MySQL基础
什么是SQL?
结构化查询语言(Structured Query Language)简称,是用来操作关系型数据库的一门语言,是一个关系型数据库通用的操作语言。
SQL语句功能划分:
- DDL:数据定义语句
用来定义数据库对象:创建库,表,列等。 - DML:数据操作语句
用来操作数据库表中的记录 - DQL:数据查询语句
用来查询数据 - DCL:数据控制语句
用来定义访问权限和安全级别
MySQL使用
下载安装包
https://dev.mysql.com/downloads/mysql/
如:mysql-8.0.26-macos11-x86_64.dmg
安装
双击*.dmg,一路next,中间会弹出一个对话框,提示输入root的密码,done.
开启MySQL服务。
点击右上角苹果按钮,进入系统偏好设置,点击mysql,开启MySQL服务
设置环境变量
进入/usr/local/mysql/bin,查看此目录下是否有mysql
执行 vim ~/.bash_profile 在该文件中添加mysql/bin的目录
PATH=$PATH:/usr/local/mysql/bin
添加完成后,按esc,然后输入:wq保存。
在命令行输入:
source ~/.bash_profile
注意:你可以通过以下方法来查看当前使用的是哪个 shell:
echo $SHELL 命令: 打开终端并输入以下命令:
echo $SHELL
这会输出当前 shell 的路径,例如 /bin/bash 或 /bin/zsh。
使用MySQL
登录MySQL
mysql -uroot -p 输入默认密码
指定数据库地址,默认为本地地址,也可以登录远程数据库
mysql -h127.0.0.1 -uroot -p
修改密码:
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('newpass');
对数据库的使用,从本质上来说分为三个维度:
- 对数据库的增删改查
- 对表的增删改查
- 对数据的增删改查
查看数据库:
show databases;
查看数据库后,mysql会有4个默认的数据库,一般不能动:
- information_schema
保存着关于MySQL服务器所维护的所有其他数据库的信息。如数据库名,数据库的表,表栏的数据类型与访问权限等 - mysql
MySQL系统数据库, 保存了登录用户名,密码,以及每个用户的权限等等 - performance_schema
用来保存数据库服务器性能的参数 - sys
这个库是通过视图的形式把information_schema和performance_schema结合起来,查询出更加令人容易理解的数据
创建数据库:
create DATABASE test;
使用某个数据库:
use test;
查看当前数据库里的数据表:
show tables;
创建数据表:
create table comment(
id int primary key auto_increment,
content varchar(200)
);
接下来就是对数据表进行操作:
插入一条数据:
INSERT INTO comment (content) VALUES ('This is a sample comment.');
例如查询数据表
select * from comment;
删除数据表:
drop table tableName
删除数据表中的指定数据:
delete from urls where url="www.baidu.com";
数据完整性
什么是数据的完整性?
保证保存到数据库中的数据都是正确的。
如何保证数据完整性?
- 数据的完整性可以分为三类: 实体完整性、域完整性、参照完整性
- 无论是哪一种完整性都是在创建表时给表添加约束即可
实体完整性
什么是实体? 表中的一行数据就是一个实体(entity)。
如何保证实体完整性?保证实体完整性就是保证每一行数据的唯一性。
实体完整性的约束类型
- 主键约束(primary key)
- 唯一约束(unique)
- 自动增长列(auto_increment)
主键约束
主键用于唯一标识表中的每一条数据, 和现实生活中的身份证很像。
什么是联合主键?
我们通过将表中的某个永远不重复的字段设置为主键, 从而达到保证每一行数据的唯一性(实体完整性)。但是在企业开发中有时候我们可能找不到不重复的字段, 此时我们还可以通过联合主键的方式来保证每一行数据的唯一性
联合主键就是同时将多个字段作为一个主键来使用。
如何设置联合主键?
设置主键有两种方式,第一种在某个字段后面注明是primary key;第二种是在所有字段之后通过primary key来标注;联合主键采用第二种方式,即标注多个字段来作为联合主键。如下:
create table persion(
name varchar(20),
age int,
primary key(name, age) // 设置联合主键。
);
什么是唯一约束(unique)
唯一约束用于保证某个字段的值永远不重复
create table person(
id int unique,
name varchar(20)
);
主键和唯一键异同:
- 唯一约束和主键约束一样, 被约束的字段的取值都不能够重复;
- 主键在一张表中只能有一个, 而唯一约束在一张表中可以有多个;
- 主键的取值不能为Null, 而唯一约束的取值可以是Null;
自动增长约束(auto_increment)
如果某个字段是自动增长的, 那么这个字段必须是主键才可以
create table person(
id int auto_increment primary key,
name varchar(20)
);
insert into person values (1, 'lnj');
insert into person values (null, 'lnj');
insert into person values (default, 'lnj');
如果仅仅是主键, 那么取值不能是null, 但是如果主键还是自动增长的, 那么取值就可以是null或者default
动态修改主键、约束、自动增长
alter table 表名 add primary key(字段);
alter table 表名 add unique(字段);
alter table 表名 modify 字段名称 数据类型 auto_increment;
域完整性
什么是域?一行数据中的每个单元格都是一个域。
如何保证域的完整性?保证域的完整性就是保证每个单元格数据的正确性。
- 使用正确的数据类型
- 使用非空约束(not null)
- 使用默认值约束(default)
create table person(
id int,
name varchar(20) default 'it666'
);
参照完整性
参照完整性又称引用完整性, 主要用于保证多表之间引用关系的正确性。
为什么要进行表的拆分?如果将所有的数据都放到一张表中, 会出现大量冗余数据。
什么时候会出现冗余数据?
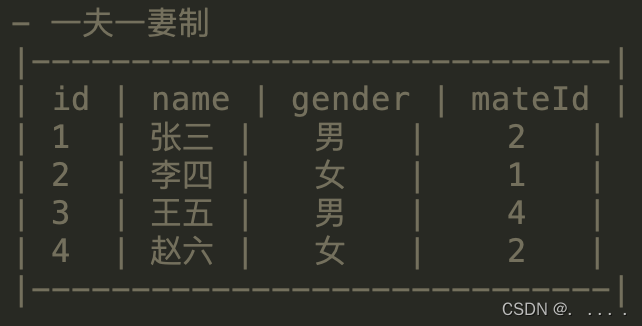
表与表之间的关系可以分为三种: 一对一、一对多、多对多。
- 一对一(一般不需要拆分):例如,一夫一妻制
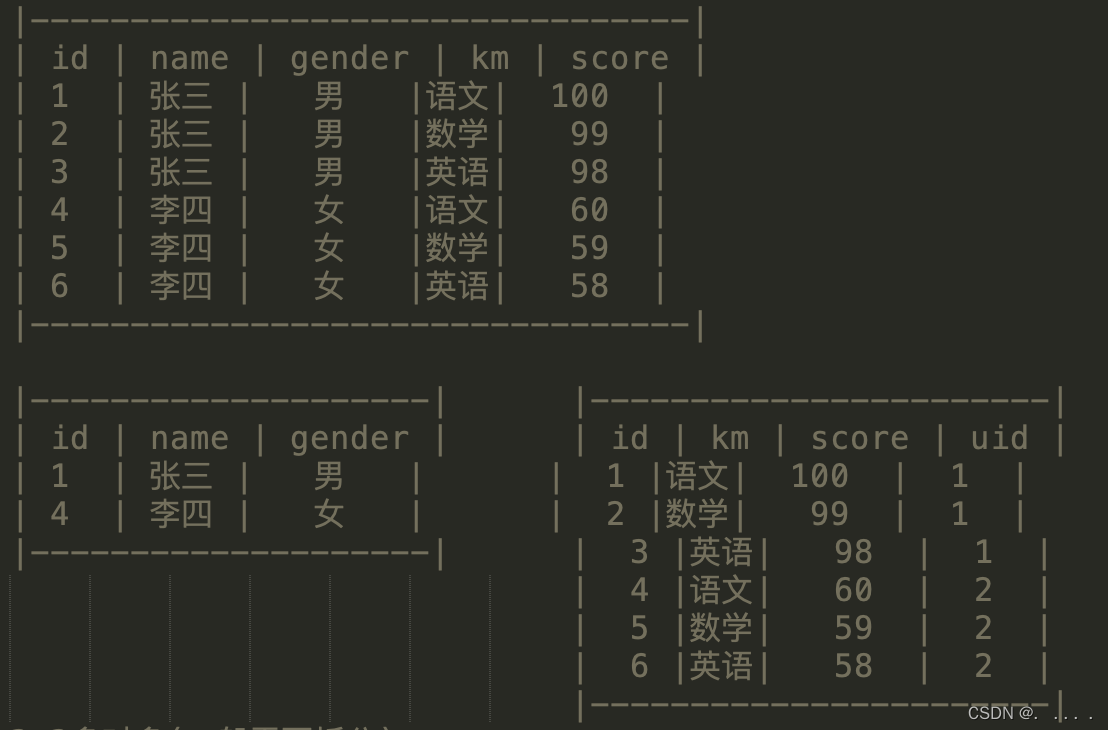
- 一对多(一般需要拆分): 例如,一个班有多个学生
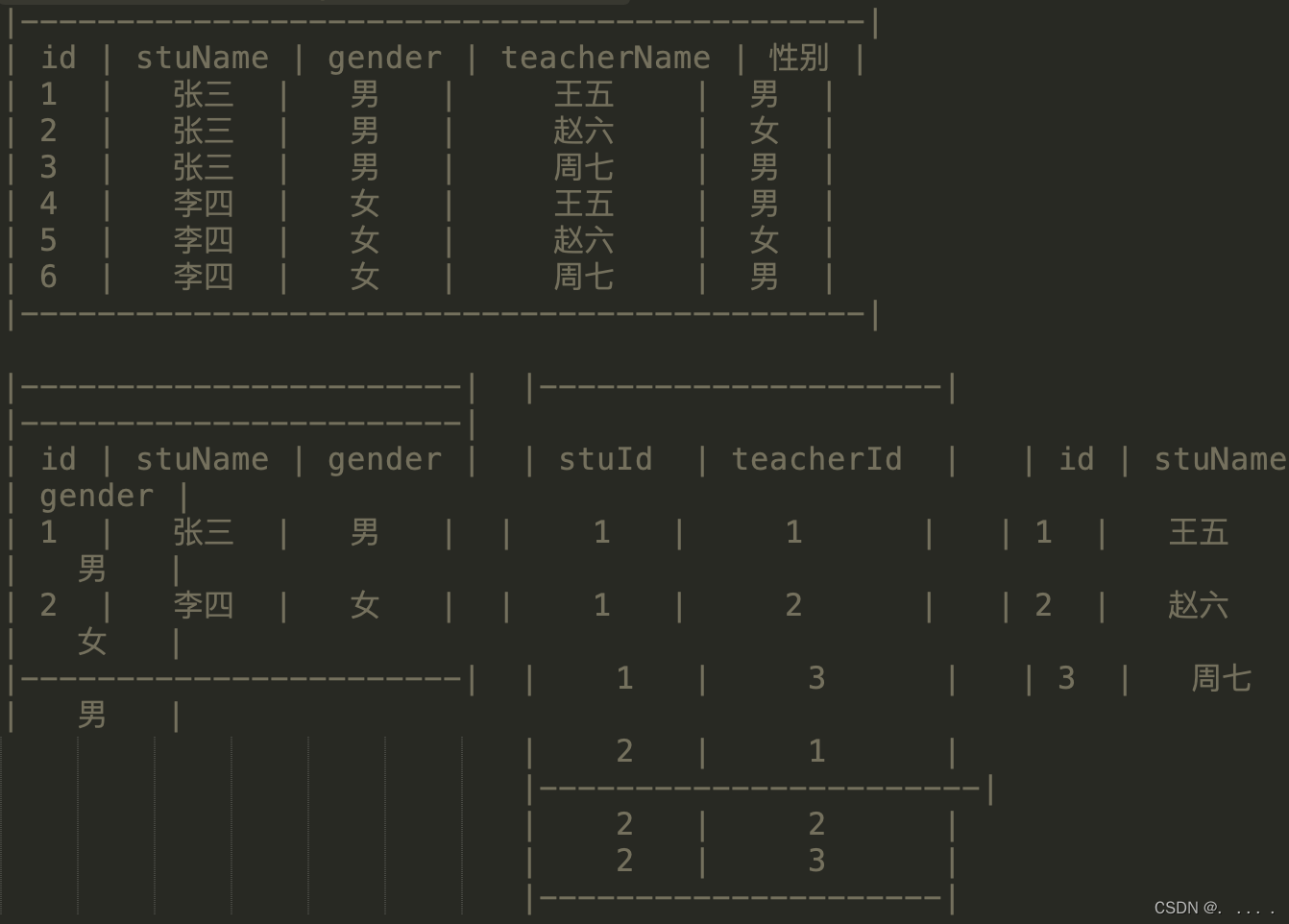
- 多对多(一般需要拆分):例如,一个学生有多个老师, 一个老师有多个学生
外键
为了保证表与表之间参照完整性, 我们可以通过’外键’来保证参照完整性。
如果一张表中有一个字段指向了别一张表中的主键,就将该字段叫做外键
例如: 成绩表中的uid引用了学生表中的id, 那么成绩表中的uid我们就称之为外键。
外键注意点:
- 只有InnoDB的存储引擎才支持外键约束。
- 外键的数据类型必须和指向的主键一样。
- 在一对多的关系中, 外键一般定义在多的一方(一个学生有多门成绩, 那么外键定义在成绩表中)。
- 定义外键的表我们称之为从表, 被外键引用的表我们称之为主表。
如何查看外键?
show create table 表名称;
外键的相关操作:
-
严格操作:
- 主表不存在对应数据,从表不允许添加
- insert into grade values (null, ‘语文’, 100, 3);
- 从表引用着数据,主表不允许删除
- delete from stu where id=1;
- 从表引用这数据, 主表不允许修改
- update stu set id=3 where id=1;
- 主表不存在对应数据,从表不允许添加
-
置空操作(null) :
- 在企业开发中, 我们可能必须要删除主表中的数据, 但是如果主表被删除了从表就不完整了
- 所以在企业开发中, 我们可以通过置空操作, 在删除主表数据的同时删除从表关联的数据
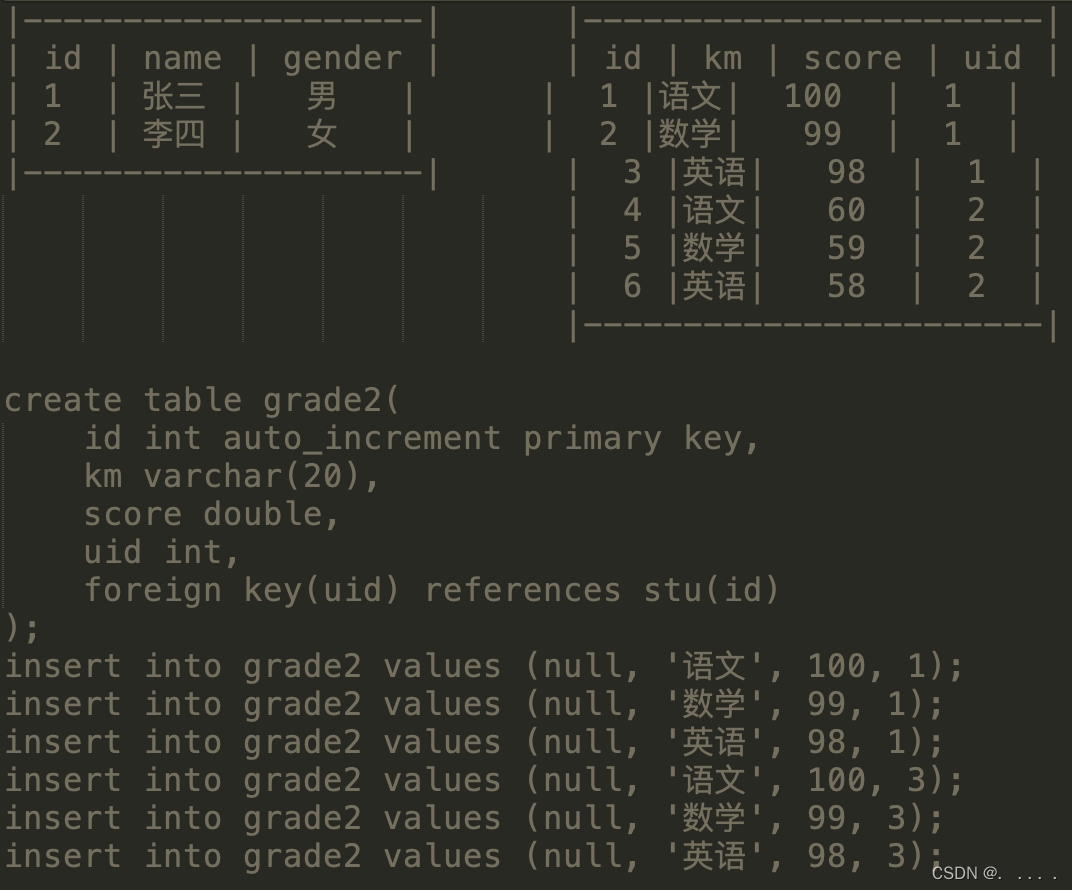
create table grade2( id int auto_increment primary key, km varchar(20), score double, uid int, foreign key(uid) references stu(id) on delete set null ); insert into grade values (null, '语文', 100, 1); delete from stu where id=1; -
级联操作(cascade):
- 在企业开发中, 我们可能必须要修改主表中的数据, 但是如果主表被修改了从表就不完整了
- 所以在企业开发中, 我们可以通过’级联操作’, 在修改主表数据的同时修改从表关联的数据
create table grade3( id int auto_increment primary key, km varchar(20), score double, uid int, foreign key(uid) references stu(id) on update cascade ); insert into grade values (null, '语文', 100, 1); update stu set id=1 where id=3;
单表查询
模糊查询:任务39.
