【EdgeAI实战】(1)STM32 边缘 AI 生态系统
【EdgeAI实战】(2)STM32 AI 扩展包的安装与使用
【EdgeAI实战】(2)STM32 AI 扩展包的安装与使用
STM32Cube.AI 套件将基于各种人工智能开发框架训练出来的算法模型,统一转换为c语言支持的源码模型,然后将 c模型部署到 STM32 的硬件产品,实现将人工智能模型直接部署在前端或边缘端设备。
本文介绍 STM32Cube.AI 套件的下载、安装和使用。
1. STM32Cube.AI 简介
1.1 STM32Cube.AI 简介
将人工智能模型/神经网络模型部署到边缘设备,可以减少延迟、节约能源、提高云利用率,并通过大限度地减少互联网上的数据交换来保护隐私。
STM32Cube.AI 是ST公司的打造的 STM32Cube 生态体系的扩展包 X-CUBE-AI,用于帮助开发者实现人工智能开发。具体地说,STM32Cube.AI 将基于各种人工智能开发框架训练出来的算法模型,统一转换为c语言支持的源码模型,然后将 c模型部署到 STM32 的硬件产品,实现将人工智能模型直接部署在前端或边缘端设备。
ST Edge AI套件支持各种意法半导体产品:STM32微控制器和微处理器、神经ART加速器、恒星微控制器和智能传感器。
X-CUBE-AI 是 ST Edge AI Suite的一部分,该套件是一个集成的软件工具集合,旨在促进嵌入式AI应用程序的开发和部署。这个全面的套件支持机器学习算法和神经网络模型的优化和部署,从数据收集到硬件上的最终部署,简化了跨学科专业人员的工作流程。
X-CUBE-AI扩展包扩展了STM32CubeMX,提供了一个自动神经网络库和经典的机器学习库生成器,在计算和内存(RAM和闪存)方面进行了优化,可以将最常用的人工智能框架(如Keras、TensorFlow Lite、scikit-learn和以ONNX格式导出的任何模型)中的预训练人工智能算法转换为自动集成在最终用户项目中的库。该项目会自动设置,准备在STM32微控制器或神经ART加速器上编译和执行。
X-CUBE-AI还扩展了STM32CubeMX,为项目创建添加了特定的MCU和板过滤,以选择符合用户AI模型特定标准要求(如RAM或闪存大小)的正确设备。
主要功能:
- 从预训练神经网络和经典机器学习(ML)模型生成STM32优化库
- 支持意法半导体神经ART加速器神经处理单元(NPU),用于硬件中的AI/ML模型加速
- 原生支持各种深度学习框架,如Keras和TensorFlow Lite,并支持可导出为ONNX标准格式的所有框架,如PyTorch、MATLAB等
- 通过ONNX支持各种内置的sci-kit学习模型,如随机森林、支持向量机(SVM)和 K-means
- 支持32位浮点和8位量化神经网络格式(TensorFlow Lite和面向 ONNX Tensor的QDQ)
- 支持QEras和Larq的深度量化神经网络(低至1位)
- 可重定位选项,通过创建与应用程序代码分离的模型二进制代码,在产品生命周期内实现独立模型更新
- 通过在外部闪存中存储权重和在外部RAM中存储激活缓冲区,可以使用更大的网络
- 通过STM32Cube集成,可在不同STM32微控制器系列之间轻松便携
- 使用TensorFlow Lite神经网络,使用STM32Cube生成代码。用于微控制器运行时的AI运行时或TensorFlow Lite
开发过程:
STM32Cube.AI 以插件形式支持ST相关开发平台如cubeIDE、cubeMX、keil等,整体开发过程分为三个步骤:
- (1)收集和整理数据,
- (2)训练及验证模型,
- (3)模型生成和部署。
生成项目:
- 在STM32 MCU或NPU上运行的系统性能项目,允许准确测量神经网络推理CPU或NPU的负载和内存使用情况
- 验证项目,在台式PC和基于STM32 Arm®Cortex®-M的MCU或具有neural ART Accelerator嵌入式环境的STM32 MCU上,对随机或用户测试数据刺激的神经网络返回的结果进行增量验证
- 应用程序和混合精度量化模板项目允许构建包括多网络支持的8位量化网络和二值化神经网络的应用程序,从而减少了所需的闪存大小,提高了推理时间,而不会显著降低网络精度。
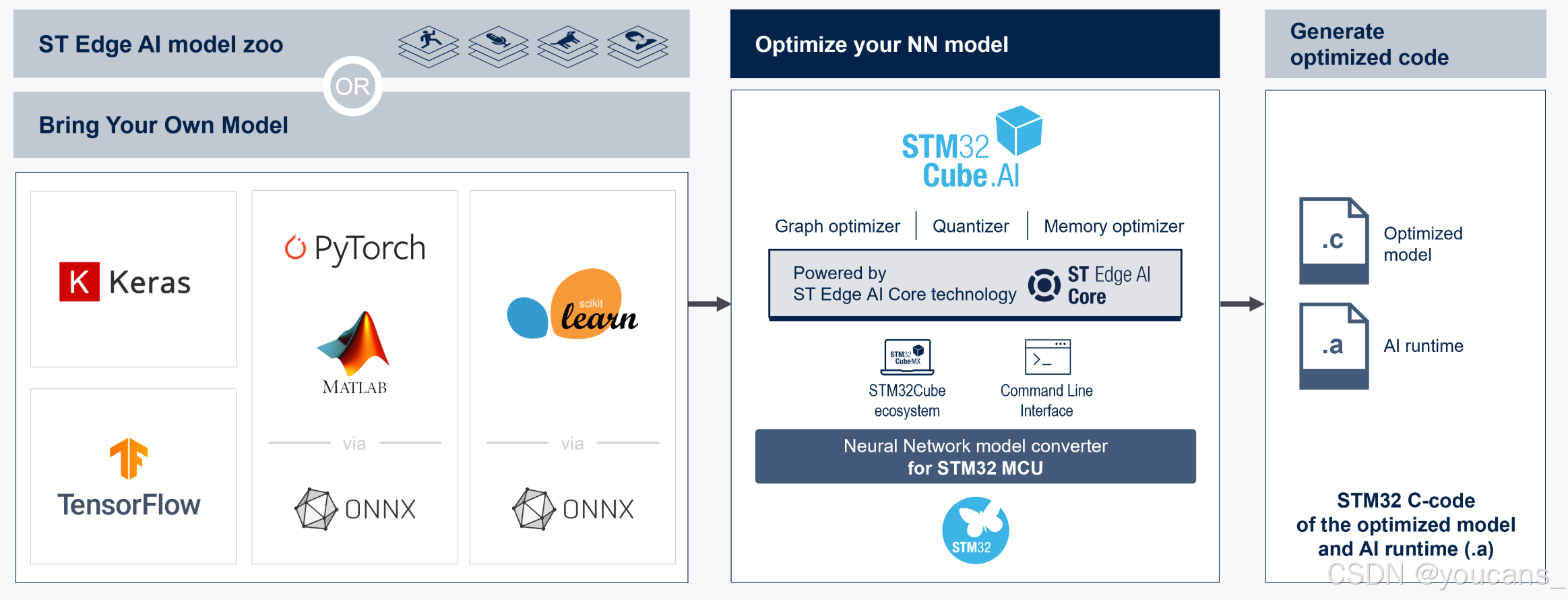
1.2 X-CUBE-AI 内核引擎
X-CUBE-AI 的内核引擎如下图所示。
- 提供一个自动且先进的 NN 映射工具,利用有限并受约束的硬件资源为嵌入式系统的预训练神经网络(DL模型)生成并部署优化且稳定的 C模型。
- 生成 STM32NN 库(专用和通用部分),可以直接集成到 IDE项目或基于 makefile 的构建系统。
- 可以导出定义明确且特定的推理客户端 API,用于开发客户端基于 AI 的应用程序。
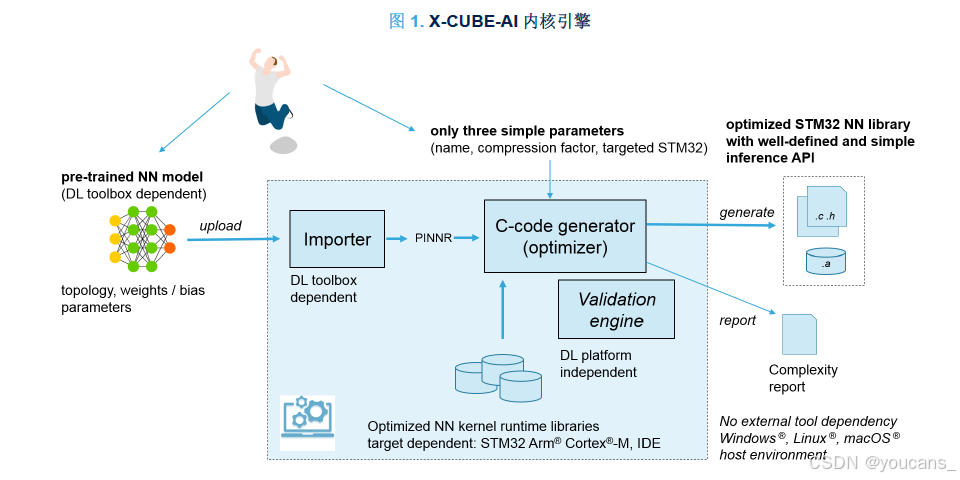
配备一个简单的配置接口。使用预训练的 DL 模型文件,只需要几个参数:
- name,表示生成的 C模型的名称,默认为 “network”;
- 压缩系数,表示用于减小权重/偏差参数大小的压缩系数;
- STM32 系列,选择优化的 NN 内核运行时的库。
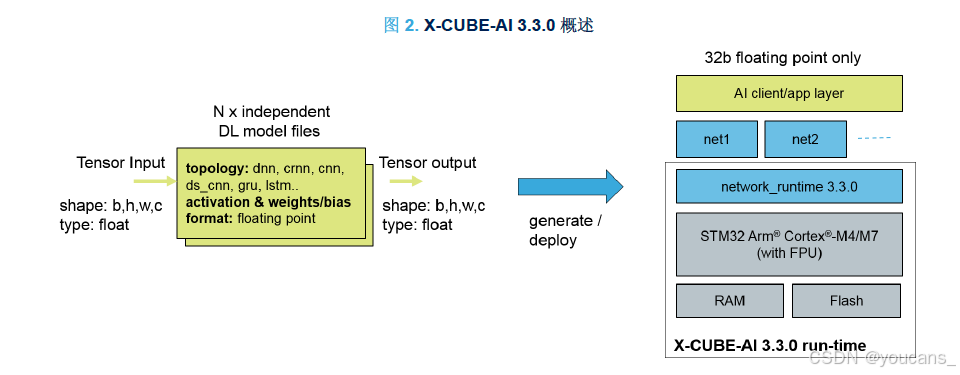
STM32Cube 是 ST公司推出的用于 STM32 微处理器的软件配置工具,可以利用图形向导为 STM32 创建完整的 IDE 项目,包括生成用于设备和平台设置的 C 初始化代码。
X-CUBE-AI 扩展包可以视为添加 IP 或中间件 SW 组件。基于 X-CUBE-AI 内核提供了以下功能:
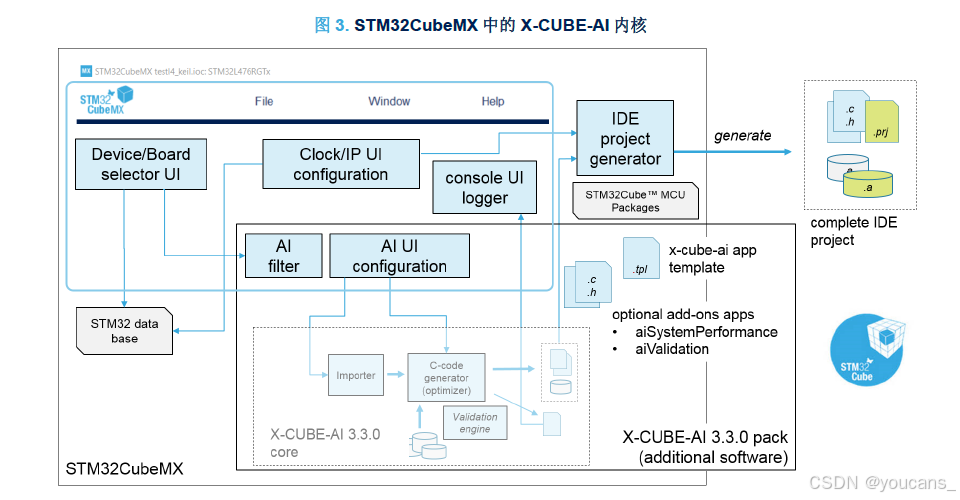
- 扩展 MCU 过滤器选择,利用可选特定 AI 过滤器移除内存不足的设备,例如滤除没有 Arm Cortex-M4 或 Cortex-M7 内核的 STM32 设备;
- 提供完整的 AI 配置向导,可以上传多个深度学习模型,包括在 PC 和目标板上对生成的 C 代码进行验证过程。
- 扩展 IDE 项目生成器,辅助生成优化的 STM32NN库,并将其集成到选定的 STM32 Arm Cortex-M 内核和 IDE。
- 可选插件式应用程序,可生成完整的即用型 AI 测试应用程序项目,包括生成的 NN 库。
2. 支持的深度学习框架和算子
STM32Cube.AI 支持各种深度学习框架的训练模型,如 Keras、TensorFlow Lite,并支持可导出为 ONNX 标准格式的所有框架,如 PyTorch、Microsoft Cognitive Toolkit、MATLAB 等。
通过 cube.MX 可视化配置界面,导入基于深度学习框架的训练模型,来配置及生成 c 模型,并部署在STM32芯片上。
