24年6月来自UC Berkeley的论文“RouteLLM: Learning to Route LLMs with Preference Data”。
大语言模型 (LLM) 在各种任务中选择使用哪种模型,通常涉及性能和成本之间的权衡。更强大的模型虽然有效,但成本更高,而能力较弱的模型则更具成本效益。为了解决这一困境,提出几种高效的路由器模型,这些模型在推理过程中动态选择更强和更弱的 LLM,旨在优化成本和响应质量之间的平衡。这些路由器开发提供一个训练框架,利用人类偏好数据和数据增强技术来提高性能。对公开基准的评估表明,该方法显著降低成本——在某些情况下降低 2 倍以上——而不会影响响应质量。路由器模型还展示了显著的迁移学习能力,即使在测试时更改强模型和弱模型时也能保持其性能。这凸显了这些路由器为部署 LLM 提供经济高效但高性能解决方案的潜力。
在LLM应用中,虽然将所有用户查询路由到最大、功能最强的模型可以确保高质量的结果,但成本过高。相反,将查询路由到较小的模型可以节省成本——最多可节省 50 倍以上(例如,Llama-3-70b 与 GPT-4 相比,或 Claude-3 Haiku 与 Opus 相比)——但可能会导致响应质量较低,因为较小的模型可能无法有效处理复杂查询。
LLM 路由是解决此问题的一个有希望的解决方案,即每个用户查询首先由路由器模型处理,然后再决定将查询路由到哪个 LLM。这可以将较容易的查询路由到较小的模型,将较困难的查询路由到较大的模型,从而优化模型响应的质量并最大限度地降低成本。但是,最佳 LLM 路由(定义为在给定成本目标的情况下实现最高质量或在给定质量目标的情况下最小化成本)是一个具有挑战性的问题。强大的路由器模型需要推断传入查询的意图、复杂性和领域,并了解候选模型将查询路由到最合适模型的能力。此外,路由器模型需要经济、快速并适应不断发展的模型格局,其中不断引入具有改进功能的新模型。
近期有几项研究探索了在部署大语言模型 (LLM) 时如何优化成本和性能之间的权衡。LLM-BLENDER [17] 采用集成框架,在推理时调用多个 LLM,并使用路由器模型选择最佳响应。Frugal-GPT [9] 采用 LLM 级联,依次查询 LLM,直到找到可靠的响应。这两种方法的推理成本都会随着涉及的模型数量的增加而增加。一项密切相关的研究 Hybrid-LLM [13] 在三个主要方面有所不同:它使用通过 BARTScore [29] 得出的合成偏好标签,依赖于单个基于 BERT 的路由器架构,并将评估限制在域内泛化。
考虑一组 N 个不同的 LLM 模型 M = {M1,…,MN}。每个模型 Mi : Q → A 都可以抽象为将查询映射到答案的函数。路由函数 R: Q × MN → {1,…,N} 是一个 N 路分类器,它接受查询 q ∈ Q 并选择一个模型来回答 q,答案为 a = MR(q)。路由的挑战在于在提高响应质量和降低成本之间实现最佳平衡。假设可以访问偏好数据:Dpref = {(q,li,j) | q ∈ Q,i,j ∈ N, li,j ∈ L},其中 q 是一个查询,li,j 是一个标签,表示比较 Mi,Mj 在 q 上的质量的比较结果,其取值在 L = {winMi, tie, winMj} 中。
