导语:前场经常非法关机导致单机的etcd损坏。每次都重装k8s虽然比较简单,但是会相对耗时。
思路:通过cronjob类型去定时备份(cronjob备份可以确保每次备份的时候k8s状态是ok的),通过可执行文件在宿主机上进行恢复。
docker pull bitnami/etcd:3.5
cronjob.yaml如下
不用root去备份会报权限问题。
apiVersion: batch/v1beta1
kind: CronJob
metadata:
namespace: kube-system
name: etcd-backup
spec:
schedule: "0 20 * * *"
jobTemplate:
spec:
template:
metadata:
labels:
backup: "etcd"
spec:
containers:
- name: etcd-backup
image: bitnami/etcd:3.5
command:
- sh
- -c
- "etcdctl --endpoints 100.100.100.100:2379 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
snapshot save /backup/$(date +%Y%m%d_%H%M%S)_snapshot.db && echo etcd backup sucess"
#- "export ETCDCTL_API=3; etcdctl --endpoints $ENDPOINT snapshot save /backup/$(date +%Y%m%d_%H%M%S)_snapshot.db; echo etcd backup sucess"
#ETCDCTL_DEBUG=true etcdctl --endpoints $ENDPOINT snapshot save /tmp/test2_snapshot.db
# env:
# - name: ENDPOINT
# value: "127.0.0.1:2379"
# securityContext:
# privileged: true
securityContext:
runAsUser: 0
runAsGroup: 0
privileged: true
volumeMounts:
- name: backup
mountPath: /backup
- name: etcd
mountPath: /etc/kubernetes
readOnly: true # 设置为只读
- mountPath: /etc/localtime
name: lt-config
- mountPath: /etc/timezone
name: tz-config
restartPolicy: OnFailure
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
#node-role.kubernetes.io/control-plane: 'true'
#node-role.kubernetes.io/control-plane: 'true'
volumes:
- name: backup
persistentVolumeClaim:
claimName: etcd-pvc
- name: etcd
hostPath:
path: /etc/kubernetes
type: ''
- name: lt-config
hostPath:
path: /etc/localtime
- name: tz-config
hostPath:
path: /etc/timezone
立即运行cronjob
kubectl -n kube-system create job --from=cronjob/etcd-backup manual-etcd-backup
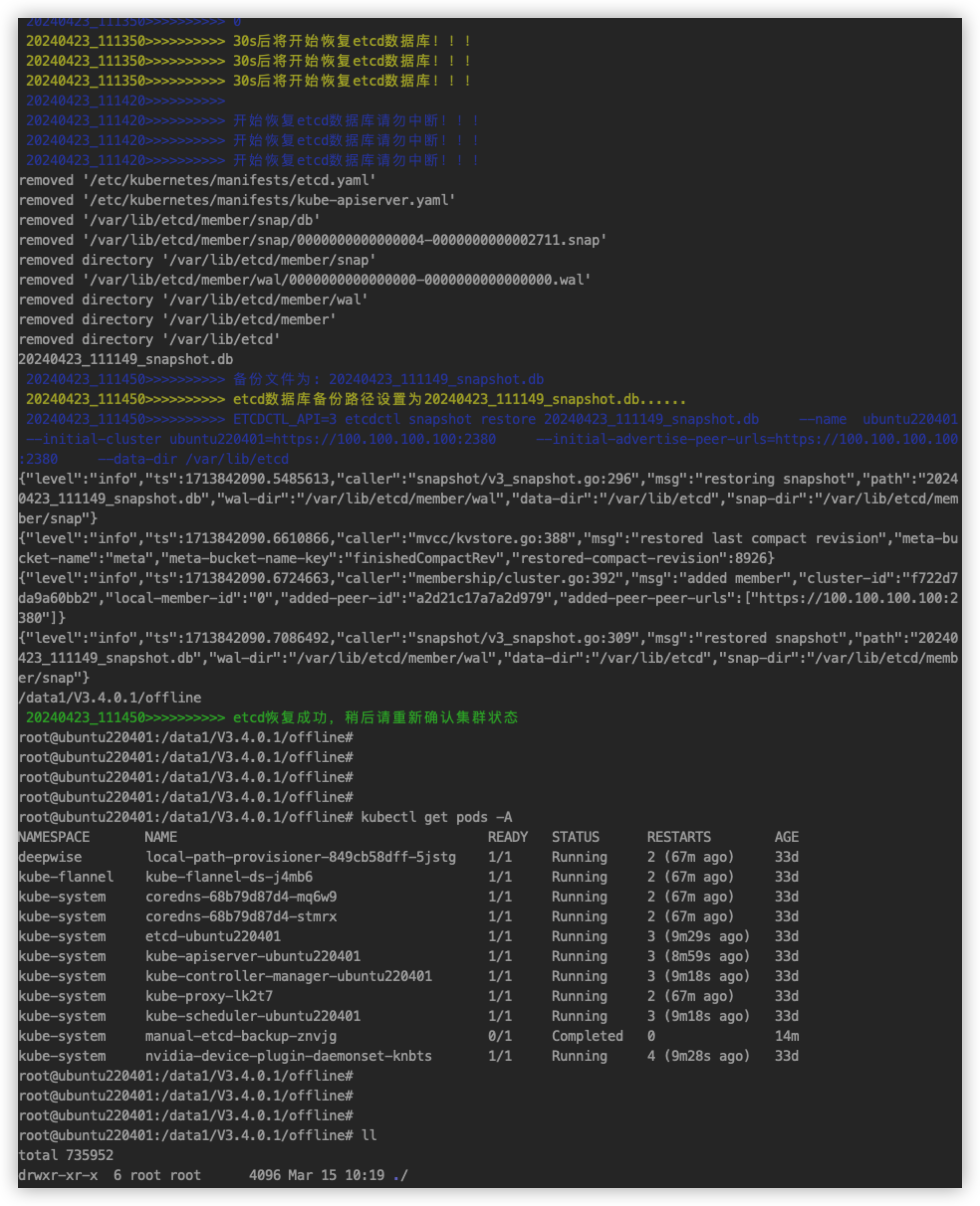
恢复测试
ETCDCTL_API=3 etcdctl snapshot restore /srv/123.db --name ubutnuw2204 --initial-cluster ubutnuw2204=https://100.100.100.100:2380 --initial-advertise-peer-urls=https://100.100.100.100:2380 --data-dir /var/lib/etcd
把命令写到脚本里做了下测试,恢复成功
https://liujinye.gitbook.io/openshift-docs/etcd/k8s-1.22-shi-yong-cronjob-bei-fen-etcd
https://developer.aliyun.com/article/704295