Java学习-Collection
Collection(单列集合)
集合的概述
集合的由来:为了方便对多个对象进行操作,必须要储存多个对象,而想要储存多个对象,就不能是一个基本的变量,而应该是一个容器类型变量,而对象数组的长度是固定的,为了适应变化需求Java就提供了集合类。
- 数组和集合的区别:
- 长度区别: 数组长度固定,集合长度可变
- 内容不容: 数组储存的是同一种类型数,而集合可以存储不同类型的元素
- 元素的数据类型问题: 数组可以储存基本数据类型,也可以储存引用数据类型;而集合只能储存引用数据类型
- 数据结构: 数据的储存方式。
Collection: 是集合的顶层接口,它的子体系,有些是有序的,有些是无序的,有些允许重复元素,有些不允许重复元素
//仅保留此集合中包含在指定集合中的元素(可选操作)。 换句话说,从该集合中删除所有不包含在指定集合中的元素
boolean retainAll(Collection<?> c)
//假设有两个集合 A 和 B
//A 对B 取交集, 元素保存在A中 而B不变
// 返回值: 如果A集合的内容发生改变则返回true ,否则返回false
List集合
- List集合的特点:
- 1.有序的(存储顺序和取出顺序一致),通常允许元素重复
- 2.对列表中的每个元素可以进行精确的控制,通过索引可以访问元素
- List特有的遍历方式,size()和get(int index)方法
for (int i = 0; i < list2.size(); i++) {
Student student4 = list2.get(i);
System.out.println("Student====" + student4);
}
List三个子类:ArrayList: 底层数据结构是数组,查询快,增删慢、线程不安全效率高。Vector: 磁层数据结构是数组,查询快、增删慢,线程安全,效率低。LinkedList: 底层数据结构是链表,查询慢,增删快,线程不安全,效率高。
//需求: ArrayList 中去除重复元素,不创建新的集合
//我们使用插入排序的思想来实现这个需求
for (int i = 0; i < arrayList.size(); i++) {
for (int j = i+1; j < arrayList.size(); j++) {
if (arrayList.get(j).equals(arrayList.get(i))) {
arrayList.remove(j);
j--;
}
}
}
System.out.println("删除之后的元素=====" + arrayList);
//删除之后的元素=====[hello, world, java, world]
//会出现重复的元素,经查看之后,因为当你删除一个元素时,该元素后面的下标自动减一,这个时候我们
//没有判断当前所以的元素是否有重复,所以当出现连续重复的元素时,会有元素漏掉,解决方法是当我们删除
//该重复元素时,集合的元素下表发生改变时,应才在判断后续补位元素是否有重复
//删除之后的元素=====[hello, world, java]
Set集合
Set集合: 不包含重复元素的collection(存储顺序和取出顺序不一致)
哈希值
- 就是一个int类型的
数值,Java中每个对象都有一个哈希值 - Java中的所有对象,都可以调用Object类提供了hashCode方法,返回该对象自己的哈希值。
public int hashCode(): 返回对象的哈希值
对象哈希的特点:
- 同一个对象多次调用hashCode()方法的哈希值是相同的
不同的对象,它们的哈希值一般不相同,但也有可能会想通(哈希碰撞)

HashSet
HashSet集合的底层原理