区分奖励建模 [22] 和路由的工作非常重要。奖励建模评估 LLM 生成后的响应质量,而路由要求路由器在看到响应之前选择适当的模型。这需要深入了解问题的复杂性以及可用 LLM 的优缺点。
这项工作专注于两类模型之间的路由:(1)强模型(Mstrong),由能够产生高质量响应但成本高昂的模型组成。这类模型主要由最先进的闭源模型组成,例如 GPT-4。(2)弱模型(Mweak),由质量相对较低、成本较低的模型组成,例如 Mixtral-8x7B。这种二元路由问题在实践中相当常见,尤其是在 LLM 应用程序的开发人员努力平衡质量和成本的情况下。此外,解决这个问题为解决更一般的 N-路路由问题奠定了基础。
提出一个原则框架,用于从偏好数据中学习 Mweak 和 Mstrong 之间的二元路由函数 Rαbin : Q → {0, 1}。为了实现这一点,用两个组件来定义 Rαbin:
- 获胜预测模型,预测强模型 Mstrong 的获胜概率,即 Pθ (win Mstrong |q)。在二元分类设置中,这个概率捕获了两个模型类的获胜/失败概率。可以学习这个模型的参数 θ,并在偏好数据上具有最大似然性:
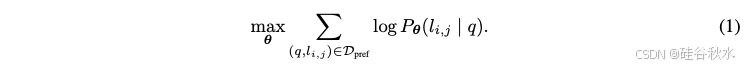
通过学习偏好数据的获胜概率,可以捕获两个模型类在各种查询上的优势和劣势。
- 成本阈值 α ∈ [0, 1],将获胜概率转换为 Mstrong 和 Mweak 之间的路由决策。给定查询 q,路由决策公式为:
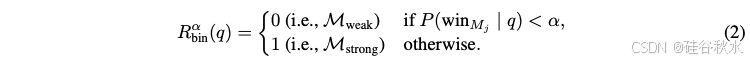
阈值 α 控制质量/成本权衡:更高的阈值施加更严格的成本约束,通过潜在地损害质量来降低费用。
最后,将路由器的响应表示为 MRαbin(q),它表示由弱模型或强模型产生的响应,具体取决于路由器的决策。
以下定义评估测度。
1 成本效率
2 质量
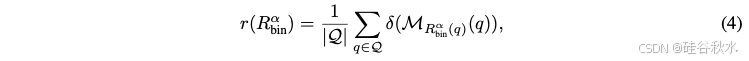
这样总成本增益为恢复的性能差异(PGR)
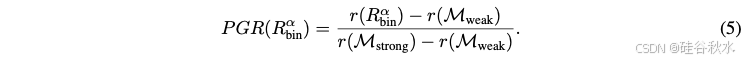
定义恢复的平均性能差异(APGR)为
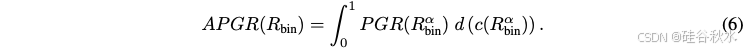
近似计算为:
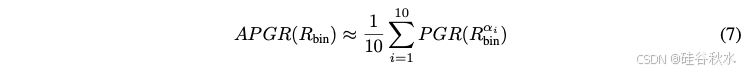
定义调用性能门限(CPT)。给定所需的路由器性能(以 x% 的 PGR 衡量),CPT(x%) 指的是获得所需 PGR 所需的对强模型的最小调用百分比。
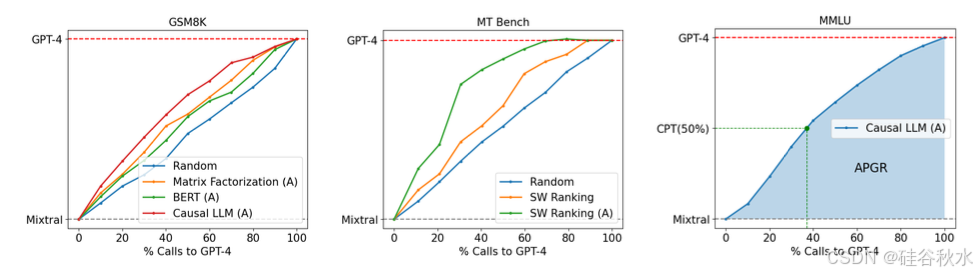
如图所示GPT-4 和 Mixtral-8x7B 之间的路由性能/成本权衡。 (左)演示几款在 OOD eval GSM8K 上表现优于随机基线的路由器。 (中)在 MT Bench 上通过数据增强(用 (A) 表示)展示路由器性能的提升。 (右)展示考虑的主要指标:调用性能阈值(CPT,用绿色表示)和恢复的平均性能增益(APGR,用蓝色阴影区域表示)。可以看见,绿色虚线表示 CPT(50%),即实现所需 50% PGR 性能所需的对 GPT-4 的调用百分比;这里,CPT (50%) ≈ 37%。
