Invar-RAG:基于不变性对齐的LLM检索方法提升生成质量

论文链接:https://arxiv.org/html/2411.07021v1
论文概述
在检索增强型生成(Retrieval-Augmented Generation, RAG)系统中直接应用大型语言模型(Large Language Models, LLMs)时面临的挑战。具体来说,论文关注以下几个问题:
-
特征局部性问题(Feature Locality Problem):由于大型语言模型的庞大参数知识库阻碍了有效使用所有语料库中的全局信息,例如,基于LLM的检索器通常输入文档的摘要而不是整个文档,这可能导致无法充分利用全局信息。
-
检索方差问题(Retrieval Variance):由于大型语言模型固有的生成不一致性属性,当前基于LLM的检索可能会产生不可预见的方差,尤其是在输入查询或上下文大小变化时,直接导致不理想且易受攻击的性能。
-
检索器与生成模型的分离问题:在RAG系统中,检索器和生成模型之间的分离阻碍了它们的完全集成,限制了它们在下游应用中的兼容性。
为了解决这些问题,论文提出了一个名为Invar-RAG的新颖两阶段微调架构,包括检索阶段和生成阶段。在检索阶段,通过整合基于LoRA的表示学习来解决特征局部性问题,并开发了两种模式(即不变模式和变体模式)以及不变损失来减轻LLM中的方差。在生成阶段,设计了一种精心设计的微调方法,以改进LLM,以便根据检索到的信息准确生成答案。实验结果表明,Invar-RAG在三个开放域问答(Open-domain Question Answering, ODQA)数据集上显著优于现有基线
核心内容
论文提出了一个名为Invar-RAG的新型两阶段微调架构来解决上述问题,具体方法如下:
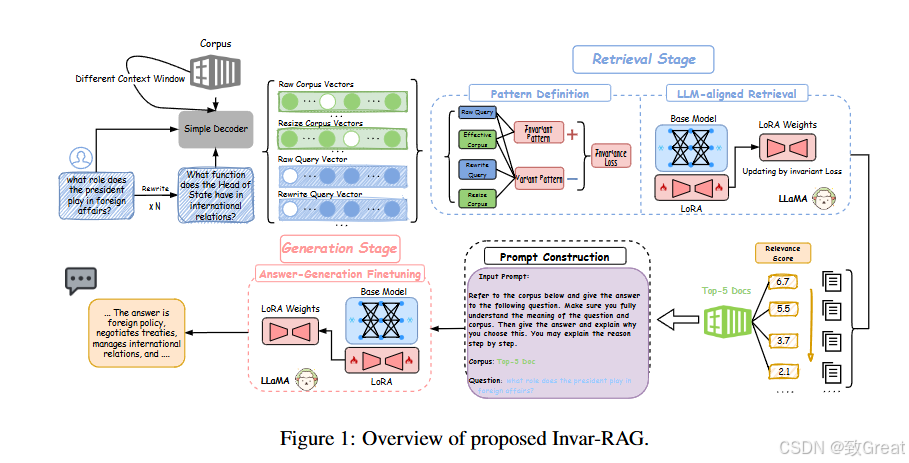
检索阶段(Retrieval Stage)
1. LLM-based Retriever:
-
使用基于LLaMA的双编码器架构作为检索器的骨干网络。
-
引入了LLM-aligned Retrieval,通过小语言模型(MiniLM)将输入查询和文档表示为高维空间中的向量,然后通过KL散度构建的新损失函数将这些粗略的查询-文档对表示与LLM的表示空间对齐。
2. 表示学习(Representation Learning):
利用LoRA(Low-Rank Adaptation)架构为原始表示添加额外的适配参数,以增强检索器返回相关文档的能力。
3. 不变性损失(Invariance Loss):
通过识别对性能贡献最大的不变模式,并逐渐迫使模型依赖于这些不变模式,减少实践中不可预见的方差,增强RAG系统的鲁棒性。
生成阶段(Generation Stage)
1. 生成能力优化:
在检索到相关信息后,通过特殊设计的微调示例来优化LLM,使其能够更准确地回答给定问题。
2. 微调方法:
冻结先前微调的权重,并优化生成函数,允许LLM根据检索到的文档给出正确答案。
论文总结
-
Invar-RAG框架:提出了一个新颖的框架,包含两个阶段的微调方法,分别针对检索和生成。
-
LLM-based检索方法:提出了一种新的基于LLM的检索方法,包括表示学习和不变性损失,分别解决特征局部性和检索方差问题。
-
性能验证:在三个公共ODQA数据集上验证了Invar-RAG的性能,无论在检索性能还是生成性能上,都展示了其优越性。
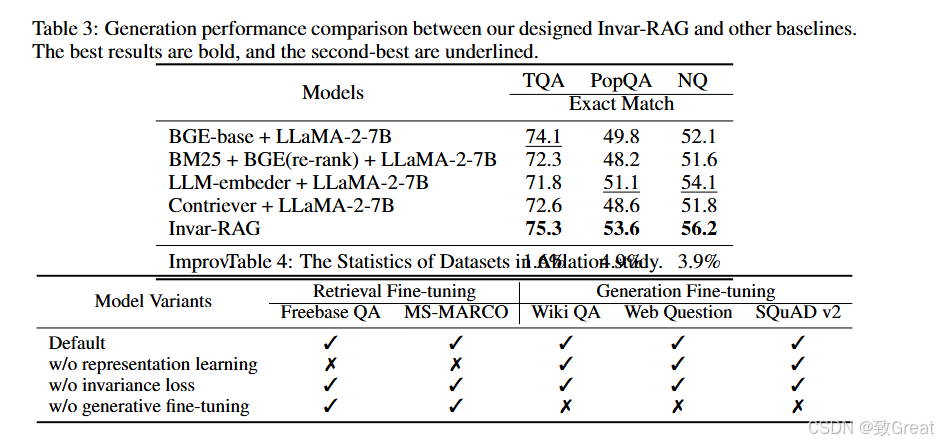
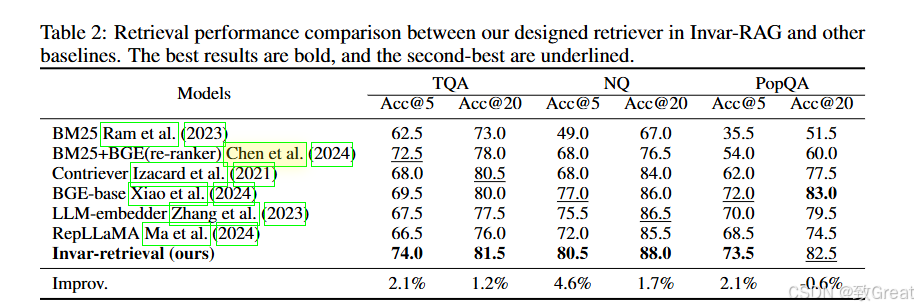
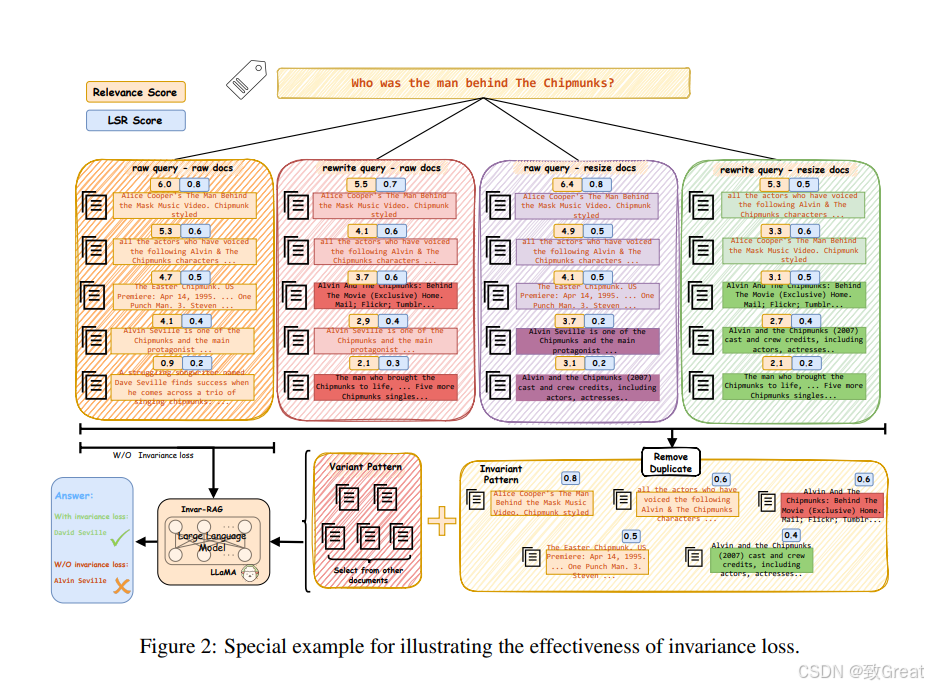
通过这些方法,Invar-RAG能够有效地利用LLM的语义理解能力来检索相关信息,并生成准确的答案,同时解决了特征局部性和检索方差的问题。
编者简介
致Great,中国人民大学硕士,多次获得国内外算法赛奖项,目前在中科院计算所工作,目前负责大模型训练优化以及RAG框架开发相关工作。