- 基于
哈希表实现。 - 哈希表是一种增删改查数据,性能都比较好的数据结构
HashSet底层原理分析
哈希表
- JDK8之前: 哈希表 = 数组 + 链表
- JDK8开始:哈希表 = 数组 + 链表 +
红黑树

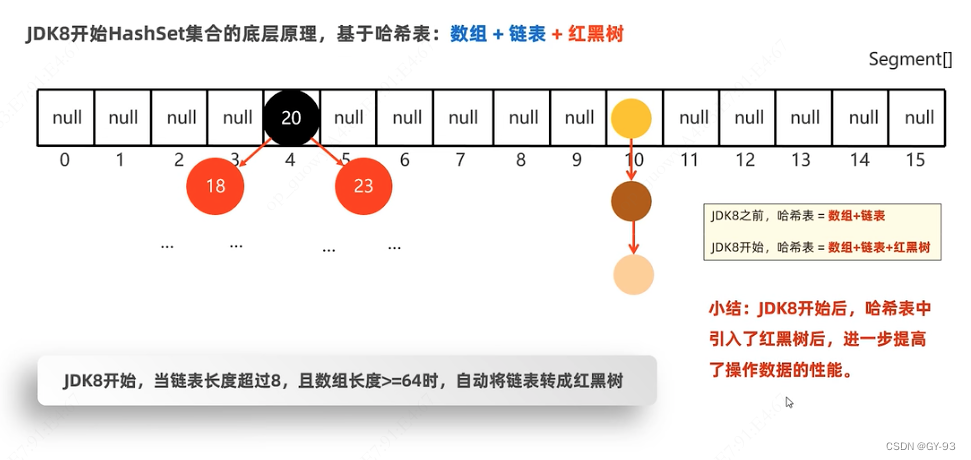
HashSet底层源码分析
HashSet: 它不保证set的迭代顺序;特别是它不保证该顺序恒久不变(可能几次的顺序都不一样)(虽然Set集合的元素无序,但是作为集合来说,这代表不了有序,可以多储存一些数据,就能看到效果)HashSet底层是有HashMap(哈希表结构)实现的,底层源码:
public boolean add(E e) {
//调用map对象的put方法
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//获取对象的hash值,然后对hash值做一些计算操作
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//HashSet 调用add方法最终调用的方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
通过查看add方法的源码,我们回到底层方法依赖hashCode()和equals()方法,首先比较hash值,如果相同,在比较地址值和equals()方法,而String方法重写了hashCode()和equals()方法,所以可以保证把内容相同的字符串去掉只留下一个
HashSet储存自定义的对象,为了保证不存在相同的对象我们重写了对象的hashCode()方法和equals()方法。 但是我们是把hashCode()方法直接返回0,这样并不是很好。

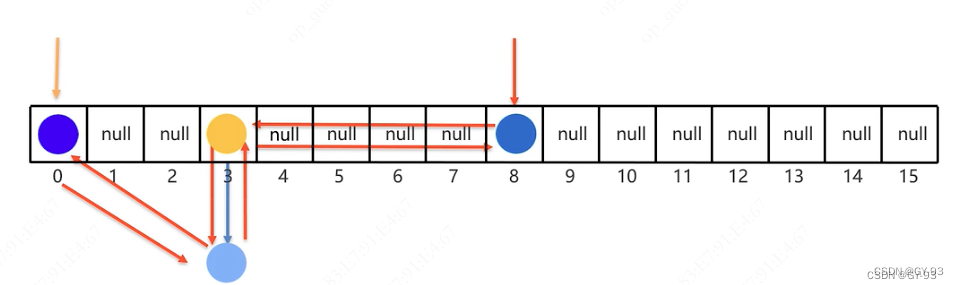
LInkedHashSet
LInkedHashSet: 底层数据结构由哈希表和链表组成;哈希表保证元素的唯一性;链表保证元素的有序(储存和取出是一致,不是排序的意思)
LInkedHashSet底层原理
- 依然是基于哈希表(
数组、链表、红黑树)实现的。 但是,它的每个元素都额外的多一个双链表的机制记录它前后元素的位置
TreeSet
TreeSet的概述
TreeSet: 能够对元素按照某种规则进行排序;排序有两种方式: 自然排序、比较器排序(Comparator)
TreeSet集合的特点: 排序和唯一,底层是二叉树结构(红黑树 ),底层由TreeMap实现
唯一性: 是根据比较的返回值是否是0来决定
排序: 1.自然排序(元素具备比较性,让元素所属类实现自然排序接口Comparable);2.比较器排序(集合具备比较性,让集合的构造方法接受一个比较器接口的子类对象Comparator)
注意:
- 对于数值类型: Integer,Double,默认按照数值本身大小进行升序排序
- 对于字符串类型: 默认按照首字符的编号升序排序
自定义排序规则
- TreeSet集合存储自定义类型的对象时,必须指定排序规则,支持如下两种方式来指定比较规则。
- 让自定义的类(如学生类)
实现Comparable接口,重写里面的compareTo方法来指定比较规则 通过调用TreeSet集合有参数构造器,可以设置Comparator对象(比较器对象,用于指定比较规则)
- 让自定义的类(如学生类)
public TreeSet(Comparator<? super E> comparator)
TreeSet的底层原理分析
底层放置元素:放置元素的时候,第一个元素是根节点,然后把放入的元素和更节点比较,如果小于,放左边,大于放右边 ;等于 不添加,取元素的时候,按照左、中、右的顺序来去元素就排序好了。
