本文主要讲述flink1.15版本checkpoint状态恢复之KafkaSourceEnumState和KafkaPartitionSplit恢复流程,其中包括topic、partition值、当前读取的offset值。
一、从checkpoint恢复
1. flink run形式的
A job may be resumed from a checkpoint just as from a savepoint by using the checkpoint’s meta data file instead (see the savepoint restore guide). Note that if the meta data file is not self-contained, the jobmanager needs to have access to the data files it refers to (see Directory Structure above).
$ bin/flink run -s :checkpointMetaDataPath [:runArgs]
例如:
$ bin/flink run -s hdfs://xxx/user/xxx/river/82d8fe12464eae32abeaadd5a252b888/chk-1 [:runArgs]
2. 从代码中恢复
Configuration configuration = new Configuration();
configuration.setString("execution.savepoint.path", "file:///c/xxx/3626c0cf8135dda32878ffa95b328888/chk-1");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
二、源码流程
1、入口
flink消费kafka任务直接启动入口:
@Internal
@Override
public SplitEnumerator<KafkaPartitionSplit, KafkaSourceEnumState> createEnumerator(
SplitEnumeratorContext<KafkaPartitionSplit> enumContext) {
return new KafkaSourceEnumerator(
subscriber,
startingOffsetsInitializer,
stoppingOffsetsInitializer,
props,
enumContext,
boundedness);
}
flink消费kafka的checkpoint恢复入口:
@Internal
@Override
public SplitEnumerator<KafkaPartitionSplit, KafkaSourceEnumState> restoreEnumerator(
SplitEnumeratorContext<KafkaPartitionSplit> enumContext,
KafkaSourceEnumState checkpoint)
throws IOException {
return new KafkaSourceEnumerator(
subscriber,
startingOffsetsInitializer,
stoppingOffsetsInitializer,
props,
enumContext,
boundedness,
checkpoint.assignedPartitions());
}
2、内容
flink读取kafka checkpoint的operator状态包括两种:coordinatorState和operatorSubtaskStates状态:
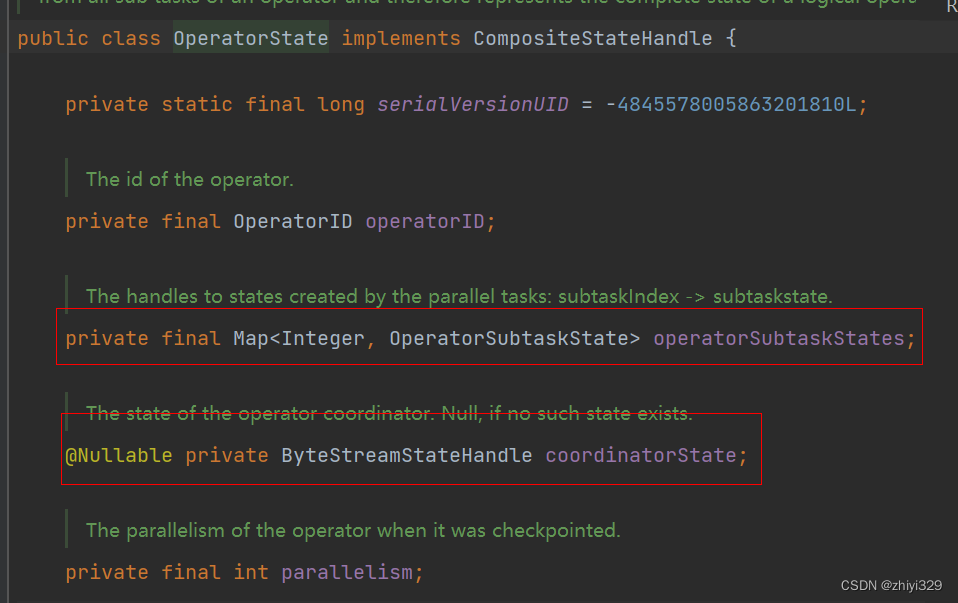
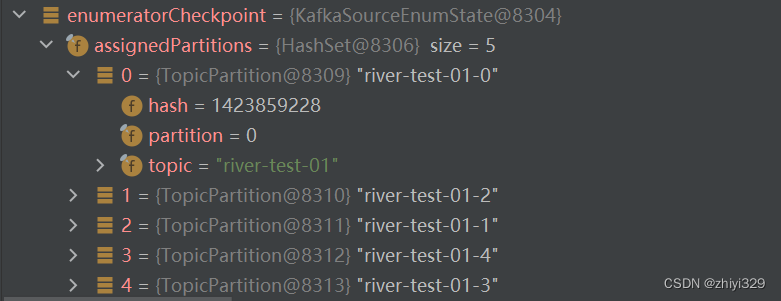
其中,coordinatorState保存了topic和以及当前任务分配的分区:
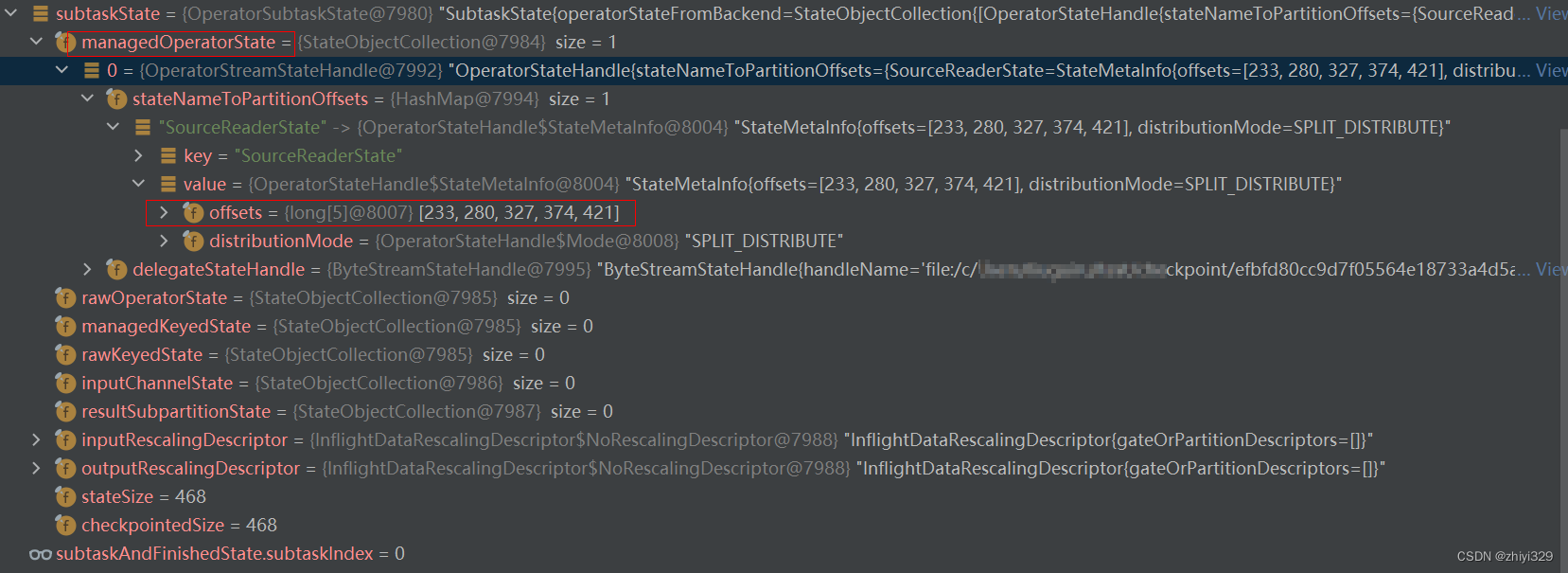
operatorSubtaskStates保存当前快照读取的offset值:
OperatorStateHandle{stateNameToPartitionOffsets={SourceReaderState=StateMetaInfo{offsets=[233, 280, 327, 374, 421], distributionMode=SPLIT_DISTRIBUTE}}, delegateStateHandle=ByteStreamStateHandle{handleName=‘file:/c/Users/liuguiru/test/checkpoint/f388506c01e786ab059809d65f8b5229/chk-16/6ac4a8e0-d50f-4115-91cb-bafd536b7226’, dataBytes=468}}
3、源码流程
主要讲解如何从checkpoint文件中读取checkpoint信息,然后解析成checkpoint数据KafkaSourceEnumState(即上面cp恢复入口处值)和KafkaPartitionSplit。
初始化JobMaster时,会创建DefaultScheduler实例,其调用父类SchedulerBase时,然后在createAndRestoreExecutionGraph中调用DefaultExecutionGraphFactory.createAndRestoreExecutionGraph -> tryRestoreExecutionGraphFromSavepoint -> CheckpointCoordinator.restoreSavepoint
public boolean restoreSavepoint(
SavepointRestoreSettings restoreSettings,
Map<JobVertexID, ExecutionJobVertex> tasks,
ClassLoader userClassLoader)
throws Exception {
final String savepointPointer = restoreSettings.getRestorePath();
final boolean allowNonRestored = restoreSettings.allowNonRestoredState();
Preconditions.checkNotNull(savepointPointer, "The savepoint path cannot be null.");
LOG.info(
"Starting job {} from savepoint {} ({})",
job,
savepointPointer,
(allowNonRestored ? "allowing non restored state" : ""));
final CompletedCheckpointStorageLocation checkpointLocation =