格式:
select 字段 from 表名 where 字段 like ‘条件’;
- _通配符: 表示任意一个字符
- %通配符: 表示任意0~n个字符
排序 order by
select 字段 from 表名 order by 字段 [asc | desc];
select * from stu order by age; #默认按照升序进行排序
select * from stu order by age asc; # 升序排序
select * from stu order by age desc; # 降序排序
select * from stu order by age desc, score asc; #如果年龄相同, 那么还可以继续按照其它字段来排序
聚合函数
count(); 统计
select count(*) from stu;
select count(*) from stu where score >= 60;
sum(); 求和
select sum(id) from stu;
avg(); 求平均值
select avg(id) from stu; # 21 / 6 = 3.5
select avg(score) from stu;
max(); 获取最大值
select max(score) from stu;
min(); 获取最小值
select min(score) from stu;
数据分组 group by
注意点:
- 在对数据进行分组的时候, select 后面必须是分组字段或者聚合函数, 否则就只会返回第一条数据
select city from stu group by city;
select name from stu group by city;
select city, group_concat(name) from stu group by city;
条件查询having
- having和where很像都是用来做条件查询的
- 但是where是去数据库中查询符合条件的数据, 而having是去结果集中查询符合条件的数据
select * from stu where city='北京';
select * from stu having city='北京';
select name, age from stu where city='北京';
select name, age from stu having city='北京';
#Unknown column 'city' in 'having clause'
分页 limit:
select 字段 from 表 limit 索引, 个数;
select * from stu limit 0, 3;
select * from stu limit 3, 3;
查询选项
select [查询选项] 字段名称 from 表名;
all: 显示所有查询出来的数据[默认]
distinct: 去除结果集中重复的数据之后再显示
select name from stu;
select all name from stu;
select distinct name from stu;
注意点:
如果是通过distinct来对结果集中重复的数据进行去重,那么只有所有列的数据都相同才会去重。
多表查询 – 任务46
多表查询
多表查询只需要在单表查询基础上增加一张表即可:
select * from 表名1, 表名2;
select * from stu, grade;
注意点:默认情况下多表查询的结果是笛卡尔集。
union作用
在纵向上将多张表的结果结合起来返回给我们
select * from 表名1 union select * from 表名2;
select id, name from stu union select id, score from grade;
注意点:
- 使用union进行多表查询, 返回的结果集的表头的名称是第一张表的名称
- 使用union进行多表查询, 必须保证多张表查询的字段个数一致
- 使用union进行多表查询, 默认情况下会自动去重
- 使用union进行多表查询, 如果不想自动去重, 那么可以在union后面加上all
#select id, name from stu union all select id, name from person;
表的连接查询
1. 内连接 inner join
select * from stu, grade where stu.id = grade.stuId;
select * from 表名1 inner join 表名2 on 条件;
select * from stu inner join grade on stu.id = grade.stuId;
注意点:
- 在进行多表查询的时候, 如果想查询指定的字段, 那么必须在字段名称前面加上表名才行
#select stu.id, stu.name, grade.score from stu inner join grade on stu.id = grade.stuId; - 在内连接中只会返回满足条件的数据
2. 外连接
左外连接 left join
- 在左外连接中, 左边的表是不看条件的, 无论条件是否满足, 都会返回左边表中所有的数据
- 在左外连接中, 只有右边的表会看条件, 对于右边的表而言, 只有满足条件才会返回对应的数据
select stu.id, stu.name, grade.score from stu left join grade on stu.id = grade.stuId;
右外连接 right join
- 在右外连接中, 右边的表是不看条件的, 无论条件是否满足, 都会返回右边表中所有的数据
- 在右外连接中, 只有左边的表会看条件, 对于左边的表而言, 只有满足条件才会返回对应的数据
select stu.id, stu.name, grade.score from stu right join grade on stu.id = grade.stuId;
3. 交叉连接 cross join
- 如果没有指定条件, 那么返回笛卡尔集
#select stu.id, stu.name, grade.score from stu cross join grade; - 如果指定了条件, 那么就等价于内连接
#select stu.id, stu.name, grade.score from stu cross join grade on stu.id = grade.stuId;
- 全连接 full join(MySQL不支持全连接)。