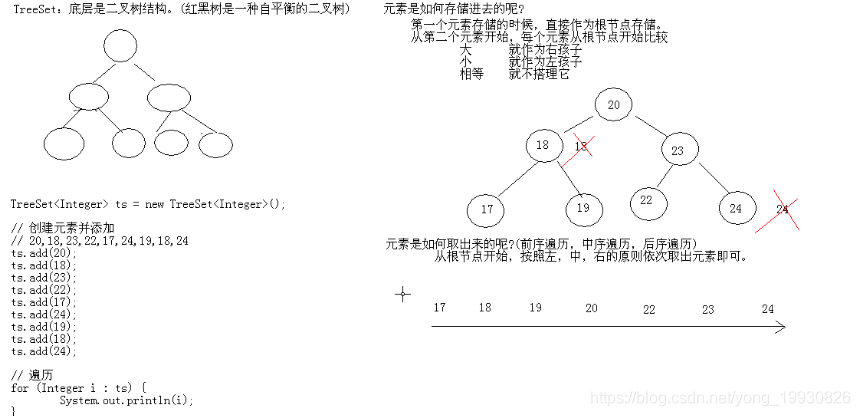
TreeSet集合两种排序方式代码示例
TreeSet储存自定的对象,需要注意
- 需要告诉集合是怎么排序的(排序规则)
- 只有实现接口java.lang.Comparable(自然排序)接口实现方法compareTo()方法,才能排序
- 判断元素的唯一的条件是什么? (例子:成员变量值相同即为同一个元素)
/*
* 如果在TreeSet集合中缓存,需要实现接口Comparable接口
*/
public class Student implements Comparable<Student> {
@Override
public int compareTo(Student o) {
// TODO Auto-generated method stub
//return 0;
/**
* 首先规定规则,按照年龄排序 ---》 如果年龄相同就比较姓名
*/
int num = this.age - o.age;
return num == 0 ? this.name.compareTo(o.name) : num;
}
}
//示例代码
Student student = new Student("lishi", 22);
Student student1 = new Student("wangwu", 23);
Student student2 = new Student("zhangsan", 18);
Student student3 = new Student("zhaoliu", 44);
Student student4 = new Student("gy", 15);
Student student5 = new Student("lishi", 22);
treeSet.add(student);
treeSet.add(student1);
treeSet.add(student2);
treeSet.add(student3);
treeSet.add(student4);
treeSet.add(student5);
for (Student tempStudent : treeSet) {
System.out.println("Student===" + tempStudent);
}
//打印结果
/**
Student===Student [name=gy, age=15]
Student===Student [name=zhangsan, age=18]
Student===Student [name=lishi, age=22]
Student===Student [name=wangwu, age=23]
Student===Student [name=zhaoliu, age=44]
*/
比较器排序:
//比较器排序
TreeSet<Student> treeSet = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
// TODO Auto-generated method stub
//return 0;
int num = o1.getAge() - o2.getAge();
return num == 0 ? o1.getName().compareTo(o2.getName()) : num;
}
});
集合的并发修改异常问题
集合的并发修改异常
- 使用迭代器遍历集合时,又同时在删除集合中的数据,程序就会出现并发修改异常的错误
- 由于增强for循环遍历集合就是迭代器遍历集合的简化写法,因此,使用增强for循环遍历集合,又同时删除集合的数据时,程序也会出现并发修改异常的错误
怎么保证遍历集合同时删除数据不出bug?
