1 什么是机器学习
机器学习是一种人工智能领域的技术,它旨在让计算机通过学习数据和模式,而不是明确地进行编程来完成任务。机器学习分为
- 监督学习(Supervised Learning)
- 无监督学习(Unsupervised Learning)
- 强化学习(Reinforcement Learning)
2 监督学习
2.1 什么是监督学习
定义:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。
在监督学习中训练数据既有特征(feature)又有标签(label),通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。
简单理解:可以把监督学习理解为我们教机器如何做事情。
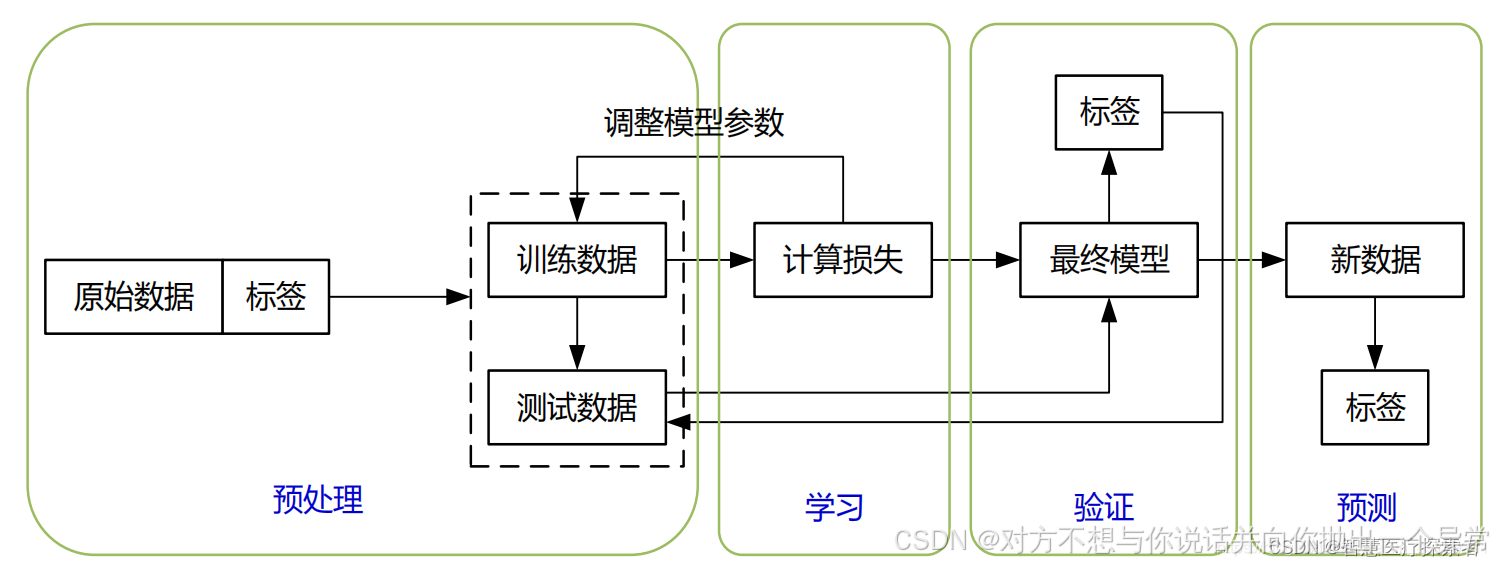
2.2 监督学习的类别
监督学习任务主要包括分类和回归两种类型,在监督学习中,数据集中的样本被称为“训练样本”,并且每个样本都有一个输入特征和相应的标签(分类任务)或目标值(回归任务)。
-
分类(Classification): 在分类任务中,目标是将输入数据分到预定义的类别中。每个类别都有一个唯一的标签。算法在训练阶段通过学习数据的特征和标签之间的关系来构建一个模型。然后,在测试阶段,模型用于预测未见过的数据的类别标签。例如,将电子邮件标记为“垃圾邮件”或“非垃圾邮件”,将图像识别为“猫”或“狗”。
-
回归(Regression): 在回归任务中,目标是预测连续数值的输出。与分类不同,输出标签在回归任务中是连续的。算法在训练阶段通过学习输入特征和相应的连续输出之间的关系来构建模型。在测试阶段,模型用于预测未见过的数据的输出值。例如,预测房屋的售价、预测销售量等。
2.3 常见的监督学习算法
监督学习算法种类众多,有着极其广泛的应用,下面是一些常见的监督学习算法:
-