为了简化上面的连接,还有个自然连接,自然连接(natural)就是用来简化’内连接和外连接’的,如果多张表需要判断的条件字段名称一致, 那么不用编写条件, 自然连接会自动判断。例如:
select * from 表名1 inner join 表名2 on 条件;
select * from stu inner join grade on stu.id = grade.stuId;
select * from 表名1 natural join 表名2;
select * from stu natural join grade;
同理,自然连接也有自然左外连接和自然右外连接。
如果多张表需要判断的条件字段名称一致, 那么除了可以使用自然连接来简化以外,还可以使用using关键字来简化
// 内连接
select * from stu inner join grade on stu.stuId = grade.stuId;
select * from stu inner join grade using(stuId);
子查询
- 将一个查询语句查询的结果作为另一个查询语句的条件来使用;
- 将一个查询语句查询的结果作为另一个查询语句的表来使用;
将一个查询语句查询的结果作为另一个查询的条件来使用
// 返回的结果只有一个
select stuId from grade where score = 100;
select name from stu where stuId = 3;
select name from stu where stuId = (select stuId from grade where score = 100);
// 返回的结果有多个
select stuId from grade where score >= 60;
select name from stu where stuId = 3 OR stuId = 1;
select name from stu where stuId in(3, 1);
select name from stu where stuId in(select stuId from grade where score >= 60);
将一个查询语句查询的结果作为另一个查询的表来使用
select name, city, score from person where score >= 60;
select name, city, score from (select name, city, score from person where score >= 60) as t;
注意点:
如果要将一个查询语句查询的结果作为另一个查询的表来使用, 那么必须给子查询起一个别名。
事务
对事务的理解和基本概念
- MySQL中的事务主要用于处理容易出错的数据。
- 事务可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
- 事务用来管理 insert,update,delete 语句
- MySQL中只有使用了 Innodb 数据库引擎的表才支持事务。
银行卡转账案例。

语法
开启事务: start transaction
提交事务: commit
回滚事务: rollback
注意点:
事务的本质是开启事务的时候拷贝一张一模一样的表,然后执行相关的操作都是在拷贝的这张表中做操作,
如果失败了, 如果执行了rollback, 那么系统就会自动删除拷贝的这张表
所以失败了不会影响到原有的数据。
如果成功了, 如果执行了commit, 那么系统就会自动利用拷贝表中最新的数据覆盖原有表中的数据,所以成功了会影响到原有的数据。
另外,如何整体回滚外,也可以设置事务回滚点,这样如果失败就可以回滚到指定的地方。
事务特点:
-
原子性(关注的是状态):
事务开启后的所有操作,要么全部成功,要么全部失败,不可能出现部分成功的情况。事务执行过程中如果出错,哪怕我们不手动回滚, 系统也会自动帮我们回滚 -
一致性(关注数据可见性):
事务开始前和结束后,数据库的完整性约束没有被破坏
例如 A向B转账,不可能A扣了钱,B却没收到 -
持久性:
事务完成后,事务对数据库的所有操作是永久的, 操作完成之后就不能再回滚 -
隔离性:
数据库允许多个并发事务同时对其数据进行读写和修改的能力,
隔离性可以防止多个事务并发时由于交叉执行而导致数据的不一致。
事务隔离级别 - 任务57,讲的特别清晰
- 读未提交(read uncommitted): 一个事务可以读取另一个未提交事务的数据。
问题:脏读。 - 读提交(read committed): 一个事务要等另一个事务提交后才能读取数据。
问题:在一个事务范围内多次查询的结果不同,即不可重复读。 - 可重复读(repeatable read): 一个事务范围内多个相同的查询返回相同的结果:
问题:幻读。 - 串行化(serializable): 前面一个事务没有执行完后面一个事务不能执行。
视图 - 任务58
视图基本概念
- 视图本质就是将结果集缓存起来
- 由于结果集是一张虚拟的表, 所以视图也是一张虚拟的表
- 由于结果集是建立在表的基础上的, 所以视图也是建立在表的基础上的
视图的作用:
- 视图可以用来简化SQL语句
- 视图可以用来隐藏表的结构
- 视图可以用来提升数据安全性
创建视图语法
create view 视图名称 as select 语句;
视图数据操作
SELECT name, city FROM person;
CREATE VIEW person_view as SELECT name, city FROM person;
SELECT * FROM person_view;
INSERT INTO person_view values ('it666', '武汉');
UPDATE person_view set city='香港' WHERE name='it666';
DELETE FROM person_view WHERE name='it666';
注意点:
由于视图保存的是结果集, 由于结果集是基于原始表的,所以操作视图中的数据, 本质上操作的是原始表中的数据。
另外,也可以对视图进行修改和删除。
视图更新限制(with check option)
- 如果视图的算法是merge算法, 那么可以更新视图
- 如果没有指with check option, 那么无论数据符不符合创建视图条件都可以更新
- 如果指定了with check option, 那么只有符合创建视图条件才可以更新
- 除此之外由于视图是一张虚拟表, 视图是基于原始表的, 更新视图的本质就是更新原始表
所以只有原始表中存在的原始数据才可以更新,通过其它方式生成的数据都不可以更新。
预处理
所谓的预处理技术,最初也是由MySQL提出的一种减轻服务器压力的一种技术!