- 使用迭代器遍历集合,
但用迭代器自己的删除方法删除数据即可 - 如果使用for循环遍历时:
可以倒着遍历并删除;或则从前往后遍历,但删除元素后做i--操作
解决方法:
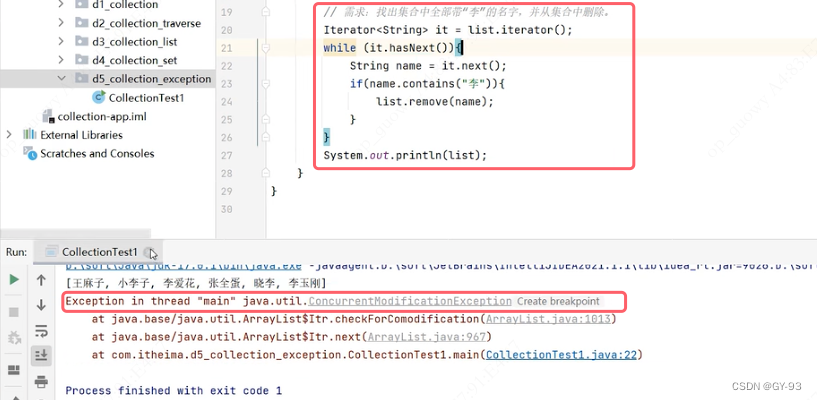

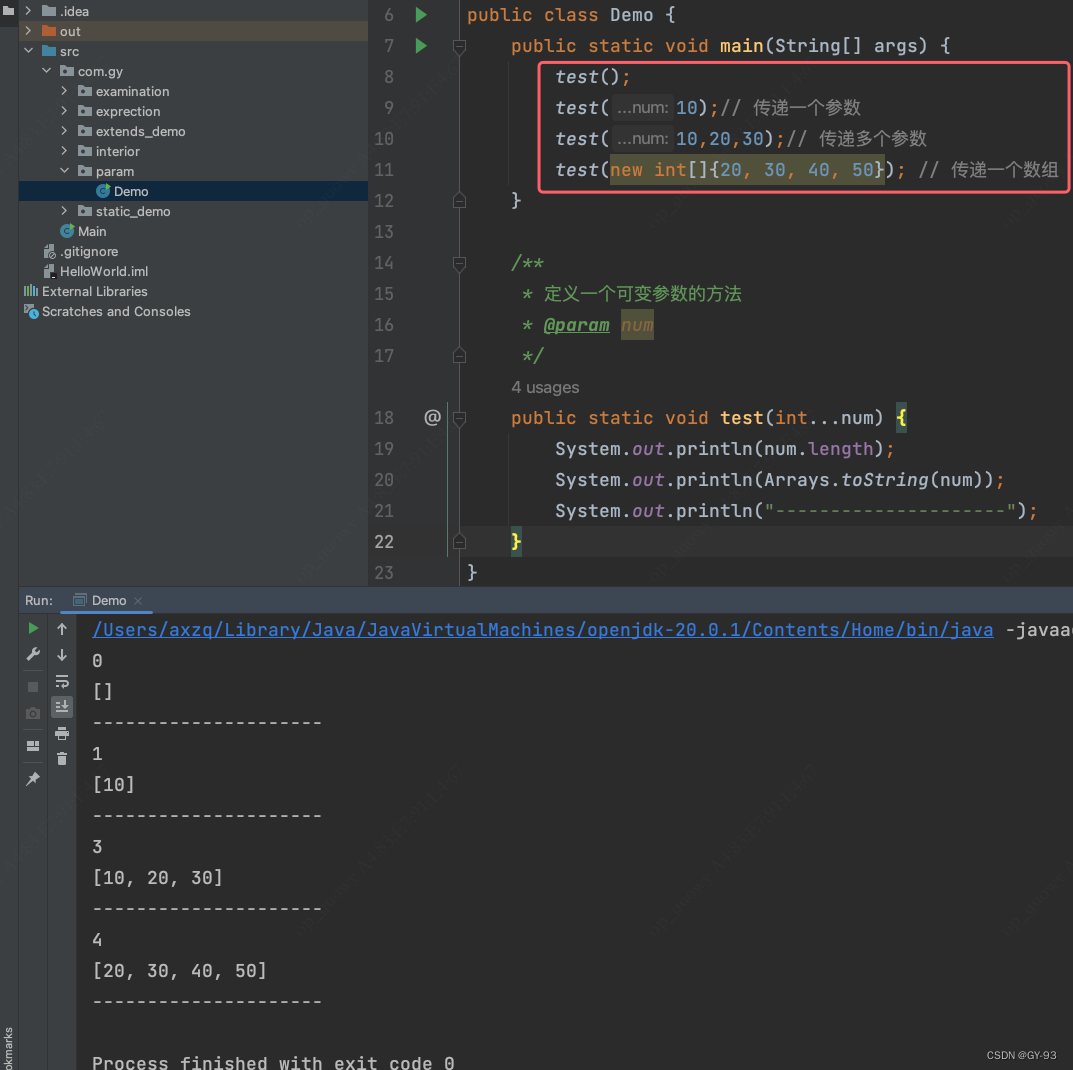
可变参数
- 就是一种特殊形参,定义在方法、构造器的形参列表里,格式是:
数据类型...参数名称;
可变参数的特点和好处
- 特点: 可以不传数据给它, 可以传一个或则同时传递多个数据给它;也可以传一个数组给它
- 好处: 常常用来灵活的接受数据
可变参数的注意事项:
可变参数在方法内部就是一个数组- 一个形参列表中可变参数只有一个
- 可变参数必须放在形参列表的最后面
Collections
Collections: 是针对集合进行操作的工具类,都是静态方法
Collection和Collections的区别?
Collection: 是单列集合的顶层接口,有子接口List和Set。
