Seq2Seq model个人小记
Seq2Seq模型在许多自然语言处理的任务中表现良好,比如:机器翻译,聊天机器人等。它主要由两个RNN(经常使用LSTM或者GRU)模块构成,分别充当encoder和decoder的角色,encoder有序的读取不同长度的输入,每个timestep读取一个symbol(word),encoder把不同长度的句子(inputs)转换为固定长度的向量c,decoder在根据这个固定长度的向量解码为不同长度的输出(outputs)。
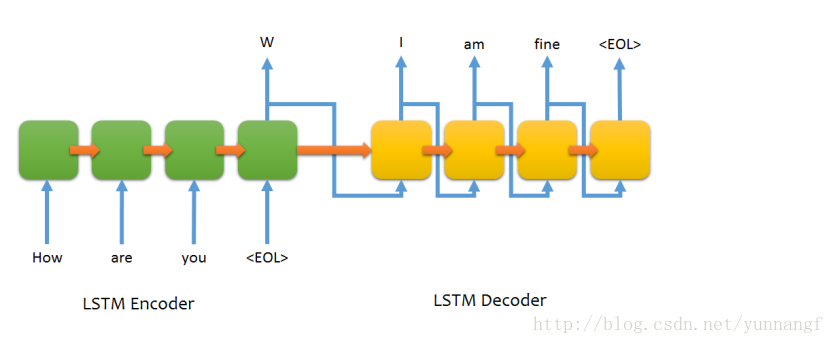
使用模型需要考虑的一些问题
- Padding
- bucketing && dynamic-rnn
- attention Mechanism
Padding
细心的读者可能会说,你前面不是说encoder有序的读取不同长度的输入(inputs)吗?这里表达的意思是模型能够处理不同长度的输入,但是模型训练的时候,我们需要先把中文(英文)先转换成计算机能够识别的表达(这里通常说的是向量形式),我们知道神经网络训练其实就是大量的矩阵计算,长度不统一会给计算和参数更新带来一定的困难,所以需要每个输入保持固定长度(或者每个minibatch内的输入保持固定长度),这里就需要用到padding,通常是zero-padinng,即把每个minibatch内的输入都不足的地方补零,直到所有句子的长度都等于该minibatch内最长句子的长度。
除了zero-padding补足长度之外,还需要对句子做一些其他特殊的padding,这里需要用到下面几个字符
1. PAD (zero-padding)
2. SOS (start of sentence)
3. EOS(end of sentence)
4. UNK(Unknown; word not in vocabulary)
SOS主要用来告诉decoder什么地方开始decoding,EOS用来告诉decoder什么地方结束decoding。
当遇到一些词典里面没有的词的时候,通常使用UNK替换。
Bucketing && Dynamic-rnn
尽管Padding能够解决不同长度输入的问题,但接下来考虑这种情况,如果所有输入中最长的句子的长度为100,而最短的只有2,rnn有要求所有输入长度必须一样,那就需要把所有句子都padding到100,而长度为2的句子padding到100,得加入98个0, 这样做的后果就是:
1. 向量稀疏问题(存在大量0)
2. 增大计算量
3. 短句子的信息可能被大量0所掩盖
Bucketing
bucketing的思想其实很简单,就是根据句子长度把句子放入不同大小的buckets中,例如我们定义了 [ (5,10), (10,15), (20,25), (40,50) ]这几个buckets,如果输入(input)的长度为4,我们就把这个input放入(5,10)这个bucket中,这样最后相似长度的句子都会被放到同一个bucket中,也就解决了前面提到的问题。
有的同学可能接着会问,这样的话,不同的bucket里的句子还是不同大小的啊,还是不满足rnn需求。答案是最rnn会为每一个buckets都创建一个sub graph。训练的时候,根据当前batch data所归属的bucket id,找到它对应的sub graph,进行参数更新(虽然是不同的sub graph,但参数是共享的。至少tensorflow中是这么实现的)。
Dynamic-rnn
Dynamic-rnn会更灵活一点,它可以让不同迭代传入的batch可以是长度不同数据,但同一次迭代一个batch内部的所有数据长度仍然是固定的。例如,第一时刻传入的数据shape=[batch_size, 10],第二时刻传入的数据shape=[batch_size, 12],第三时刻传入的数据shape=[batch_size, 8]等。
attention Mechanism
Seq2Seq model也存在一些限制,encoder把输入(input)中的所有信息整合为一个固定输入的向量,decoding的时候,对短句可能影响不太明显,但是对于长句,则将丢失大量信息(context)。对于长句丢失信息,有一种方法是encoder倒着读入输入,这样的话encoding后的上下文向量c和的从顶时更接近,比如对于中英翻译:source:“这是一个太阳”。target:”this is a sun”,倒着读的时候, encoding读入的顺序是:“阳太个一是这“,“这”和”this”更接近,这可以在一定程度上缓解长时依赖的问题。
但有没有一种更好的方法能在每次decoding的时候着重关注对当前decoding影响较大的encoding, 比如,对于input: 这是一个太阳 decoding 预测this的t时候,我们知道主要取决于于”这是”,所以我们期望,decoding时能着重关注对当前output的词影响较大的词,我们能不能给input中的每个词一个权重,根据decoding时候的场景不同选择不同的权重,对于前面例子,我们就可以给“这是”这个词分配更高的权重。每次decoding的时候,对于encoder中的每个词的信息都会有不同的权重。(这只是一个粗略的比喻,如有不对,欢迎指正,细节的公式推导不在给出,网上都有)