sklearn中IRS数据
导入库
import pandas as pd
from sklearn.datasets import load_irisiris=load_iris()在机器学习和数据科学领域,load_iris() 函数通常是指从 scikit-learn 库中导入的,用于加载鸢尾花(Iris)数据集的函数。鸢尾花数据集是一个经典的多变量数据集,被广泛用于测试和展示机器学习算法。
type(iris)#可以当作字典来使用输出:sklearn.utils._bunch.Bunch
在
scikit-learn(通常缩写为sklearn)中,Bunch是一个简单的类,用于将数据集的相关信息组织成一个对象。Bunch对象类似于一个小型的数据库,它可以包含数据集的特征、目标、特征名称、目标名称以及其他元数据。
Bunch通常作为load_iris、load_digits等函数的返回类型,这些函数用于加载scikit-learn内置的标准数据集。Bunch使得访问数据集的不同部分变得简单和直观。以下是
Bunch对象的一些常用属性:
data: 特征数据,通常是一个NumPy数组。target: 数据集的目标值或标签。feature_names: 特征的名称列表。target_names: 目标值的名称列表。DESCR: 数据集的描述性文本。
查看数据集里有的关键字
iris.keys()输出:dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
iris["filename"]#数据集路径输出:'iris.csv'
iris[data][:10]输出:
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[5.4, 3.9, 1.7, 0.4],
[4.6, 3.4, 1.4, 0.3],
[5. , 3.4, 1.5, 0.2],
[4.4, 2.9, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.1]])查看列名和分类
#查看列名和分类名
iris["feature_names"]#特征名称输出:
下面是每个特征的含义:
sepal length (cm): 花萼长度,以厘米为单位。花萼是花的外部结构,保护花瓣在开放之前不受损害。
sepal width (cm): 花萼宽度,以厘米为单位。这是指花萼的最宽处的测量值。
petal length (cm): 花瓣长度,以厘米为单位。花瓣是植物繁殖结构的一部分,通常用于吸引传粉者。
petal width (cm): 花瓣宽度,以厘米为单位。这是指花瓣的最宽处的测量值。
这些特征通常用于鸢尾花数据集的分类任务,目的是根据这些测量值将鸢尾花分为三个不同的物种(类别):
- Iris Setosa
- Iris Versicolor
- Iris Virginica
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']pd.DataFrame(data=iris["data"],columns=iris["feature_names"])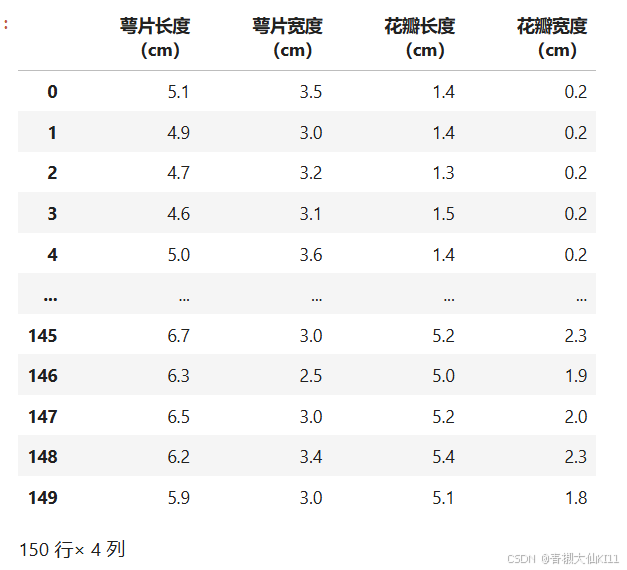
iris['target_names']输出:array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
数据和目标的shape
data=iris["data"]
type(data)输出:numpy.ndarray
data.shape输出:(150, 4)
pd.Series(target).unique()输出:array([0, 1, 2])
拆分训练集和测试集
from sklearn.model_selection import train_test_splitdata_train,data_test,target_train,target_test=\
train_test_split(data,target,test_size=0.3)#30%的数据变成测试数据另外的变成测试数据data_train.shape#包含数据和目标用来训练输出:(105, 4)
target_train.shape输出:(105,)
data_test.shape#45行的数据和目标用来测试输出:(45, 4)
使用逻辑回归训练,计算准确率
from sklearn.linear_model import LogisticRegression#逻辑回归函数model = LogisticRegression(max_iter=1000)model.fit(data_train,target_train)输出:

在测试集上实现预估
model.predict(data_test)输出:

target_pred=model.predict(data_test)target_pred.shape输出:(45,)
target_test输出:(45,)
发现问题:应该有差异性可是结果显示一样
混淆矩阵-----衡量好坏的方法
from sklearn.metrics import confusion_matrixconfusion_matrix(target_test,target_pred)#预估结果#第一类被正确预测的有19个数据
#斜线上都是预测正确的结果#那个2是第三类的花被预测成第二类的有2个数据,第二类和第三类混淆的有2个输出:

#输出和理解分类报告
from sklearn.metrics import classification_report
print(classification_report(target_test,target_pred,target_names=iris["target_names"]))输出:
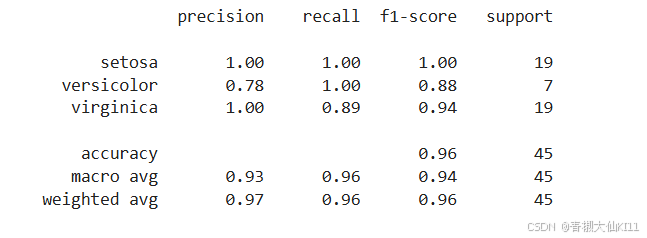
f1_score越高越好
precision(精确度): 这是“预测为正类别中实际为正类别的比例”。对于每个类别,它计算为 TP (真正例) 与 TP + FP (假正例) 的比例。高精确度意味着很少有负样本被错误地分类为正样本。
recall(召回率): 也称为“真正例率”或“灵敏度”,它是“实际为正类别中被正确预测为正类别的比例”。对于每个类别,它计算为 TP 与 TP + FN (假负例) 的比例。高召回率意味着很少有正样本被错误地分类为负样本。
f1-score(F1 分数): 精确度和召回率的调和平均值,用于衡量模型的准确性和完整性的平衡。它是 2 * (precision * recall) / (precision + recall) 的结果。
support(支持度): 在每个类别中,这是实际出现样本的数量。
具体到这个报告:
- setosa: 这个类别的模型性能非常好,精确度和召回率都是完美的(1.00)。
- versicolor: 这个类别的召回率是完美的(1.00),但精确度稍低(0.78),意味着可能有一些负样本被错误地分类为这个类别。
- virginica: 这个类别的精确度很高(1.00),但召回率稍低(0.89),意味着一些正样本被错误地分类为其他类别。
整体上:
- accuracy(准确度): 所有类别的预测中,正确预测的比例是 0.96,这意味着只有 4% 的样本被错误分类。
- macro avg: 计算每个类别的宏平均值,即对所有类别的 metric 求平均,不考虑类别样本的数量。
- weighted avg: 计算每个类别的加权平均值,其中每个类别的 metric 根据它们的 support(样本数量)进行加权。