目标:分析学生成绩的影响因素
1.导入原始数据,以及需要用到的库
import pandas as pd
import numpy as np
df = pd.read_csv('StudentsPerformance.csv')
(数据来源于kaggle)
2.查看文件
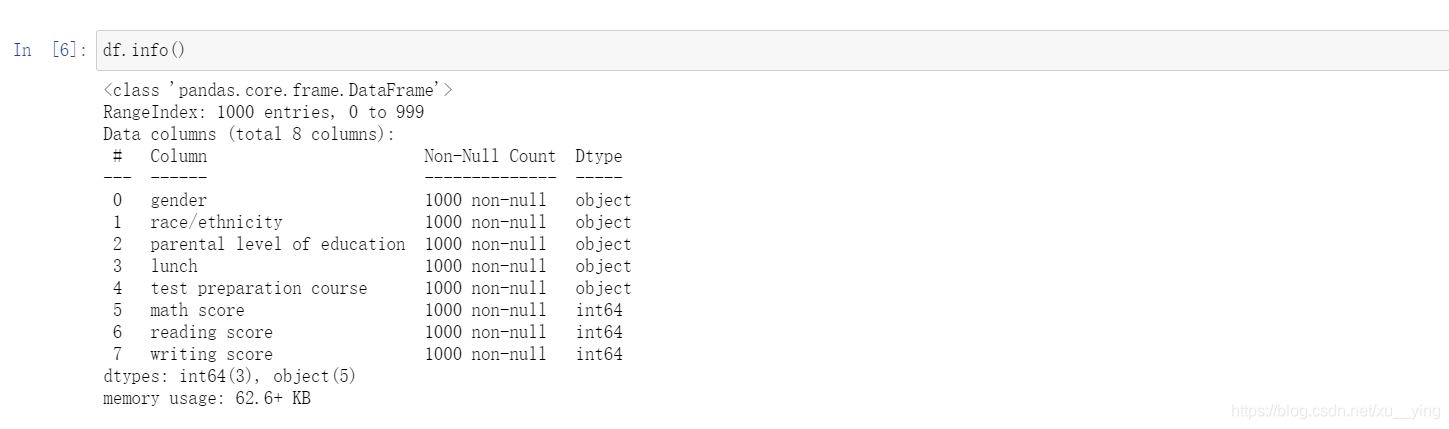
从上面的信息可以看出这一千个学生的数据中是没有空值,而且可以看出各列数据的类型。
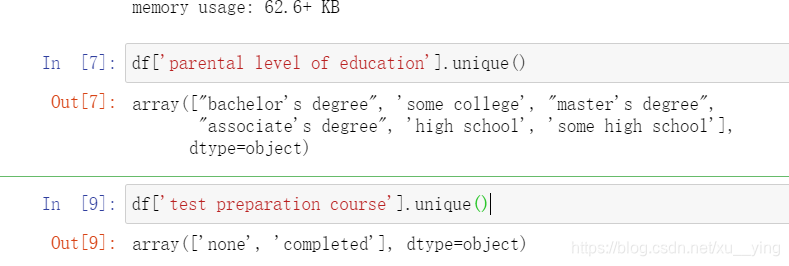
还可以通过unique来查看某列数据都有哪些值,是否有无效数据。
df['parental level of education'].unique()
df['test preparation course'].unique()
再来查看成绩是否为有效值(使用loc)
df.loc[(df['math score']<0) | (df['math score']>100) | (df['reading score']<0) | (df['reading score']>100) | (df['writing score']<0) | (df['writing score']>100)]
可以看出成绩中没有无效值

3.数据处理
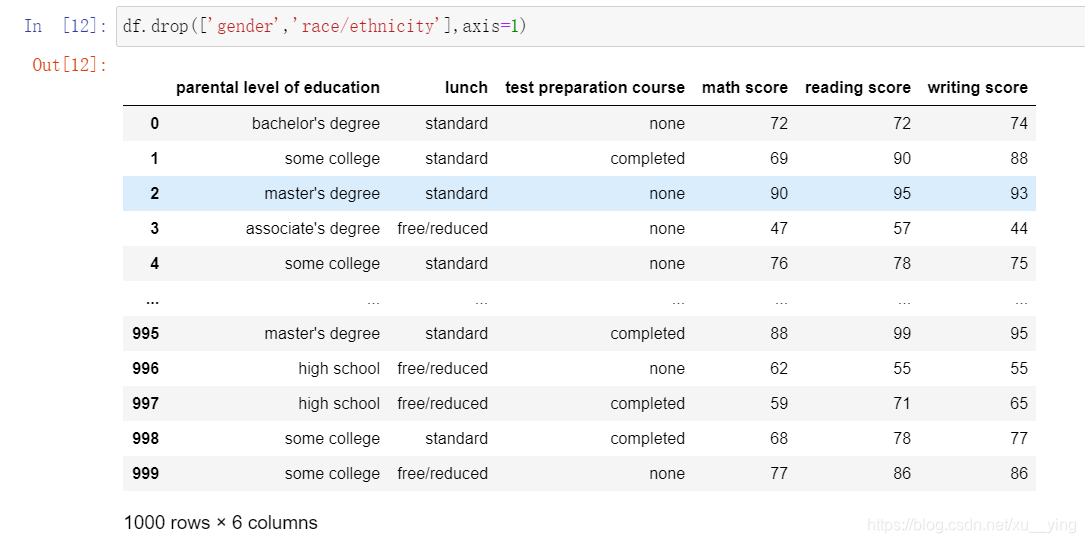
根据目标,删除一些不需要的列(使用drop)
df.drop(['gender','race/ethnicity'],axis=1)
#参数axis默认值为0,指行,要删除列的话将axis设为1
df_1 = df.drop(['gender','race/ethnicity'],axis=1)
求学生成绩平均值
df_1['average']= round((df_1['math score']+df_1['reading score']+df_1['writing score'])/3)
#round()用来对数据四舍五入
4.分析学生成绩影响因素
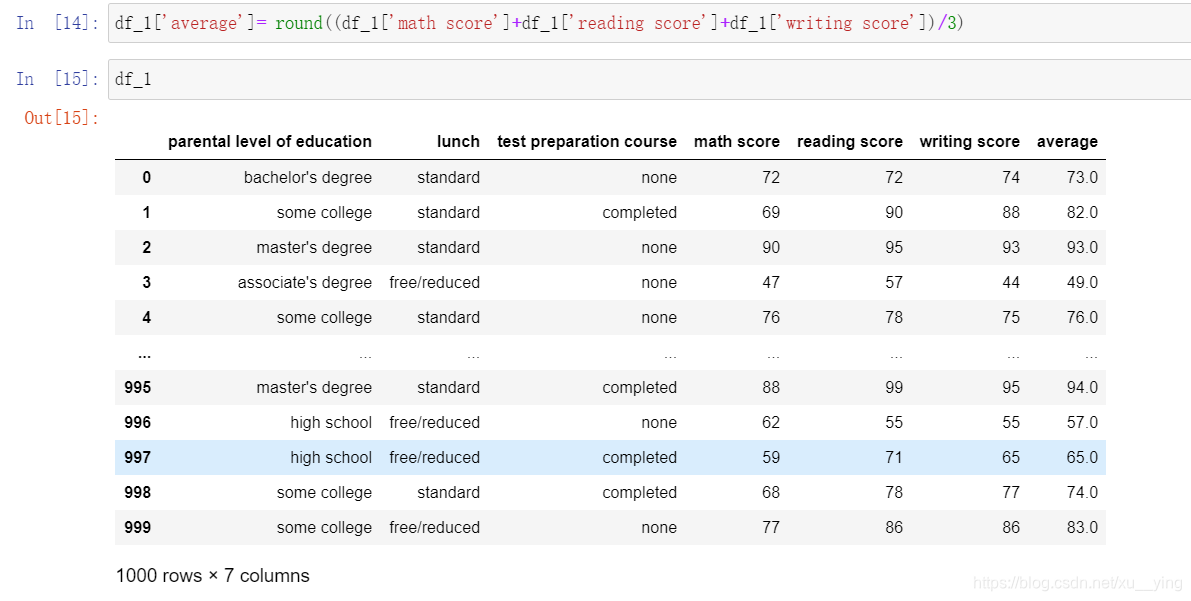
