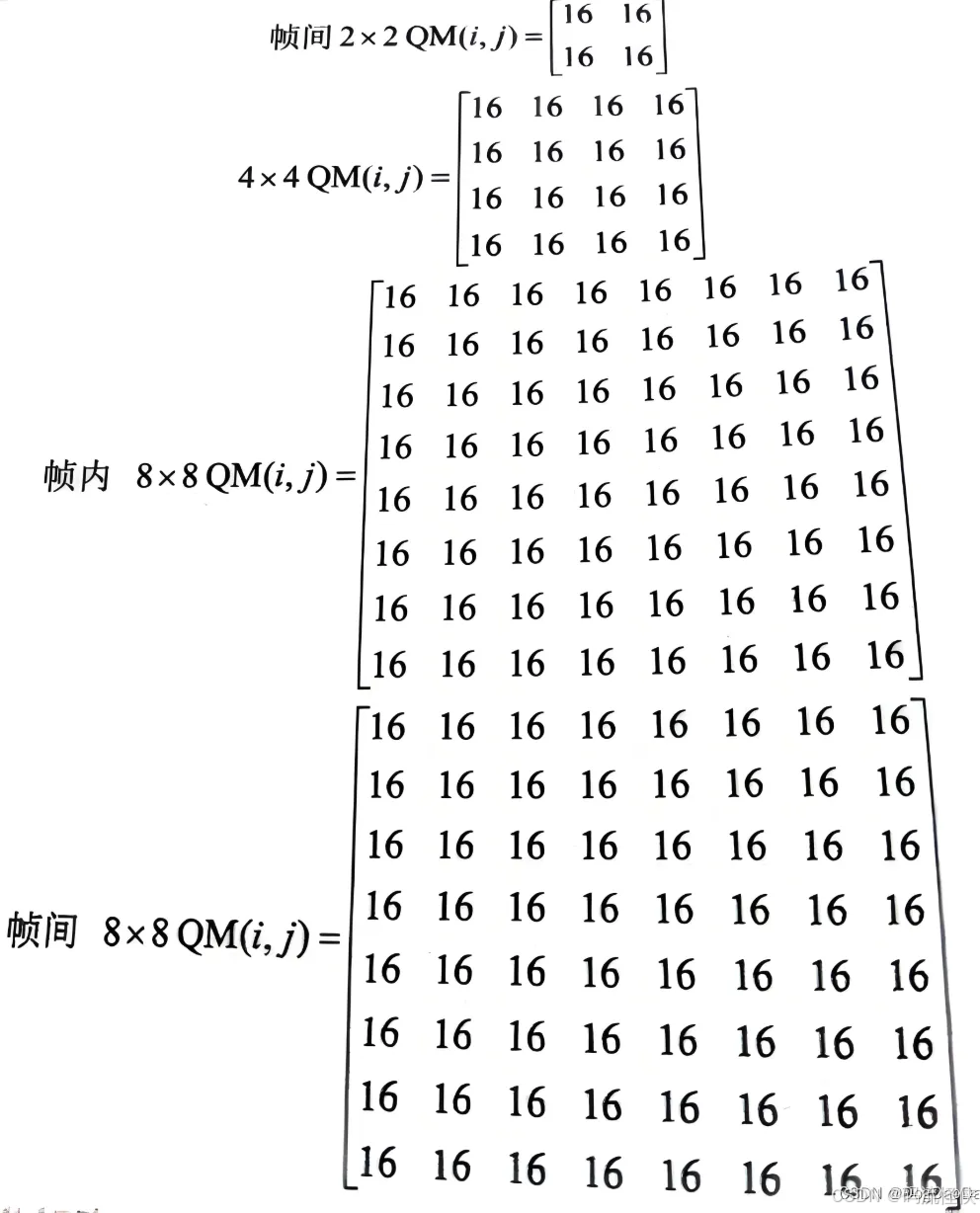
量化矩阵(Quantization Matrixes,QM)的原理是对于不同位置的变换系数使用不同的量化步长进行量化,人眼对高频不敏感对低频敏感,对低频分量进行小步长量化,对高频分量进行大步长量化,在保证主观质量的情况下,提高压缩效率。量化矩阵作用于比例缩放过程(比例缩放过程在变换和量化之间),其大小和 TU 相同。VVC 支持默认量化矩阵和自定义量化矩阵 。 如下图,变换后的DCT(或DST)系数将与量化矩阵(比例缩放)对应位置的系数相除,所得到的结果作为量化模块的输入。 VVC 中所有尺寸的默认量化矩阵的元素值都是 16。用户自定义的量化矩阵 MatrixType 和 MatrixType_DC 数量更新如下:对于 16x16,32x32 和 64x64 的量化矩阵,DC 值单独编码。对于小于 8x8 的量化矩阵,矩阵中所有元素都要在命令中传输。对于大于或等于 8x8 的量化矩阵, 仅传输一个 8x8 的基础矩阵(64 个元素),然后通过上采用得到更大尺寸的量化矩阵。 当变换时使用高频系数置零时,量化矩阵的对应高频系数也置零。VVC 中最小的帧内色度块和 IBC 块尺寸是 2x8 或 8x2,且 4x4 的亮度块不允许进行帧 间预测,则只有在使用 SBT 时才会产生 2x2 的色度块,所以默认量化矩阵中去除了 2x2 的矩阵且不允许用户自定义。 H266 规定了2x2、4x4和8x8共三种大小的默认量化矩阵 ,并规定16x16、32x32、64x64的量化矩阵可由8x8量化矩阵通过上采样得到。 为了提高用户自定义的 QM 的编码效率,有以下方法:
可以允许当前 QM 参考上一个已编码的相同尺寸的 QM。 仅编码当前 QM 和参考 QM 的残差。 在当前 QM 中使用 DPCM。 matrixId 和 sizeId 结合起来形成单一的矩阵标识符 scalingListId。 在 2020 年 1 月的 JVET-Q2002[Algorithm description for Versatile Video Coding and Test Model 8 (VTM 8)] 提案中对 QM 技术进行了总结描述。 在 VVenC 编码器中 Rom.cpp 文件中有MatrixType、 MatrixType_DC、g_quantTSDefault4x4、g_quantIntraDefault8x8、g_quantInterDefault8x8 的定义。【~但代码中没有实际应用到,后期再仔细研究 VVenC 源码~】 const char * MatrixType[ SCALING_LIST_SIZE_NUM] [ SCALING_LIST_NUM] =
{
{
"INTRA1X1_LUMA" ,
"INTRA1X1_CHROMAU" ,
"INTRA1X1_CHROMAV" ,
"INTER1X1_LUMA" ,
"INTER1X1_CHROMAU" ,
"INTER1X1_CHROMAV"
} ,
{
"INTRA2X2_LUMA" ,
"INTRA2X2_CHROMAU" ,
"INTRA2X2_CHROMAV" ,
"INTER2X2_LUMA" ,
"INTER2X2_CHROMAU" ,
"INTER2X2_CHROMAV"
} ,
{
"INTRA4X4_LUMA" ,
"INTRA4X4_CHROMAU" ,
"INTRA4X4_CHROMAV" ,
"INTER4X4_LUMA" ,
"INTER4X4_CHROMAU" ,
"INTER4X4_CHROMAV"
} ,
{
"INTRA8X8_LUMA" ,
