【写在前面:这是笔者心理学的本科毕业设计内容,在此记录设计中所包含的部分思路、代码操作和设计步骤,方便后续查阅和学习,希望对大家有点帮助,对于不足之处,也希望各路大佬可以不吝赐教。本文为作者原创文章,文中所示的图片、代码皆来自网络或笔者自制,仅做学习、记录使用,如果某些东西涉及侵权,或者发现有任何写的不对的地方,请作者大大告知笔者,可以对此进行补充说明。如有人私自引入商业使用构成侵权或违法犯罪,则笔者概不负责。鉴于今年是卢雷元年,必须声明一下,如若抄袭本文作为毕设内容,笔者保留追究责任的权利。】
文章目录
一、相关背景介绍
1.1 认知灵活性
认知灵活性(cognitive flexibility)就是对不断变化的环境条件有选择性地转换和适应行为的能力(Miyake, A. et al., 2000; Norman, D. A. et al., 1980)。
由于是关于认知灵活性的研究,故先用一幅图简单说明研究中常用的实验设计方法及设计中各任务之间的关系。而在认知灵活性的实验中,大多都是对被试在完成不同任务时的转换代价进行的研究。而常用的几种研究范式有交替转换范式、单一转换范式、自主转换范式和任务线索提示范式这几种。简要介绍下常用的两种范式。
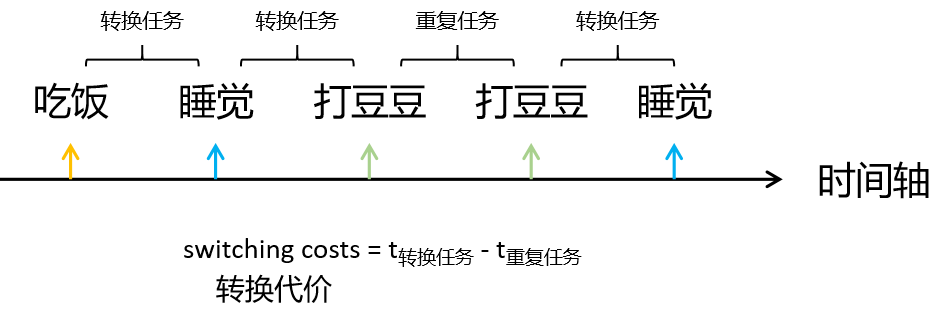
任务线索提示范式
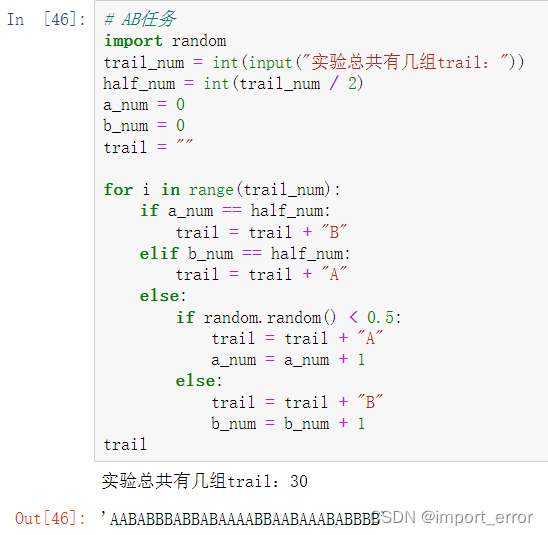
在任务线索提示范式中,我们需要提前设计好任务出场的顺序,尽可能地保证任务是随机(伪随机)出现的。打个比方,实验中有任务A和任务B,那么我们就可以按照ABABBABABBABAB…的顺序或者BAABABBABAABABA…的顺序安排任务,可以人为安排,或者用代码(如下python)或excel随机生成,例如下面这个思路。
# python 3.7.4
# jupyter notebook
# AB任务随机
import random
trail_num = int(input("实验总共有几组trail:"))
half_num = int(trail_num / 2)