如何获取偏好数据来训练路由功能?用在线 Chatbot Arena 平台 [10] 中的 80k 场战斗。在这个平台上,用户与聊天机器人界面交互并提交他们选择的提示。提交后,他们会收到两个匿名模型的回复,并投票选出获胜模型或平局。结果数据集表示为 Darena = {(q, ai, aj , li,j ) | q ∈ Q, ai, aj ∈ A, li,j ∈ L},由用户查询、两个模型 Mi 和 Mj 的答案以及基于人类判断的成对比较标签组成。
使用原始 Chatbot Arena 数据的一个主要问题是标签稀疏性。例如,任何两个模型之间的比较标签百分比平均不到 0.1%。因此,按如下方式推导出用于训练路由器的偏好数据:首先,将 Darena 中的模型聚类为 10 个不同层级来降低标签稀疏性,使用每个模型在 Chatbot Arena 排行榜5 上的 Elo 分数,并通过动态规划最小化每个层级内的变化。选择第一和第二层的模型来表示强模型 Mstrong,选择第三层的模型来表示弱模型 Mweak。虽然主要在这些层级的战斗上进行训练,但也会利用涉及其他模型层的战斗来规范学习方法。至关重要的是,省略 Darena 中的实际模型响应,仅保留模型标识,即 e ∼ Dpref 是 e = (q, Mi, Mj , li,j )。比较标签 li,j 仍然可以洞察 LLM Mi 和 Mj 在查询 q 各种类型和复杂度级别上的相对能力。
即使将模型分为不同层级,人类偏好信号在不同的模型类别中仍然相当稀疏。这可能会阻碍泛化,尤其是对于参数繁重的模型。因此,分析以下两种数据增强方法:
黄金标签数据集:用 Dgold ={(q,a,lg)| q ∈ Q, a ∈ A, lg ∈ R} 形式的数据集来增强训练数据,其中黄金标签 lg 是针对模型答案 a(例如多项选择题答案)自动计算的。这种数据集的一个例子是 MMLU 基准 [15]。用包含大约 1500 个问题的 MMLU 验证分割,并通过简单比较 Mi 和 Mj 的响应从 lg 中得出比较标签 li,j,从而创建偏好数据集 Dgold 进行增强。
LLM 评判标注数据集:使用 LLM 评判器 [30] 获取开放式聊天域的偏好标签,因为它已证明与人类判断具有高度相关性 [14, 17]。给定一组用户查询,首先从 Mstrong 中的强模型和 Mweak 中的弱模型生成响应,然后使用 GPT-4 作为评判器生成成对比较标签。这种方法的主要挑战是从 GPT-4 大量收集响应和成对比较的成本很高。幸运的是,Nectar 数据集 [31] 提供了各种各样的查询和相应的模型响应。通过选择具有 GPT-4 响应的查询(作为 Mstrong 的代表),在其上从 Mixtral-8x7B(作为 Mweak 的代表)生成响应,从而显着降低了成本。最后,用 GPT-4 评判器获得成对比较 6 个标签。总体而言,收集了一个大约 120K 个样本的偏好数据集 Djudge,总成本约为 700 美元。
将一个样本 (q,Mi,Mj,li,j) ∼ Dpref 表示为 e = (q,Mw,Ml),其中 Mw 和 Ml 分别表示获胜和失败模型。