Collections: 是针对集合的操作类工具,有对集合进行排序和二分法查找的方法
常见的一些静态方法:

Map(双列)集合
Map集合的概述
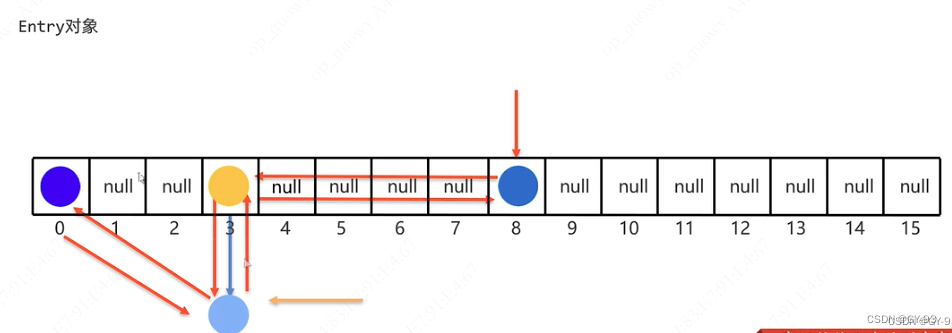
- Map集合的每个元素“key=value”,称为一个键值对/键值对象/一个Entry对象,Map集合也被叫做
键值对集合 Map集合所有的键不允许重复的,但值可以重复,键和值是一一对应的,每一个键只能找自己对应的值- 将键映射到值的对象,一个映射不能包含重复的键;每个键最多只能映射到一个值。
Map集合体系
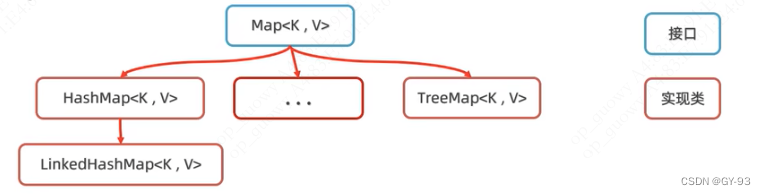
Map集合体系的特点
注意:Map系列集合的特点都是由键决定的,值只是一个附属品,值是不做要求的
- HashMap(由键决定特点):无序、不重复、无索引;(
用的最多) - LinkedHashMap(由键决定特点):
有序、不重复、无索引 - TreeMap(由键决定特点):
按照大小默认升序排序、不重复、无索引
Map集合和Collection集合的区别?
