1. 聚类任务概述
聚类是一种无监督学习任务,旨在将数据集中相似的数据点划分到同一组(簇)中,
使得同一簇内的数据点相似度高,不同簇的数据点相似度低。
2. 性能度量
2.1 外部指标
- Jaccard系数 (Jaccard Coefficient):
- 公式:
,其中(a)是在预测和真实划分中都属于同一簇的数据点对的数量,(b)是在预测中属于同一簇但在真实划分中不属于同一簇的数据点对的数量,(c)是在预测中不属于同一簇但在真实划分中属于同一簇的数据点对的数量。
- 公式:
- Rand指数 (Rand Index):
- 公式:
,其中(d)是在预测和真实划分中都不属于同一簇的数据点对的数量。
- 公式:
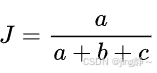
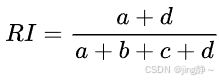
2.2 内部指标
- 轮廓系数 (Silhouette Coefficient):
- 对于样本(i),(a(i))是(i)到同簇其他样本的平均距离,(b(i))是(i)到其他簇样本的最小平均距离。
- 公式:
,轮廓系数
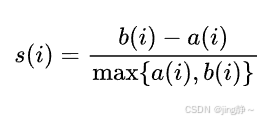
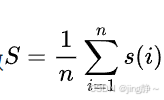
3. 距离计算
3.1 欧氏距离 (Euclidean Distance)
- 公式:
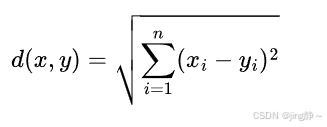
3.2 曼哈顿距离 (Manhattan Distance)
- 公式:
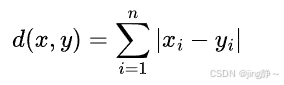
4. 原型聚类
4.1 K-Means 聚类
-
算法步骤:
- 随机初始化(k)个簇中心。
- 将每个数据点分配到最近的簇中心。
- 更新簇中心为簇内数据点的均值。
- 重复步骤 2 和 3 直到收敛。
-
**代码示例(使用 Python 和
scikit-learn):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
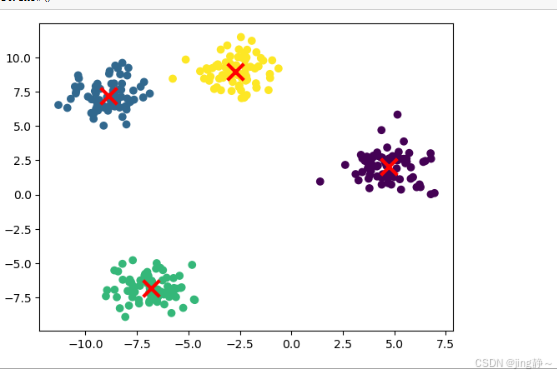
# 生成数据
X, y = make_blobs(n_samples=300, centers=4, random_state=42)
# 创建 K-Means 聚类器
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(X)
# 预测簇
labels = kmeans.predict(X)
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], marker='x', s=200, linewidths=3, color='r')
plt.show()
5. 密度聚类
5.1 DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
-
核心概念:
- 核心点:在半径(eps)内至少有(MinPts)个邻居的数据点。
- 边界点:在半径(eps)内邻居数少于(MinPts)但属于核心点的邻居的数据点。
- 噪声点:既不是核心点也不是边界点的数据点。
-
**代码示例(使用 Python 和
scikit-learn):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
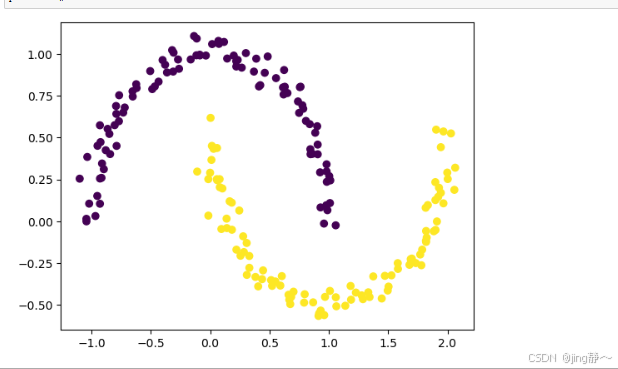
# 生成数据
X, y = make_moons(n_samples=200, noise=0.05, random_state=42)
# 创建 DBSCAN 聚类器
dbscan = DBSCAN(eps=0.3, min_samples=5)
dbscan.fit(X)
# 预测簇
labels = dbscan.labels_
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.show()
6. 层次聚类
6.1 凝聚式层次聚类 (Agglomerative Hierarchical Clustering)
-
算法步骤:
- 每个数据点作为一个单独的簇。
- 合并最相似的两个簇。
- 重复步骤 2 直到达到预定的簇数量或其他停止条件。
-
**代码示例(使用 Python 和
scikit-learn):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
# 生成数据
X, y = make_blobs(n_samples=300, centers=4, random_state=42)
# 创建凝聚式层次聚类器
agg_clustering = AgglomerativeClustering(n_clusters=4)
agg_clustering.fit(X)
# 预测簇
labels = agg_clustering.labels_
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.show()
代码解释
K-Means 代码解释:
make_blobs:生成聚类数据。KMeans:创建 K-Means 聚类器,设置簇的数量。kmeans.fit(X):训练聚类器。kmeans.predict(X):对数据进行聚类预测。plt.scatter:绘制数据点和簇中心。
DBSCAN 代码解释:
make_moons:生成非球形数据。DBSCAN:创建 DBSCAN 聚类器,设置邻域半径(eps)和最小样本数(MinPts)。dbscan.fit(X):训练聚类器。dbscan.labels_:获取聚类结果。
凝聚式层次聚类代码解释:
AgglomerativeClustering:创建凝聚式层次聚类器,设置簇的数量。agg_clustering.fit(X):训练聚类器。agg_clustering.labels_:获取聚类结果。
总结
聚类是无监督学习中的重要任务,不同的聚类算法适用于不同的数据分布和场景。性能度量可以评估聚类结果的好坏,距离计算是许多聚类算法的基础,原型聚类(如
K-Means)适合球形数据,密度聚类(如 DBSCAN)适用于处理噪声和非球形数据,层次聚类可以生成聚类的层次结构。