a_num = 0
b_num = 0
trail = ""
for i in range(trail_num):
if a_num == half_num:
trail = trail + "B"
elif b_num == half_num:
trail = trail + "A"
else:
if random.random() < 0.5:
trail = trail + "A"
a_num = a_num + 1
else:
trail = trail + "B"
b_num = b_num + 1
trail
直接运行代码,输入实验要生成几组trail,就能得到结果,执行结果如下:
之后,我们便可以按照这个顺序安排实验任务的出场顺序,但需要注意的是,安排的任务中需要注意几点问题:(1)对于两个任务,我们需要尽可能将任务难度设置成一致,比如任务A是判断大小,任务B是判断数字奇偶,不然如果任务A是问1+1=?,任务B是求解地球到太阳的距离,会出问题的。(2)由于被试是按照我们程序设定的提示做出相应反应,完成对应任务的,那么提示的线索需要做到足够简单,类型一致,放置方位一致,所以基本上常用的提示线索有简单几何图形,颜色等。(3)在设置任务按键的时候,要注意按键平衡,比如对于被试甲来说,第一个任务按q键是正确的,第二个任务按p键是正确的,那么对于被试乙来说,第一个任务则需要按p键是正确的,第二个任务则是按q键是正确的,以此类推。
当然,对于以上需要注意的点,若是有特殊的实验设计,则可以忽略。
自主选择范式
在自主选择范式中,我们需要让被试自主选择目标任务去完成,即假设第一个任务是A,那么被试可以自主选择第二个任务是A还是B。由于在我的实验中并没有涉及到这部分的设计,所以在此就不展开介绍了。
1.2 情绪
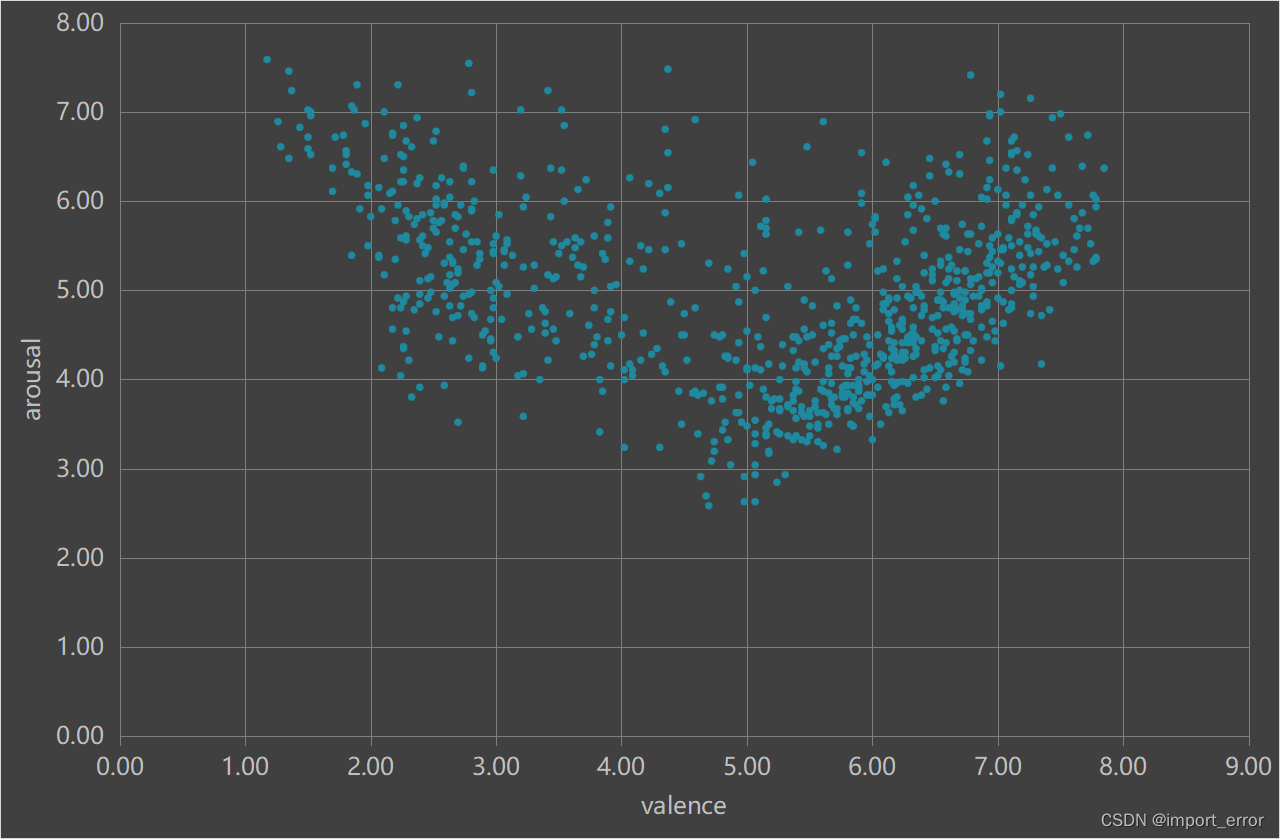
情绪是我们生活中非常常见的一种心理现象,开心,愤怒,痛苦…但在本篇文章中,在情绪的诱发方面主要用到的是Russell(1980)所提出的一个二维情绪模型,在这个模型中,情绪被划分成了两个维度,即效价和唤醒度。如下图所示,x轴表示情绪的效价,而y轴表示的是情绪的唤醒度。于是我们就可以根据这个维度信息来对情绪进行一个简单的划分,即积极情绪(Positive affect)、中性情绪(Neutral affect)、消极情绪(Negative affect)三种,也就是本文中用到的部分。当然,这里的三个部分是指在横坐标上的一个划分,即效度上的一个划分,而唤醒度部分在下文中再予以讨论。

1.3 认知资源
认知资源理论是一个非常经典的理论了,大致上描述起来就是,理论认为我们的认知是属于一种资源,是有限的,假设我们有100个单位的认知资源,那么码字可能就需要消耗掉80个单位,听歌消耗掉20个单位,那么这个时候,再叫我们去背个书,就做不到了。但是,我们可以人为地分配我们的认知资源,让它投入到我们希望投入的事情中去。
同时,我们知道记忆将会消耗一定量的认知资源,特别是处理目前手头事情的工作记忆,是前人探索认知资源时一个非常常用的锚点,即让你记住某些字词或图形一段时间,与此同时,你需要去做一些别的任务,完成任务后再对这部分的记忆内容去进行复述。
因为相信大家对这个概念相对来说都比较熟了,在这里就不展开说了。
1.4 功能性近红外成像(fNIRS)
总体介绍
功能近红外光谱设备(fNIRS, functional near-infrared spectroscopy)是一种新兴的脑成像探测技术,它是一项主要运用了近红外光,对大脑表层的血流动力学反应进行测量的功能性神经成像技术,其原理可类比依赖检测大脑血氧水平的功能磁共振技术,即是检测由大脑神经活动引起的血红蛋白浓度变化的一项技术(Logothetis, N. et al., 2001; Mehagnoul-Schipper D J et al., 2002; 杨茜, 2020)。大致原理为脑组织中生色团物质之间存在着对不同波长近红外光表现出不一样的吸收和散射关系,因此,我们可根据大脑表层对近红外光的吸收和散射程度来测定大脑血管中含氧血红蛋白 (HbO, Oxygenated hemoglobin) 和脱氧血红蛋白 (HbR, Deoxygenated hemoglobin) 的浓度,从而达到间接考察对应区域神经元活动、细胞代谢情况等大脑功能变化的目的 (Villringer A et al., 1997; 杨茜, 2020)。
基本原理
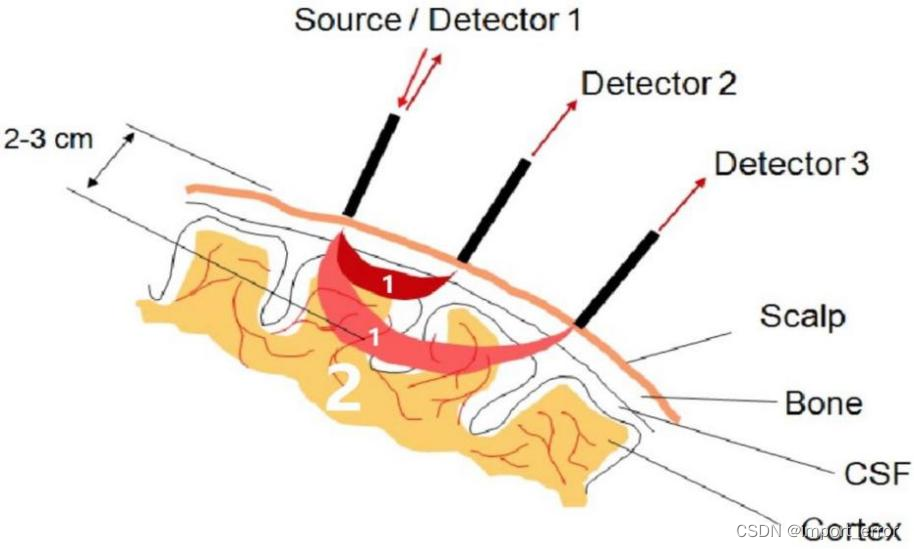
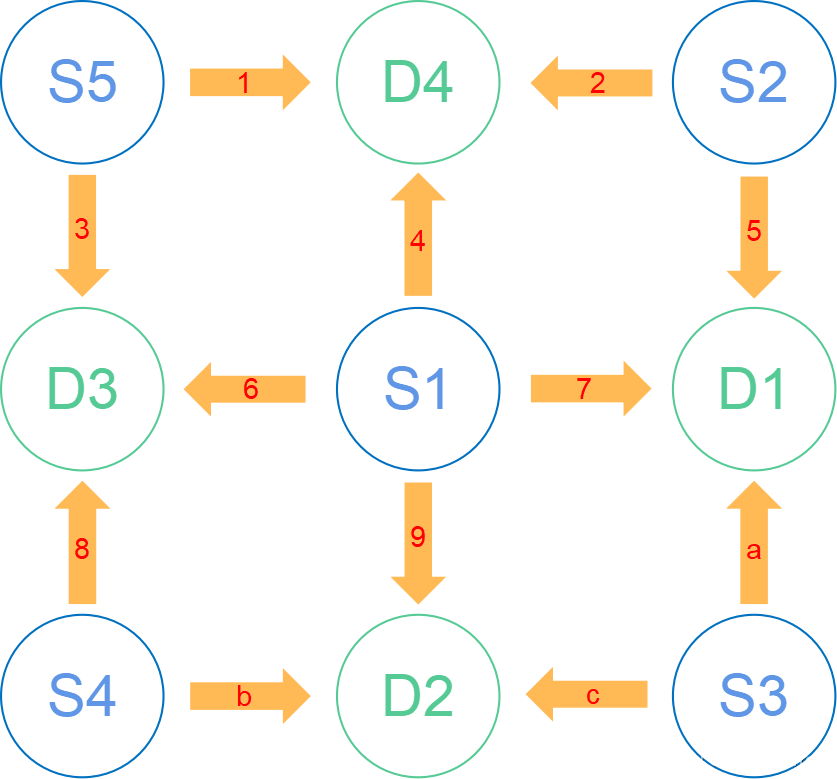
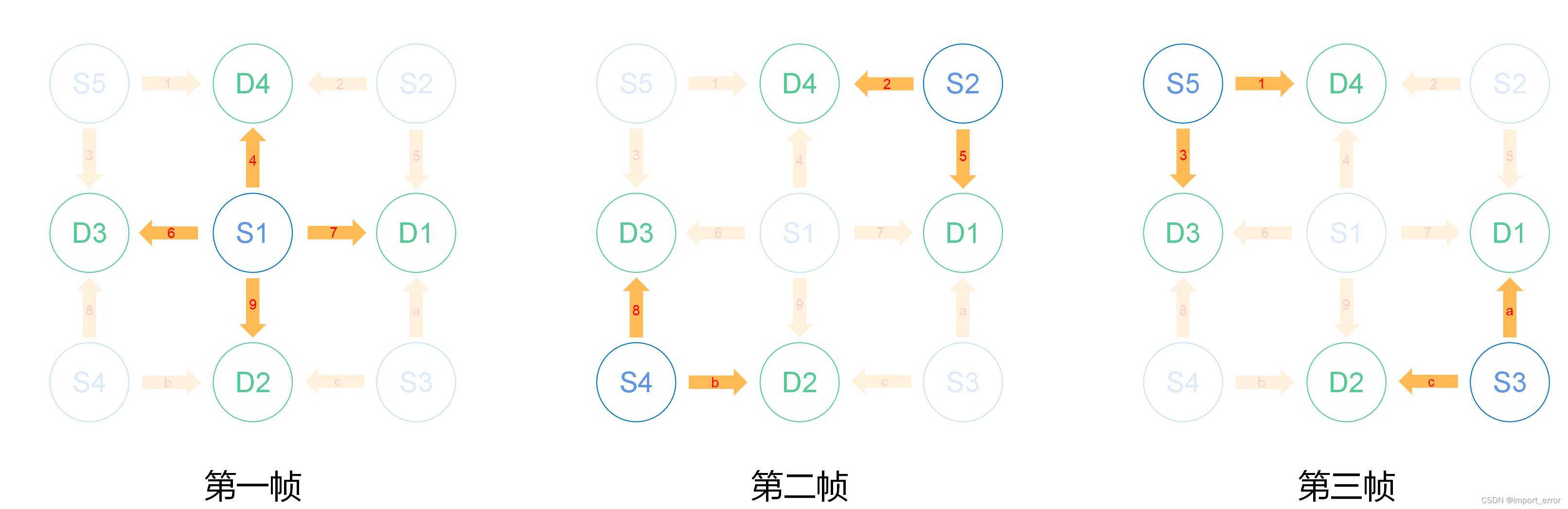
简单点说原理就是如上左图所示,图是从另一位博主[1]那粘贴的,概括来说就是近红外的最简结构是由一个近红外光源(Source)和一个探头(Detector)组成的,光线由S头发出,被D头接收到,经过电脑处理之后,就可以分析出S到D之间个区域的血氧情况。而由于在实验中通常都是由多个探头矩阵组成的,例如常见的8x8的组合方式,即8光源8探头,那么若全部S和D同时工作的话,就有可能出现多组信号源同时到达探测器,从而无法判定信号来源方向的问题。讲人话就是,如上右图所示,如果S1、S2、S3同时打开,那么D1就会在同一时间收到三个信号,那么这时候,就会出现两个bug,一是信号可能会叠加,从而引发共振或叠加造成数据错误;二是无法判断信号源,从而无法判定信号来的方向,还是以D1为例,它会无法判断现在拿到的信号是来自S1的、S2的还是S3的。所以为了解决这个bug,在近红外设备设计之初,就采取了差分发射的方式,用上右图的探头分布模板简单说就是,第一帧是S1发光,S2、S3、S4、S5不发光,第二帧是S2、S4发光,S1、S3、S5不发光,第三帧是S3、S5发光,S1、S2、S4不发光,以此类推,这样就可以保证对同一个探头(Detector)不会同时收到两个信号,即如下图所示。当然,如果是使用系统预设的探头分布模板的话,这部分可以不管,但如果需要自己设计探头分布模板的话,就需要注意这个问题。
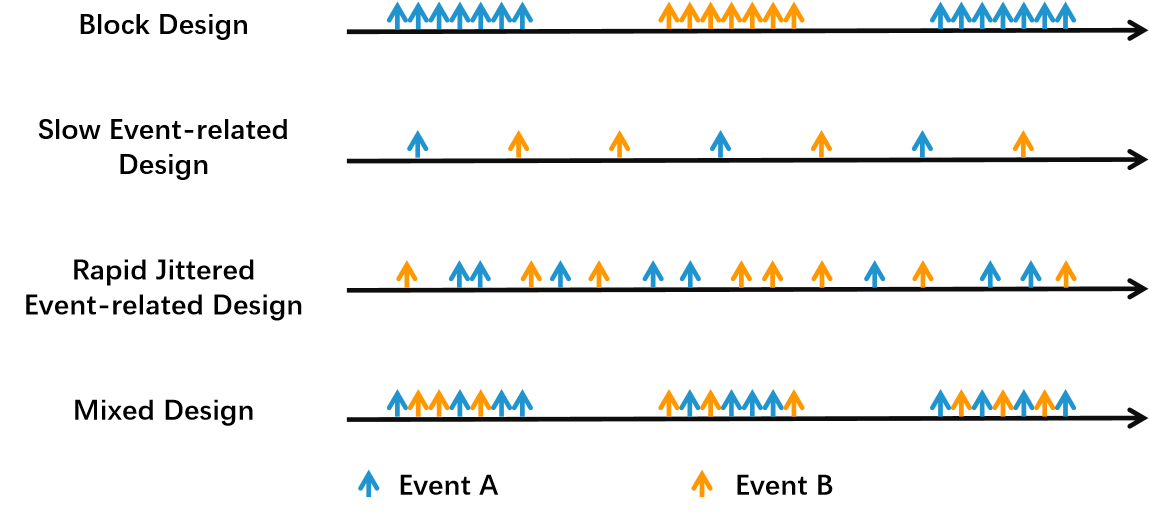
1.5 事件相关设计
事件相关设计 (Event-related (ER)) 经常在认知灵活性的实验中被应用,且由于它们比封锁式任务范式更灵活,故常是研究认知过程的一个先决条件(Burock et al., 1998, Rosen et al., 1998, Pollmann et al., 2000; Plichta M M et al., 2007)。而其他常用的设计方法如图所示,如组块设计 (Block-design (BD)) 等。这个看图应该是很好理解的,就是一个在近红外和核磁实验中非常常见的一个任务设计模式。
二、实验设计部分
2.1 实验设计思路
情绪图片选择上
由于在本次的实验中,激活情绪的部分用的是CAPS情绪库(中国情绪图片库,Chinese Affective Picture System),在图片库中,有给出的每张图片对应的效度和唤醒度的评分,将所有效度和唤醒度数据以二维点图的形式导出,就会呈现如下左图所示的点阵。与上图相同的是,横坐标代表的是情绪的效价,纵坐标表示的是情绪的唤醒度。由于图片的作用是诱发对应的情绪,所以不难看出,情绪的唤醒度水平相对是比较高的,这也是为什么上文中没有对唤醒度进行区分的原因。随后,根据左图,我们人为地将CAPS情绪库分成右图中的三个部分,分别代表积极情绪、中性情绪、消极情绪三种目标诱发情绪。在之后的实验中,我们将在这三个分类框框中的点,所对应的图片,去代表对应的情绪,即比如说实验需要用到消极情绪诱发图片,那么就在红框框中随机抽取。图片抽取的操作直接在EXCEL中完成(筛选)即可。这种划分方式是我自己设定的,大伙可以根据自己的实验需求重新划分。

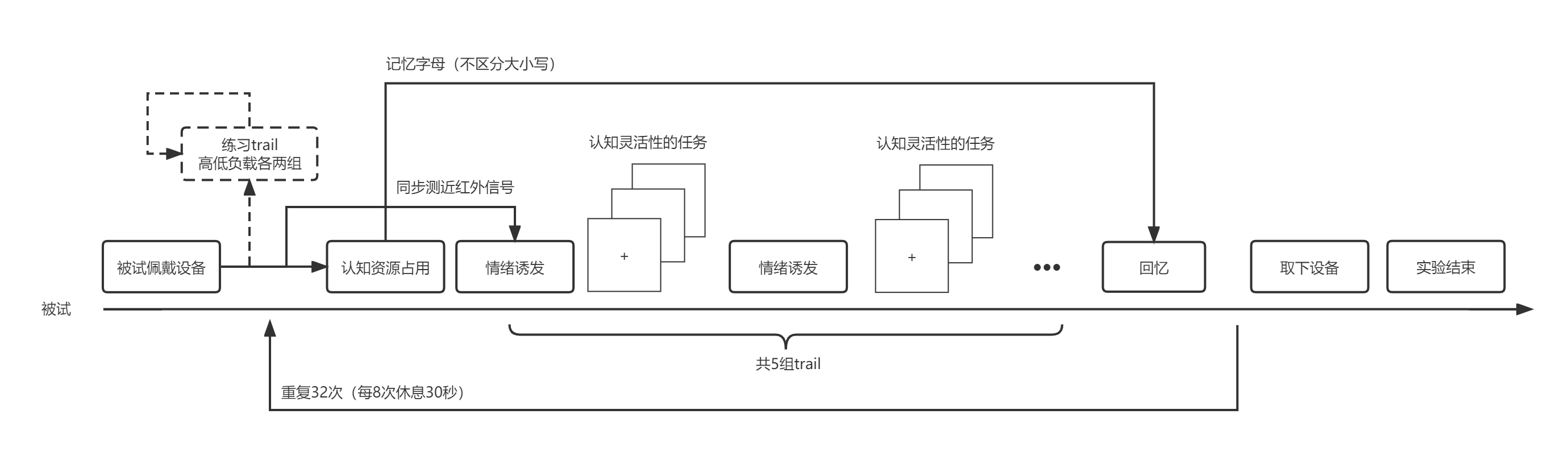
实验设计思路
我的实验思路如上图所示,由于大伙要研究的东西都不同,所以这里就不展开了,简单放个图,下一part。
2.2 E-prime部分
这一部分可以说是整个实验中最关键的部分,因为整个实验包括行为和近红外在内的所有控制操作都是在eprime中去完成的,相当于是问卷实验中的那份问卷。下图展示的是我eprime中设计的一整个完整流程。
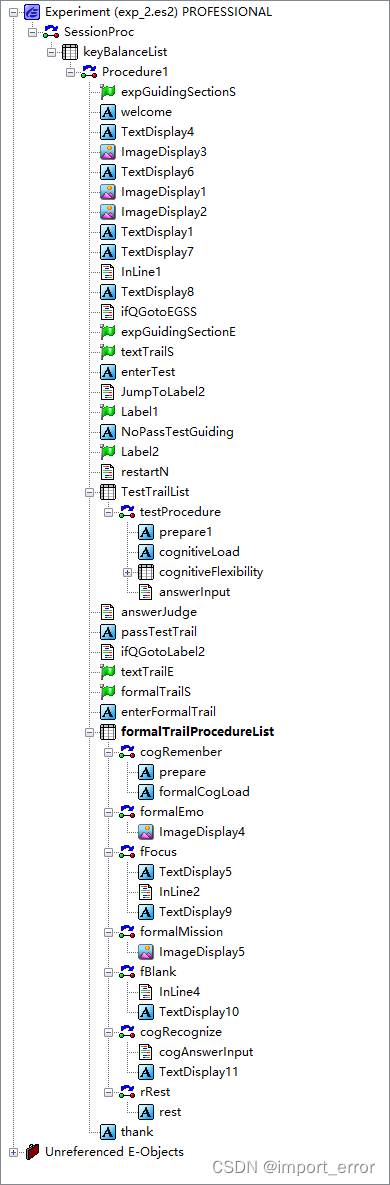
好像是有那么一点长and复杂,化简一下就是下面这个流程图所表示的思路,对比着看应该好一些。
接下来就是一步步拆解开,对每个部分进行设计就可以了。
实验教学部分,这里巨简单,一步步插图就可以了,不废话,下一步。
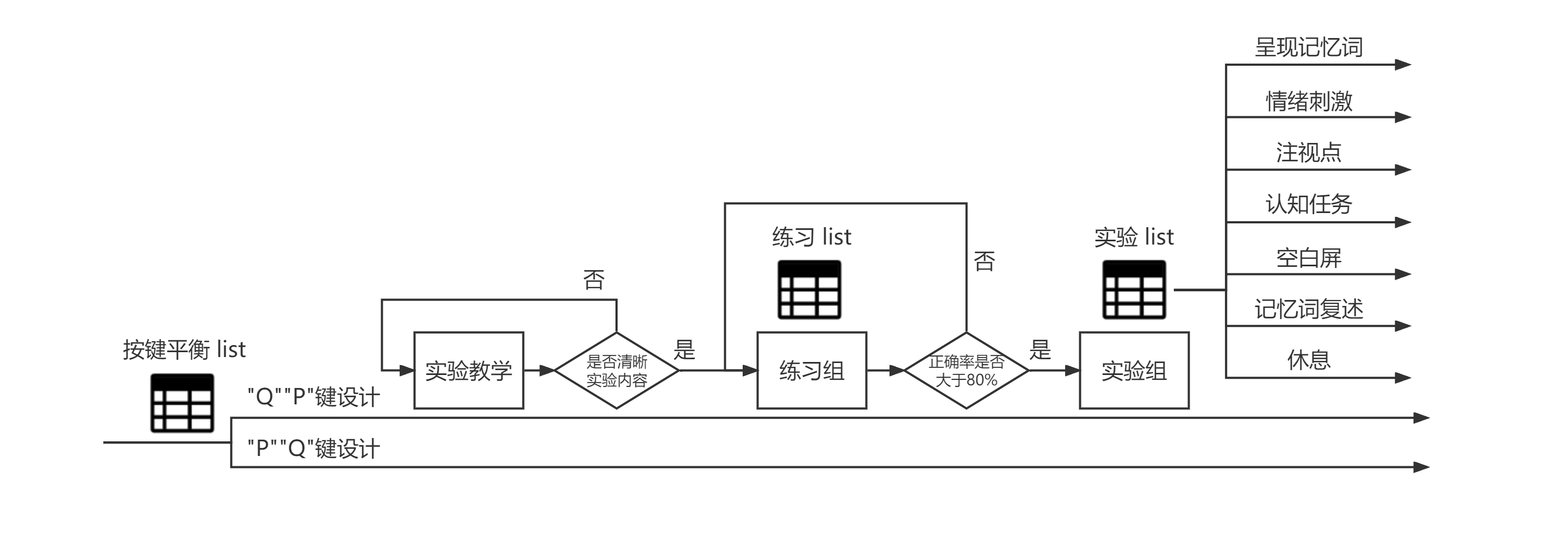
训练组部分,这部分也不难,只不过我设计了个自动判定跳转的步骤,逻辑的话看下图应该很好理解,而这里的list,则可以看做是一个任务池,随机从里捞任务(random)做就可以了。当然这个设计方式不唯一,比如说把这个没能通过的提示文本放在判断正确率之后也是可以的。
实验组部分就相对比较复杂了,由于eprime的单行道模式,所以操作起来就会很麻烦。但是,咱们可以运用面向对象的编程思维,给他封装、多态、继承一下,这样操作起来就方便很多了。具体说呢,就是我们把eprime中提供的list,看成procedure(因为list会一行一行执行命令),然后把每一行所执行的procedure看成是一个封装好的函数,而后面加进去的列,就是我们要往函数里传的参数。(如下所示代码) 这样一来,procedure设计问题,就会变成一个list填写,和对每个对象(函数)进行封装的问题。
#下图所示的表格,即可理解成这样,仅举例说明理解思路,不完全正确
def procedure(emoLoad, trailMission, fTrailAnswer, cogLoad, Mark):
既然用到了面向对象的方法,那么首先第一步需要做的就是抽象出这个程序中的类,讲人话就是把相同的东西放一块,然后用一个函数(procedure)去解决它。按照我的实验设计思路,在实验组中,会依次按照下图所示的这个顺序,向被试呈现这一屏一屏的东西。
思路有了之后,我们再来聚类分析,把相似的东西凑一凑,很轻松就可以分成以下七个部分(空格中表示的是我在程序中设置的procedure名称),分别是呈现记忆词(cogRemenber)、情绪刺激(formalEmo)、注视点(fFocus)、认知任务(formalMission)、空白屏(fBlank)、记忆词复述(cogRecognize)、休息(rRest)。

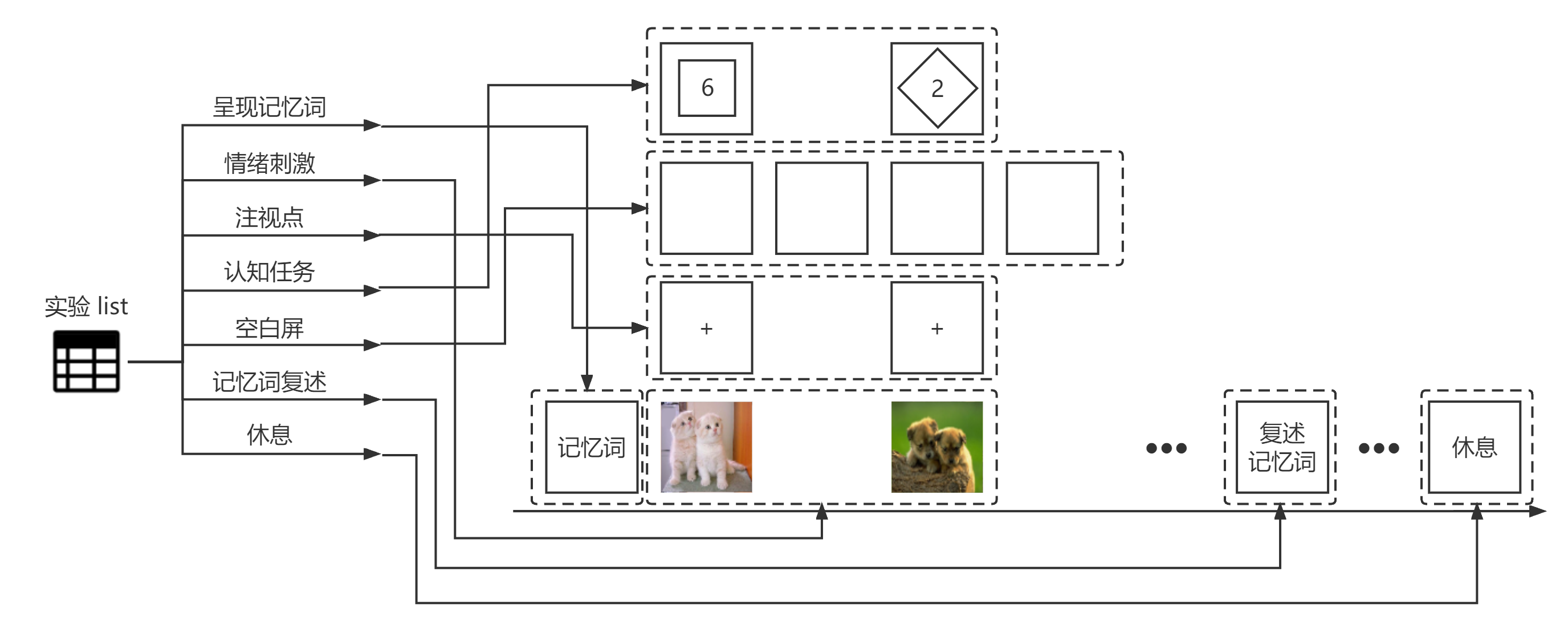
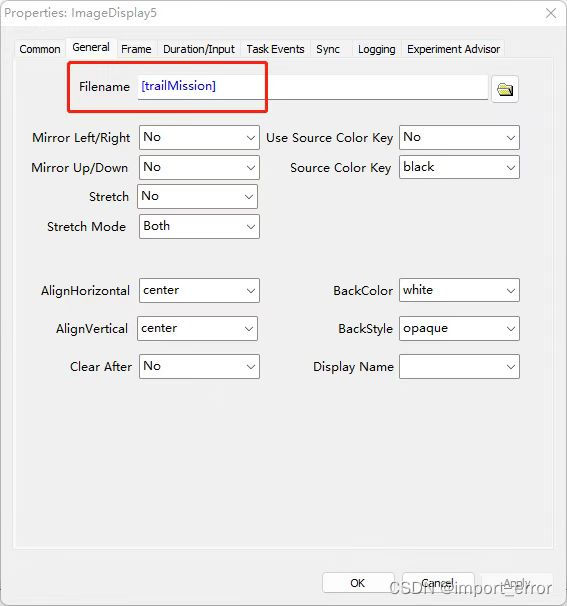
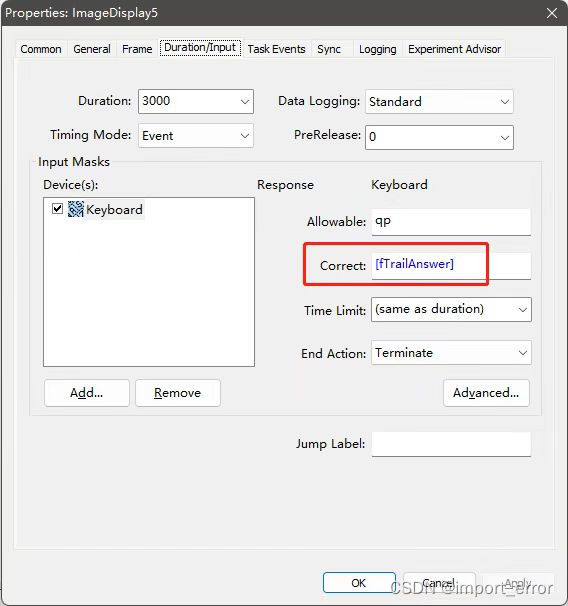
这样一来,每个对象(函数)中的procedure,就会变的非常简单,看上面那个图可以看出来,每个procedure里面基本就一两个屏。而难点就变成了如何填写这个list,即如下图所示,我们要做的就是把左边这个list填满,变成右边的就可以了。而这个表格的建立思路是,第一行放你需要执行的第一个procedure,第二行放第二个procedure,以此类推,而后面新增的列,要填的是你需要往这个procedure中传进去的数据(参数)(参数的作用如下图所示),像我这里需要的情绪图片(文件名)、提示做哪个任务的任务图片(文件名)、这个任务的答案(按键)、记忆词(字符)、近红外mark号(数字)这几个。这样一来,我们就可以借助外界工具了,填表嘛,谁不会啊。
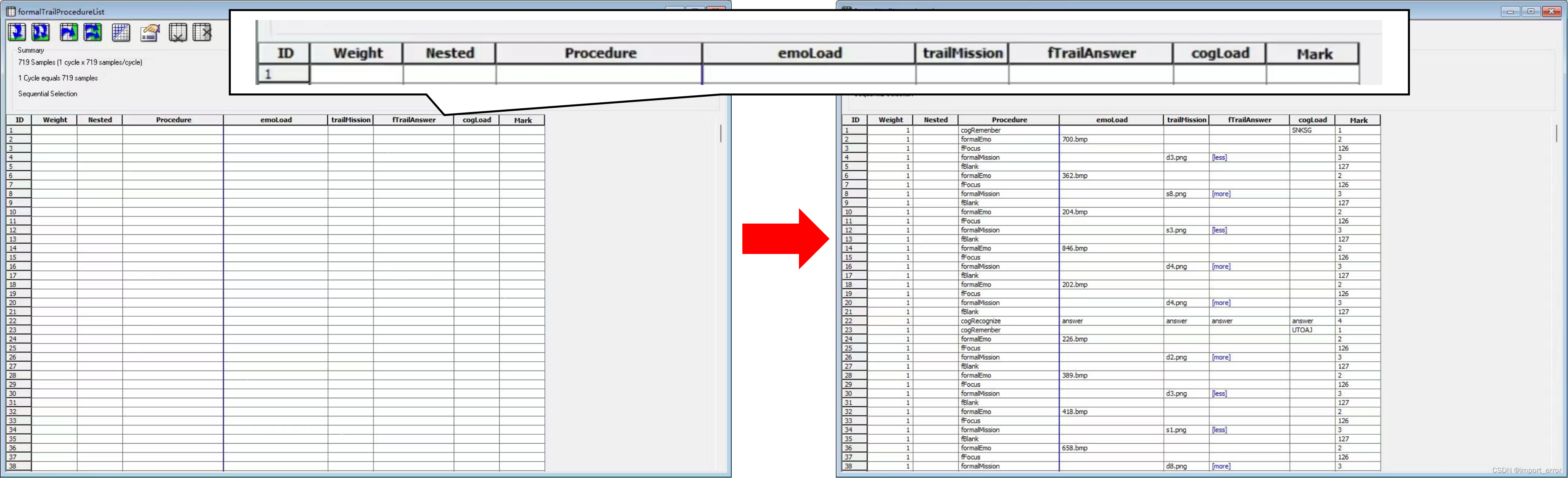
下面提供一个我的填表方法,因为我的实验总共有六个分组,每组里面要填708行x8列的表格,相当于就是6x708x8=33984个格子,虽然有规律可循,但是我选择敲代码,复制粘贴会死的orz。
"""
python 3.7.4
jupyter notebook
正式list生成 2.0 函数封装
group_num输入 0 || 1:
0表示先高负载,后低负载
1表示先低负载,后高负载
emo_group输入 non_emotion || active_emotion || negetive_emotion:
这里需要预先导入前文中划分好的情绪图片的表格
non_emotion表示中性情绪
