27年7月来自Rutgers大学的论文“AutoFlow: Automated Workflow Generation for Large Language Model Agents”。
大语言模型 (LLM) 的最新进展表明,在理解复杂自然语言方面取得了重大进展。LLM 的一个重要应用是基于 LLM 的 AI 智体,它利用 LLM 以及外部工具的能力来解决复杂任务。为了确保 LLM 智体遵循有效可靠的程序来解决给定的任务,通常使用人工设计的工作流来指导智体的工作机制。然而,手动设计工作流需要大量的努力和领域知识,这使得大规模开发和部署代理变得困难。
AutoFlow,一个旨在自动生成智体工作流以解决复杂任务的框架。AutoFlow 以自然语言程序作为智体工作流的格式,并采用工作流优化程序来迭代优化工作流质量。此外,这项工作提供了两种工作流生成方法:基于微调和基于上下文的方法,使 AutoFlow 框架适用于开源和闭源的 LLM。用自然语言自动生成和解释工作流程是解决复杂任务的一个有前途的范例,尤其是在 LLM 快速发展的情况下。这项工作的源代码可在 https://github.com/agiresearch/AutoFlow 上找到。
大语言模型 (LLM) 在理解和处理复杂的自然语言方面取得了重大进展。这些发展开辟了广泛的应用领域,其中基于 LLM 的 AI 智体部署尤为突出。这些智体利用 LLM 的功能以及外部工具来处理复杂的任务,从数据分析 [7]、软件开发 [23, 35]、科学研究 [2]、旅行计划 [46] 到各个领域的许多其他决策过程。
确保基于 LLM AI 智体有效可靠地运行的关键方面之一是指导其任务解决程序的工作流设计。例如,基于 LLM 的假新闻检测智体可以在信息和通信专家设计的以下工作流程下执行 [24]:1) 检查 URL,2) 检查语言,3) 常识评估,4) 立场评估,5) 总结调查结果,6) 分类。智体逐步执行工作流,每个步骤都可能调用 LLM 或外部工具来收集有用的信息,以便进行最终的汇总和分类。
传统上,这些工作流是手工制作的,需要付出大量努力和深厚的领域知识。这种手动过程对 AI 智体的大规模开发和部署构成了重大障碍,因为它既耗时又耗资源。
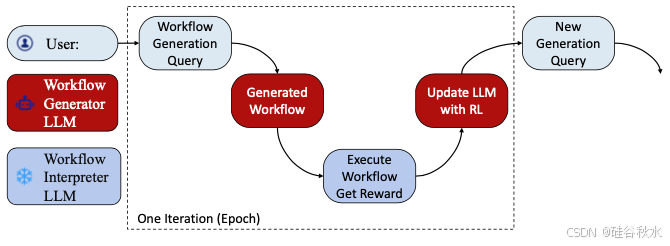
从技术上讲,AutoFlow 引入了两种工作流生成方法:基于微调的方法和基于上下文的方法。基于微调的方法通过调整 LLM 的参数来为特定任务和领域定制工作流生成过程。相比之下,基于上下文的方法利用上下文信息来指导生成过程,而无需进行大量微调,使其适用于开源和闭源 LLM。更具体地说,如图所示,用户将提供工作流生成查询来描述任务类型。基于查询,生成器 LLM 生成工作流,冻结解释器 LLM 在数据集上执行生成的工作流,以评估性能作为奖励。然后,AutoFlow 使用强化学习 (RL) 用奖励更新生成器 LLM。这个过程可以看作是一次训练迭代,生成器 LLM 期望在几次迭代后学习如何生成有效且最佳的工作流。
首先,代码表示和执行 (CoRE) 语言定义了四个组件,将工作流组织为自然语言指令。
• 步骤名称用于唯一标识工作流的每个步骤。
• 步骤类型定义每个步骤的指令类型。有三种不同类型的步骤:
- 流程:流程步在执行当前步后过渡到下一个指定步。
- 决策:与条件语句(例如“if-else”)类似,决策步用于根据评估条件分支程序流。
- 终端:终端步代表程序的结束。
• 步骤指令是要在步骤中执行的自然语言指令。
• 步骤连接指向下一步,从而建立程序执行流程。
为了处理和执行CoRE语言的工作流,系统使用LLM作为解释器。LLM解释器一步一步地执行指令。具体来说,在CoRE系统中,一个步骤的执行可以分为四个过程。
❶首先,LLM决定执行当前步骤可能需要内存中的哪些信息,并从内存中检索相关信息。
❷在获得相关信息后,系统将这些信息与该步骤的指令整合成一个结构化的提示,LLM对其进行处理以生成响应。
❸为了扩展LLM的能力,系统可以使用外部工具来分析每个步骤的初始响应。根据对当前步骤的初始响应,LLM确定是否需要外部工具。如果确认使用工具,LLM将决定工具名称和工具参数,然后执行外部工具,最后将结果合并到内存中。
❹在执行当前步骤后,LLM将根据当前步骤的输出决定下一步要执行哪个步骤。
受自动机器学习(AutoML)[13]的启发,希望根据给定的任务和训练数据自动学习最佳的工作流。考虑到 CoRE 语言中的指令是用自然语言编写的,而 LLM 具有很强的自然语言理解能力,也使用 LLM 作为工作流生成器。将学习生成工作流的 LLM 表示为工作流生成器 LLM,将解释并执行工作流的 LLM 称为工作流解释器 LLM。这样,用户只需要提供任务的高级描述和相应的数据集,生成器 LLM 就可以用 CoRE 语言生成最优的工作流,供解释器 LLM 在给定的任务上执行。这个过程希望最大限度地减少人力投入,并自动追求 LLM 的最优工作流,而不管用户对工作流设计的知识水平如何。
如图所示AutoFlow生成工作流的一个例子:(a-)微调方法,(b-)ICL上下文学习方法
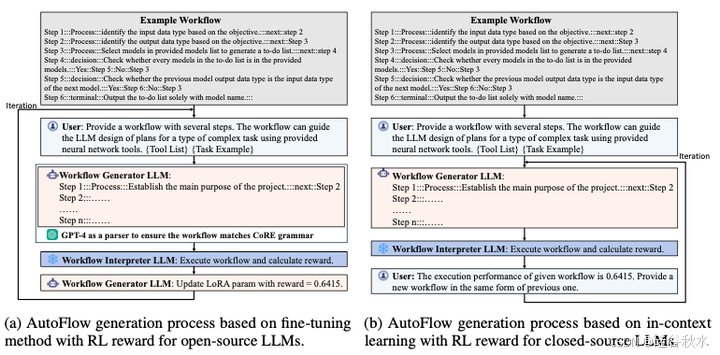
微调方法
首先,工作流生成器 LLM 接收来自用户的少样本工作流和任务描述作为输入查询。虽然 CoRE 语言对语法的要求很低,指令都是用自然语言编写的,LLM 可以很好地学习和生成,但示例工作流可以帮助工作流生成器 LLM 更好地理解 CoRE 语言的语法。任务的自然语言描述是为了帮助生成器 LLM 了解要生成的工作流应用场景。以 OpenAGI 基准 [7] 中的文本和图像处理任务为例,任务描述可以是“提供一个包含多个步骤的工作流。该工作流可以指导 LLM 使用提供的工具为与文本和图像处理相关的一类复杂任务设计规划”。
其次,下一步是根据输入查询生成可执行工作流。对于 GPT-4 等闭源 LLM,模型可以直接根据少样本示例生成语法有效的工作流。然而,即使提供了少样本示例工作流,开源 LLM(例如 Mixtral-8x7B)也无法始终如一地生成语法有效的工作流。为了解决这个问题,遵循研究 [7, 52] 中的后处理策略,并使用 GPT-4 作为解析器将输出工作流修改为语法有效的工作流。
第三,生成的工作流将由解释器 LLM 执行,获得其在验证数据集上的表现。然后,根据工作流在验证数据集上的表现更新生成器 LLM。具体来说,使用强化学习 (RL) 来更新生成器 LLM 的 LoRA 适配器参数,以验证数据集上所有数据实例的平均指标作为奖励。
这三个步骤一起构成了微调过程的一次迭代。当满足终止条件时,即当两次连续迭代之间的奖励差异小于阈值时,微调过程将终止,并生成最终的工作流。经过迭代优化过程,工作流生成器LLM根据执行反馈为任务生成最优工作流。
上下文学习方法
对于GPT-4等闭源LLM,用上下文学习来避免对参数进行微调。AutoFlow框架也需要一个示例工作流和任务描述,并将它们作为输入查询提供给工作流生成器LLM。在GPT-4生成工作流后,不使用解析器来修改流程,因为GPT-4可以很好地遵循示例工作流所演示的CoRE语法。然后,解释器LLM执行工作流以评估其在验证数据集上的表现作为奖励,这与微调方法的过程相同。不同之处在于,在下一步中,AutoFlow框架直接将奖励值包含在查询中,并提示生成器LLM根据先前生成的工作流性能生成新的工作流,例如“先前工作流的执行性能为0.6415。提供一个可以获得更好性能的新工作流”。
实验中,GPT-4 等闭源 LLM 可以很好地利用提示中的奖励值来细化工作流程,并最终通过上下文学习方法获得最佳工作流程。
实验中,GPT-4 [32](闭源)是 OpenAI 的生成式预训练Transformer。用 GPT-4-1106-preview 版本。Mixtral-8x7B [14](开源)是一个预训练的生成式稀疏混合专家模型,具有 467 亿个参数。将这两种类型的LLM应用于工作流生成器LLM和解释器LLM。因此,总共有四种组合。
框架和所有基线均由开源库 PyTorch 实现。遵循 OpenAGI 平台 [7] 的实现设置,用于零样本和小样本学习。用 DSPy 框架 [19, 20] 将 CoT 策略应用于 OpenAGI 平台。还在 OpenAGI 平台上尝试 Program-of-Thought [5] 和 ReAct [51] 策略。但是,ReAct 策略需要文本观测,这不适合 OpenAGI 任务,因为一些观测是图像格式,而 Program-of-Thought 无法生成可执行代码。因此,没有将它们作为基线。
对于 AutoFlow 框架的超参设置,将工作流生成器 LLM 的迭代次数设置为 30。对于开源 LLM Mixtral 作为生成器 LLM,用 REINFORCE [41] 作为生成器 LLM 的核心强化学习 (RL) 算法,训练数据集上的平均分数作为奖励。用 Adam 作为优化器,在强化学习中学习率为 0.001。此外,将秩为 8 的低秩自适应 (LoRA) [11] 应用于 Mixtral,以实现高效微调。
下表是在 OpenAGI 上用开源 LLM Mixtral 作为所有任务和学习模式的 LLM 解释器时的性能。

下表是在 OpenAGI 上使用闭源 LLM GPT-4 作为所有任务和学习模式的 LLM 解释器时的性能。