- Keras: //keras.io/
- TensorFlow Lite: www.tensorflow.org/lite/
- ONNX: //onnx.ai/
对于每个工具箱,根据网络C API 的表达能力以及特定工具箱的解析器,仅支持所有可能层和层参数的一个子集。
以下章节详细介绍每个工具箱的当前版本工具在所支持的各层(使用工具箱命名惯例)以及每层支持的属性(参数)方面支持的配置。同时列出多个层支持的相同功能。
2.1 支持的 Keras 运算符
本文档列出了可以导入和转换的图层(或运算符)。支持的运营商允许解决针对移动或物联网资源受限的运行时环境的大量经典拓扑:SqueezeNet、MobileNet V1或V2、Inception、SSD MobileNet V1等,。。
本文档的目的是列出运算符及其相关约束或限制,有关给定层的详细信息,请参阅原始文档。
Keras通过Tensorflow后端支持通道最后维度排序。支持Keras.io 2.0至2.5.1版本,而Keras 1.x中定义的网络则不受官方支持。最多支持TF Keras 2.7.0。
下表列出了在满足约束或限制的情况下可以导入的运算符。下表列出了30个自定义运算符。
- 支持可选的融合激活(或非线性):gelu、线性、relu、relun1_to_1、relu_0_to1、leaky_relu、relu6、elu、selu、sigmoid、hard_sigmoid、hard_swish、指数、tanh、softmax、softplus、softsign、abs、acos、acosh、asin、asinh、atan、atanh、ceil、clip、cos、cosh、erf、flexrf、exp、floor、identity、log、logistic、neg、logical_not、prelu、probit、reciprocal、relu_generic、relu_threshold、round、sign。sin、sinh、softmax_zero、sqrt、swish、tan
- 支持可选的融合整数激活(或非线性):prelu、relu、clip、lut、swish、identity、relu6
- 整数运算仅支持使用ST Edge AI Core训练后量化脚本量化的Keras模型。请求额外的张量格式配置文件(json文件格式)。
- 如果整数中不支持运算符,则使用浮点版本。转换器由代码生成器自动添加。
(略)
2.2 支持的 Tensorflow Lite 运算符
本文档列出了可以导入和转换的图层(或运算符)。支持的运营商允许解决针对移动或物联网资源受限的运行时环境的大量经典拓扑:SqueezeNet、MobileNet V1或V2、Inception、SSD MobileNet V1等,。。
本文档的目的是列出运算符及其相关约束或限制,有关给定层的详细信息,请参阅原始文档。
Tensorflow Lite是用于在移动平台上部署神经网络模型的格式。STM.ai导入并转换基于flatbuffer技术的.tflite文件。官方的“schema.fbs”定义(标签v2.5.0)用于导入模型。处理支持运算符列表中的许多运算符,包括量化感知训练或/和训练后量化过程生成的量化模型和/或运算符。
下表列出了在满足约束或限制的情况下可以导入的运算符。
- 支持可选的融合激活(或非线性):gelu、线性、relu、relun1_to_1、relu_0_to1、leaky_relu、relu6、elu、selu、sigmoid、hard_sigmoid、hard_swish、指数、tanh、softmax、softplus、softsign、abs、acos、acosh、asin、asinh、atan、atanh、ceil、clip、cos、cosh、erf、flexrf、exp、floor、identity、log、logistic、neg、logical_not、prelu、probit、reciprocal、relu_generic、relu_threshold、round、sign。sin、sinh、softmax_zero、sqrt、swish、tan
- 支持可选的融合整数激活(或非线性):prelu、relu、clip、lut、swish、identity、relu6
- 如果整数中不支持运算符,则使用浮点版本。转换器由代码生成器自动添加。
(略)
2.3 支持的 ONNX 运算符
针对移动或物联网资源受限的运行时环境:SqueezeNet、MobileNet V1或V2、Inception、SSD MobileNet V1等,。。
本文档的目的是列出运算符及其相关约束或限制,有关给定层的详细信息,请参阅原始文档。
ONNX是一种开放格式,用于表示机器学习模型。支持ONNX 1.15的操作集7、8、9、10到15的部分运算符子集。
注意:生成的C代码总是最后一个通道,这取决于应用程序是否正确地重新排列元素顺序。
此文件是自动生成的。
下表列出了在满足约束或限制的情况下可以导入的运算符。
- 支持可选的融合激活(或非线性):gelu、线性、relu、relun1_to_1、relu_0_to1、leaky_relu、relu6、elu、selu、sigmoid、hard_sigmoid、hard_swish、指数、tanh、softmax、softplus、softsign、abs、acos、acosh、asin、asinh、atan、atanh、ceil、clip、cos、cosh、erf、flexrf、exp、floor、identity、log、logistic、neg、logical_not、prelu、probit、reciprocal、relu_generic、relu_threshold、round、sign。sin、sinh、softmax_zero、sqrt、swish、tan
(略)
2.4 支持的 ST Neural ART NPU 运算符
本文档描述了在neural ART加速器上高效部署神经网络模型所需的模型格式和相关量化方案。它列出了不同运算符的映射。
量化模型格式
ST 神经ART编译器支持两种量化模型格式。两者都基于相同的量化方案:每信道8b/8b,ss/sa。
- 由训练后或训练感知过程生成的量化TensorFlow lite模型。校准由TensorFlow Lite框架执行,主要是通过导出TensorFlow文件的“TF Lite转换器”实用程序。
- 基于面向张量(QDQ;量化和去量化)格式的量化ONNX模型。在原始运算符之间插入 DeQuantizeLinear和QuantizeLiner运算符(浮点数),以模拟量化和解量化过程。它可以通过ONNX量化器运行时服务生成。
请参阅量化模型一章,了解使用Tensorflow Lite转换器或onnxruntime的量化过程的详细说明。
如有必要,模型中的某些层可以保持浮动状态,但它们将在CPU上执行,而不是在Neural ART NPU上执行。
推理模型约束
ST神经ART处理器单元是一个可重新配置的纯推理引擎,能够在硬件上加速量化推理模型,不支持训练模式。
- 输入和输出张量必须是静态的
- 可变长度批次维度被视为等于1
- 不支持输出未连接的操作单元
- 不支持混合数据操作(即混合运算符),应量化激活和权重
- 权重/激活张量的数据类型必须为:
- int8(比例/偏移格式)ss/sa方案(见量化模型-每个通道)
- 如果请求float32操作,它将映射到软件操作上
自定义层支持-后处理
目前,对象检测模型不支持“TFLite_Detection_PostProcess”运算符等自定义层。如果可能的话,在量化模型之前,最好将其删除,只保留骨干和头部。这包括“NMS”(非最大抑制)算法(通常基于浮点运算),它将由在HOST MCU处理器上运行的“外部”库支持。
TFlite到Neural ART操作映射
下表列出了TensorFlow Lite(TFlite)和Neural ART™堆栈之间的操作映射。请注意,只有量化操作(int8比例/偏移格式)可以直接映射到Neural ART™处理单元上。如果操作员未映射到硬件上,则会发出回退实现(int8或float32版本),并使用HOST(Cortex-m55)子系统来执行回退实现。
(略)
3. Cube.AI 扩展包的下载与安装
3.1 Cube.AI 扩展包的下载
X-CUBE-AI 是 STM32Cube.AI生态系统的STM32Cube扩展包部分,能够自动转换预训练人工智能算法(包括神经网络和经典机器学习模型),并将生成的优化库集成到用用户项目中,以此来扩展STM32CubeMX功能。
关于 STM32Cube.AI 的资料和文档可以从 ST 官网上查看和下载:STM32 x-cube-ai 扩展包
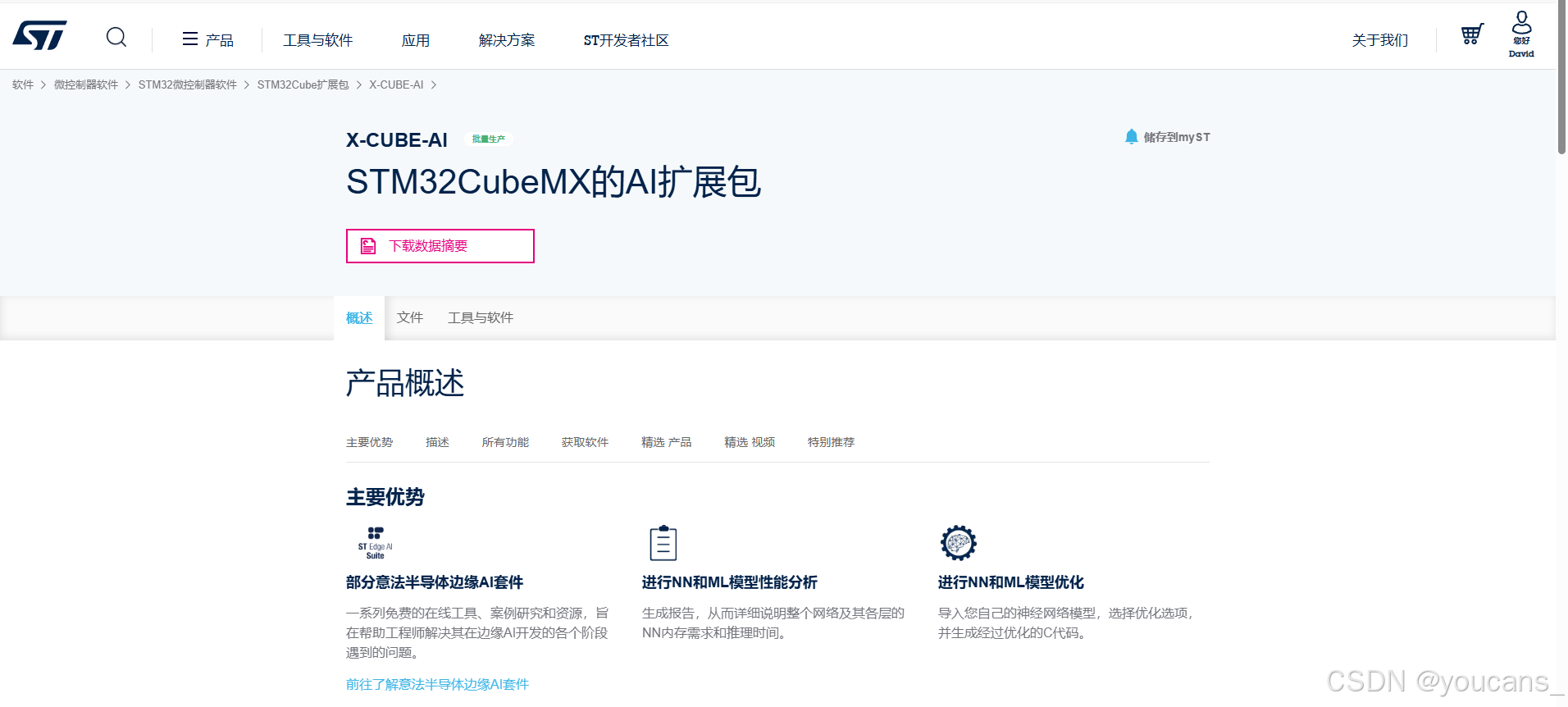
下载地址:
STM32 Cube.AI 扩展包的下载地址为:STM32 x-cube-ai
根据使用的操作系统,选择对应的安装包进行下载,即可安装使用。

3.2 Cube.AI 扩展包的安装
-
X-CUBE-AI 是 STM32Cube 的扩展包,需要先安装 STM32CubeMX 开发工具(5.0以上版本)。
STM32CubeMX 是 ST公司推出的软件开发工具,官方下载地址:https://www.st.com.cn/content/st_com/zh/stm32cubemx.html,安装步骤详见本系列 【动手学电机驱动】STM32-FOC(1)STM32 电机控制的软件开发环境。 -
启动 STM32CubeMX,安装 X-CUBE-AI 扩展包:
(1)从菜单中选择 [帮助] > [管理嵌入式软件包],或者 Alt-U 快捷键。
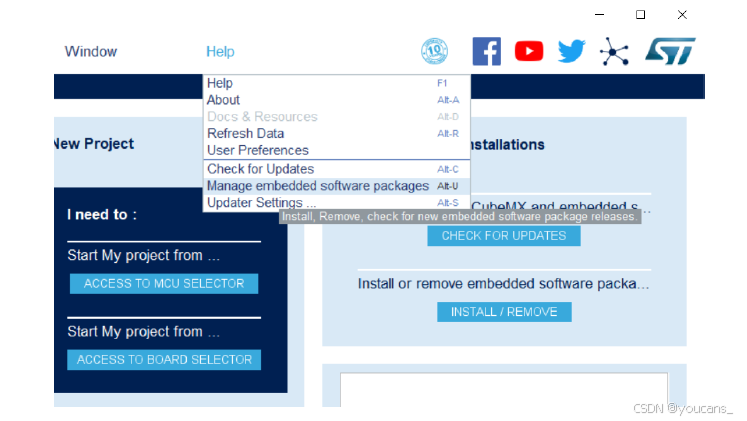
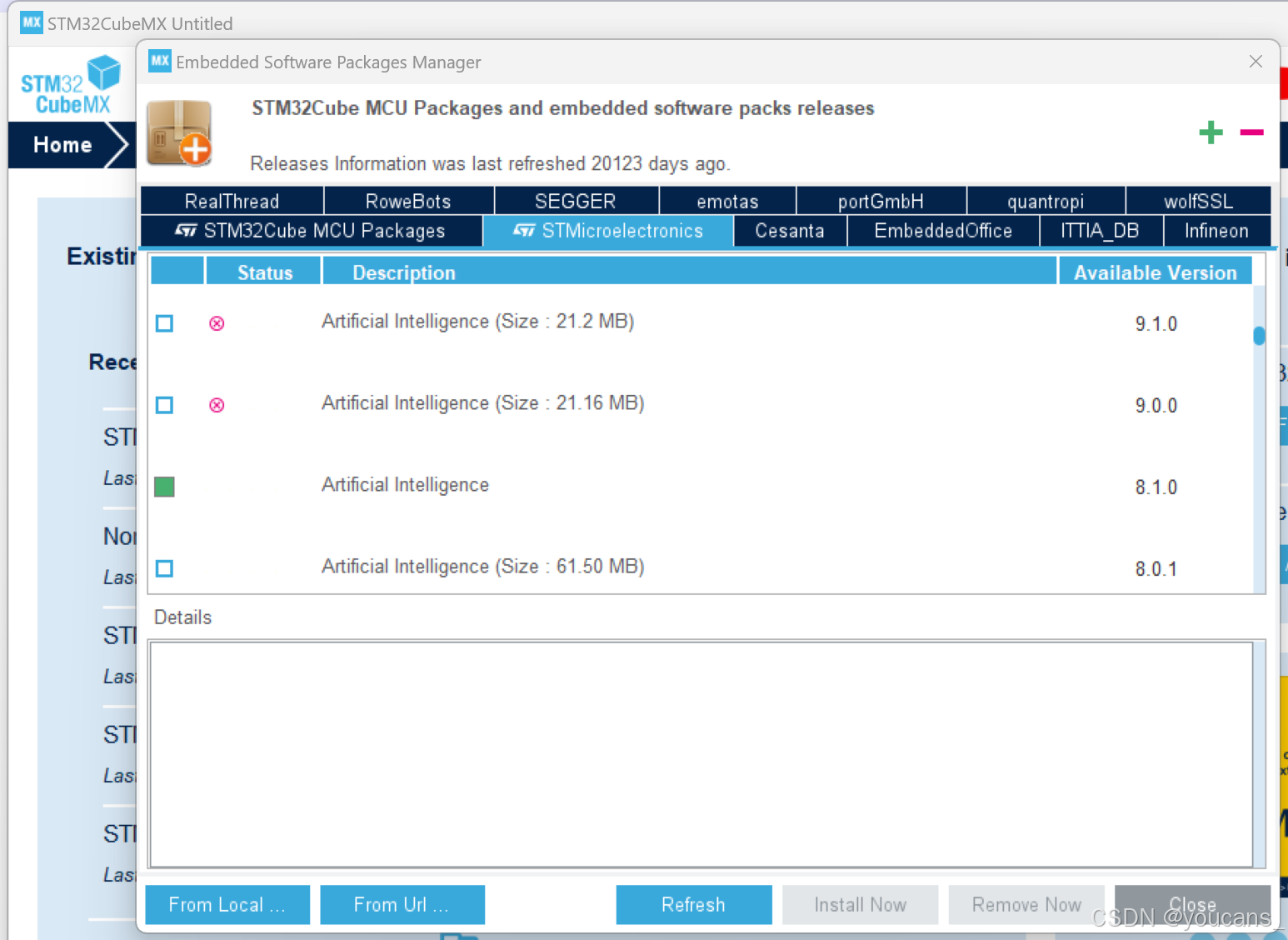
(2)从[嵌入式软件包管理器]窗口,点击[刷新]按钮,获得扩展包的更新列表。进入[STMicroelectronics] 选项卡,找到 X-CUBE-AI。
注意不同版本的 STM32CubeMX 支持的 X-CUBE-AI 版本也不同,不兼容的版本之前会出现红色叉号 ❌。
(3)选中相应的复选框,然后点击[立即安装]按钮进行安装。安装完成后,该版本前面方框呈绿色标记,点击[关闭] 按钮。
4. 环境配置
4.1 Windows10 64-bit or newer
-
打开 Windows 命令行窗口。
-
更新系统路径变量。
set PATH=%STEDGEAI_CORE_DIR%\Utilities\windows;%PATH%
- [替代方案] 使用doskey命令创建别名
doskey stedgeai=“%STEDGEAI_CORE_DIR%\Utilities\windows\stedgeai.exe” $*
- 验证环境(显示的版本取决于安装的组件)
$ stedgeai --version
ST Edge AI Core v2.0.0-A1
ISPU 1.1.0
MLC 1.1.0
StellarStudioAI 2.0.0
STM32CubeAI 10.0.0
STM32MP2 1.0
或者也有嵌入式Python模块的版本(显示的模块取决于安装的组件)
$ stedgeai --tools-version
stedgeai - ST Edge AI Core v1.0.0
- Python version : 3.9.13
- Numpy version : 1.23.5
- TF version : 2.15.1
- TF Keras version : 2.15.0
- ONNX version : 1.15.0
- ONNX RT version : 1.18.1
4.2 Ubuntu 20.4 and Ubuntu 22.4 (or derived)
环境设置类似。系统路径中应可访问本机GCC(X86_64)工具链。
export PATH= S T E D G E A I C O R E D I R / U t i l i t i e s / l i n u x : STEDGEAI_CORE_DIR/Utilities/linux: STEDGEAICOREDIR/Utilities/linux:PATH
4.3 macOS (x64) - Minimum version High Sierra
环境设置类似。系统路径中应可访问本机GCC(X86_64)工具链。
export PATH= S T E D G E A I C O R E D I R / U t i l i t i e s / m a c : STEDGEAI_CORE_DIR/Utilities/mac: STEDGEAICOREDIR/Utilities/mac:PATH
5. 启动一个新的 STM32 AI 项目
《待续》
6. 嵌入式推理客户端 API
嵌入式推理客户端API 是<project_name>/Middlewares/ST/AI/src/.h 文件的一部分。所有函数和宏均根据所提供的C 网络名称生成。
6.1 张量
输入和输出缓冲区被定义为具有最多3 个维度的张量(HWC 布局格式,代表高度、宽度和通道)。为了处理一组张量,可添加批维度。缓冲区完全通过struct ai_buffer C 结构定义来定义。
/* @file: ai_platform.h */
typedef struct ai_buffer_ {
ai_buffer_format format; /*!< 缓冲区格式 */
ai_u16 n_batches; /*!< 缓冲区中的批数 */
ai_u16 height; /*!< 缓冲区高度维度 */
ai_u16 width; /*!< 缓冲区宽度维度 */
ai_u32 channels; /*!< 缓冲区通道编号 */
ai_handle data; /*!< 指向缓冲区数据的指针 */
} ai_buffer;
提示:目前,输入和输出张量仅支持AI_BUFFER_FORMAT_FLOAT 格式(32 位浮点)。这种C 结构还可用于处理不透明和特定数据缓冲区。
6.1.1 一维张量
对于一维张量,预计采用标准C 数组类型处理输入和输出张量。
#include "network.h"
#define xx_SIZE VAL /* = H * W * C = C */
ai_float xx_data[xx_SIZE]; /* n_批次 = 1,高度 = 1,宽度 = 1,通道 = C */
ai_float xx_data[B * xx_SIZE]; /* n_批次 = B,高度 = 1,宽度 = 1,通道 = C */
ai_float xx_data[B][xx_SIZE];
6.1.2 二维张量
对于二维张量,采用标准二维C 数组存储器排列来处理输入和输出张量。两个维度映射到原始工具箱表达中的张量的前两个维度:Keras / TensorFlow™中的H 和C、Lasagne 中的H 和W。
#include "network.h"
#define xx_SIZE VAL /* = H * W * C = H * C */
ai_float xx_data[xx_SIZE]; /* n_批次 = 1,高度 = H,宽度 = 1,通道 = C */
ai_float xx_data[H][C];
ai_float xx_data[B * xx_SIZE]; /* n_批次 = B,高度 = H,宽度 = 1,通道 = C */
ai_float xx_data[B][H][C];
6.1.3 三维张量
对于三维张量,采用标准三维C 数组存储器排列来处理输入和输出张量。
#include "network.h"
#define xx_SIZE VAL /* = H * W * C */
ai_float xx_data[xx_SIZE]; /* n_批次 = 1,高度 = H,宽度 = W,通道 = C */
ai_float xx_data[H][W][C];
ai_float xx_data[B * xx_SIZE]; /* n_批次 = B,高度 = H,宽度 = W,通道 = C */
ai_float xx_data[B][H][W][C];
6.2 create() / destroy()
ai_error ai_<name>_create(ai_handle* network, const ai_buffer* network_config);
ai_handle ai_<name>_destroy(ai_handle network);
这份强制函数是 AI 客户端实例化和初始化 NN 实例必须调用的早期函数。 ai_handle 引用必须传递到其他函数的不透明上下文。
- config 参数是编码为ai_buffer 的特定网络配置缓冲区,由(AI_DATA_CONFIG C 定义)AI 代码生成器(参见 <名称>.h 文件)生成
- 当应用程序不再使用该实例,必须调用ai__destroy()函数,释放所分配的资源
典型使用
#include <stdio.h>
#include "network.h"
...
