目录
知识星球 | 深度连接铁杆粉丝,运营高品质社群,知识变现的工具
我们知道爬虫是 IO 密集型任务,比如如果我们使用 requests 库来爬取某个站点的话,发出一个请求之后,程序必须要等待网站返回响应之后才能接着运行,而在等待响应的过程中,整个爬虫程序是一直在等待的,实际上没有做任何的事情。对于这种情况我们有没有优化方案呢?
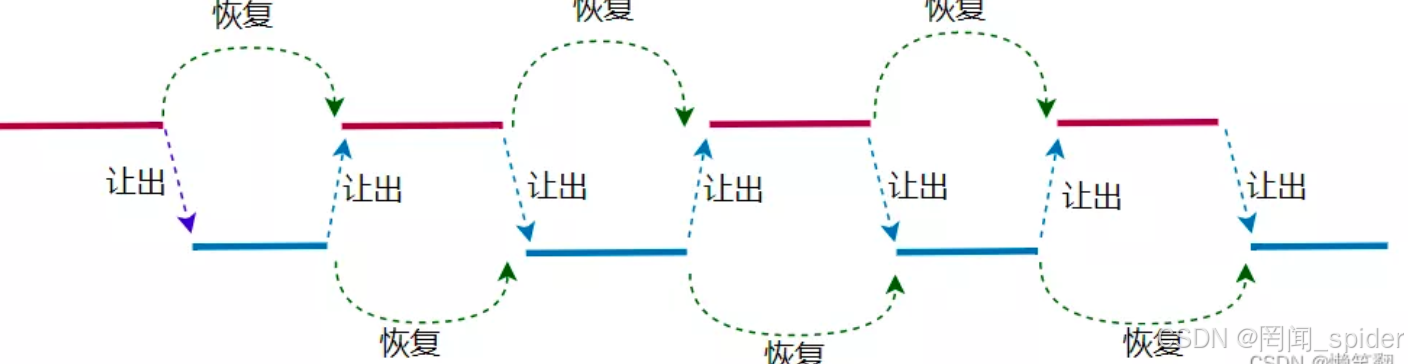
协程不是计算机提供,程序员人为创造。
协程(Coroutine),也可以被称为微线程,是一种用户态内的上下文切换技术。简而言之,其实就是通过一个线程实现代码块相互切换执行
同步异步速度对比
1.基本概念
异步
为完成某个任务,不同程序单元之间过程中无需通信协调,也能完成任务的方式,不相关的程序单元之间可以是异步的。
例如,爬虫下载网页。调度程序调用下载程序后,即可调度其他任务,而无需与该下载任务保持通信以协调行为。不同网页的下载、保存等操作都是无关的,也无需相互通知协调。这些异步操作的完成时刻并不确定。
同步
不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,我们称这些程序单元是同步执行的。
阻塞
阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续处理其他的事情,则称该程序在该操作上是阻塞的。
非阻塞
程序在等待某操作过程中,自身不被阻塞,可以继续处理其他的事情,则称该程序在该操作上是非阻塞的。
同步/异步关注的是消息通信机制 (synchronous communication/ asynchronouscommunication) 。
阻塞/非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
需要下载的包
pip install aiohttpaiohttp是一个为Python提供异步HTTP 客户端/服务端编程,基于asyncio(Python用于支持异步编程的标准库)的异步库。asyncio可以实现单线程并发IO操作,其实现了TCP、UDP、SSL等协议,aiohttp就是基于asyncio实现的http框架。
async 用来声明一个函数为异步函数
await 用来声明程序挂起,比如异步程序执行到某一步时需要等待的时间很长,就将此挂起,去执行其他的异步程序
asyncio和async的关系
asyncio
在python3.4及之后的版本。
import asyncio
@asyncio.coroutine
def func1():
print(1)
# 网络IO请求:下载一张图片
yield from asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print(2)
@asyncio.coroutine
def func2():
print(3)
# 网络IO请求:下载一张图片
yield from asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print(4)
tasks = [
asyncio.ensure_future( func1() ),
asyncio.ensure_future( func2() )
]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))注意:遇到IO阻塞自动切换
async & await关键字
在python3.5及之后的版本。
import asyncio
async def func1():
print(1)
# 网络IO请求:下载一张图片
await asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print(2)
async def func2():
print(3)
# 网络IO请求:下载一张图片
await asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print(4)
tasks = [
asyncio.ensure_future( func1() ),
asyncio.ensure_future( func2() )
]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
协程基本语法
协程的基本写法: 咱就介绍一种, 也是最好用的一种.