- Map集合储存元素是成对出现的,Map集合的键是唯一的,值是可重复的
- Collection集合储存元素是单独出现的,子类Set是唯一的,List是可重复的
注意 :
- Map集合的数据结构只针对键有效,跟值无关
- Collection集合的数据结构是针对元素有效
HashMap
HashMap和Hashtable的区别:
- Hashtable: 线程安全,效率低,不允许null键和null值
- HashMap:线程不安全,效率高。允许null键和null值
HashMap的底层原理
HashMap集合的底层原理
- HashMap跟HashSet的底层原理是一模一样的,都是基于哈希表实现的
实际上:原来学的Set系列集合的底层原理就是基于Map实现的,只是Set集合中的元素只要建数据,不要值数据而已。
哈希表- JDK8之前: 哈希表 = 数组 + 链表
- JDK8开始:哈希表 = 数组 + 链表 +
红黑树 - 哈希表是一种增删改查数据,性能都比较好的数据结构
- HashMap底层是基于哈希表来实现的,HashMap的键依赖hashCode方法和equals方法保证键的唯一
- 如果键存储的是自定义类型的对象,可以通过重写hashCode和equals方法,这样可以保证多个对象内容一样时,HashMap集合能认为是重复的。

HashMap的示例代码
HashMap的示例代码:
Map<String, String> map = new HashMap<String, String>();
map.put("1", "lisi");
map.put("2", "zhangsan");
map.put("3", "wangwu");
map.put("4", "zhaoliu");
//得到所有键值对的集合
Set<Entry<String, String>> con = map.entrySet();
for (Entry<String, String> entry : con) {
System.out.println("entry====" + entry);
}
LinkedHashMap
LinkedHashMap集合的原理:
- 底层数据结构依然是基于哈希表实现的,只是每个键值对元素又额外多了一个双链表的机制记录元素顺序(
保证有序) 实际上:原来学习的LInkHashSet集合的底层原理就是LinkedHashMap
TreeMap
- 特点: 不重复、无索引、可排序(按照键的大小默认升序排序,
只能对键排序) - 原理:TreeMap跟TreeSet集合的底层原理是一样的,都是基于红黑树实现的排序
TreeMap集合同样也支持两种方式来指定排序规则
-
让类实现Comparable接口,重写比较规则。
-
TreeMap集合有一个参数构造器,支持创建Comparator比较器对象,以便用来指定比较规则。
-
TreeMap的示例代码:
/*
* 需求:“aababcabcdabcde” 获取字符串中每一个字母出现的次数
*/
public class TreeMapDemo {
public static void main(String[] args) {
String string = "aababcabcdabcde";
TreeMap<String, Integer> treeMap = new TreeMap<String, Integer>();
//遍历循环数组
for (char temp : string.toCharArray()) {
//把字符作为集合的key 然后去查询集合中有没有
String keyString = String.valueOf(temp);
if (treeMap.containsKey(keyString)) {
//如果集合中包含这个key,那就取出这个值 加1
Integer tempCountInteger = treeMap.get(keyString);
tempCountInteger += 1;
treeMap.put(keyString, tempCountInteger);
} else {
treeMap.put(keyString, 1);
}
}
//现在Map集合显示的是所有字母和出现次数键值对
StringBuilder stringBuilder = new StringBuilder();
for (String string2 : treeMap.keySet()) {
Integer valueInteger = treeMap.get(string2);
stringBuilder.append(string2 + "(" + valueInteger + ")");
}
System.out.println("string===" + stringBuilder);
}
}