- 很亢奋,今年终迎来了算子大比。在交流前先感谢算子相关工作人员的辛勤付出,才能有牛刀小试的机会,辛苦了
- 其次,这里分享的个人的一点小小的不成器思路,如果有更好的解题思路,或者优化方案,还望大家多交流,不吝指教

- 具体的Pytorch调用公式如下,公式计算不难
- 首先要考虑value在Pytorch是标量,但是案例中是tensor
- 那么我们需要tensor输入转value标量,再调用标量乘法API
- 通过tiling引入plusvalue变量并输入this->plusvalue
half buf = static_cast<half>(this->plusvalue);
Muls(calcBuf1Local,calcBuf1Local,buf,this->tileLength);复制
- 关于这道题目,官方提供了5个测试案例,个人认为第四题是当仁不让的难中之王,理由如下
- 需要考虑INT8的格式转换,查找官方文档Muls计算并不支持INT8格式
- Atlas 200/500 A2推理产品,支持的数据类型为:Tensor(half/int16_t/float/int32_t)
- 所以个人思路是需要将输入INT8格式转换为half类型或者其他类型,进行运算
- 最后将运算后的结果重新再转换为INT8格式输出
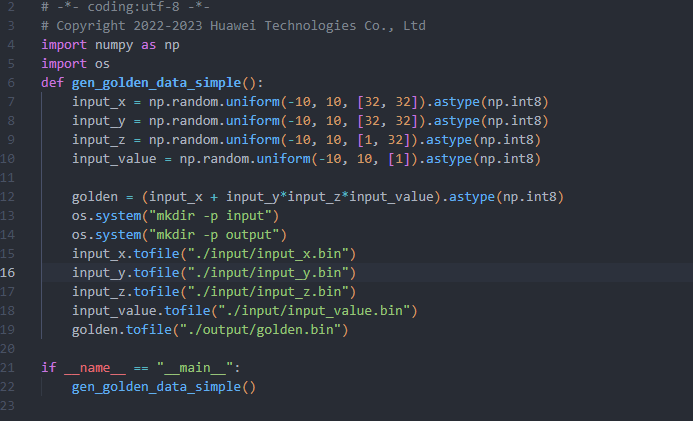

- 具体的一个API思路如下
Cast(calcBuf1Local,x1LocalLocal,RoundMode::CAST_NONE,this->tileLength);
Cast(calcBuf2Local,x2LocalLocal,RoundMode::CAST_NONE,this->tileLength);
Mul(calcBuf1Local,calcBuf1Local,calcBuf2Local,this->tileLength);
half buf = static_cast<half>(this->plusvalue);
Muls(calcBuf1Local,calcBuf1Local,buf,this->tileLength);
Cast(calcBuf2Local,input_dataLocal,RoundMode::CAST_NONE,this->tileLength);
Add(calcBuf1Local,calcBuf1Local,calcBuf2Local, this->tileLength);
Cast(yLocal,calcBuf1Local,RoundMode::CAST_CEIL,this->tileLength);复制- 类型转换API完成,那么如何嵌入主题代码呢?
- 个人思路是通过tiling中对类型进行识别再通过 this->inputtype 自定义变量来辨别计算公式
__aicore__ inline void Process() {
CopyInit();
int32_t loopCount = this->tileNumy * BUFFER_NUM;
if (this->inputtype != 2) {
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
else if (this->inputtype == 2) {
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute_int8(i);
CopyOut(i);
}
}
}复制- 前面提到类型识别,具体API是什么呢?