先上手来一下.
async def func():
print("我是协程")
if __name__ == '__main__':
# print(func()) # 注意, 此时拿到的是一个协程对象, 和生成器差不多.该函数默认是不会这样执行的
coroutine = func()
asyncio.run(coroutine) # 用asyncio的run来执行协程.
# lop = asyncio.get_event_loop()
# lop.run_until_complete(coroutine) # 这两句顶上面一句
效果不明显, 继续加码
import time
import asyncio
# await: 当该任务被挂起后, CPU会自动切换到其他任务中
async def func1():
print("func1, start")
await asyncio.sleep(3)
print("func1, end")
async def func2():
print("func2, start")
await asyncio.sleep(4)
print("func2, end")
async def func3():
print("func3, start")
await asyncio.sleep(2)
print("func3, end")
async def run():
start = time.time()
tasks = [ # 协程任务列表
asyncio.ensure_future(func1()), # create_task创建协程任务
asyncio.ensure_future(func2()),
asyncio.ensure_future(func3()),
]
await asyncio.wait(tasks) # 等待所有任务执行结束
print(time.time() - start)
if __name__ == '__main__':
asyncio.run(run())多任务协程返回值
import asyncio
async def faker1():
print("任务1开始")
await asyncio.sleep(1)
print("任务1完成")
return "任务1结束"
async def faker2():
print("任务2开始")
await asyncio.sleep(2)
print("任务2完成")
return "任务2结束"
async def faker3():
print("任务3开始")
await asyncio.sleep(3)
print("任务3完成")
return "任务3结束"
async def main():
tasks = [
asyncio.create_task(faker3()),
asyncio.create_task(faker1()),
asyncio.create_task(faker2()),
]
# 方案一, 用wait, 返回的结果在result中
result, pending = await asyncio.wait(tasks,timeout=None)
for r in result:
print(r.result())
# 方案二, 用gather, 返回的结果在result中, 结果会按照任务添加的顺序来返回数据
# return_exceptions如果任务在执行过程中报错了. 返回错误信息.
result = await asyncio.gather(*tasks, return_exceptions=True)
for r in result:
print(r)
if __name__ == '__main__':
asyncio.run(main())
案例1
import asyncio
async def download(url):
print("开始抓取")
await asyncio.sleep(3) # 我要开始下载了
print("下载结束", url)
return "老子是源码你信么"
async def main():
urls = [
"http://www.baidu.com",
"http://www.h.com",
"http://luoyonghao.com"
]
# 生成任务列表
tasks = []
for url in urls:
tasks.append(asyncio.create_task(download(url)))
done, pedding = await asyncio.wait(tasks)
for d in done:
print(d.result())
if __name__ == '__main__':
asyncio.run(main())协程在爬虫中的使用
aiohttp是python的一个非常优秀的第三方异步http请求库. 我们可以用aiohttp来编写异步爬虫(协程)
安装:
pip install aiohttp
pip install aiofilesaiohttp模块基本使用
实例代码:
import aiohttp
import asyncio
import aiofiles
async def download(url):
try:
name = url.split("/")[-1]
# 创建session对象 -> 相当于requsts对象
async with aiohttp.ClientSession() as session:
# 发送请求, 这里和requests.get()几乎没区别, 除了代理换成了proxy
async with session.get(url) as resp:
# # resp.text(encoding='') 这可以设置字符集
# 读取数据. 如果想要读取源代码. 直接resp.text()即可. 比原来多了个()
content = await resp.content.read()
# 写入文件, 用默认的open也OK. 用aiofiles能进一步提升效率
async with aiofiles.open(name, mode="wb") as f:
await f.write(content)
return "OK"
except:
print(123)
return "NO"
async def main():
url_list = [
"https://x.u5w.cc/Uploadfile/202110/20/42214426253.jpg",
"https://x.u5w.cc/Uploadfile/202110/20/B3214426373.jpg",
"https://www.xiurenji.vip/uploadfile/202110/20/1F214426892.jpg",
"https://www.xiurenji.vip/uploadfile/202110/20/91214426753.jpg"
]
tasks = []
for url in url_list:
# 创建任务
task = asyncio.create_task(download(url))
tasks.append(task)
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
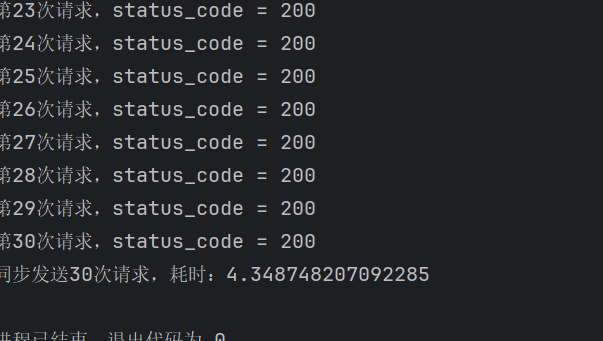
从最终运行的结果中能非常直观的看到用异步IO完成爬虫的效率明显高了很多
协程案例-扒光一部小说需要多久?
目标, 明朝那些事儿 明朝那些事儿-明朝那些事儿全集在线阅读
import asyncio
import aiohttp
import aiofiles
import requests
from lxml import etree
import os
def get_chapter_info(url):
resp = requests.get(url)
resp.encoding = 'utf-8'
page_source = resp.text
resp.close()
result = []
# 解析page_soruce
tree = etree.HTML(page_source)
mulus = tree.xpath("//div[@class='main']/div[@class='bg']/div[@class='mulu']")
for mulu in mulus:
trs = mulu.xpath("./center/table/tr")
title = trs[0].xpath(".//text()")
chapter_name = "".join(title).strip()
chapter_hrefs = []
for tr in trs[1:]: # 循环内容
hrefs = tr.xpath("./td/a/@href")
chapter_hrefs.extend(hrefs)
result.append(
{"chapter_name": chapter_name, "chapter_hrefs": chapter_hrefs}
)
return result
async def download_one(name, href):
async with aiohttp.ClientSession() as session:
async with session.get(href) as resp:
hm = await resp.text(encoding="utf-8", errors="ignore")
# 处理hm
tree = etree.HTML(hm)
title = tree.xpath("//div[@class='main']/h1/text()")[0].strip()
content_list = tree.xpath("//div[@class='main']/div[@class='content']/p/text()")
content = "\n".join(content_list).strip()
async with aiofiles.open(f"{name}/{title}.txt", mode="w", encoding="utf-8") as f:
await f.write(content)
print(title)
# 方案一
async def download_chapter(chapter):
chapter_name = chapter['chapter_name']
if not os.path.exists(chapter_name):
os.makedirs(chapter_name)
tasks = []
for href in chapter['chapter_hrefs']:
tasks.append(asyncio.create_task(download_one(chapter_name, href)))
await asyncio.wait(tasks)
# 方案二
async def download_all(chapter_info):
tasks = []
for chapter in chapter_info:
name = chapter['chapter_name']
if not os.path.exists(name):
os.makedirs(name)
for url in chapter['chapter_hrefs']:
task = asyncio.create_task(download_one(name, url))
tasks.append(task)
await asyncio.wait(tasks)
def main():
url = "http://www.mingchaonaxieshier.com/"
# 获取每一篇文章的名称和url地址
chapter_info = get_chapter_info(url)
# 可以分开写. 也可以合起来写.
# 方案一,分开写:
# for chapter in chapter_info:
# asyncio.run(download_chapter(chapter))
# 方案e,合起来下载:
asyncio.run(download_all(chapter_info))
if __name__ == '__main__':
main()
操作数据库
异步redis
在使用python代码操作redis时,链接/操作/断开都是网络IO。
pip3 install aioredis示例1:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import asyncio
import aioredis
async def execute(address, password):
print("开始执行", address)
# 网络IO操作:创建redis连接
redis = await aioredis.create_redis(address, password=password)
# 网络IO操作:在redis中设置哈希值car,内部在设三个键值对,即: redis = { car:{key1:1,key2:2,key3:3}}
await redis.hmset_dict('car', key1=1, key2=2, key3=3)
# 网络IO操作:去redis中获取值
result = await redis.hgetall('car', encoding='utf-8')
print(result)
redis.close()
# 网络IO操作:关闭redis连接
await redis.wait_closed()
print("结束", address)
asyncio.run( execute('redis://47.93.4.198:6379', "root!2345") )示例2:
import asyncio
import aioredis
async def execute(address, password):
print("开始执行", address)
# 网络IO操作:先去连接 47.93.4.197:6379,遇到IO则自动切换任务,去连接47.93.4.198:6379
redis = await aioredis.create_redis_pool(address, password=password)
# 网络IO操作:遇到IO会自动切换任务
await redis.hmset_dict('car', key1=1, key2=2, key3=3)
# 网络IO操作:遇到IO会自动切换任务
result = await redis.hgetall('car', encoding='utf-8')
print(result)
redis.close()
# 网络IO操作:遇到IO会自动切换任务
await redis.wait_closed()
print("结束", address)
task_list = [
execute('redis://47.93.4.197:6379', "root!2345"),
execute('redis://47.93.4.198:6379', "root!2345")
]
asyncio.run(asyncio.wait(task_list))
异步MySQL
pip3 install aiomysql示例1:
import asyncio
import aiomysql
async def execute():
# 网络IO操作:连接MySQL
conn = await aiomysql.connect(host='127.0.0.1', port=3306, user='root', password='123', db='mysql', )
# 网络IO操作:创建CURSOR
cur = await conn.cursor()
# 网络IO操作:执行SQL
await cur.execute("SELECT Host,User FROM user")
# 网络IO操作:获取SQL结果
result = await cur.fetchall()
print(result)
# 网络IO操作:关闭链接
await cur.close()
conn.close()
asyncio.run(execute())示例2:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import asyncio
import aiomysql
async def execute(host, password):
print("开始", host)
# 网络IO操作:先去连接 47.93.40.197,遇到IO则自动切换任务,去连接47.93.40.198:6379
conn = await aiomysql.connect(host=host, port=3306, user='root', password=password, db='mysql')
# 网络IO操作:遇到IO会自动切换任务
cur = await conn.cursor()
# 网络IO操作:遇到IO会自动切换任务
await cur.execute("SELECT Host,User FROM user")
# 网络IO操作:遇到IO会自动切换任务
result = await cur.fetchall()
print(result)
# 网络IO操作:遇到IO会自动切换任务
await cur.close()
conn.close()
print("结束", host)
task_list = [
execute('47.93.41.197', "root!2345"),
execute('47.93.40.197', "root!2345")
]
asyncio.run(asyncio.wait(task_list))案例2:
import hashlib
import random
import time
import redis
from lxml import etree
import aiohttp
import asyncio
import aiomysql
class QiChe():
def __init__(self):
self.url = 'https://www.che168.com/china/a0_0msdgscncgpi1ltocsp{}exf4x0/?pvareaid=102179#currengpostion'
self.red = redis.Redis()
self.headers = {
'cookie': 'listuserarea=0; fvlid=1680001956301DaYJ4eiunV2R; sessionid=21b958ec-44d7-4d2e-94c0-e2adb575f619; sessionip=113.246.154.77; area=430104; che_sessionid=0EF0CDB5-A9C1-45CC-A742-DA21F9043918%7C%7C2023-03-28+19%3A12%3A36.699%7C%7C0; sessionvisit=9effbe46-2133-4609-8bfd-847ca49d7087; sessionvisitInfo=21b958ec-44d7-4d2e-94c0-e2adb575f619||100943; Hm_lvt_d381ec2f88158113b9b76f14c497ed48=1680001957,1680068945; che_sessionvid=9E2BB2F8-234E-4851-8DCC-3B590C8B5098; userarea=410100; ahpvno=22; showNum=15; Hm_lpvt_d381ec2f88158113b9b76f14c497ed48=1680069967; ahuuid=C4CD708B-1BE2-456B-AF64-FEB954906092; v_no=17; visit_info_ad=0EF0CDB5-A9C1-45CC-A742-DA21F9043918||9E2BB2F8-234E-4851-8DCC-3B590C8B5098||-1||-1||17; che_ref=0%7C0%7C0%7C0%7C2023-03-29+14%3A06%3A06.926%7C2023-03-28+19%3A12%3A36.699; sessionuid=21b958ec-44d7-4d2e-94c0-e2adb575f619',
'referer': 'https://www.che168.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
self.json_url = 'https://cacheapigo.che168.com/CarProduct/GetParam.ashx?specid={}'
def get_md5(self, val):
"""把目标数据进行哈希,用哈希值去重更快"""
md5 = hashlib.md5()
md5.update(str(val).encode('utf-8'))
# print(md5.hexdigest())
return md5.hexdigest()
async def info_get(self, specid, client, pool):
response = await client.get(self.json_url.format(specid))
res_json = await response.json()
if res_json['result'].get('paramtypeitems'):
item = {}
item['name'] = res_json['result']['paramtypeitems'][0]['paramitems'][0]['value']
item['price'] = res_json['result']['paramtypeitems'][0]['paramitems'][1]['value']
item['brand'] = res_json['result']['paramtypeitems'][0]['paramitems'][2]['value']
item['altitude'] = res_json['result']['paramtypeitems'][1]['paramitems'][2]['value']
item['breadth'] = res_json['result']['paramtypeitems'][1]['paramitems'][1]['value']
item['length'] = res_json['result']['paramtypeitems'][1]['paramitems'][0]['value']
await self.save_data(item, pool)
async def get_data(self, page, client, pool):
response = await client.get(self.url.format(page))
data = await response.text(encoding='gbk')
html = etree.HTML(data)
li_list = list(set(html.xpath('//ul[@class="viewlist_ul"]/li/@seriesid')))
tasks = []
for li in li_list:
res = self.info_get(li, client, pool)
task = asyncio.create_task(res)
tasks.append(task)
await asyncio.wait(tasks)
async def save_data(self, item, pool):
# # 连接mysql
async with pool.acquire() as conn:
# 创建游标
async with conn.cursor() as cursor:
print(item)
value = self.get_md5(item)
res = self.red.sadd('qiche:filter', value)
if res:
# sql插入语法
sql = 'INSERT INTO qiche(id, name, price, brand, altitude, breadth, length) values(%s, %s, %s, %s, %s, %s, %s)'
try:
# print(sql, (0, item['authors'], item['title'], item['score']))
await cursor.execute(sql, (
0, item['name'], item['price'], item['brand'], item['altitude'], item['breadth'],
item['length']))
# 提交到数据库执行
await conn.commit()
print('数据插入成功...')
except Exception as e:
print(f'数据插入失败: {e}')
# 如果发生错误就回滚
await conn.rollback()
else:
print('数据重复!!!!')
async def main(self):
# 异步创建连接池
pool = await aiomysql.create_pool(host='127.0.0.1', port=3306, user='root', password='root', db='spiders',
loop=loop)
conn = await pool.acquire()
cursor = await conn.cursor()
# 使用预处理语句创建表
create_sql = '''
CREATE TABLE IF NOT EXISTS qiche(
id int primary key auto_increment not null,
name VARCHAR(255) NOT NULL,
price VARCHAR(255) NOT NULL,
brand VARCHAR(255) NOT NULL,
altitude VARCHAR(255) NOT NULL,
breadth VARCHAR(255) NOT NULL,
length VARCHAR(255) NOT NULL
);
'''
# 执行sql
await cursor.execute(create_sql)
async with aiohttp.ClientSession(headers=self.headers) as client:
tasks = []
for i in range(1, 40):
res = self.get_data(i, client, pool)
task = asyncio.create_task(res)
tasks.append(task)
await asyncio.sleep(random.randint(500, 800) / 1000)
await asyncio.wait(tasks)
await cursor.close()
conn.close()
if __name__ == '__main__':
start = time.time()
qczj = QiChe()
# 获取事件循环 Eventloop 我们想运用协程,首先要生成一个loop对象,然后loop.run_xxx()就可以运行协程了,而如何创建这个loop, 方法有两种:对于主线程是loop=get_event_loop().
loop = asyncio.get_event_loop()
# 执行协程
loop.run_until_complete(qczj.main())
print('运行时间{}'.format(time.time() - start))