checkpointStorageView.resolveCheckpoint(savepointPointer);
// convert to checkpoint so the system can fall back to it
final CheckpointProperties checkpointProperties;
switch (restoreSettings.getRestoreMode()) {
case CLAIM:
checkpointProperties = this.checkpointProperties;
break;
case LEGACY:
checkpointProperties =
CheckpointProperties.forSavepoint(
false,
// we do not care about the format when restoring, the format is
// necessary when triggering a savepoint
SavepointFormatType.CANONICAL);
break;
case NO_CLAIM:
checkpointProperties = CheckpointProperties.forUnclaimedSnapshot();
break;
default:
throw new IllegalArgumentException("Unknown snapshot restore mode");
}
// Load the savepoint as a checkpoint into the system
CompletedCheckpoint savepoint =
Checkpoints.loadAndValidateCheckpoint(
job,
tasks,
checkpointLocation,
userClassLoader,
allowNonRestored,
checkpointProperties,
restoreSettings.getRestoreMode());
// register shared state - even before adding the checkpoint to the store
// because the latter might trigger subsumption so the ref counts must be up-to-date
savepoint.registerSharedStatesAfterRestored(
completedCheckpointStore.getSharedStateRegistry(),
restoreSettings.getRestoreMode());
completedCheckpointStore.addCheckpointAndSubsumeOldestOne(
savepoint, checkpointsCleaner, this::scheduleTriggerRequest);
// Reset the checkpoint ID counter
long nextCheckpointId = savepoint.getCheckpointID() + 1;
checkpointIdCounter.setCount(nextCheckpointId);
LOG.info("Reset the checkpoint ID of job {} to {}.", job, nextCheckpointId);
final OptionalLong restoredCheckpointId =
restoreLatestCheckpointedStateInternal(
new HashSet<>(tasks.values()),
OperatorCoordinatorRestoreBehavior.RESTORE_IF_CHECKPOINT_PRESENT,
true,
allowNonRestored,
true);
return restoredCheckpointId.isPresent();
}
在Checkpoints.loadAndValidateCheckpoint中获取到savepoint值,即operator状态:
public static CompletedCheckpoint loadAndValidateCheckpoint(
JobID jobId,
Map<JobVertexID, ExecutionJobVertex> tasks,
CompletedCheckpointStorageLocation location,
ClassLoader classLoader,
boolean allowNonRestoredState,
CheckpointProperties checkpointProperties,
RestoreMode restoreMode)
throws IOException {
checkNotNull(jobId, "jobId");
checkNotNull(tasks, "tasks");
checkNotNull(location, "location");
checkNotNull(classLoader, "classLoader");
final StreamStateHandle metadataHandle = location.getMetadataHandle();
final String checkpointPointer = location.getExternalPointer();
// (1) load the savepoint
final CheckpointMetadata checkpointMetadata;
try (InputStream in = metadataHandle.openInputStream()) {
DataInputStream dis = new DataInputStream(in);
checkpointMetadata = loadCheckpointMetadata(dis, classLoader, checkpointPointer);
}
// generate mapping from operator to task
Map<OperatorID, ExecutionJobVertex> operatorToJobVertexMapping = new HashMap<>();
for (ExecutionJobVertex task : tasks.values()) {
for (OperatorIDPair operatorIDPair : task.getOperatorIDs()) {
operatorToJobVertexMapping.put(operatorIDPair.getGeneratedOperatorID(), task);
operatorIDPair
.getUserDefinedOperatorID()
.ifPresent(id -> operatorToJobVertexMapping.put(id, task));
