| 版本 | 内容 | 姓名 | 时间 |
| V1.0 | 新建 | xx | 2025-01-16 |
声明:只是进行探究,后续真正实践后,会更新新的内容
前置条件:70B的模型,并发要求200
性能测试参考链接
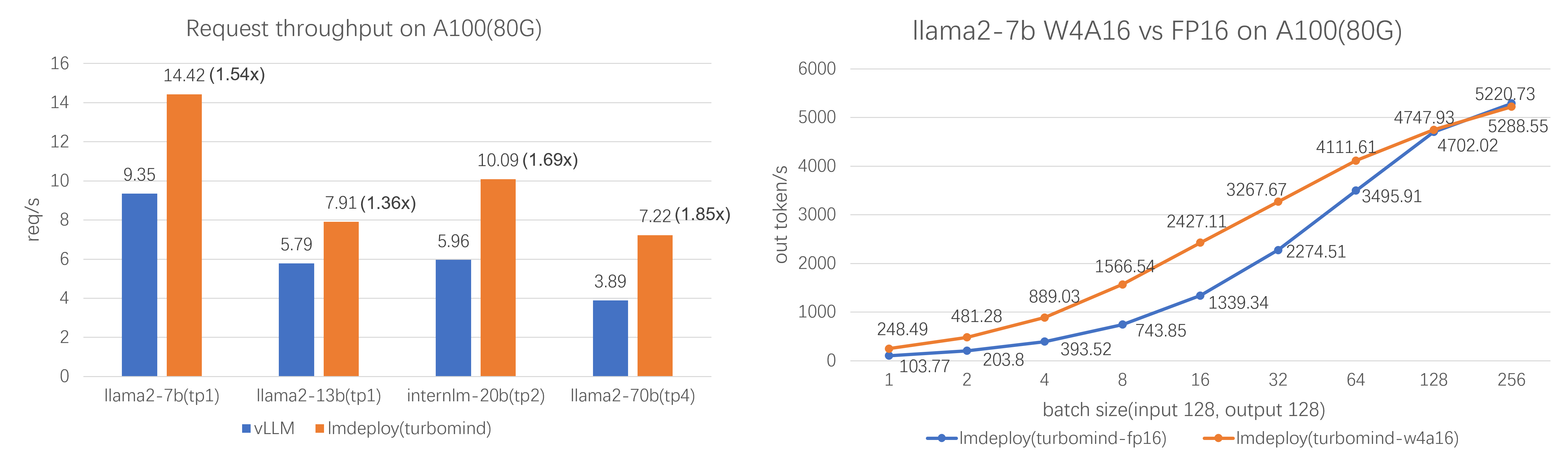
Benchmarking LLM Inference Backends :表明一台A100(80GB)能够进行70b 4bit量化后进行满足100并发。
部署大模型基础知识参考
Fundamental of Deploying Large Language Model Inference
1.显存需求分析
- 70B模型在FP8精度下单个模型加载约需要35GB显存
- 考虑到推理时的中间变量和缓存,建议预留1.5倍显存,即约52.5GB/模型
- 考虑KV Cache: 每个并发会话约需要0.5GB显存
- 200并发总共需要: 52GB + (0.5GB × 200) =152 GB显存
2.硬件配置建议
- 最低2卡,建议使用3卡服务器,GPU选型: NVIDIA H100 (80GB显存/卡)或A100 (80GB显存/卡)
3.部署方案
参考链接
vllm github: https://github.com/vllm-project/vllm
nccl:Overview of NCCL — NCCL 2.6.2 documentation
vllm+nccl: Vllm Nvlink NccL Integration | Restackio
vllm+nginx_loadbalancer+docker:Deploying with Nginx Loadbalancer — vLLM
3.1 为什么选择vllm进行推理?