/* 引用实例化NN 的全局句柄 */
static ai_handle network = AI_HANDLE_NULL;
...
int aiInit(void) {
ai_error err;
...
err = ai_network_create(&network, AI_NETWORK_DATA_CONFIG);
if (err.type != AI_ERROR_NONE) {
/* 管理错误 */
printf("E: AI error - type=%d code=%d\r\n", err.type, err.code);
...
}
...
}
6.5 init()
ai_bool ai__init(ai_handle network, const ai_network_params* params);
该强制函数必须由客户端用于初始化实例化NN 的内部运行时结构:
- params 参数是一个结构(ai_network_params 类型),用于传递所生成权重(params 属性)的引用以及激活/崩溃存储器缓冲区(activations 属性)。
- network 句柄必须是有效句柄。请参考ai__create()函数。
/* @file: ai_platform.h */
typedef struct ai_network_params_ {
ai_buffer params; /*! 参数缓冲区信息(必需!) */
ai_buffer activations; /*! 激活缓冲区信息(必需!) */
} ai_network_params;
必须使用多个C 宏助手和特定AI__XX C 定义初始化此参数:
- params 属性处理权重/偏差存储器缓冲区
- activations 属性处理转发过程使用的激活/崩溃存储器缓冲区, 参考ai__run()函数)
- 相关存储块的大小分别由以下C 定义(参考文件<名称>_data.h)来定义。这些缓冲区的存储布局取决于实现的神经网络。
- AI__DATA_WEIGHTS_SIZE
- AI__DATA_ACTIVATIONS_SIZE
典型使用
#include <stdio.h>
#include "network.h"
#include "network_data.h"
...
/* 引用实例化NN 的全局句柄 */
static ai_handle network = AI_HANDLE_NULL;
/* 处理激活数据缓冲区的全局缓冲区 - R/W 数据 */
AI_ALIGNED(4)
static ai_u8 activations[AI_NETWORK_DATA_ACTIVATIONS_SIZE];
...
int aiInit(void) {
ai_error err;
...
/* 初始化网络 */
const ai_network_params params = {
AI_NETWORK_DATA_WEIGHTS(ai_network_data_weights_get()),
AI_NETWORK_DATA_ACTIVATIONS(activations) };
if (!ai_network_init(network, ¶ms)) {
err = ai_network_get_error(network);
/* 管理错误 */
...
}
...
}
6.6 run()
ai_i32 ai__run(ai_handle network, const ai_buffer* input, ai_buffer* output);
该函数是馈送NN 的主函数。输入和输出缓冲区参数(ai_buffer 类型)提供输入张量并存储预测的输出张量
- 返回值是处理的输入张量数(n_batches > 1)。如果返回值是负数或为空,则使用
ai__get_error()函数获取错误。 - 必须使用AI_IN_1(和AI_OUT_1)初始化输入(和输出)缓冲区句柄
- AI_IN_1_SIZE(和AI_OUT_1_SIZE)用于初始化输入数据(和输出数据)缓冲区
提示:可以传递两个单独的输入和输出ai_buffer 列表。这样即可在未来支持具有多个输入、输出或两者的神经网络。AI_IN_NUM 和AIOUT_NUM 分别用于在编译时获取输入和输出的数量。这些数值也由 ai_network_report 结构返回(参考ai_get_info()函数)。
典型应用:
#include <stdio.h>
#include "network.h"
...
/* 引用实例化NN 的全局句柄 */
static ai_handle network = AI_HANDLE_NULL;
...
static ai_buffer ai_input[AI_NETWORK_IN_NUM] = { AI_NETWORK_IN_1 };
static ai_buffer ai_output[AI_NETWORK_OUT_NUM] = { AI_NETWORK_OUT_1 };
...
int aiRun(const ai_float *in_data, ai_float *out_data,
const ai_u16 batch_size)
{
ai_i32 nbatch;
...
/* 初始化输入/输出缓冲区处理程序 */
ai_input[0].n_batches = batch_size;
ai_input[0].data = AI_HANDLE_PTR(in_data);
ai_output[0].n_batches = batch_size;
ai_output[0].data = AI_HANDLE_PTR(out_data);
nbatch = ai_network_run(network, &ai_input[0], &ai_output[0]);
if (nbatch != batch_size) {
err = ai_network_get_error(network);
/* 管理错误 */
...
}
...
}
参考文献:UM2526 人工智能(AI)X-CUBE-AI 扩展包入门指南
版权声明:
[email protected] 原创作品,转载必须标注原文链接:【EdgeAI实战】(2)STM32Cube.AI 扩展包
Copyright@youcans 2025
Crated:2025-02