传统mysql处理流程
- 在客户端准备sql语句
select * from stu where id=1;
select * from stu where id=2;
- 发送sql语句到MySQL服务器。
- MySQL服务器对sql语句进行解析(词法,语法), 然后编译, 然后执行该sql语句。
- 服务器将执行结果返回给客户端。
弊端:
- 哪怕多次传递的语句大部分内容都是相同的, 每次还是要重复传递
- 哪怕语句是相同的, 每次执行之前还是要先解析、编译之后才能执行
预处理的处理流程:
- 在客户端准备预处理sql语句
prepare 预处理名称 from 'sql语句';
prepare stmt from 'select * from stu where id=?;';
- 发送预处理sql语句到MySQL服务器
- MySQL服务器对预处理sql语句进行解析(词法,语法), 但不会执行
- 在客户端准备相关数据
set @id=1; - MySQL服务器对数据和预处理sql编译, 然后执行该sql语句
execute stmt using @id; - 服务器将返回结果给客户端
优点:
- 只对sql语句进行了一次解析
- 重复内容大大减少(网络传输更快)
存储过程
什么是存储过程?
存储过程和其它编程语言的函数很像, 可以用于封装一组特定功能的SQL语句集;用户通过’call 存储过程的名称()’ 来调用执行它。
存储过程基本语法
create procedure 存储过程名称(形参列表)
begin
// sql语句
// ... ...
end;
示例:
create procedure show_stu_by_id(stuId int)
begin
select * from stu where id=stuId;
end;
查看存储过程
- 查看MySQL中所有存储过程
show procedure status; - 查看指定数据库中的存储过程
show procedure status where db=‘db_name’; - 查看指定存储过程的源代码
show create procedure show_stu;
删除存储过程
drop procedure show_stu;
如何在MySQL中定义变量
- 全局变量:
定义: @变量名称;
赋值: set @全局变量名称=值;
select 字段名称 into @全局变量名称 from 表名; - 局部变量:
定义: declare 变量名称 数据类型;
赋值: set 局部变量名称=值;
select 字段名称 into 局部变量名称 from 表名;
自定义函数
什么是自定义函数
自定义函数和存储过程很像,只不过自定义函数不需要手动通过call调用, 而是和其它的聚合函数一样会在SQL语句中自动被调用,例如自定义函数名为add_stu,那么执行的时候不需要call,只需要select add_stu() from dual;
即:自定义函数需要和其他SQL语句配合使用,而存储过程需要手动call一下。
创建自定义函数
create function 函数名(形参列表) returns 数据类型 函数特征
begin
sql语句;
... ...
return 值;
end;
备注:在MySQL中也有if语句、switch语句、循环语句。
索引
需求: 往数据库里存储一万条数据
实现方案:
- 写一万条insert into语句
- 将insert into语句封装到存储过程或者函数中
将来怎么使用?是配合其它SQL语句使用, 还是单独使用?
- 单独使用–存储过程
- 配合其它SQL语句使用–自定义函数
create procedure add_stus(num int)
begin
declare currentId int default 0;
declare currentAge int default 0;
declare currentName varchar(255) default '';
while currentId < num do
set currentId = currentId + 1;
set currentAge = floor(rand() * 30);
set currentName = concat('it', currentAge);
insert into stu values(currentId,currentName,currentAge);
end while;
end;
call add_stus(10000); #48.428s
注意点:
以上封装存在的问题, 默认情况下每生成一条插入语句, 就会立即执行这条插入的语句。所以整个过程我们生成了一万条插入语句, 我们解析了一万条插入的语句, 我们编译了一万条插入的语句, 我们执行了一万条插入的语句
所以整个过程就比较耗时
优化1 – 预处理,seqelize默认都是这么干的:
create procedure add_stus4(num int)
begin
set @currentId = 0;
set @currentAge = 0;
set @currentName = '';
prepare stmt from 'insert into stu values(?,?,?);';
set autocommit = 0;
while @currentId < num do
set @currentId = @currentId + 1;
set @currentAge = floor(rand() * 30);
set @currentName = concat('it', @currentAge);
execute stmt using @currentId, @currentName, @currentAge;
end while;
commit;
end;
call add_stus(10000); #2.017s
优化2:
只要在循环前面加上set autocommit = 0;,在循环后面加上commit;
那么就不会生成一条插入语句就执行一条插入语句了,会等到所有的插入语句都生成之后, 再统一的解析, 统一的编译, 统一的执行。
create procedure add_stus2(num int)
begin
declare currentId int default 0;
declare currentAge int default 0;
declare currentName varchar(255) default '';
set autocommit = 0;
while currentId < num do
set currentId = currentId + 1;
set currentAge = floor(rand() * 30);
set currentName = concat('it', currentAge);
insert into stu values(currentId,currentName,currentAge);
end while;
commit;
end;
call add_stus2(10000); #1.713s
什么是索引?
- 索引就相当于字典中的目录(拼音/偏旁部首手),有了目录我们就能通过目录快速的找到想要的结果。
- 但是如果没有目录(拼音/偏旁部首手), 没有索引,那么如果想要查找某条数据就必须从前往后一条一条的查找。
- 所以索引就是用于帮助我们提升数据的查询速度的。
索引的优缺点和使用原则
优点
- 大大加快数据的查询速度
- 没有任何限制, 所有MySql字段都可以用作索引
缺点
- 索引是真实存在的会占空间, 会增加数据库体积
- 如果对作为索引的字段进行增删修操作, 系统需要花费时间去更新维护索引
原则
- 对经常用于查询的字段应该创建索引(作为where条件字段、作为group by分组的字段, 作为order by排序的字段)
- 对于主键和外键系统会自动创建索引, 无序我们手动创建
- 对于数据量小的表不需要刻意使用索引
索引分类
- 单值索引: 将某个字段的值作为索引
- 复合索引: 将多个字段的值作为索引
- 唯一索引(唯一键): 索引列中的值必须是唯一的,但是允许为空值
- 主键索引:是一种特殊的唯一索引,不允许有空值
- … …
查看当前查询是否使用索引
查询没有索引的表
SELECT * FROM stu WHERE id=999999; #0.695s
查询有索引的表
SELECT * FROM stu2 WHERE id=999999; #0.008s
如何查看当前的查询语句有没有用到索引
EXPLAIN 查询语句;
如果返回的结果集中的key有值, 那么就表示当前的查询语句中用到了索引
如果返回的结果集中的key没有值, 那么就表示当前的查询语句中没有用到索引
如何添加索引
-
给表设置主键 - 自动添加, 只要设置了主键, 那么系统就会自动创建对应的索引
-
给表设置外键 - 自动添加, 只要设置了外键, 那么系统就会自动创建对应的索引
-
给表设置唯一键 - 自动添加, 只要设置了某一个字段的取值是唯一的, 也会自动创建对应的索引
-
创建表的时候指定给哪个字段添加索引 - 手动添加
create table test1(
id int,
name varchar(20),
index idx_name(id) #创建索引
);
- 创建好表之后再给指定字段添加索引 - 手动添加
create table test2(
id int,
name varchar(20),
);
create index idx_name on test2(id); #创建索引
create table test3(
id int,
name varchar(20),
);
alter table test3 add index idx_name(id);
删除索引
drop index 索引名称 on 表名;
什么是索引算法?
索引算法决定了如何创建索引,索引算法决定了如何查找索引对应的数据。
传统查找:
1, 2, 3, 4, 5
BTree查找:
4
|-------------|
2 6
|----|----| |----|----|
1 3 5 7
BTree索引:
BTree索引是基于平衡多叉排序树实现的, 能够缩短查找的次数
Hahs索引:
哈希索引是基于哈希表实现的, 只能用于memory存储引擎, 可以一次性定位到指定数据
https://dev.mysql.com/doc/refman/8.0/en/index-btree-hash.html
扩展:
Java中的jdbc
JDBC代表Java数据库连接(Java Database Connectivity)。它是一种Java编程语言用于与关系型数据库进行交互的API(应用程序接口)。JDBC允许Java应用程序通过标准的SQL语句访问数据库,执行查询、更新和管理数据库中的数据。
JDBC提供了一组Java类和接口,使Java应用程序能够执行以下任务:
-
建立连接: 通过JDBC,Java应用程序可以与数据库建立连接,这是执行任何数据库操作的第一步。
-
执行SQL语句: 通过JDBC,可以执行SQL查询、更新和删除等操作。JDBC支持预编译的语句,也可以执行动态生成的语句。
-
处理结果集: 当执行查询时,JDBC提供了一种方式来处理返回的结果集。开发人员可以迭代结果集,检索数据并进行相应的处理。
-
事务管理: JDBC允许在Java应用程序中管理事务,确保数据库操作的原子性、一致性、隔离性和持久性(ACID属性)。
-
处理异常: 通过捕获和处理JDBC异常,开发人员可以更好地处理与数据库连接和操作相关的问题。
使用JDBC,Java开发人员可以编写与数据库无关的代码,因为JDBC提供了一个标准的接口,允许在不同的数据库系统上运行相同的Java代码,只需更改数据库连接的配置。
总体而言,JDBC为Java应用程序与关系型数据库之间的通信提供了一种灵活、可扩展的方式。
mysql忘记密码处理:https://blog.csdn.net/weixin_43922901/article/details/109570089