相似度加权 (SW) 排名采用类似于 [10] 的 Bradley-Terry (BT) 模型 [6]。给定用户查询 q,根据训练集中的每个查询 qi 与其相似度,计算权重 ωi = γ^(1+S(q,qˆ) ):
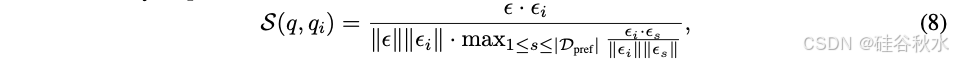
然后,学习 BT 系数 ξ(代表 10 个模型类别):
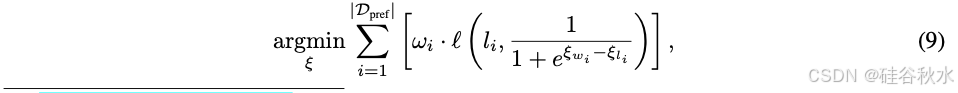
由此得出的 BT 系数能够估算出获胜的概率:P (winMw |q) = 2/(1+eξw −ξl) 。对于此路由器模型,无需进行训练,其求解在推理时进行。
受到推荐系统中矩阵分解模型 [18, 25] 的启发,用这种方法对偏好数据进行训练,以捕捉用户-项目交互的低秩结构。关键是要发现一个隐评分函数 s : M × Q → R。分数 s(Mw,q) 应该代表模型 Mw 对查询 q 回答的质量,即,如果模型 Mw 在查询 q 上优于 Ml,则 s(Mw, q) > s(Ml, q)。通过一个 BT 关系 [6] 对获胜概率进行建模,强化这种关系:
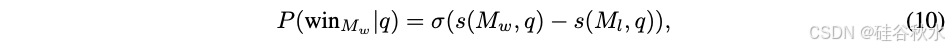
将评分函数 s 建模为模型和查询的双线性函数,并将模型标识 M 嵌入到 dm 维向量 vm,将查询嵌入到 dq 维向量 vq:
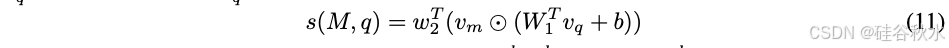
这种方法本质上是在集合 Q × M 上学习得分矩阵的矩阵分解。在 8GB GPU 上对模型进行约 10 个 epoch 的训练,使用批量大小 64 和 Adam 优化器,学习率为 3 × 10^−4,权重衰减为 1 × 10^−5。
用一种标准文本分类方法,与以前的方法相比,该方法具有更多的参数。用基于 BERT 的架构 [12],为用户查询提供上下文嵌入,并将获胜概率定义为:
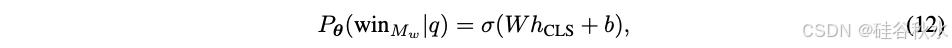
对 Dpref 执行全参数微调。在 2xL4 24GB GPU 上训练模型约 2000 步,批处理大小为 16,最大序列长度为 512,学习率为 1 × 10^−5,权重衰减为 0.01。
最终通过使用 Llama 3 8B[2] 参数化路由器来扩展路由器的容量。用指令跟随范式 [28],即提供包含用户查询的指令提示作为输入并以下一个token预测的方式输出获胜概率 - 而不是使用单独的分类头。值得注意的是,将比较标签作为附加token附加到词汇表中,并计算标签类别 L 上 softmax 形式的获胜概率。在 8 x A100 80GB GPU 上对模型进行训练,训练步骤为 ∼ 2000 步,使用批量大小为 8、最大序列长度为 2048 以及学习率为 1 × 10^-6 。
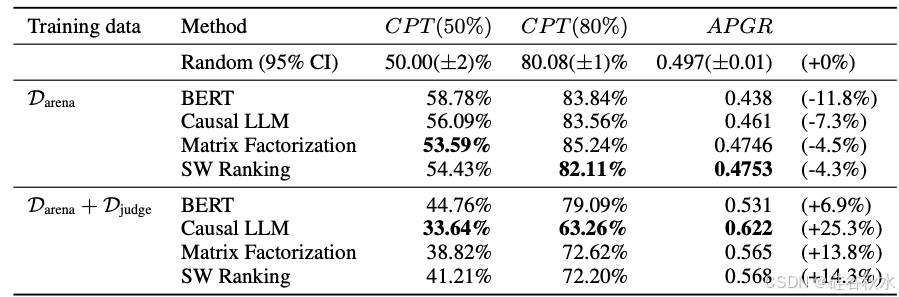
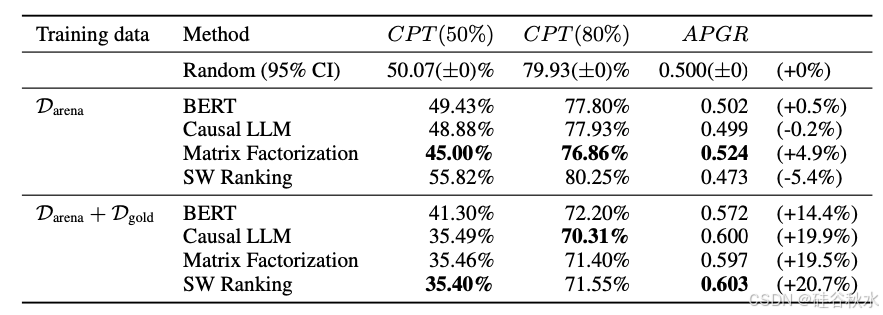
如下表是在 MT Bench 的结果:
下表是5-样本 MMLU 的结果:
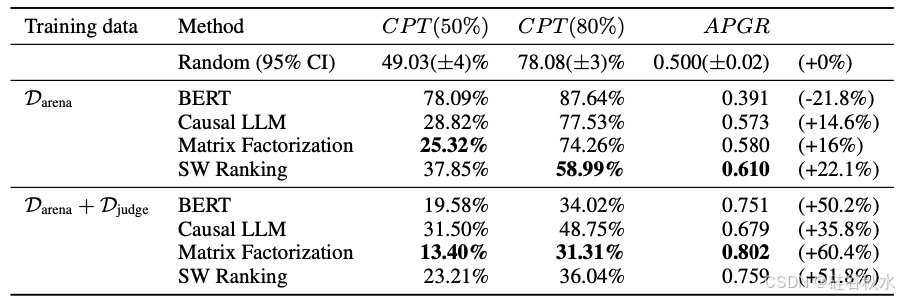
下表是5-样本 GSM8K 的结果: