随着气候变化对各行各业的影响日益加剧,精准的天气预测已经变得尤为重要。降雨预测在日常生活中尤其关键,例如农业、交通和灾害预警等领域。本文将通过机器学习方法,利用历史天气数据预测明天是否会下雨,具体内容包括数据预处理、模型训练、调参、评估与优化等多个环节。
1. 项目背景与目标
本项目的核心任务是通过分析天气数据来预测明天是否降雨。数据集包含了多个天气特征(如温度、湿度、风速、气压等),我们使用这些特征作为输入,构建机器学习模型预测目标变量(是否下雨)。具体目标如下:
- 使用历史天气数据来预测明天是否降雨。
- 使用多种机器学习算法进行模型训练和评估。
- 处理数据中的缺失值、类别不平衡等问题,提高模型的预测准确性。
2. 数据集介绍
我们使用一个典型的天气数据集,它包含了如下几个主要特征:
- Location:表示获取该信息的气象站的名称。
- MinTemp:以摄氏度为单位的最低温度。
- MaxTemp:以摄氏度为单位的最高温度。
- Rainfall:当天记录的降雨量,单位为毫米(mm)。
- Evaporation:到早上9点之前的24小时内的A级蒸发量,单位为毫米(mm)。
- Sunshine:白天日照的完整小时数,表示当天白昼时段阳光的强度。
- WindGustDir:表示在午夜12点前24小时内,最强风的风向。
- WindGustSpeed:表示在午夜12点前24小时内,最强风的风速,单位为千米每小时(km/h)。
- WindDir9am:上午9点时的风向。
- WindDir3pm:下午3点时的风向。
- WindSpeed9am:上午9点之前每个十分钟的风速平均值,单位为千米每小时(km/h)。
- WindSpeed3pm:下午3点之前每个十分钟的风速平均值,单位为千米每小时(km/h)。
- Humidity9am:上午9点的湿度,单位为百分比。
- Humidity3pm:下午3点的湿度,单位为百分比。
- Pressure9am:上午9点的平均海平面气压,单位为百帕(hpa)。
- Pressure3pm:下午3点的平均海平面气压,单位为百帕(hpa)。
- Cloud9am:上午9点时的天空云层遮蔽程度,以“oktas”单位衡量。0表示完全晴朗,8表示完全阴天。
- Cloud3pm:下午3点时的天空云层遮蔽程度,单位同上午9点。
- Temp9am:上午9点的温度,单位为摄氏度。
- Temp3pm:下午3点的温度,单位为摄氏度。
- RainTomorrow:目标变量,表示明天是否会下雨。1表示下雨,0表示不下雨。
目标是基于这些特征来预测RainTomorrow,即明天是否会下雨。

3. 数据预处理
机器学习模型的效果很大程度上取决于数据的质量,因此数据预处理是一个至关重要的步骤。
3.1 读取数据
我们从CSV文件中加载数据并进行抽样:
import pandas as pd
# 读取数据
data = pd.read_csv("weather.csv", encoding='gbk', index_col=0)
weather = data.sample(n=5000, random_state=0)
weather.index = range(weather.shape[0])
3.2 特征与目标变量分离
我们将数据集分为特征(X)和目标变量(Y):
X = weather.iloc[:, :-1] # 所有列,除了最后一列
Y = weather.iloc[:, -1] # 目标变量,即是否下雨
3.3 处理缺失值
数据中可能存在缺失值,特别是对于天气数据,缺失值可能较为常见。我们可以使用适当的策略填充这些缺失值。对于分类特征,我们使用众数(最频繁的值)填充;对于数值型特征,我们使用均值填充:
from sklearn.impute import SimpleImputer
# 对分类变量使用众数填充
categorical_columns = X.select_dtypes(include=['object']).columns
si = SimpleImputer(strategy="most_frequent")
X[categorical_columns] = si.fit_transform(X[categorical_columns])
# 对连续变量使用均值填充
continuous_columns = X.select_dtypes(include=['float64', 'int64']).columns
impmean = SimpleImputer(strategy="mean")
X[continuous_columns] = impmean.fit_transform(X[continuous_columns])
3.4 特征工程
特征工程旨在通过从现有数据中提取更有用的特征来提升模型性能。例如,我们可以通过分析降水量来生成一个新特征,表示当天是否有降水:
X['RainToday'] = X['Rainfall'].apply(lambda x: "Yes" if x >= 1 else "No")
此外,我们还可以从日期中提取月份信息,因为不同季节的天气差异较大:
X['Month'] = pd.to_datetime(X['Date']).dt.month
3.5 类别特征编码
机器学习模型通常无法直接处理非数值型数据,因此我们需要对类别特征进行编码。我们可以使用OrdinalEncoder将类别变量转换为数字值:
from sklearn.preprocessing import OrdinalEncoder
encoder = OrdinalEncoder()
categorical_columns = ['Location', 'WindGustDir']
X[categorical_columns] = encoder.fit_transform(X[categorical_columns])
3.6 特征标准化
标准化步骤有助于加速梯度下降优化算法的收敛,并提高模型性能。我们可以使用StandardScaler对数值特征进行标准化,使得数据具有零均值和单位方差:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X[continuous_columns] = scaler.fit_transform(X[continuous_columns])
3.7 处理类别不平衡
由于“下雨”的频率较低,目标变量RainTomorrow的类别可能不平衡。我们使用SMOTE(合成少数类过采样技术)来生成新的少数类样本,以平衡数据集:
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, Y)
4. 模型训练与评估
在数据预处理完成后,我们开始使用不同的分类模型进行训练,并评估它们的表现。常见的分类模型包括:
- 逻辑回归(Logistic Regression)
- 支持向量机(SVM)
- 随机森林(Random Forest)
- XGBoost(XGBoost)
- AdaBoost(AdaBoost)
- Gradient Boosting(Gradient Boosting)
4.1 数据集划分
首先,我们将数据划分为训练集和验证集。一般来说,80%的数据用于训练,20%的数据用于验证:
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X_resampled, y_resampled, test_size=0.2, random_state=42)
4.2 训练模型
接下来,我们训练多种分类模型,并评估它们的性能:
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
import xgboost as xgb
from sklearn.metrics import classification_report
# 定义模型
models = {
"Logistic Regression": LogisticRegression(),
"Random Forest": RandomForestClassifier(),
"SVM": SVC(),
"XGBoost": xgb.XGBClassifier(),
"AdaBoost": AdaBoostClassifier(),
"Gradient Boosting": GradientBoostingClassifier()
}
# 训练并评估每个模型
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_val)
print(f"{name} Performance:")
print(classification_report(y_val, y_pred))
4.3 投票分类器(集成方法)
为了提升预测效果,我们使用投票分类器(Voting Classifier)。投票分类器通过结合多个分类器的预测结果,达到提升预测准确率的效果。我们选择几个表现较好的分类器进行组合:
from sklearn.ensemble import VotingClassifier
voting_classifier = VotingClassifier(
estimators=[
('rf', RandomForestClassifier()),
('ada', AdaBoostClassifier()),
('gb', GradientBoostingClassifier()),
('xgb', xgb.XGBClassifier())
],
voting='hard'
)
voting_classifier.fit(X_train, y_train)
y_pred = voting_classifier.predict(X_val)
print("Voting Classifier Performance:")
print(classification_report(y_val, y_pred))
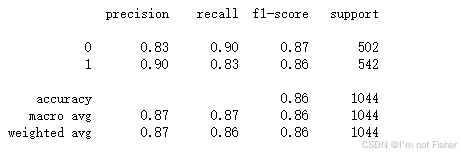
5. 结果分析与模型评估
通过模型训练与评估,我们可以比较各个模型的表现。通常,随机森林和XGBoost模型会表现较好,因为它们能够处理复杂的非线性关系并具有较强的抗过拟合能力。
模型评估结果通常包含如下指标:
- Accuracy(准确率):模型正确预测的样本数占总样本数的比例。
- Precision(精确度):预测为“降雨”时,实际降雨的比例。
- Recall(召回率):实际降雨时,模型正确预测为“降雨”的比例。
- F1-Score:精确度与召回率的调和平均值,是分类模型中较为综合的评估指标。
6. 结论与未来方向
本文展示了如何利用机器学习方法预测明天是否会下雨。通过合理的数据预处理、特征工程以及使用多种机器学习模型进行训练与评估,我们成功地建立了一个天气预测模型。
未来的工作包括:
- 深度学习方法:可以考虑使用LSTM(长短时记忆网络)等深度学习方法
来建模天气的时间序列特性。
- 集成学习优化:进一步优化集成学习方法,如Stacking、Boosting等。
- 更多的特征:增加更多天气相关的特征,如气象卫星数据等,来提高模型的准确性。
通过不断优化模型与特征,天气预测的准确性可以得到显著提高,为农业、物流等领域提供更加精确的预报。
参考资料
这篇博客详细介绍了使用机器学习方法进行天气预测的步骤,包括数据预处理、特征工程、模型训练与评估等多个环节。希望能帮助大家在实际项目中更好地应用这些技术。如果有任何问题或建议,欢迎在评论区留言。