- 社区稳定
- 可以高并发、多卡并行
- 有较多实践可以参考
3.2 具体方案
使用 多个 vLLM 实例 来利用 两张 /三张 A100 GPU ,对外提供接口。为保证用户对话的连续性,让nginx根据ip路由来进行分发请求 。
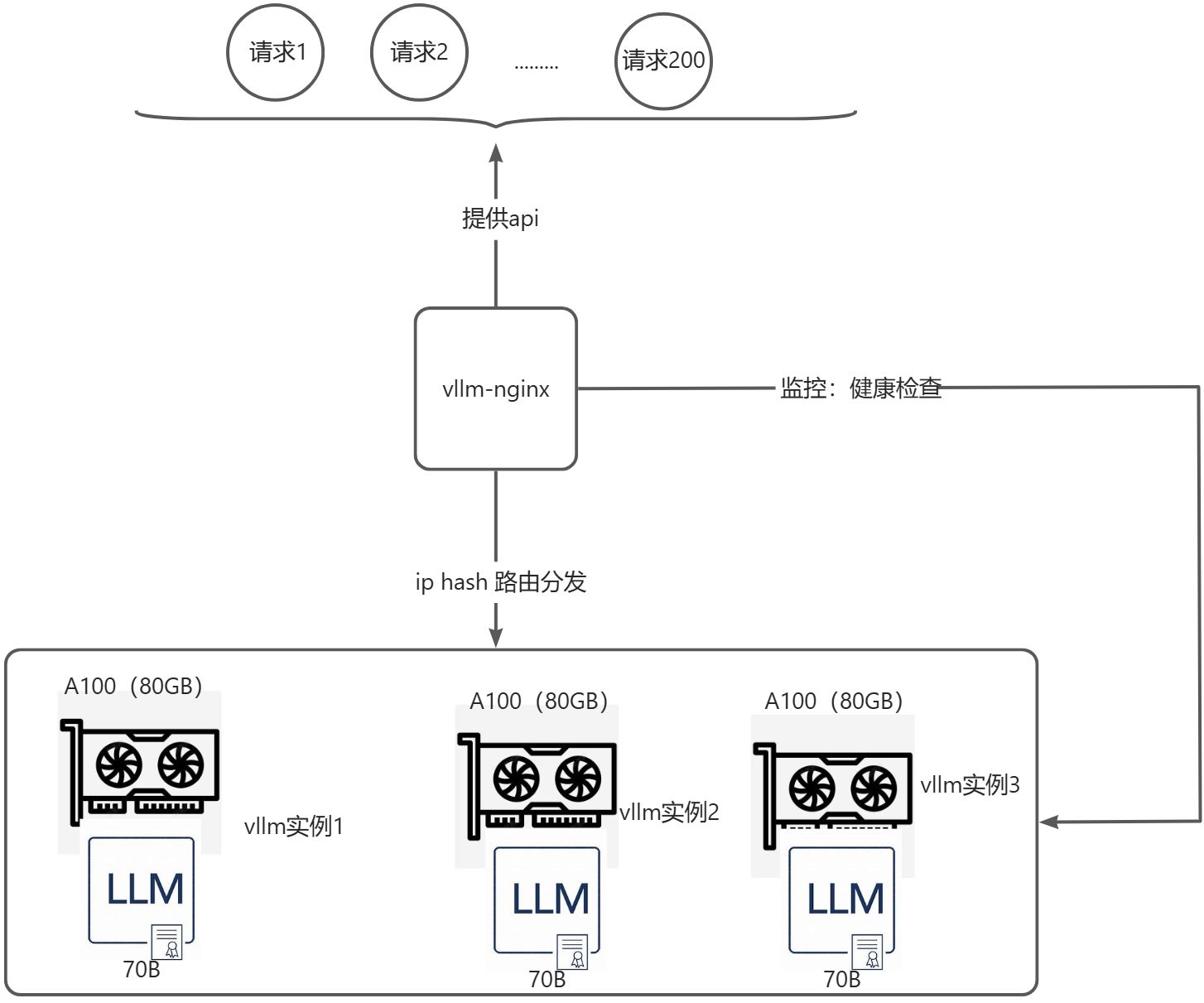
为什么使用nginx分发,多个vllm实例进行?而不利用nvidia nccl技术直接使用一个vllm实例?
- 负载均衡:Nginx分发请求,提升并发处理能力。
- 扩展性强:未来可轻松增加更多GPU和vLLM实例。
- 容错性高:单卡故障时,另一卡仍可继续服务。
- 适用机制:nccl适用于单卡无法加载模型时使用,多机多卡可作为性能补充优化。
3.3 关于吞吐量 vs 延迟说明
- 单实例多卡: 如果重点是吞吐量,使用单实例多卡的方式可能会更好,因为 vLLM 会在多个 GPU 上并行处理任务,且有 NCCL 加速优化。
- 多个实例+Nginx: 如果目标是更高的并发和更加细粒度的负载分配,且可以接受可能出现的小量跨实例通信延迟,使用多个实例和 Nginx 分发会更适合。
4.其他部署方案
4.1 k8s+llm
提醒:若目前使用,单卡能够加载的模型。不涉及分布式处理、多个资源调度,因运维复杂,建议不使用
| 工具 | 优点 | 缺点 | 参考链接 |
| SkyPilot | 自动资源调度、多云支持、简化部署 | 社区支持有限、主要面向云环境 | |
| KServe | 与 Kubernetes 集成、支持多种框架、自动化管理 | 依赖 Kubernetes、学习曲线较高 | |
| 自动化资源管理、高可用性、与云平台兼容 | 社区不稳定,成本较高、需要配置和集成工作 | ||
| Kubernetes | 强大的扩展性、容器化部署、广泛的生态系统支持 | 部署和管理复杂、性能调优需要经验 |
4.2 推理工具LMDeploy
https://github.com/InternLM/lmdeploy/blob/main/README_zh-CN.md
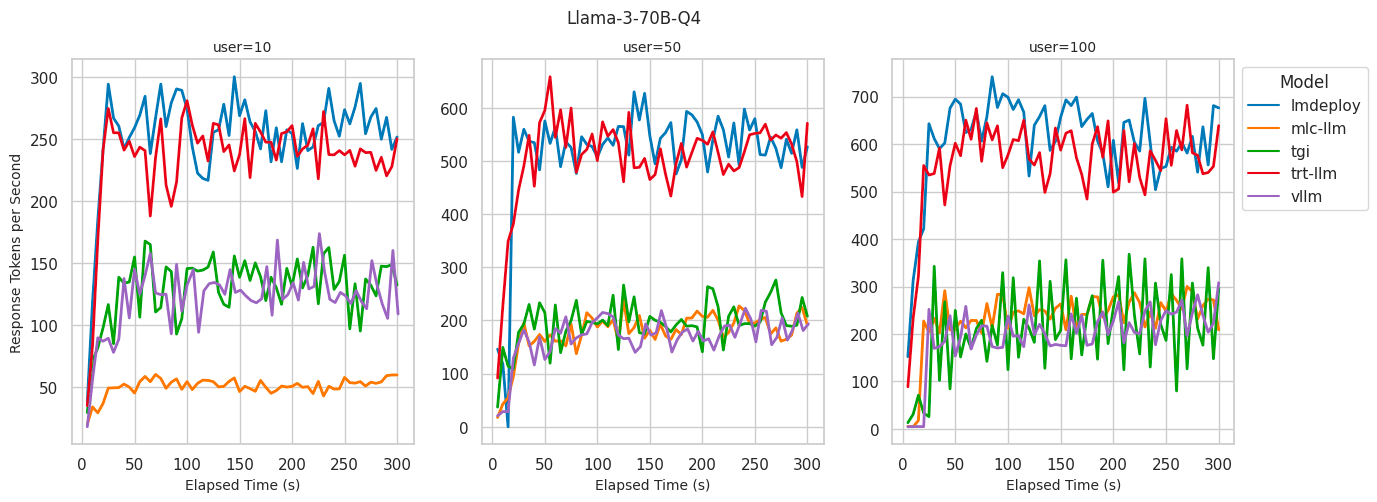
Lmdepoly 对比vllm推理简单测试效果较好,但社区实践较vllm少。可供后续推理工具的备选