active_emotion表示积极情绪
negetive_emotion表示消极情绪
"""
def trail_list_creat(group_num, emo_group):
trail_list = ['10011', '11010', '01001', '01010', '00000', '01111', '11000', '01100'] #1、0分别代表不同的任务
high_load = ['SNKSG','UTOAJ','VTQBZ','BWPDK','BIQVS','XKCYV','SNGXW','CPEYR','VJFSM','XGKBW','MWJTA','MKLVG','MCKWV','XKNMC','YKSLM','AYPOZ'] #高负荷组记忆词
low_load = ['RRRRR','QQQQQ','JJJJJ','SSSSS','UUUUU','ZZZZZ','HHHHH','MMMMM','LLLLL','NNNNN','IIIII','EEEEE','UUUUU','JJJJJ','UUUUU','OOOOO'] #低负荷组记忆词
square = ['s1.png','s2.png','s3.png','s4.png','s6.png','s7.png','s8.png','s9.png'] #方形任务展示图片的文件名
dimand = ['d1.png','d2.png','d3.png','d4.png','d6.png','d7.png','d8.png','d9.png'] #菱形任务展示图片的文件名
fTrail_df = DataFrame()
count_num = 0 #计负载组
m = 0 #计休息组
high_low_bool = group_num #高低认知负荷布尔,切换高低认知负载
#生成任务列表
while True:
#休息行
if m == 8:
fTrail_df = pd.concat([fTrail_df, DataFrame([1,'nan','rRest','rest','rest',