支持向量机(Support Vector Machine,SVM):SVM是一种用于二分类和多分类任务的强大算法。它通过找到一个最优的超平面来将不同类别的数据分隔开。SVM在高维空间中表现良好,并且可以应用于线性和非线性分类问题。
-
决策树(Decision Trees):决策树是一种基于树结构的分类和回归算法。它通过在特征上进行递归的二分决策来进行分类或预测。决策树易于理解和解释,并且对于数据的处理具有良好的适应性。
-
逻辑回归(Logistic Regression):逻辑回归是一种广泛应用于二分类问题的线性模型。尽管名字中带有"回归",但它主要用于分类任务。逻辑回归输出预测的概率,并使用逻辑函数将连续输出映射到[0, 1]的范围内。
-
K近邻算法(K-Nearest Neighbors,KNN):KNN是一种基于实例的学习方法。它根据距离度量来对新样本进行分类或回归预测。KNN使用最接近的K个训练样本的标签来决定新样本的类别。
2.3 监督学习应用场景
监督学习是最常见的机器学习方法之一,在各个领域都有广泛的应用,它的成功在很大程度上得益于其能够从带有标签的数据中学习,并对未见过的数据进行预测和泛化。
-
图像识别:监督学习在图像识别任务中非常常见。例如,将图像分类为不同的物体、场景或动作,或者进行目标检测,找出图像中特定对象的位置。
-
自然语言处理:在自然语言处理任务中,监督学习用于文本分类、情感分析、机器翻译、命名实体识别等。
-
语音识别:监督学习在语音识别领域被广泛应用,例如将语音转换为文本、说话者识别等。
-
医学诊断:在医学领域,监督学习可以用于疾病诊断、影像分析、药物发现等。
3 无监督学习
无监督学习的特点是在训练数据中没有标签或目标值。无监督学习的目标是从数据中发现隐藏的结构和模式,而不是预测特定的标签或目标。
3.1 无监督学习类别
无监督学习的主要类别包括以下几种:
-
聚类(Clustering):聚类是将数据样本分成相似的组别或簇的过程。它通过计算样本之间的相似性度量来将相似的样本聚集在一起。聚类是无监督学习中最常见的任务之一,常用于数据分析、市场细分、图像分割等。
-
降维(Dimensionality Reduction):降维是将高维数据转换为低维表示的过程,同时尽可能地保留数据的特征。降维技术可以减少数据的复杂性、去除冗余信息,并可用于可视化数据、特征提取等。常见的降维方法有主成分分析(PCA)和t-SNE等。
-
关联规则挖掘(Association Rule Mining):关联规则挖掘用于发现数据集中项之间的关联和频繁项集。这些规则描述了数据集中不同项之间的关联性,通常在市场篮子分析、购物推荐等方面应用广泛。
-
异常检测(Anomaly Detection):异常检测用于识别与大多数样本不同的罕见或异常数据点。它在检测异常事件、欺诈检测、故障检测等领域有着重要的应用。
无监督学习在数据挖掘、模式识别、特征学习等领域中发挥着重要作用。通过发现数据中的结构和模式,无监督学习有助于我们更好地理解数据,从中提取有用的信息,并为其他任务提供有益的预处理步骤。
3.2 无监督学习算法
无监督学习算法在不同的问题和数据集上都有广泛的应用。它们帮助我们从未标记的数据中发现有用的结构和模式,并在数据处理、可视化、聚类、降维等任务中发挥着重要的作用。以下是一些常见的无监督学习算法:
-
K均值聚类(K-Means Clustering):K均值聚类是一种常用的聚类算法,它将数据样本分成K个簇,使得每个样本与所属簇中心的距离最小化。
-
主成分分析(Principal Component Analysis,PCA):PCA是一种常用的降维算法,它通过线性变换将高维数据投影到低维空间,以保留最重要的特征。
-
关联规则挖掘(Association Rule Mining):关联规则挖掘是一种发现数据集中项之间关联性的方法,它常用于市场篮子分析、购物推荐等领域。
-
异常检测(Anomaly Detection):异常检测算法用于识别与大多数样本不同的罕见或异常数据点。常见的方法包括基于统计的方法、基于聚类的方法和基于生成模型的方法等。
3.3 无监督学习应用场景
无监督学习在数据挖掘、模式识别、特征学习等应用场景发挥着重要作用。通过无监督学习,我们可以从未标记的数据中获得有用的信息和洞察力,为其他任务提供有益的预处理步骤,并且有助于更好地理解和利用数据。:
-
聚类与分组:无监督学习中的聚类算法可以帮助将数据样本分成相似的组别或簇,例如在市场细分中将顾客分成不同的群体、在图像分割中将图像区域分割成不同的物体等。
-
特征学习与降维:无监督学习的降维算法如PCA和t-SNE可以用于特征学习和可视化高维数据,例如在图像、音频和自然语言处理中,以及用于数据压缩和可视化。
-
异常检测:无监督学习中的异常检测算法可用于发现与大多数数据样本不同的罕见或异常数据点。这在欺诈检测、故障检测和异常事件监测等场景中具有重要应用。
-
关联规则挖掘:无监督学习的关联规则挖掘算法可用于发现数据集中项之间的关联性,常应用于市场篮子分析、购物推荐等领域。
4 强化学习
定义: 强化学习是让一个智能体(agent)在环境中通过尝试和错误来学习行为策略。智能体通过与环境进行交互,根据奖励信号来调整其行为策略,以达到最大化累积奖励的目标。
在强化学习中,智能体不需要明确地告诉如何执行任务,而是通过尝试和错误的方式进行学习。当智能体在环境中采取某个动作时,环境会返回一个奖励信号,表示该动作的好坏程度。智能体的目标是通过与环境交互,学习到一种最优策略,使其在长期累积的奖励最大化。
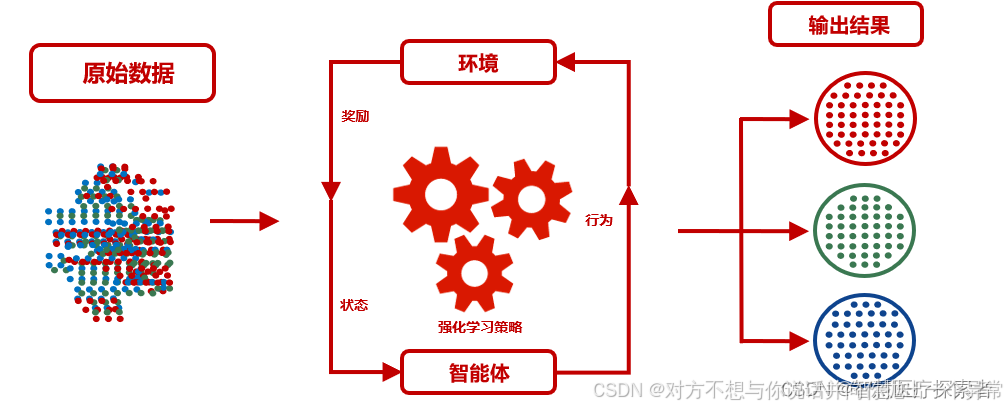
强化学习的过程可以描述为智能体与环境之间的不断交互过程
(1)智能体观察当前环境状态(state)。
(2)基于当前状态,智能体选择一个动作(action)。
(3)环境根据智能体的动作转换到新的状态,并返回一个奖励信号(reward)。
(4)智能体根据奖励信号更新其策略,以便在将来的决策中获得更好的奖励。
(5)重复以上步骤,直到智能体学习到一个使其获得最大累积奖励的策略。
5 环境安装
5.1 python环境配置
5.1.1 python下载和安装
1.下载安装包,放在文末网盘里
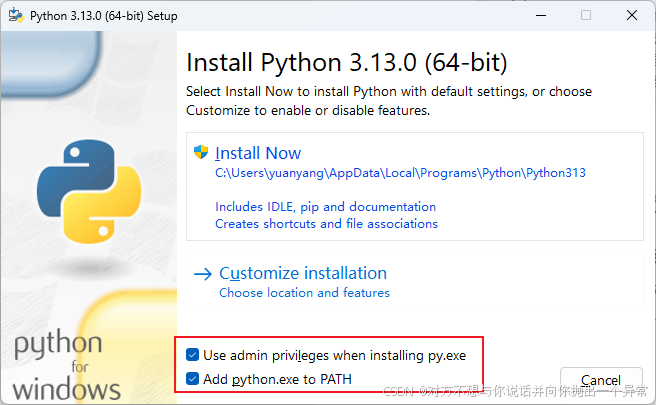
2.打开文件夹中的 python-3.13.0-amd64.exe
3.运行后勾上下图然后点击 Install Now
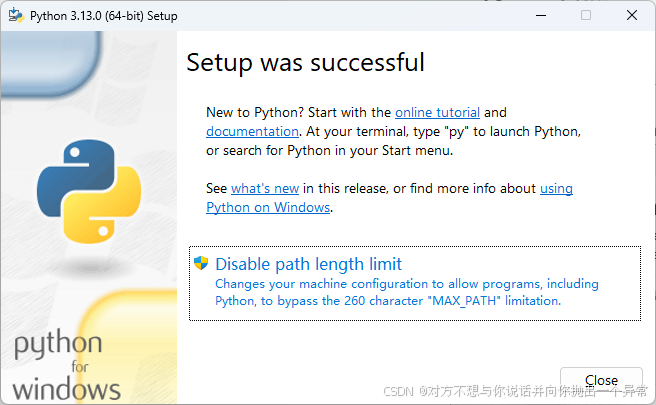
4.等待安装完毕后弹出这个页面就可以了
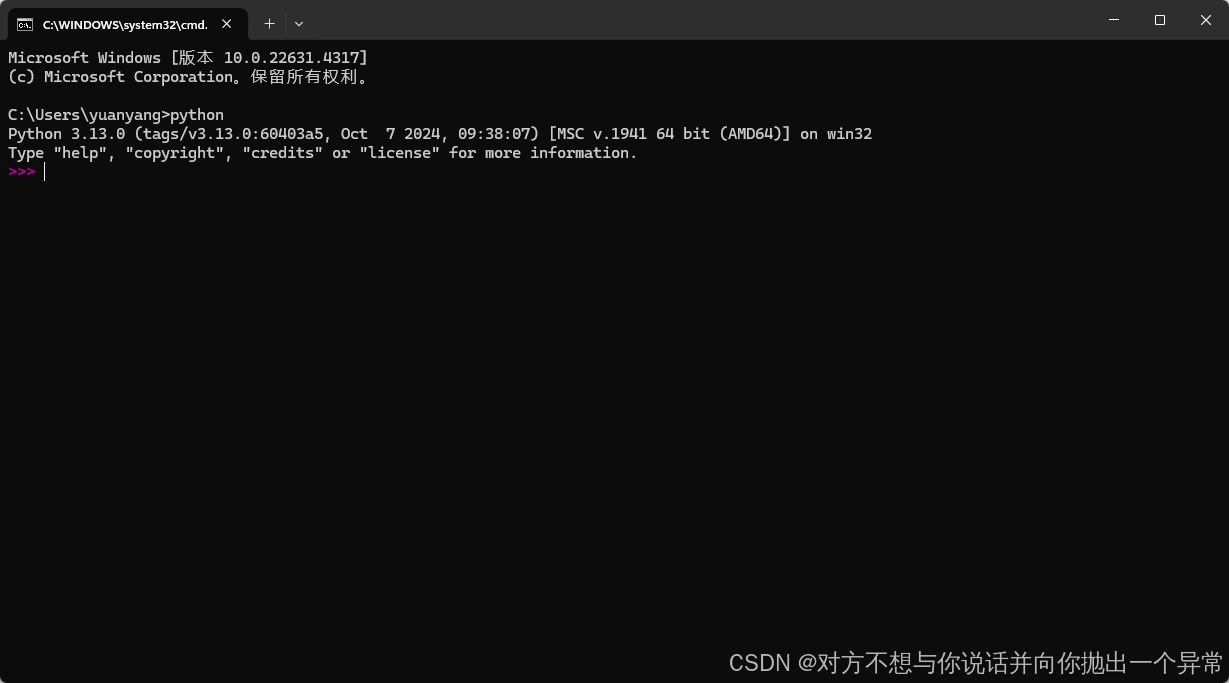
5.按windows键+R 运行输入cmd,弹出黑框输入python后输出一下内容即代表python安装正确
5.1.2 软件源配置
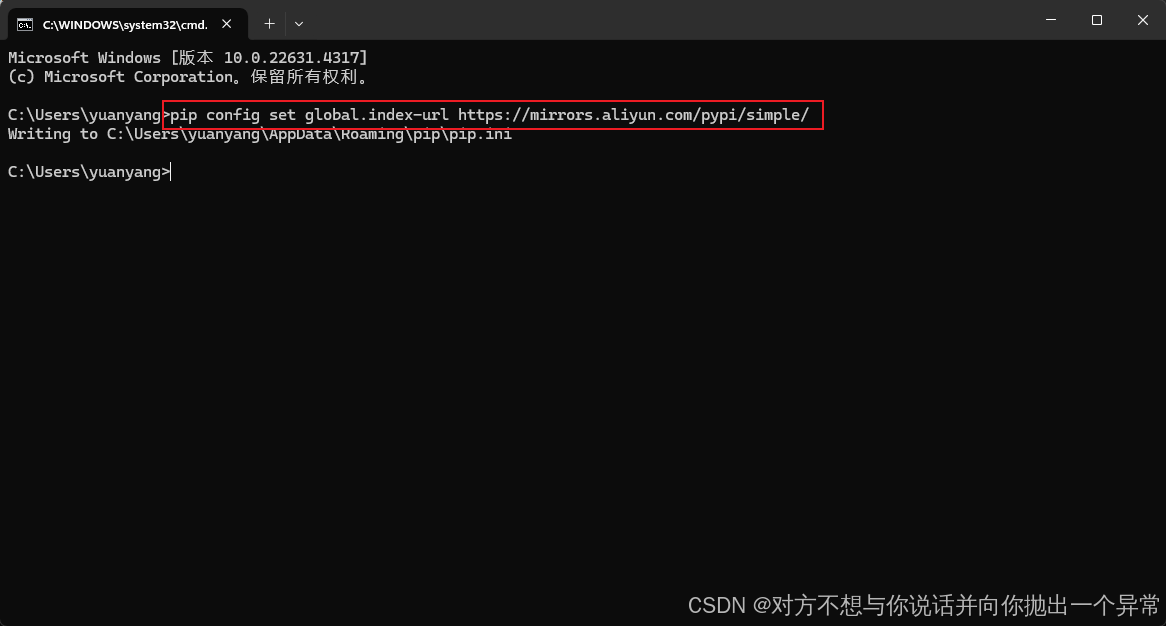
1.按windows键+R 运行输入cmd,弹出黑框输入以下内容,该方式是将相关软件包设置为国内镜像源加速后续库的下载
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple
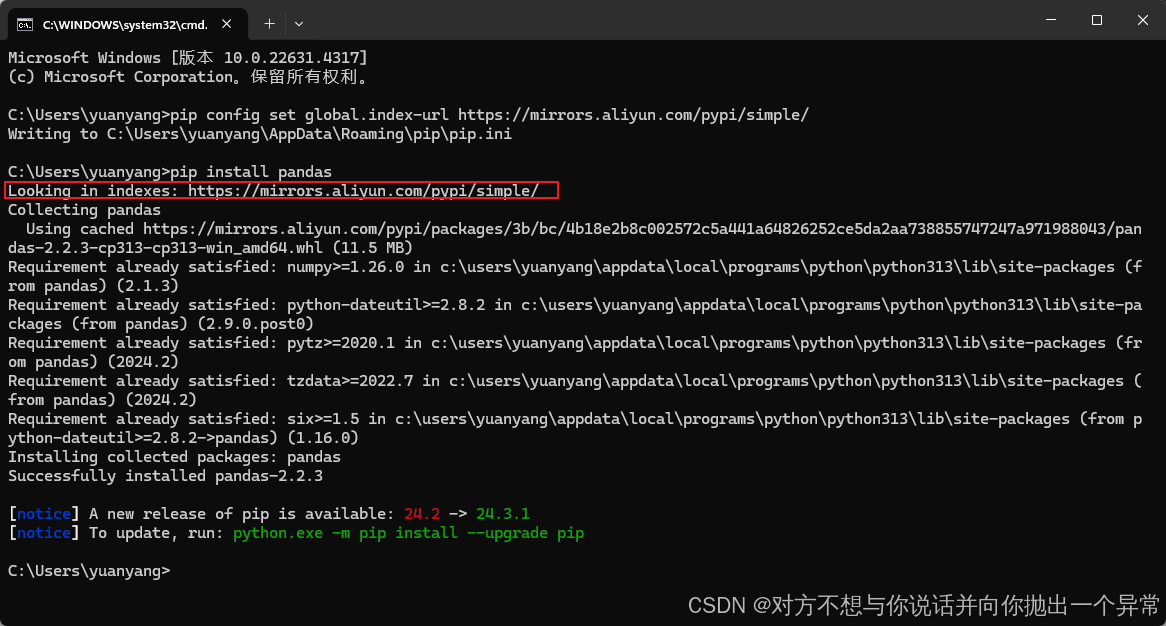
2.继续运行命令,能运行成功,并且出现aliyun的字样说明配置完成
pip install pandas
5.1.3 机器学习相关库安装
pip install pandas scikit-learn openpyxl matplotlib seaborn
5.2 IDE安装和配置
1.打开文件夹中的 pycharm-community-2024.3.exe
2.按照提示下一步,不用修改任何配置,安装路径可以自己选,等待安装完成
3.安装完成之后,打开开始菜单,应用列表,找到pycharm,或者直接搜索都可以
4.第一次打开会让选择语言和地区,一般选择英文,地区不指定就行,
5.然后点击勾上确认点击继续
6.最终打开到这个页面即可
6 第一个python代码
6.1 创建项目
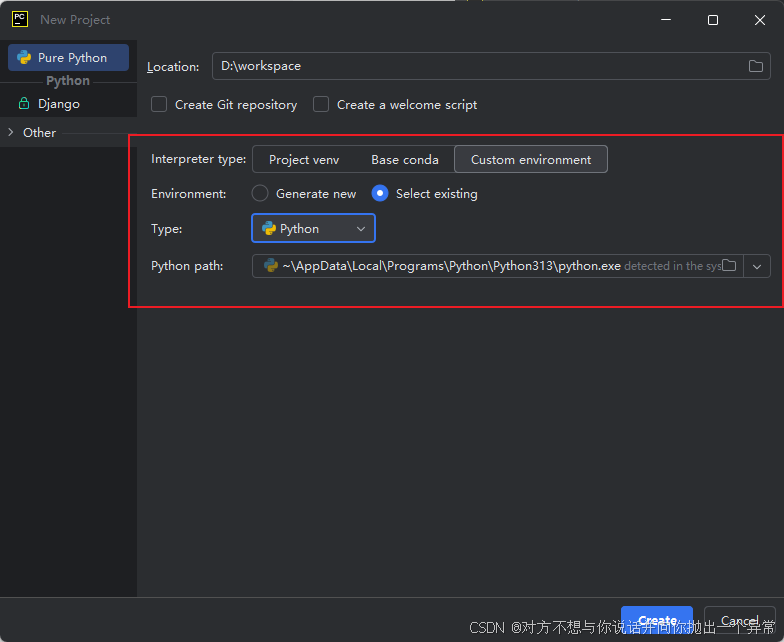
1.继续刚刚的页面,点击新建项目
2.按照我这样配置即可,下面的python路径会自动识别,然后点击create
3.我们的项目就创建好了
6.2 运行hello world
1.现在来写第一个python程序,我们要测试环境是否都正确,可以写一个helloworld代码来确认环境安装ok
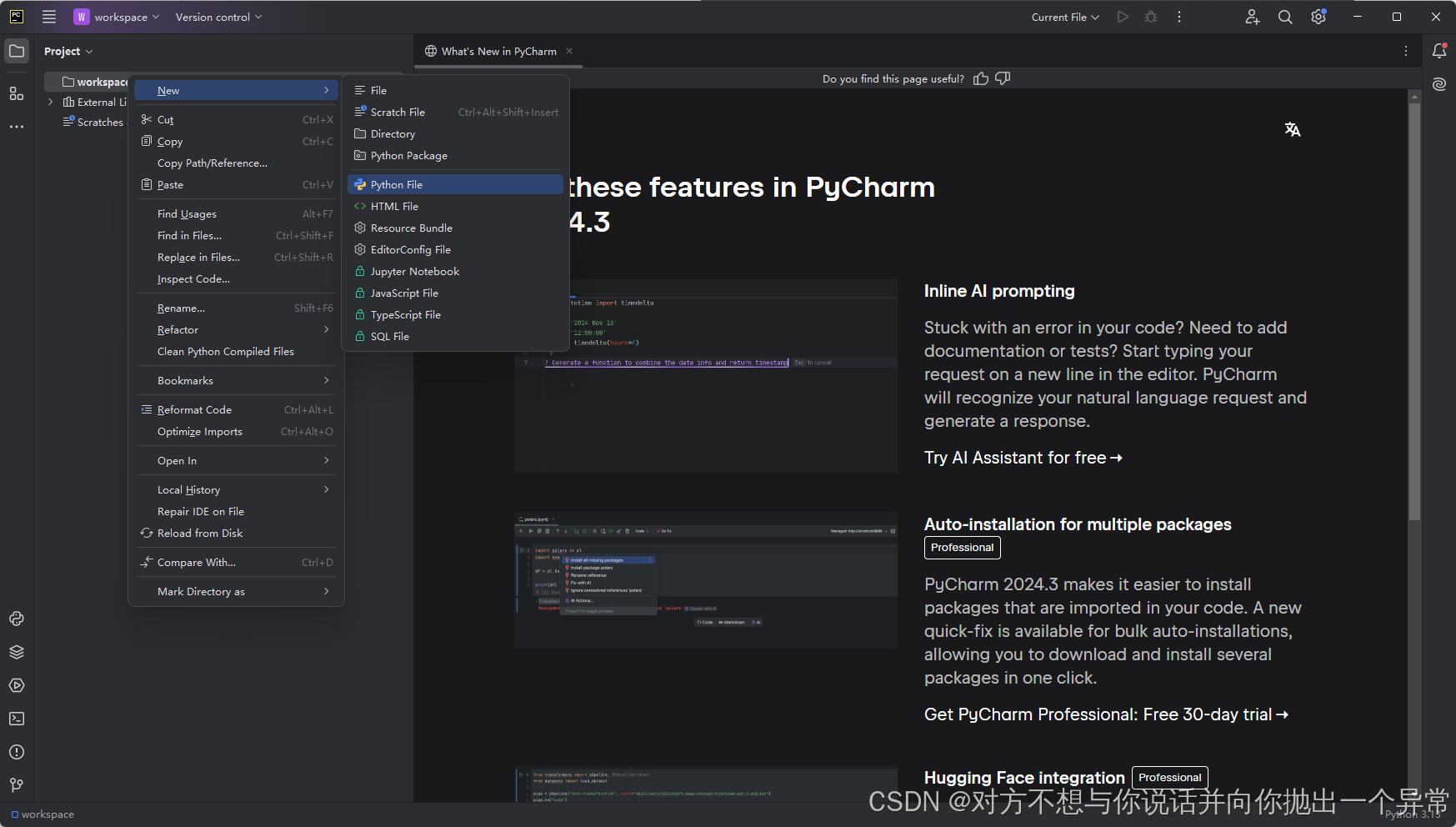
2.在左侧项目根目录右键点击 - New - Python Filem, 在弹出的框里面自定义文件名,我们可以起一个hello,然后点击回车
3.此时创建了一个项目文件了,可以看到目前项目文件内容是空的,我们输入以下代码
print("hello world")
4.右键点击hello.py文件,点击run
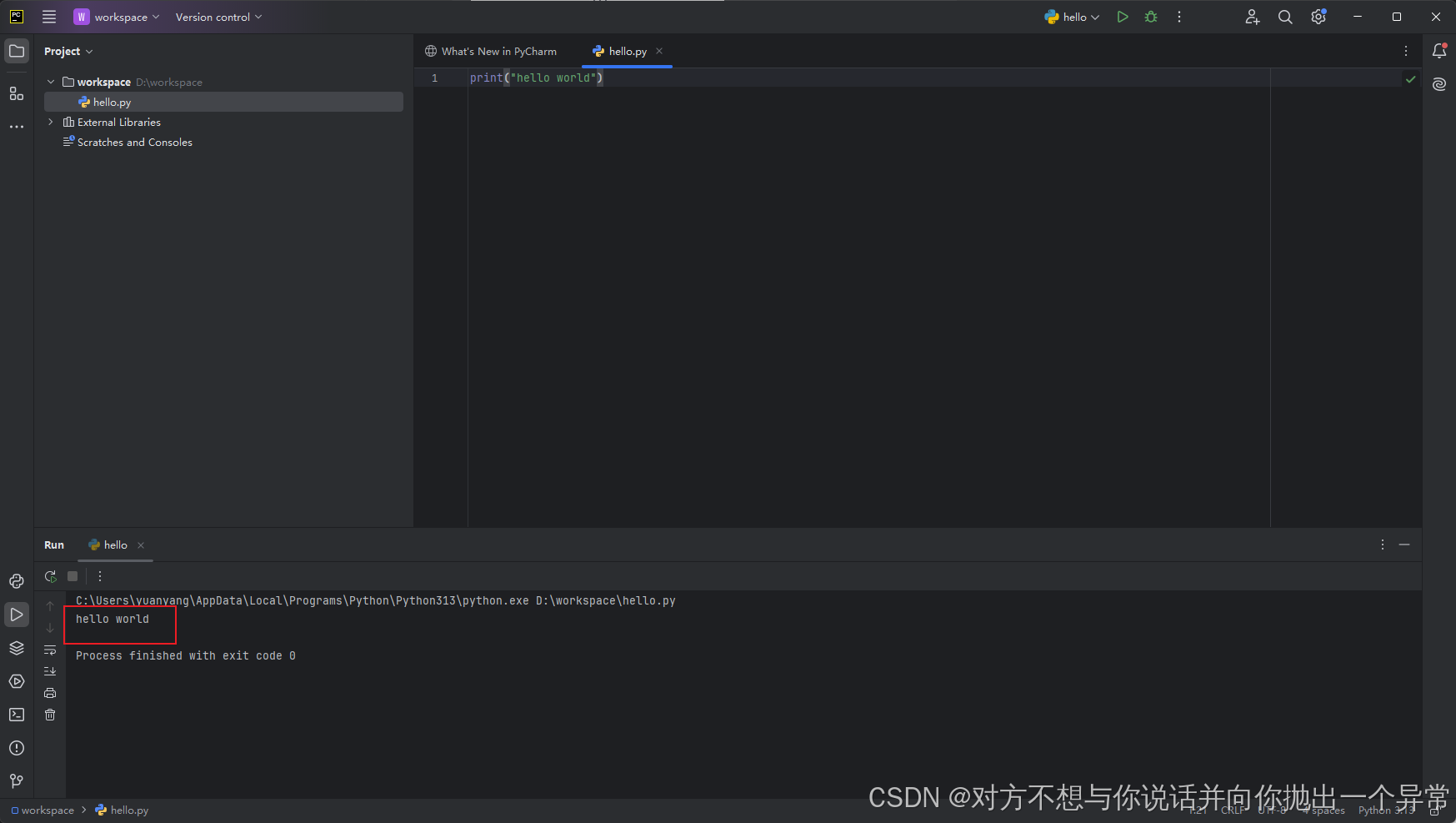
5.在控制台中看到有输出内容hello world代表python环境和IDE都安装正确了
7 例子:线性回归
7.1 下载线性回归数据集
网盘中的 “线性回归.xlsx”
7.2 创建py文件
新建ml-rl.py文件
7.3 线性回归代码
在文件中填写以下内容,其中代码中有一个数据集路径,按照你下载的数据集实际路径进行修改,注意路径分隔符为双反斜杠 \
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
file_path='C:\\Users\\yuanyang\\Desktop\\机器学习\\线性回归.xlsx'
data=pd.read_excel(file_path)
#目标列
target='房价(万)'
# 划分特征和目标变量
X = data.drop(target, axis=1)
y = data[target]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# 输出特征重要性
feature_importances = model.coef_
feature_names = X.columns
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importances})
print("Feature Importances:")
print(importance_df.sort_values(by='importance', ascending=False))
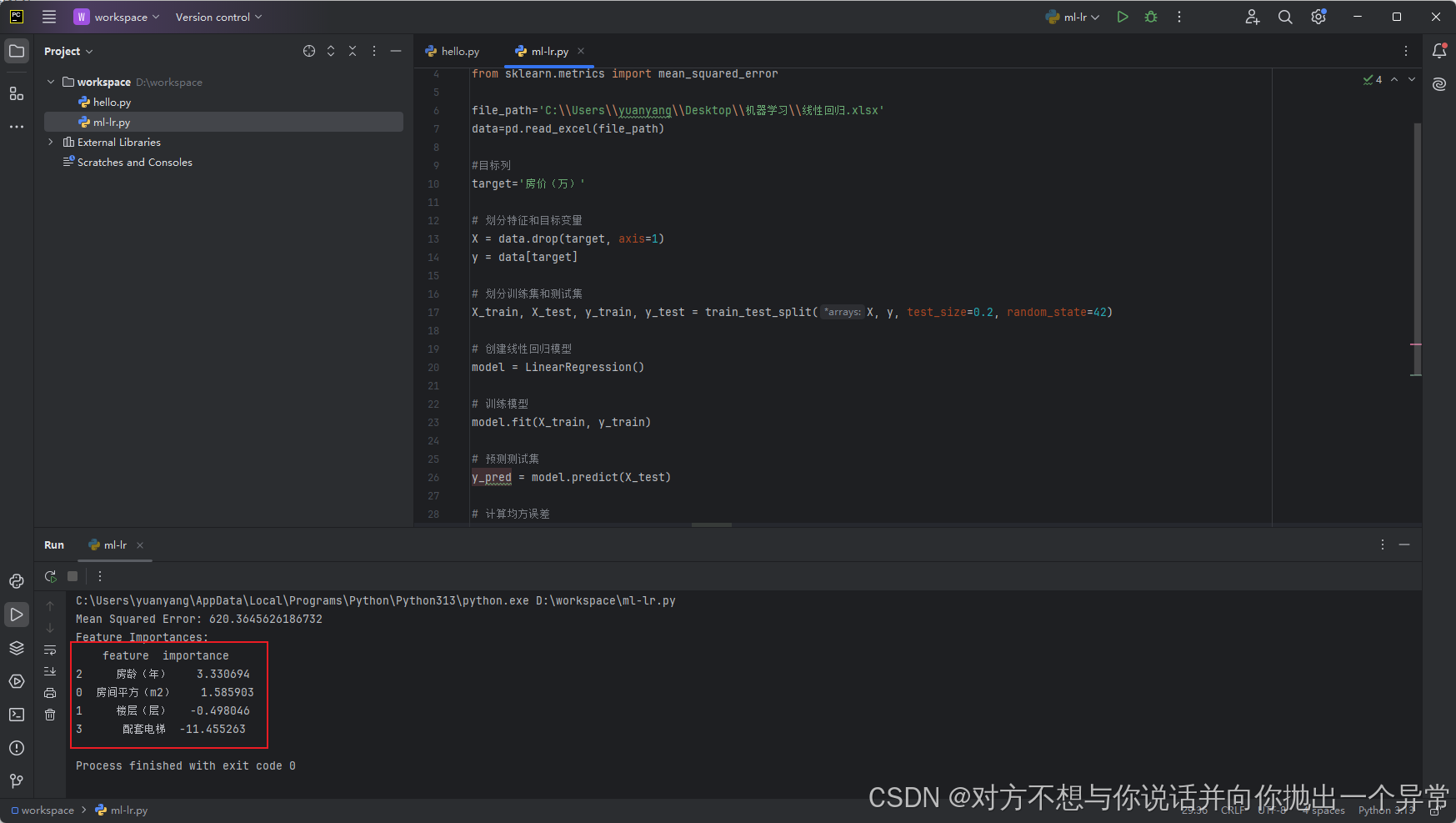
7.4 运行结果
点击运行,在下侧控制台中看到结果,可以看到几个因素对于结果所占的比重,此为线性回归的系数,从系数大小可以看到特征的重要性,并且还有方差,可以看到方差比较大,所以线性回归效果其实不太好
8 例子:随机森林回归
8.1 数据集
数据集沿用7中的
8.2 代码
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
file_path = 'C:\\Users\\yuanyang\\Desktop\\机器学习\\线性回归.xlsx'
data = pd.read_excel(file_path)
# 目标列
target = '房价(万)'
# 划分特征和目标变量
X = data.drop(target, axis=1)