}
}
// (2) validate it (parallelism, etc)
HashMap<OperatorID, OperatorState> operatorStates =
new HashMap<>(checkpointMetadata.getOperatorStates().size());
for (OperatorState operatorState : checkpointMetadata.getOperatorStates()) {
ExecutionJobVertex executionJobVertex =
operatorToJobVertexMapping.get(operatorState.getOperatorID());
if (executionJobVertex != null) {
if (executionJobVertex.getMaxParallelism() == operatorState.getMaxParallelism()
|| executionJobVertex.canRescaleMaxParallelism(
operatorState.getMaxParallelism())) {
operatorStates.put(operatorState.getOperatorID(), operatorState);
} else {
String msg =
String.format(
"Failed to rollback to checkpoint/savepoint %s. "
+ "Max parallelism mismatch between checkpoint/savepoint state and new program. "
+ "Cannot map operator %s with max parallelism %d to new program with "
+ "max parallelism %d. This indicates that the program has been changed "
+ "in a non-compatible way after the checkpoint/savepoint.",
checkpointMetadata,
operatorState.getOperatorID(),
operatorState.getMaxParallelism(),
executionJobVertex.getMaxParallelism());
throw new IllegalStateException(msg);
}
} else if (allowNonRestoredState) {
LOG.info(
"Skipping savepoint state for operator {}.", operatorState.getOperatorID());
} else {
if (operatorState.getCoordinatorState() != null) {
throwNonRestoredStateException(
checkpointPointer, operatorState.getOperatorID());
}
for (OperatorSubtaskState operatorSubtaskState : operatorState.getStates()) {
if (operatorSubtaskState.hasState()) {
throwNonRestoredStateException(
checkpointPointer, operatorState.getOperatorID());
}
}
LOG.info(
"Skipping empty savepoint state for operator {}.",
operatorState.getOperatorID());
}
}
return new CompletedCheckpoint(
jobId,
checkpointMetadata.getCheckpointId(),
0L,
0L,
operatorStates,
checkpointMetadata.getMasterStates(),
checkpointProperties,
restoreMode == RestoreMode.CLAIM
? new ClaimModeCompletedStorageLocation(location)
: location,
null);
}
loadCheckpointMetadata根据checkpoint路径和输入数据流,获取checkpoint元数据:
public static CheckpointMetadata loadCheckpointMetadata(
DataInputStream in, ClassLoader classLoader, String externalPointer)
throws IOException {
checkNotNull(in, "input stream");
checkNotNull(classLoader, "classLoader");
final int magicNumber = in.readInt();
if (magicNumber == HEADER_MAGIC_NUMBER) {
final int version = in.readInt();
final MetadataSerializer serializer = MetadataSerializers.getSerializer(version);
return serializer.deserialize(in, classLoader, externalPointer);
} else {
throw new IOException(
"Unexpected magic number. This can have multiple reasons: "
+ "(1) You are trying to load a Flink 1.0 savepoint, which is not supported by this "
+ "version of Flink. (2) The file you were pointing to is not a savepoint at all. "
+ "(3) The savepoint file has been corrupted.");
}
}
调用MetadataV3Serializer.deserialize进行反序列化:
public CheckpointMetadata deserialize(
DataInputStream dis, ClassLoader classLoader, String externalPointer)
throws IOException {
return deserializeMetadata(dis, externalPointer);
}
然后调用MetadataV2V3SerializerBase.deserializeMetadata反序列化:
protected CheckpointMetadata deserializeMetadata(
DataInputStream dis, @Nullable String externalPointer) throws IOException {
final DeserializationContext context =
externalPointer == null ? null : new DeserializationContext(externalPointer);
// first: checkpoint ID
final long checkpointId = dis.readLong();
if (checkpointId < 0) {
throw new IOException("invalid checkpoint ID: " + checkpointId);
}
// second: master state
final List<MasterState> masterStates;
final int numMasterStates = dis.readInt();
if (numMasterStates == 0) {
masterStates = Collections.emptyList();
} else if (numMasterStates > 0) {
masterStates = new ArrayList<>(numMasterStates);
for (int i = 0; i < numMasterStates; i++) {
masterStates.add(deserializeMasterState(dis));
}
} else {
throw new IOException("invalid number of master states: " + numMasterStates);
}
// third: operator states
final int numTaskStates = dis.readInt();
final List<OperatorState> operatorStates = new ArrayList<>(numTaskStates);
for (int i = 0; i < numTaskStates; i++) {
operatorStates.add(deserializeOperatorState(dis, context));
}
return new CheckpointMetadata(checkpointId, operatorStates, masterStates);
}
调用deserializeOperatorState反序列化算子的状态:
protected OperatorState deserializeOperatorState(
DataInputStream dis, @Nullable DeserializationContext context) throws IOException {
final OperatorID jobVertexId = new OperatorID(dis.readLong(), dis.readLong());
final int parallelism = dis.readInt();
final int maxParallelism = dis.readInt();
ByteStreamStateHandle coordinateState =
deserializeAndCheckByteStreamStateHandle(dis, context);
final int numSubTaskStates = dis.readInt();
if (numSubTaskStates < 0) {
checkState(
coordinateState == null,
"Coordinator State should be null for fully finished operator state");
return new FullyFinishedOperatorState(jobVertexId, parallelism, maxParallelism);
}
final OperatorState operatorState =
new OperatorState(jobVertexId, parallelism, maxParallelism);
// Coordinator state
operatorState.setCoordinatorState(coordinateState);
// Sub task states
for (int j = 0; j < numSubTaskStates; j++) {
SubtaskAndFinishedState subtaskAndFinishedState =
deserializeSubtaskIndexAndFinishedState(dis);
if (subtaskAndFinishedState.isFinished) {
operatorState.putState(
subtaskAndFinishedState.subtaskIndex,
FinishedOperatorSubtaskState.INSTANCE);
} else {
final OperatorSubtaskState subtaskState = deserializeSubtaskState(dis, context);
operatorState.putState(subtaskAndFinishedState.subtaskIndex, subtaskState);
}
}
return operatorState;
}
1)deserializeAndCheckByteStreamStateHandle反序列化coordinateState,即KafkaSourceEnumState消费的topic和分区:
static ByteStreamStateHandle deserializeAndCheckByteStreamStateHandle(
DataInputStream dis, @Nullable DeserializationContext context) throws IOException {
final StreamStateHandle handle = deserializeStreamStateHandle(dis, context);
if (handle == null || handle instanceof ByteStreamStateHandle) {
return (ByteStreamStateHandle) handle;
} else {
throw new IOException(
"Expected a ByteStreamStateHandle but found a " + handle.getClass().getName());
}
}
static StreamStateHandle deserializeStreamStateHandle(
