论文:https://cdn.openai.com/papers/dall-e-2.pdf
代码:https://github.com/lucidrains/DALLE2-pytorch
摘要
像CLIP这样的对比模型已经被证明可以学习稳健的图像表征,这些特征可以捕捉到语义和风格。为了利用这些表征来生成图像,我们提出了一个两阶段的模型:一个给定文本标题生成CLIP图像embedding的先验器,以及一个以图像embedding为条件生成图像的解码器。我们表明,明确地生成图像表征提高了图像的多样性,在逼真度和标题的相似度方面损失最小。我们以图像表征为条件的解码器也能产生图像的变化,保留其语义和风格,同时改变图像表征中不存在的非必要细节。此外,CLIP的联合嵌入空间使语言指导下的图像操作能够以zreo-shot的方式进行。我们对解码器使用扩散模型,并对先验的自回归和扩散模型进行实验,发现后者在计算上更有效率,并产生更高质量的样本。
介绍
最近计算机视觉的进展是由从互联网上收集的带标题的图像的大型数据集上的扩展模型推动的,在这个框架内,CLIP已经成为一个成功的图像表示学习者。CLIP embeddings有一些理想的特性:它们对图像分布的偏移是稳健的,有令人印象深刻的zero-shot能力,并已被微调以在各种视觉和语言任务上取得最先进的结果。
同时,扩散模型作为一个有前途的生成性建模框架出现,推动了图像和视频生成任务的最先进水平。
为了达到最佳效果,扩散模型利用了一种指导技术,它以样本的多样性为代价提高了样本的保真度(对于图像来说,就是逼真度)。
在这项工作中,我们将这两种方法结合起来,用于文本条件下的图像生成问题。我们首先训练一个扩散解码器来反转CLIP图像编码器,我们的反转器是非决定性的,可以产生对应于给定图像embedding的多个图像。编码器和它的近似反向(解码器)的存在允许超越文本到图像的翻译能力。编码器和它的近似反向(解码器)的存在允许超越文本到图像的翻译能力。正如在GAN反转中,对输入图像进行编码和解码会产生语义上相似的输出图像(图3)。我们还可以通过对输入图像的图像embeddings进行反转插值来实现输入图像之间的插值(图4)。
然而,使用CLIP潜在空间的一个显著优势是能够通过在任何编码文本向量的方向移动来对图像进行语义修改(图5),而在GAN潜在空间中发现这些方向涉及到运气和勤奋的人工检查。此外,对图像进行编码和解码也为我们提供了一个观察图像的哪些特征被CLIP识别或忽略的工具。

图1:从论文模型的生产版本中选取1024×1024的样本。
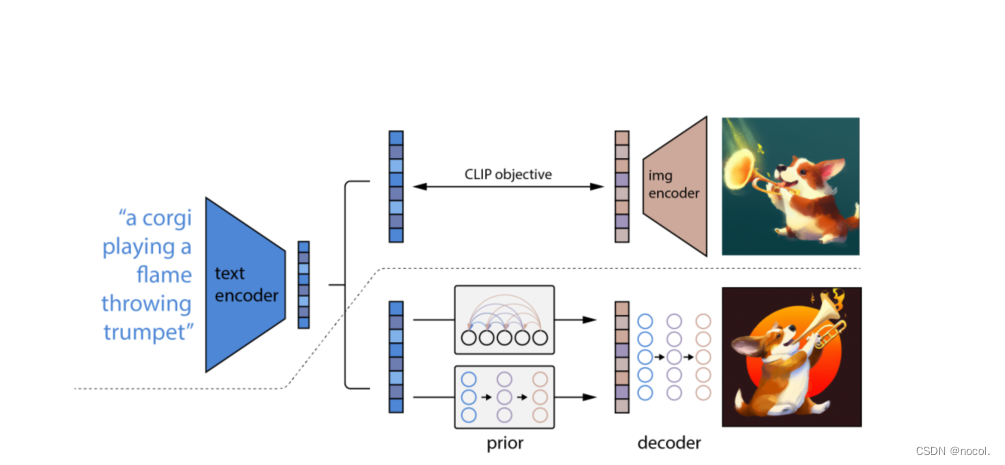
图2:unCLIP的概述。在虚线之上,我们描述了CLIP的训练过程,通过这个过程我们学习了文本和图像的联合表示空间。在虚线下面,我们描述了我们的文本到图像的生成过程:CLIP文本embedding首先被送入自回归或扩散prior,以产生一个图像embedding,然后这个embedding被用来调节扩散解码器,产生一个最终的图像。注意,在训练先验和解码器的过程中,CLIP模型被冻结。
对这张图的一点理解:
首先虚线上面是一个clip,这个clip是提前训练好的,在dalle2的训练期间不会再去训练clip,是个权重锁死的,在dalle2的训练时,输入也是一对数据,一个文本对及其对应的图像,首先输入一个文本,经过clip的文本编码模块(bert,clip对图像使用vit,对text使用bert进行编码,clip是基本的对比学习,两个模态的编码很重要,模态编码之后直接余弦求相似度了),
再输入一个图像,经过clip的图像编码模块,产生了图像的vector,这个图像vector其实是gt。产生的文本编码输入到第一个prior模型中,这是一个扩散模型,也可以用自回归的transformer,这个扩散模型输出一组图像vector,这时候通过经过clip产生的图像vector进行监督,此处其实是一个监督模型。
后面是一个decoder模块,在以往的dalle中,encoder和decoder是放在dvae中一起训练的,但是此处的deocder是单训的,也是一个扩散模型,其实虚线之下的生成模型,是将一个完整的生成步骤,变成了二阶段显式的图像生成,作者实验这种显式的生成效果更好。
这篇文章称自己为unclip,clip是将输入的文本和图像转成特征,而dalle2是将文本特征转成图像特征再转成图像的过程,其实图像特征到图像是通过一个扩散模型实现的。在deocder时既用了classifier-free guidence也用了clip的guidence,这个guidence指的是在decoder的过程中,输入是t时刻的一个带噪声的图像,最终输出是一个图像,这个带噪声的图像通过unet每一次得到的一个特征图可以用一个图像分类器去做判定,此处一般就用交叉熵函数做一个二分类,但是可以获取图像分类的梯度,利用这个梯度去引导扩散去更好的decoder。
为了获得一个完整的图像生成模型,我们将CLIP图像embeddings解码器与一个先验模型相结合,该模型从一个给定的文本标题中生成可能的CLIP图像embedding。我们将我们的文本到图像系统与其他系统如DALL-E和GLIDE进行比较,发现我们的样本在质量上与GLIDE相当,但在我们的生成中具有更大的多样性。我们还开发了在潜在空间中训练扩散先验的方法,并表明它们取得了与自回归先验相当的性能,同时计算效率更高。我们把我们的全文本条件的图像生成堆栈称为unCLIP,因为它通过倒置CLIP图像编码器来生成图像。
2.方法
我们的训练数据集由一对(x,y)图像x和它们相应的标题y组成。给定一个图像x,让zi和zt分别是其CLIP图像和文本embeddings。我们设计了我们的生成堆栈,使用两个组件从标题中产生图像。
1.根据标题y生成CLIP图像embeddings zi的先验P(zi|y)。
2.一种解码器P(x|zi,y),它生成以CLIP图像embeddings zi(以及可选的文本标题y)为条件的图像x。
解码器允许我们根据CLIP图像嵌入来反转图像,而先验允许我们学习图像嵌入本身的生成模型。将这两个组件堆叠起来,得到图像x给定标题y的生成模型P(x|y):
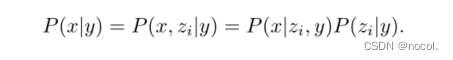
第一个等式成立是因为zi是x的确定函数。第二个等式之所以成立是因为链式法则。因此,我们可以从真实条件分布P(x|y)中进行采样,方法是首先使用3个先验值对zi进行采样,然后使用解码器对x进行采样。在下面的部分中,我们将描述解码器和先前的堆栈。
2.1解码器
我们使用扩散模型来产生以CLIP图像嵌入为条件的图像(以及可选择的文本标题)。具体来说,我们将CLIP嵌入投射到现有的时间步长的嵌入中,并将CLIP嵌入投射到四个额外的上下文标记中,这些标记被串联到GLIDE文本编码器的输出序列。 我们保留了原始GLIDE模型中存在的文本调节途径,假设它可以让扩散模型学习CLIP未能捕捉到的自然语言的各个方面(例如变量绑定),但发现它在这方面提供的帮助很小(第7节)。
虽然我们可以直接从解码器的条件分布中取样,但过去使用扩散模型的工作表明,使用对条件信息的指导可以大大改善样本质量。
我们通过在10%的时间里将CLIP嵌入随机设置为零(或学习到的嵌入),以及在训练过程中50%的时间里随机放弃文字说明来实现无分类引导。