y = data[target]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林回归模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
# 训练模型
rf_model.fit(X_train, y_train)
# 模型预测
y_pred = rf_model.predict(X_test)
# 计算评价指标
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"R² Score: {r2}")
# 特征重要性分析
importances = rf_model.feature_importances_
indices = np.argsort(importances)[::-1]
# 可视化特征重要性
plt.figure(figsize=(10, 6))
sns.barplot(x=importances[indices], y=X.columns[indices])
plt.title('Feature Importances in Random Forest Model')
plt.show()
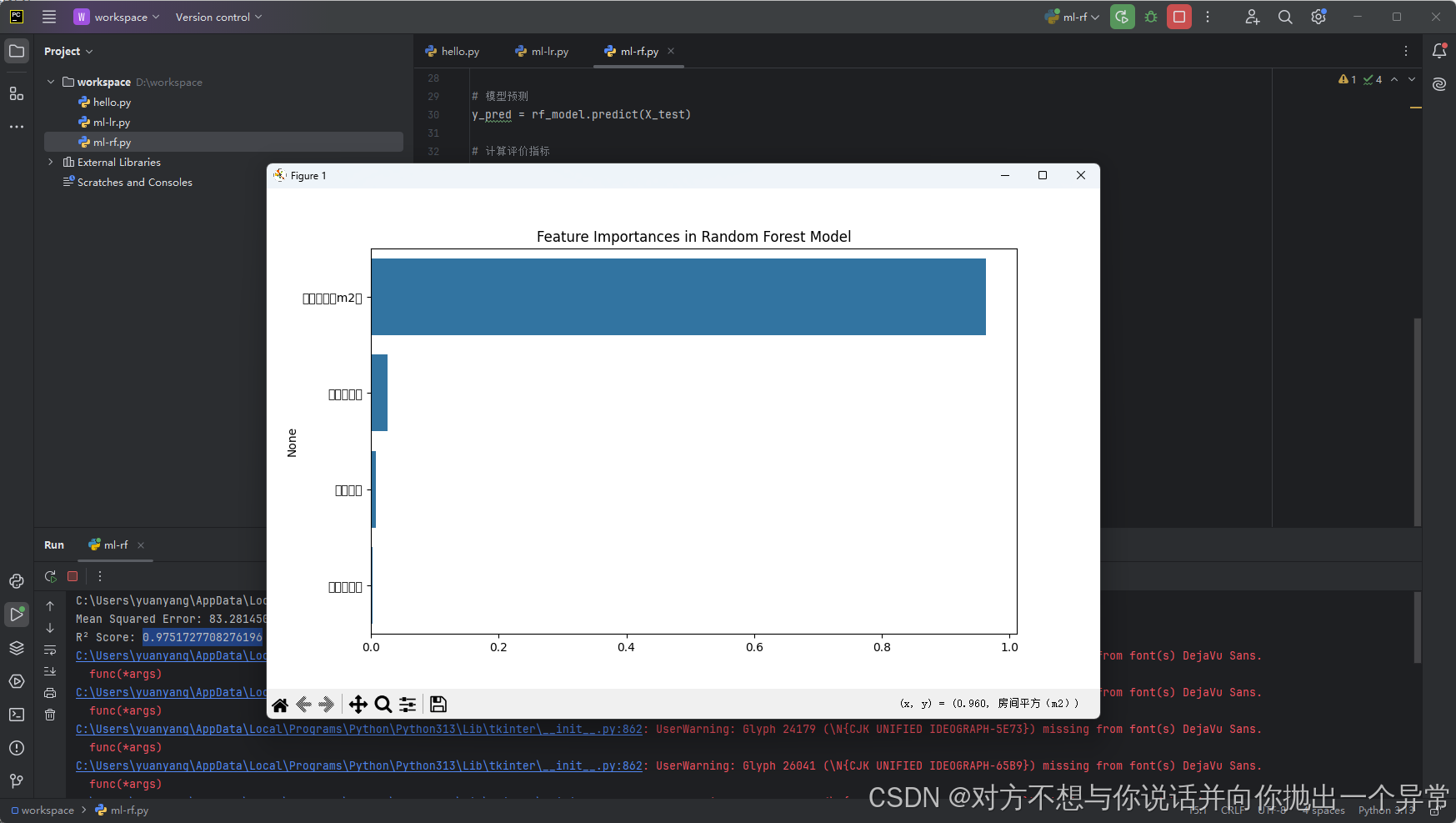
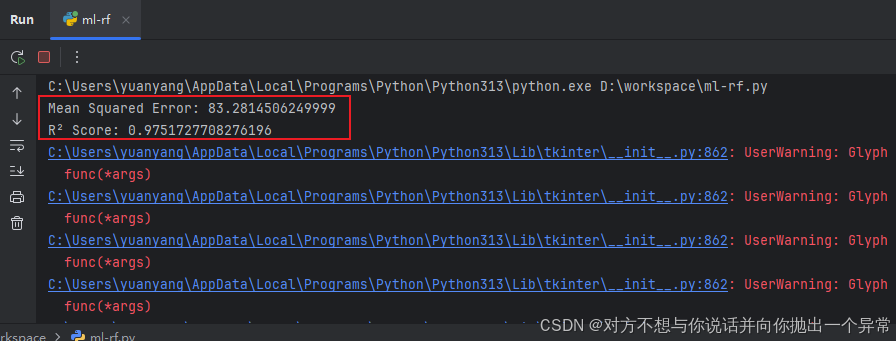
8.3 运行结果
这个图标横坐标为特征评分,纵坐标为特征,这边因为xslx中标头是中文导致这个显示有点问题,但可以分辨出来这个比重最大的参数为房房间大小,并且评分占比达到了96%,可以理解影响房价高低的最关键特征为房间大小,并且从打印的输出中可以看到方差为83,R2为0.97,关于模型的评估指标以及如何选择模型算法可以参考这一篇文章 https://zhuanlan.zhihu.com/p/669513624
9 相关附件下载
阿里云盘 https://www.alipan.com/s/ubyZR6uSSNE