- dt 与 数字绑定 在文档里搜索就可以
auto dt = context->GetInputTensor(0)->GetDataType();//获取DataType类型的属性值。
tiling.set_inputtype(dt);//如果真要改,这里还要考虑多数据类型的计算
if (dt == 1) {//DT_FLOAT16 = 1, // fp16 type
sizeofdatatype = 2;
}else if (dt == 0) {// DT_FLOAT = 0, // float type
sizeofdatatype = 4;
}else if (dt == 2){ // DT_INT8 = 2, // int8 type
sizeofdatatype = 1;
}else if(dt == 3){ // DT_INT32 = 3
sizeofdatatype = 4;
}else
{
return ge::GRAPH_FAILED;
}复制- 解决了类型转换后,最重要的问题就是如何解决{1,32}Tensor与{32,32}Tensor相乘问题
- 解决方案就是需要广播,但是不幸的是AscendC广播指令具体API在下一个版本才公布,那么不就是瞎子摸象
- 个人的思路是只解决二维Tensor之间的乘法,更高维的Tensor暂时不支持
- 解决方案就是暴力拆解
- 如果是{1,32}1行32列,那么将行复制32次,构成{32,32}
- 如果是{32,1}32行1列,那么讲列复制32次,构成{32,32}
- 看上去很简单,但是实施起来还要考虑很多问题
- GM 与 LocalTensor之间的内存交换问题
- BUFFER_NUM乒乓操作的内存分割问题
- tileLength和lasttileLength的内存使用问题
- 数据对齐后使得blocklength变大,取值难度增加问题
- 这里只粘贴部分代码展示思路
if (BUFFER_NUM == 2) {
//开启double
//buffer时,由于将输入数据分成了相等的2部分,分块大小为不开启double
//buffer的一半, 所以需要对最后两个分块数据的起始地址做处理
if ((progress == (this->tileNumy * BUFFER_NUM - 2)) ||
(progress == (this->tileNumy * BUFFER_NUM - 1))) {
//分块大小变为tileLength的一半
//倒数第2个分块数据的起始地址向前移动(tileLength-lasttileLength),最后一个分块的起始地址以此为基础进行移动
// DataCopy(inLocal[this->tileLength + this->tileLength1],x2Gm[(progress - 2) * (this->tileLength2) + this->lasttileLength2],(this->tileLength2));
if(this->OneX2Buf[1] == 1)
{
// DataCopy(inLocal[this->tileLength + this->tileLength1],x2Gm[((progress - 2) * (this->tileLengthy) + this->lasttileLengthy)%(this->axis0)], this->tileLengthy);
for (i = 0;i<this->tileLengthy;i++)
{
inLocal.SetValue(this->tileLength + this->tileLength1 + i,x2Gm.GetValue(((progress - 2) * (this->tileLengthy) + this->lasttileLengthy+i)%(this->axis0)));
}
}
else if(this->OneX2Buf[0] == 1)
{
if(((progress + 1)* this->tileLengthy) > (this->axis0 * this->axisy))
{
for (i = 0;i<(this->axis0 * this->axisy - ((progress)* this->tileLengthy));i++)
{
inLocal.SetValue(this->tileLength + this->tileLength1 + i,x2Gm.GetValue(this->axisy-1));
}
for (i = 0;i<(((progress + 1)* this->tileLengthy) - this->axis0 * (this->axisy));i++)
{
inLocal.SetValue(this->tileLength + this->tileLength1 + i + (this->axis0 * this->axisy - ((progress)* this->tileLengthy)),x2Gm.GetValue(this->axisy));
}
this->axisy = this->axisy + 1;
}
else if (((progress + 1)* this->tileLengthy) == (this->axis0 * this->axisy))
{
for (i = 0;i<this->tileLengthy;i++)
{
inLocal.SetValue(this->tileLength + this->tileLength1 + i,x2Gm.GetValue(this->axisy-1));
}
this->axisy = 1;
}
else if (((progress + 1)*this->tileLengthy) < (this->axis0 * this->axisy))
{
for (i = 0;i<this->tileLengthy;i++)
{
inLocal.SetValue(this->tileLength + this->tileLength1 + i,x2Gm.GetValue(this->axisy-1));
}
}
}
else{
DataCopy(
inLocal[this->tileLength + this->tileLength1],
x2Gm[(progress - 2) * (this->tileLengthy) + this->lasttileLengthy],
(this->tileLengthy));
}
}
else {
// inLocal.SetValue(this->tileLength + this->tileLength1+i,calcBuf4Local.GetValue(progress * this->tileLengthy +i));
if(this->OneX2Buf[1] == 1)
{
// DataCopy(inLocal[this->tileLength + this->tileLength1],x2Gm[((progress )* this->tileLengthy)%(this->axis0)], this->tileLengthy);
for (i = 0;i<this->tileLengthy;i++)
{
inLocal.SetValue(this->tileLength + this->tileLength1 + i,x2Gm.GetValue(((progress )* this->tileLengthy + i)%(this->axis0)));
}
}
else if(this->OneX2Buf[0] == 1)
{
if(((progress + 1)* this->tileLengthy) > (this->axis0 * this->axisy))
{
for (i = 0;i<(this->axis0 * this->axisy - ((progress)* this->tileLengthy));i++)
{
inLocal.SetValue(this->tileLength + this->tileLength1 + i,x2Gm.GetValue(this->axisy-1));
}
for (i = 0;i<(((progress + 1)* this->tileLengthy) - this->axis0 * (this->axisy));i++)
{
inLocal.SetValue(this->tileLength + this->tileLength1 + i + (this->axis0 * this->axisy - ((progress)* this->tileLengthy)),x2Gm.GetValue(this->axisy));
}
this->axisy = this->axisy + 1;
}
else if (((progress + 1)* this->tileLengthy) == (this->axis0 * this->axisy))
{
for (i = 0;i<this->tileLengthy;i++)
{
inLocal.SetValue(this->tileLength + this->tileLength1 + i,x2Gm.GetValue(this->axisy-1));
}
this->axisy = this->axisy + 1;
}
else if (((progress + 1)*this->tileLengthy) < (this->axis0 * this->axisy))
{
for (i = 0;i<this->tileLengthy;i++)
{
inLocal.SetValue(this->tileLength + this->tileLength1 + i,x2Gm.GetValue(this->axisy-1));
}
}
}
else{
DataCopy(inLocal[this->tileLength + this->tileLength1],x2Gm[progress * this->tileLengthy], this->tileLengthy);
}
}
}
inQueueIN.EnQue(inLocal);
}复制- 解决了这个问题后还有一个大问题需要解决
- Tensor的范围是【-10,10】
- 这就有问题了,可能会超过范围,那么溢出时,得到数值是多少,会跟C编译器一样吗?
- 这个见文档可知,cast 将src按照round_mode取整,以int8_t格式(溢出默认按照饱和处理)2^7-1存入dst中
- 这里本人并没有着手处理,只是修改范围【-5,5】然后测试
- 在编程过程中肯定遇到很多迷之BUG,那么如何定位呢?
- op_host直接printf
- op_kernel ,dump_tensor-PRINTF本版本暂不支持,只能看看/var/log/npu/slog/debug/device-app-974443
- 但是个人看来,定位能力还是较弱
- 如果有更好定位方式,望告知
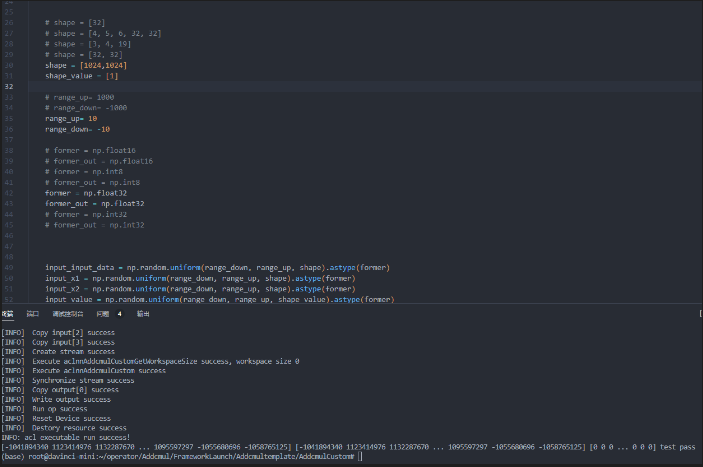
- 最后展示下5个测试案例的测试结果
- 案例一
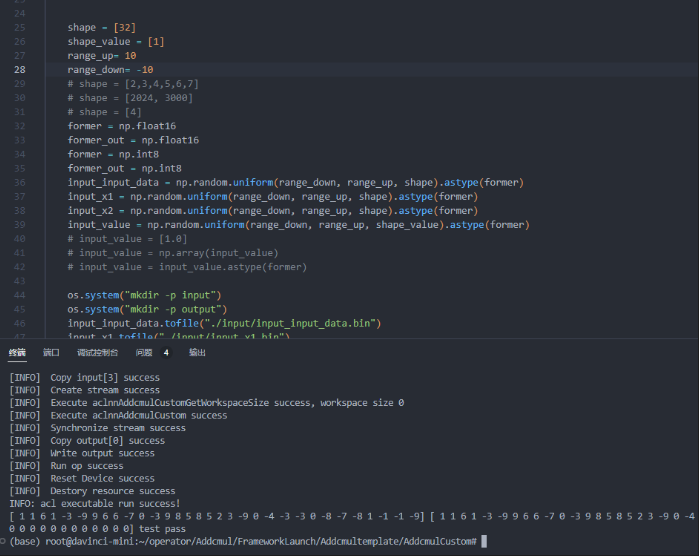
- 案例二
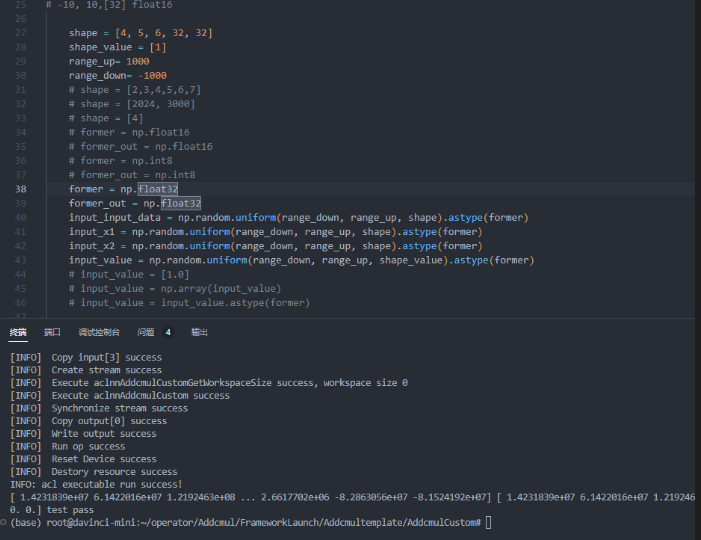
- 案例三
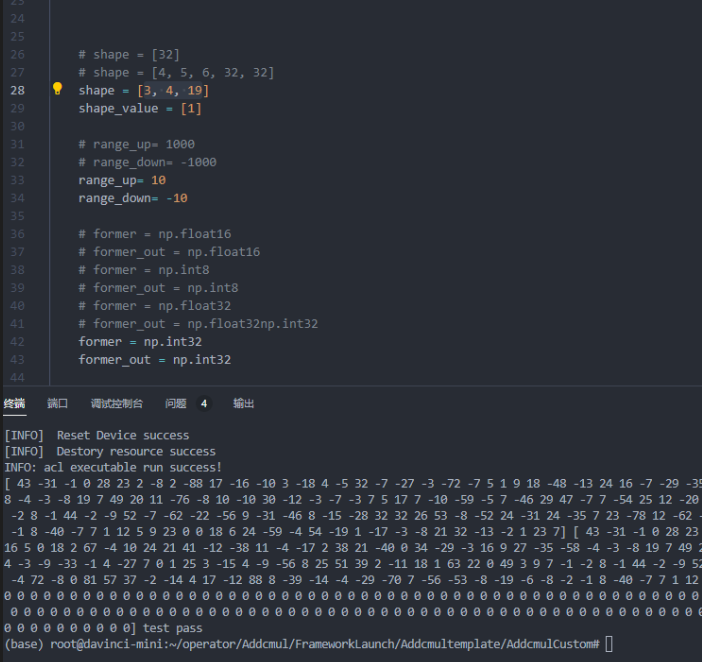
- 案例四
- 案例五