DataInputStream dis, @Nullable DeserializationContext context) throws IOException {
final int type = dis.read();
if (NULL_HANDLE == type) {
return null;
} else if (FILE_STREAM_STATE_HANDLE == type) {
long size = dis.readLong();
String pathString = dis.readUTF();
return new FileStateHandle(new Path(pathString), size);
} else if (BYTE_STREAM_STATE_HANDLE == type) {
String handleName = dis.readUTF();
int numBytes = dis.readInt();
byte[] data = new byte[numBytes];
dis.readFully(data);
return new ByteStreamStateHandle(handleName, data);
} else if (RELATIVE_STREAM_STATE_HANDLE == type) {
if (context == null) {
throw new IOException(
"Cannot deserialize a RelativeFileStateHandle without a context to make it relative to.");
}
String relativePath = dis.readUTF();
long size = dis.readLong();
Path statePath = new Path(context.getExclusiveDirPath(), relativePath);
return new RelativeFileStateHandle(statePath, relativePath, size);
} else if (KEY_GROUPS_HANDLE == type) {
int startKeyGroup = dis.readInt();
int numKeyGroups = dis.readInt();
KeyGroupRange keyGroupRange =
KeyGroupRange.of(startKeyGroup, startKeyGroup + numKeyGroups - 1);
long[] offsets = new long[numKeyGroups];
for (int i = 0; i < numKeyGroups; ++i) {
offsets[i] = dis.readLong();
}
KeyGroupRangeOffsets keyGroupRangeOffsets =
new KeyGroupRangeOffsets(keyGroupRange, offsets);
StreamStateHandle stateHandle = deserializeStreamStateHandle(dis, context);
return new KeyGroupsStateHandle(keyGroupRangeOffsets, stateHandle);
} else {
throw new IOException("Unknown implementation of StreamStateHandle, code: " + type);
}
}
data即为coordinateStat,后面会进行反序列化:
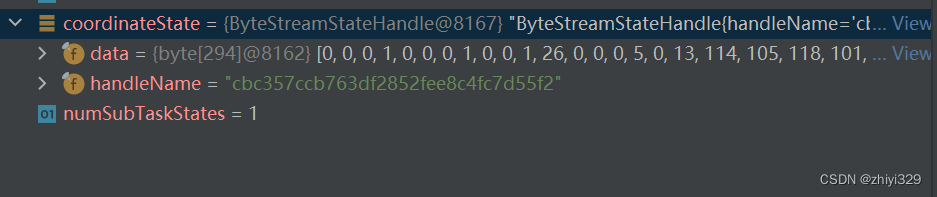
2)deserializeSubtaskState反序列化OperatorSubtaskState状态,即获取到KafkaPartitionSplit offset值:
protected OperatorSubtaskState deserializeSubtaskState(
DataInputStream dis, @Nullable DeserializationContext context) throws IOException {
final OperatorSubtaskState.Builder state = OperatorSubtaskState.builder();
final boolean hasManagedOperatorState = dis.readInt() != 0;
if (hasManagedOperatorState) {
state.setManagedOperatorState(deserializeOperatorStateHandle(dis, context));
}
final boolean hasRawOperatorState = dis.readInt() != 0;
if (hasRawOperatorState) {
state.setRawOperatorState(deserializeOperatorStateHandle(dis, context));
}
final KeyedStateHandle managedKeyedState = deserializeKeyedStateHandle(dis, context);
if (managedKeyedState != null) {
state.setManagedKeyedState(managedKeyedState);
}
final KeyedStateHandle rawKeyedState = deserializeKeyedStateHandle(dis, context);
if (rawKeyedState != null) {
state.setRawKeyedState(rawKeyedState);
}
state.setInputChannelState(deserializeInputChannelStateHandle(dis, context));
state.setResultSubpartitionState(deserializeResultSubpartitionStateHandle(dis, context));
return state.build();
}
其中的managedOperatorState即为offset值:
OperatorStateHandle deserializeOperatorStateHandle(
DataInputStream dis, @Nullable DeserializationContext context) throws IOException {
final int type = dis.readByte();
if (NULL_HANDLE == type) {
return null;
} else if (PARTITIONABLE_OPERATOR_STATE_HANDLE == type) {