df_1.groupby('parental level of education')['average'].agg([np.mean]).plot.bar()
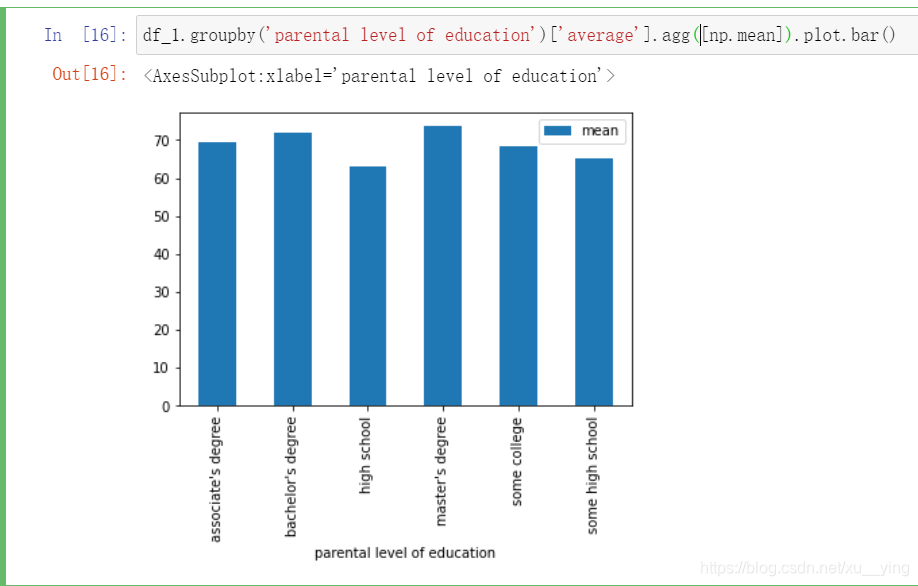
df_1.groupby('lunch')['average'].agg([np.mean]).plot.bar()
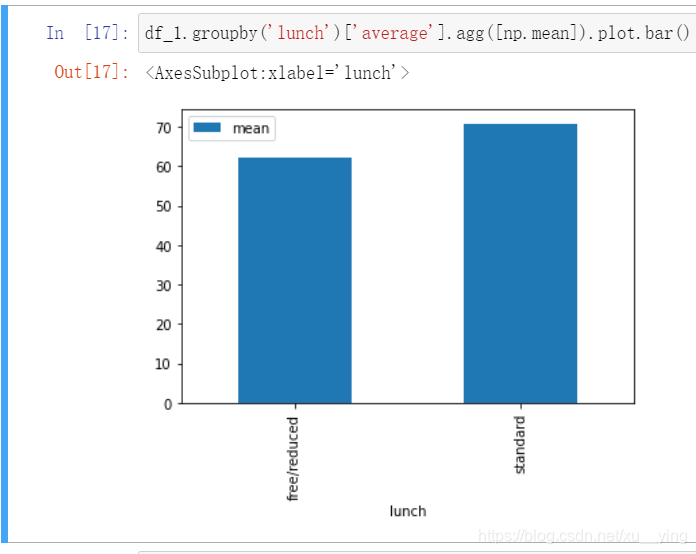
df_1.groupby('test preparation course')['average'].agg([np.mean]).plot.bar()
从上面三张图可以初步得出结论:
1.父母学历越高,学生成绩越好
2.午餐吃的好的同学成绩较高
3.考试准备充分的同学成绩较高
以下,用相关系数分析父母学历对哪科成绩影响最大
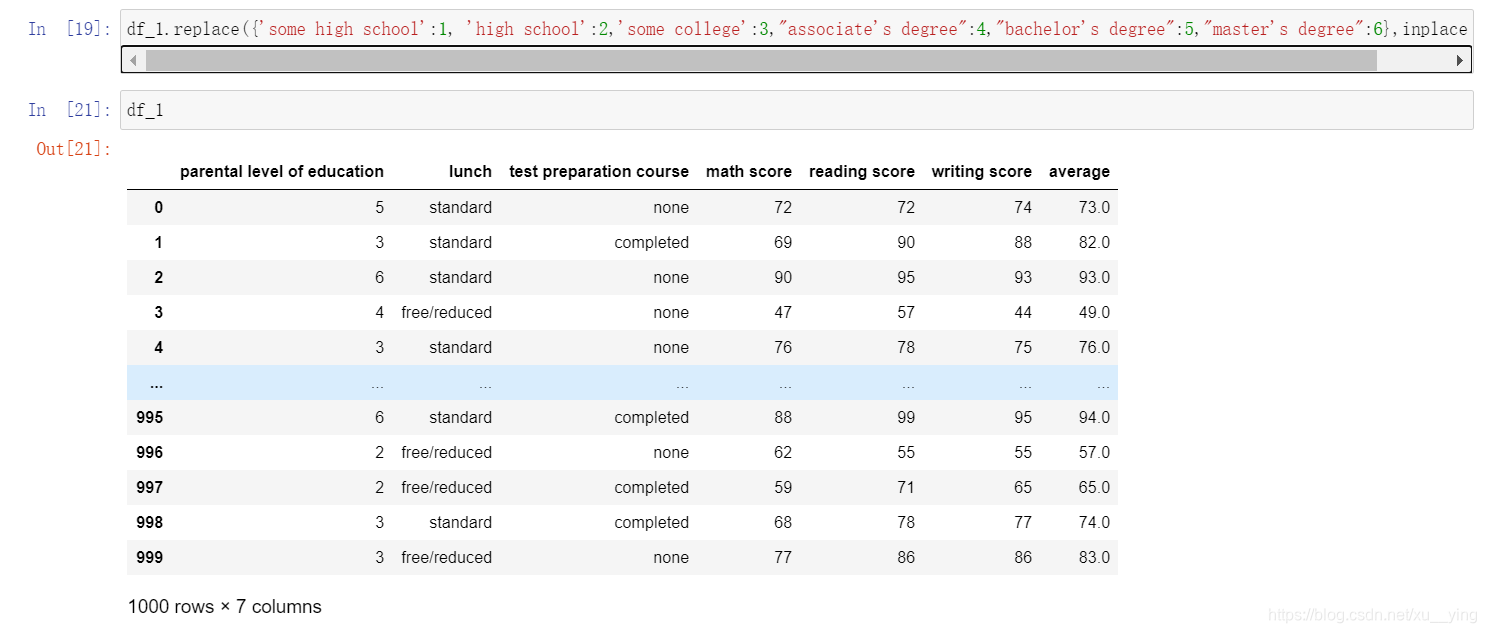
先按照父母学历高低将表中数据替换为数值