"INTRA8X8_CHROMAU" ,
"INTRA8X8_CHROMAV" ,
"INTER8X8_LUMA" ,
"INTER8X8_CHROMAU" ,
"INTER8X8_CHROMAV"
} ,
{
"INTRA16X16_LUMA" ,
"INTRA16X16_CHROMAU" ,
"INTRA16X16_CHROMAV" ,
"INTER16X16_LUMA" ,
"INTER16X16_CHROMAU" ,
"INTER16X16_CHROMAV"
} ,
{
"INTRA32X32_LUMA" ,
"INTRA32X32_CHROMAU" ,
"INTRA32X32_CHROMAV" ,
"INTER32X32_LUMA" ,
"INTER32X32_CHROMAU" ,
"INTER32X32_CHROMAV"
} ,
{
"INTRA64X64_LUMA" ,
"INTRA64X64_CHROMAU_FROM16x16_CHROMAU" ,
"INTRA64X64_CHROMAV_FROM16x16_CHROMAV" ,
"INTER64X64_LUMA" ,
"INTER64X64_CHROMAU_FROM16x16_CHROMAU" ,
"INTER64X64_CHROMAV_FROM16x16_CHROMAV"
} ,
} ;
const char * MatrixType_DC[ SCALING_LIST_SIZE_NUM] [ SCALING_LIST_NUM] =
{
{
} ,
{
} ,
{
} ,
{
} ,
{
"INTRA16X16_LUMA_DC" ,
"INTRA16X16_CHROMAU_DC" ,
"INTRA16X16_CHROMAV_DC" ,
"INTER16X16_LUMA_DC" ,
"INTER16X16_CHROMAU_DC" ,
"INTER16X16_CHROMAV_DC"
} ,
{
"INTRA32X32_LUMA_DC" ,
"INTRA32X32_CHROMAU_DC" ,
"INTRA32X32_CHROMAV_DC" ,
"INTER32X32_LUMA_DC" ,
"INTER32X32_CHROMAU_DC" ,
"INTER32X32_CHROMAV_DC"
} ,
{
"INTRA64X64_LUMA_DC" ,
"INTRA64X64_CHROMAU_DC_FROM16x16_CHROMAU" ,
"INTRA64X64_CHROMAV_DC_FROM16x16_CHROMAV" ,
"INTER64X64_LUMA_DC" ,
"INTER64X64_CHROMAU_DC_FROM16x16_CHROMAU" ,
"INTER64X64_CHROMAV_DC_FROM16x16_CHROMAV"
} ,
} ;
const int g_quantTSDefault4x4[ 4 * 4 ] =
{
16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16
} ;
const int g_quantIntraDefault8x8[ 8 * 8 ] =
{
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16
} ;
const int g_quantInterDefault8x8[ 8 * 8 ] =
{
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16 ,
16 , 16 , 16 , 16 , 16 , 16 , 16 , 16
} ;