int mapSize = dis.readInt();
Map<String, OperatorStateHandle.StateMetaInfo> offsetsMap = new HashMap<>(mapSize);
for (int i = 0; i < mapSize; ++i) {
String key = dis.readUTF();
int modeOrdinal = dis.readByte();
OperatorStateHandle.Mode mode = OperatorStateHandle.Mode.values()[modeOrdinal];
long[] offsets = new long[dis.readInt()];
for (int j = 0; j < offsets.length; ++j) {
offsets[j] = dis.readLong();
}
OperatorStateHandle.StateMetaInfo metaInfo =
new OperatorStateHandle.StateMetaInfo(offsets, mode);
offsetsMap.put(key, metaInfo);
}
StreamStateHandle stateHandle = deserializeStreamStateHandle(dis, context);
return new OperatorStreamStateHandle(offsetsMap, stateHandle);
} else {
throw new IllegalStateException("Reading invalid OperatorStateHandle, type: " + type);
}
}
deserializeStreamStateHandle读取数据:
static StreamStateHandle deserializeStreamStateHandle(
DataInputStream dis, @Nullable DeserializationContext context) throws IOException {
final int type = dis.read();
if (NULL_HANDLE == type) {
return null;
} else if (FILE_STREAM_STATE_HANDLE == type) {
long size = dis.readLong();
String pathString = dis.readUTF();
return new FileStateHandle(new Path(pathString), size);
} else if (BYTE_STREAM_STATE_HANDLE == type) {
String handleName = dis.readUTF();
int numBytes = dis.readInt();
byte[] data = new byte[numBytes];
dis.readFully(data);
return new ByteStreamStateHandle(handleName, data);
} else if (RELATIVE_STREAM_STATE_HANDLE == type) {
if (context == null) {
throw new IOException(
"Cannot deserialize a RelativeFileStateHandle without a context to make it relative to.");
}
String relativePath = dis.readUTF();
long size = dis.readLong();
Path statePath = new Path(context.getExclusiveDirPath(), relativePath);
return new RelativeFileStateHandle(statePath, relativePath, size);
} else if (KEY_GROUPS_HANDLE == type) {
int startKeyGroup = dis.readInt();
int numKeyGroups = dis.readInt();
KeyGroupRange keyGroupRange =
KeyGroupRange.of(startKeyGroup, startKeyGroup + numKeyGroups - 1);
long[] offsets = new long[numKeyGroups];
for (int i = 0; i < numKeyGroups; ++i) {
offsets[i] = dis.readLong();
}
KeyGroupRangeOffsets keyGroupRangeOffsets =
new KeyGroupRangeOffsets(keyGroupRange, offsets);
StreamStateHandle stateHandle = deserializeStreamStateHandle(dis, context);
return new KeyGroupsStateHandle(keyGroupRangeOffsets, stateHandle);
} else {
throw new IOException("Unknown implementation of StreamStateHandle, code: " + type);
}
}
至此,拿到完整的savepoint值返回,在CheckpointCoordinator.restoreSavepoint中restoreLatestCheckpointedStateInternal进行反序列化coordinateState:
private OptionalLong restoreLatestCheckpointedStateInternal(
final Set<ExecutionJobVertex> tasks,
final OperatorCoordinatorRestoreBehavior operatorCoordinatorRestoreBehavior,
final boolean errorIfNoCheckpoint,
final boolean allowNonRestoredState,
final boolean checkForPartiallyFinishedOperators)
throws Exception {
synchronized (lock) {
if (shutdown) {
throw new IllegalStateException("CheckpointCoordinator is shut down");
}
// Restore from the latest checkpoint
CompletedCheckpoint latest = completedCheckpointStore.getLatestCheckpoint();