df_1.replace({'some high school':1, 'high school':2,'some college':3,"associate's degree":4,"bachelor's degree":5,"master's degree":6},inplace = True)
#inplace = True是为了改变文档的源数据
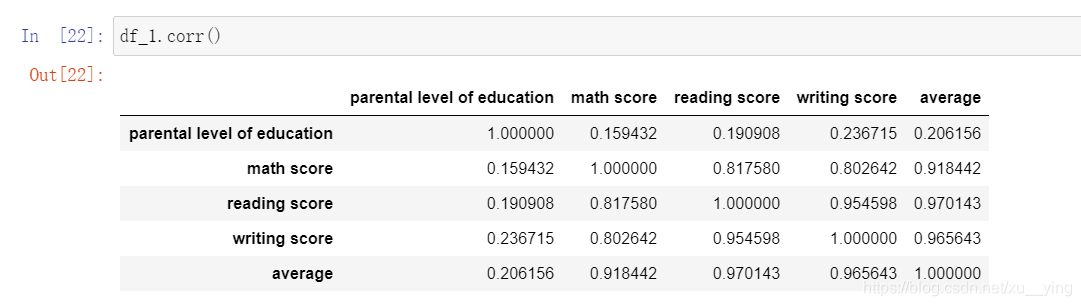
用corr求出相关系数(相关系数接近0,说明相关性小,越接近1,正相关性越强,越接近-1,负相关性越强)
根据父母学历与学生数学、阅读、写作成绩的相关系数,可以看出,父母学历与三者都成正相关,其中与写作成绩相关性最强,而且各科之间相关性都很强,说明某一科成绩好的同学其他科成绩很可能也好。
5.结论
通过以上分析,可以初步得出以下的结论:
1.父母学历越高,学生成绩越好(对写作成绩的影响最大)
2.午餐吃的好的同学成绩较高
3.考试准备充分的同学成绩较高
4.某科成绩好的学生其他科成绩也较好(其中写作与阅读成绩相关性最强)