置来解析该破损的
f
e
e
d
feed
feed,
l
x
m
l
lxml
lxml会因为这个未定义的实体而停下来。
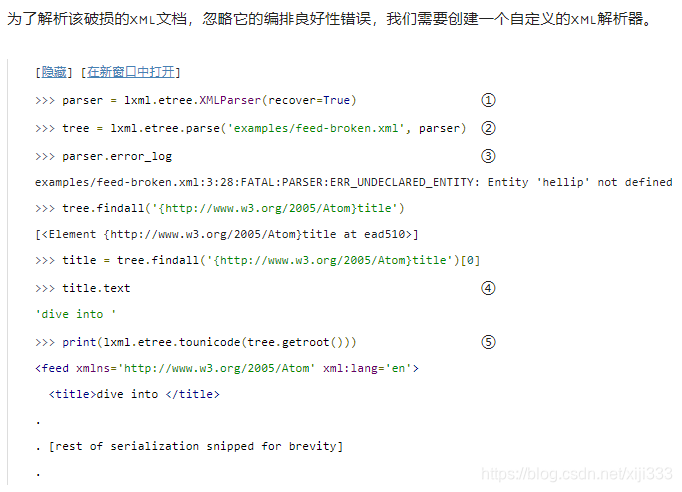
①实例化
l
x
m
l
.
e
t
r
e
e
.
X
M
L
P
a
r
s
e
r
lxml.etree.XMLParser
lxml.etree.XMLParser类来创建一个自定义的解析器。它可以使用许多不同的命名参数。在此,我们感兴趣的为
r
e
c
o
v
e
r
recover
recover参数。当它的值被设为
T
r
u
e
True
True,
x
m
l
xml
xml解析器会尽力尝试从编排良好性错误中“恢复”。
②为使用自定的解析器来处理
x
m
l
xml
xml文档,将对象
p
a
r
s
e
r
parser
parser作为第二个参数传递给
p
a
r
s
e
(
)
parse()
parse()函数。注意,
l
x
m
l
lxml
lxml没有因为那个未定义的…实体而抛出异常。
③解析器会记录它所遇到的所有编排良好性错误(无论它是否被设置为需要从错误中恢复,这个记录总会存在)。
④由于不知道如果处理该未定义的…实体,解析器默认会将其省略掉。
t
i
t
l
e
title
title元素的文本内容变成了’dive into '。
⑤从序列化的结果可以看出,实体…并没有被移到其他地方去;它就是被省略了。
在此,必须反复强调,这种“可恢复的”
x
m
l
xml
xml解析器没有互用性(interoperability)保证。另一个不同的解析器可能就会认为…来自
h
t
m
l
html
html,然后将其替换为…。这样“更好”吗?也许吧。这样“更正确”吗?不,两种处理方法都不正确。正确的行为(根据
x
m
l
xml
xml规范)应该是终止解析操作。如果你已经决定不按规范来,你得自己负责。