if (latest == null) {
LOG.info("No checkpoint found during restore.");
if (errorIfNoCheckpoint) {
throw new IllegalStateException("No completed checkpoint available");
}
LOG.debug("Resetting the master hooks.");
MasterHooks.reset(masterHooks.values(), LOG);
if (operatorCoordinatorRestoreBehavior
== OperatorCoordinatorRestoreBehavior.RESTORE_OR_RESET) {
// we let the JobManager-side components know that there was a recovery,
// even if there was no checkpoint to recover from, yet
LOG.info("Resetting the Operator Coordinators to an empty state.");
restoreStateToCoordinators(
OperatorCoordinator.NO_CHECKPOINT, Collections.emptyMap());
}
return OptionalLong.empty();
}
LOG.info("Restoring job {} from {}.", job, latest);
this.forceFullSnapshot = latest.getProperties().isUnclaimed();
// re-assign the task states
final Map<OperatorID, OperatorState> operatorStates = extractOperatorStates(latest);
if (checkForPartiallyFinishedOperators) {
VertexFinishedStateChecker vertexFinishedStateChecker =
vertexFinishedStateCheckerFactory.apply(tasks, operatorStates);
vertexFinishedStateChecker.validateOperatorsFinishedState();
}
StateAssignmentOperation stateAssignmentOperation =
new StateAssignmentOperation(
latest.getCheckpointID(), tasks, operatorStates, allowNonRestoredState);
stateAssignmentOperation.assignStates();
// call master hooks for restore. we currently call them also on "regional restore"
// because
// there is no other failure notification mechanism in the master hooks
// ultimately these should get removed anyways in favor of the operator coordinators
MasterHooks.restoreMasterHooks(
masterHooks,
latest.getMasterHookStates(),
latest.getCheckpointID(),
allowNonRestoredState,
LOG);
if (operatorCoordinatorRestoreBehavior != OperatorCoordinatorRestoreBehavior.SKIP) {
restoreStateToCoordinators(latest.getCheckpointID(), operatorStates);
}
// update metrics
long restoreTimestamp = System.currentTimeMillis();
RestoredCheckpointStats restored =
new RestoredCheckpointStats(
latest.getCheckpointID(),
latest.getProperties(),
restoreTimestamp,
latest.getExternalPointer());
statsTracker.reportRestoredCheckpoint(restored);
return OptionalLong.of(latest.getCheckpointID());
}
}
restoreStateToCoordinators获取coordinateState状态中的data,然后在resetToCheckpoint中进行反序列化:
private void restoreStateToCoordinators(
final long checkpointId, final Map<OperatorID, OperatorState> operatorStates)
throws Exception {
for (OperatorCoordinatorCheckpointContext coordContext : coordinatorsToCheckpoint) {
final OperatorState state = operatorStates.get(coordContext.operatorId());
final ByteStreamStateHandle coordinatorState =
state == null ? null : state.getCoordinatorState();
final byte[] bytes = coordinatorState == null ? null : coordinatorState.getData();
coordContext.resetToCheckpoint(checkpointId, bytes);
}
}
调用OperatorCoordinatorHolder.resetToCheckpoint方法:
public void resetToCheckpoint(long checkpointId, @Nullable byte[] checkpointData)
throws Exception {
// the first time this method is called is early during execution graph construction,
// before the main thread executor is set. hence this conditional check.
