首先引用一下李博的AD-Census
https://ethanli.blog.csdn.net/article/details/108876143
在看AD-Census十字交叉臂代价聚合的部分时产生了一些困惑,解惑以后在此贴写下笔记方便日后复习。问题就在于以下这段代码:
void CrossAggregator::ComputeSubPixelCount()
{
//计算每个像素的支持区像素数量
//注意两种不同的聚合方向,像素的支持区像素是不同的,需要分开计算
/*下面有多层循环,
* k = 0为左右,k = 1 为上下
*/
bool horizontal_first = true;
for (sint32 n = 0; n < 2; n++)
{
const sint32 id = horizontal_first ? 0 : 1;
for (sint32 k = 0; k < 2; k++) {
for (sint32 y = 0; y < height_; y++) {
for (sint32 x = 0; x < width_; x++)
{
auto& arm = vec_cross_arms_[y * width_ + x];
sint32 count = 0;
if (horizontal_first)
{
if (k == 0) {
for (sint32 t = -arm.left; t <= arm.right; t++)
count++;
}
else {
for (sint32 t = -arm.top; t <= arm.bottom; t++)
count += vec_sup_count_tmp_[(y + t) * width_ + x];
}
}
else
{
if (k == 0) {
for (sint32 t = -arm.top; t <= arm.bottom; t++)
count++;
}
else {
for (sint32 t = -arm.left; t <= arm.right; t++) {
count += vec_sup_count_tmp_[y * width_ + x + t];
}
}
}
if (k == 0)
vec_sup_count_tmp_[y * width_ + x] = count;
else
vec_sup_count_[id][y * width_ + x] = count;
}
}
}
horizontal_first = !horizontal_first;
}
}
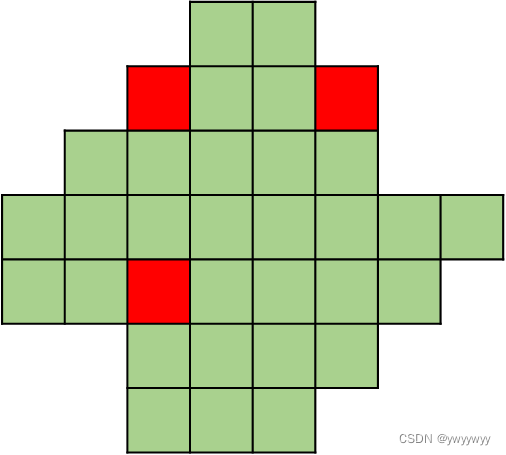
以上的代码是为了数出整个区域的像素数量,方便后面作除数。文章中有这么一个图:
https://ethanli.blog.csdn.net/article/details/108876143在看原理的时候,不自觉认为,每个像素应当单独计算其区域。却忘了每个像素的延伸规则是相同的,完全可以重复利用,省下了很多计算资源。也就是说,在聚合前那一步,只要首先把所有像素的十字方向交叉臂求出来了,后面调用就行了。
在代码中的体现如下:
for (sint32 t = -arm.top; t <= arm.bottom; t++)
count += vec_sup_count_tmp_[(y + t) * width_ + x];
即从上到下搜索每个像素的横向臂。
随后就是代价聚合了。
void CrossAggregator::AggregateInArms(const sint32& disparity, const bool& horizontal_first)
{
//此函数聚合所有像素当视差为disparity时的代价
if (disparity < min_disparity_ || disparity >= max_disparity_)
return;
const auto disp = disparity - min_disparity_;
const sint32 disp_range = max_disparity_ - min_disparity_;
if (disp_range <= 0)
return;
//将disp层的代价导入局部数组vec_cost_tmp_[0]
//可以避免过多访问更大的cost_aggr_,提高访问效率
for (sint32 y = 0; y < height_; y++) {
for (sint32 x = 0; x < width_; x++)
{
//提取每个像素的视差d下的代价值
vec_cost_tmp_[0][y * width_ + x] = cost_aggr_[y * width_ * disp_range + x * disp_range + disp];
}
}
//逐像素聚合
const sint32 ct_id = horizontal_first ? 0 : 1;
for (sint32 k = 0; k < 2; k++) {
for (sint32 y = 0; y < height_; y++) {
for (sint32 x = 0; x < width_; x++)
{
//获取arm数值
auto& arm = vec_cross_arms_[y * width_ + x];
//开始聚合
float32 cost = 0.0f;
if (horizontal_first) {
if (k == 0) {
for (sint32 t = -arm.left; t <= arm.right; t++)
cost += vec_cost_tmp_[0][y * width_ + x + t];
}
else {
for (sint32 t = -arm.top; t <= arm.bottom; t++) {
cost += vec_cost_tmp_[1][(y + t) * width_ + x];
}
}
}
else {
//竖直
if (k == 0) {
for (sint32 t = -arm.top; t <= arm.bottom; t++)
cost += vec_cost_tmp_[0][(y + t) * width_ + x];
}
else {
for (sint32 t = -arm.left; t <= arm.right; t++)
cost += vec_cost_tmp_[1][y * width_ + x + t];
}
}
if (k == 0)
vec_cost_tmp_[1][y * width_ + x] = cost;
else
cost_aggr_[y * width_ * disp_range + x * disp_range + disp] = cost / vec_sup_count_[ct_id][y*width_+x];
}
}
}
}
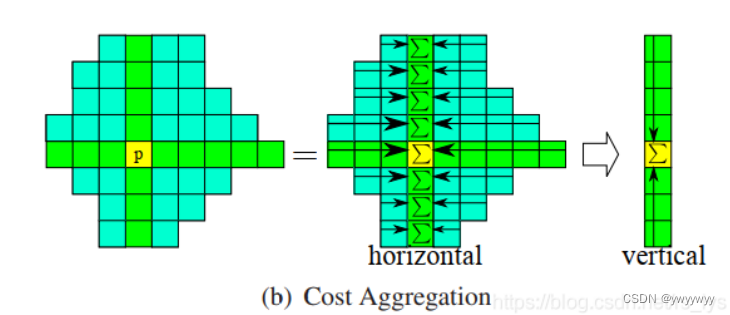
上面这段代码的总体思想如下图:
首先对每个像素做一个方向的聚合,再对每个像素的另一个方向做聚合
但是这里有个隐藏条件,就是该像素十字交叉臂区域内的像素视差相同!
如上图所示,每个像素在某个视差d下由其相邻像素的代价值聚合而成,此时其相邻像素的视差值也为d。以此计算得到视差范围内的所有代价值,最后从中选出最小代价值所对应的视差作为该像素的视差值。
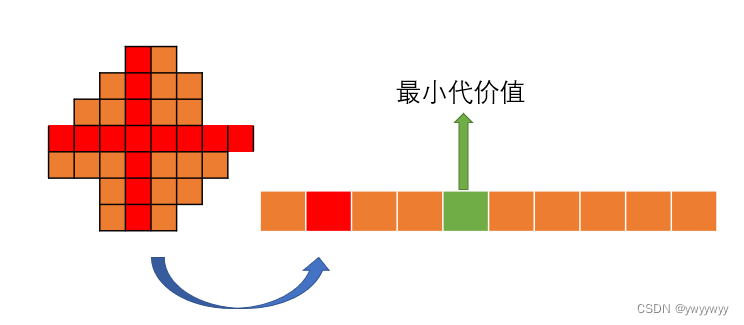
那么代价值是如何随视差变化的呢?因为在某个视差下,某些像素的代价值可能比较高,而某些像素又比较低。因此选取最优视差值的过程,其实是找到了该像素在某个视差值下,其邻域像素的代价值之和最小。