if (mainThreadExecutor != null) {
mainThreadExecutor.assertRunningInMainThread();
}
eventValve.openValveAndUnmarkCheckpoint();
context.resetFailed();
// when initial savepoints are restored, this call comes before the mainThreadExecutor
// is available, which is needed to set up these gateways. So during the initial restore,
// we ignore this, and instead the gateways are set up in the "lazyInitialize" method, which
// is called when the scheduler is properly set up.
// this is a bit clumsy, but it is caused by the non-straightforward initialization of the
// ExecutionGraph and Scheduler.
if (mainThreadExecutor != null) {
setupAllSubtaskGateways();
}
coordinator.resetToCheckpoint(checkpointId, checkpointData);
}
接下来调用RecreateOnResetOperatorCoordinator.resetToCheckpoint方法 ->resetAndStart中调用SourceCoordinator.resetToCheckpoint将字节数组类型的checkpoint数据进行反序列化SourceCoordinator.deserializeCheckpoint,然后调用source.restoreEnumerator进行任务的恢复:
public void resetToCheckpoint(final long checkpointId, @Nullable final byte[] checkpointData)
throws Exception {
checkState(!started, "The coordinator can only be reset if it was not yet started");
assert enumerator == null;
// the checkpoint data is null if there was no completed checkpoint before
// in that case we don't restore here, but let a fresh SplitEnumerator be created
// when "start()" is called.
if (checkpointData == null) {
return;
}
LOG.info("Restoring SplitEnumerator of source {} from checkpoint.", operatorName);
final ClassLoader userCodeClassLoader =
context.getCoordinatorContext().getUserCodeClassloader();
try (TemporaryClassLoaderContext ignored =
TemporaryClassLoaderContext.of(userCodeClassLoader)) {
final EnumChkT enumeratorCheckpoint = deserializeCheckpoint(checkpointData);
enumerator = source.restoreEnumerator(context, enumeratorCheckpoint);
}
}
private EnumChkT deserializeCheckpoint(byte[] bytes) throws Exception {
try (ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
DataInputStream in = new DataInputViewStreamWrapper(bais)) {
final int coordinatorSerdeVersion = readAndVerifyCoordinatorSerdeVersion(in);
int enumSerializerVersion = in.readInt();
int serializedEnumChkptSize = in.readInt();
byte[] serializedEnumChkpt = readBytes(in, serializedEnumChkptSize);
if (coordinatorSerdeVersion != SourceCoordinatorSerdeUtils.VERSION_0
&& bais.available() > 0) {
throw new IOException("Unexpected trailing bytes in enumerator checkpoint data");
}
return enumCheckpointSerializer.deserialize(enumSerializerVersion, serializedEnumChkpt);
}
}
此处调用KafkaSourceEnumStateSerializer中的deserialize方法将数据反序列化出来,将结果KafkaSourceEnumState传递给StreamKafkaSource.restoreEnumerator()进行恢复。
public KafkaSourceEnumState deserialize(int version, byte[] serialized) throws IOException {
if (version == CURRENT_VERSION) {
final Set<TopicPartition> assignedPartitions = deserializeTopicPartitions(serialized);
return new KafkaSourceEnumState(assignedPartitions);
}
// Backward compatibility
if (version == VERSION_0) {
Map<Integer, Set<KafkaPartitionSplit>> currentPartitionAssignment =
SerdeUtils.deserializeSplitAssignments(
serialized, new KafkaPartitionSplitSerializer(), HashSet::new);
Set<TopicPartition> currentAssignedSplits = new HashSet<>();
currentPartitionAssignment.forEach(
(reader, splits) ->
splits.forEach(
split -> currentAssignedSplits.add(split.getTopicPartition())));
return new KafkaSourceEnumState(currentAssignedSplits);
}
throw new IOException(
String.format(
"The bytes are serialized with version %d, "
+ "while this deserializer only supports version up to %d",
version, CURRENT_VERSION));
}