为了生成高分辨率的图像,我们训练了两个扩散上采样模型:一个将图像从64×64的分辨率上采样到256×256,另一个将图像进一步上采样到1024×1024的分辨率。
为了提高我们的上采样器的鲁棒性,我们在训练过程中对条件图像进行了轻微的破坏。
对于第一个升采样阶段,我们使用高斯模糊,而对于第二个阶段,我们使用更多样化的BSR退化。
为了减少训练计算量并提高数值稳定性,在目标尺寸四分之一的随机图像上进行训练。我们在模型中只使用空间卷积(即没有注意层),并在推理时直接应用目标分辨率的模型,观察到它很容易泛化到更高的分辨率。
2.2先验
虽然解码器可以反转CLIP图像嵌入zi以产生图像x,但我们需要一个从标题y产生zi的先验模型,以使图像从文本标题产生。我们为先验模型探索两种不同的模型类别:
1.自回归(AR)先验:CLIP图像嵌入zi被转换为一串离散的代码,并以标题y为条件进行自回归预测。
2.扩散先验。连续矢量zi直接使用高斯扩散模型,以标题y为条件进行建模。
除了标题之外,我们还可以把先验的条件放在CLIP文本嵌入zt上,因为它是标题的一个确定性函数。为了提高样本质量,我们还通过在训练过程中随机放弃这种文本条件信息10%的时间,使采样能够使用AR和扩散先验的无分类指导。
为了更有效地训练和从AR先验中取样,我们首先通过应用主成分分析(PCA)来降低CLIP图像嵌入的维度zi。特别是,我们发现在用SAM训练CLIP时,CLIP表示空间的等级急剧减少,同时略微改善评价指标。我们能够保留几乎所有的信息,只保留了原来1,024个主成分中的319个。并使用带有因果注意掩码的Transformer模型预测所得序列。这使得推理过程中预测的标记数量减少了三倍,并提高了训练的稳定性。
我们对文字标题和CLIP文本嵌入的AR先验进行编码,将它们作为序列的前缀。此外,我们在前面加上一个标记,表示文本嵌入和图像嵌入之间的(量化的)点积,zi*zt。这使我们能够以较高的点积作为模型的条件,因为较高的文本-图像点积对应于能够更好地描述图像的标题。在实践中,我们发现从分布的上半部分取样点积是有益的。
对于扩散先验,我们在一个序列上训练一个带有因果注意掩码的纯解码器转化器,该序列依次包括:编码文本、CLIP文本嵌入、扩散时间段的嵌入、无噪声的CLIP图像嵌入,以及最后的嵌入,转化器的输出被用来预测无噪声的CLIP图像嵌入。我们不选择像AR先验中那样将扩散先验置于zi - zt上;相反,我们通过生成两个zi的样本并选择与zt有较高点积的样本来提高采样时间的质量。我们直接训练我们的模型来预测未噪声的zi,并对这个预测使用均方误差损失:


图4:通过插值他们的CLIP图像嵌入,然后用扩散模型解码两个图像之间的V ariations。我们固定每一行的解码器种子。中间的变化自然地融合了两个输入图像的内容和风格。
3.图像处理
我们的方法允许我们把任何给定的图像x编码成一个双子潜像(zi, xT),足以让解码器产生一个准确的重建。潜态zi描述了被CLIP识别的图像的各个方面,而潜态xT则编码了解码器重建x所需的所有剩余信息。前者是通过简单地用CLIP图像编码器对图像进行编码得到的。后者是通过使用解码器将DDIM反转应用于x,同时以zi为条件得到的。
3.1Variations
给定一个图像x,我们可以产生相关的图像,这些图像具有相同的基本内容,但在其他方面有所不同,如形状和方向(图3)。为了做到这一点,我们使用DDIM将解码器应用于二方表示(zi, xT),用η>0进行采样。当η=0时,解码器成为确定性的,将重建给定的图像x。较大的η值将随机性引入到连续的采样步骤中,导致在感知上以原始图像x为中心的变化。随着η的增加,这些变化告诉我们哪些信息在CLIP图像嵌入中被捕获(因此在不同的样本中被保留),哪些被丢失(因此在不同的样本中变化)。

图5:通过插值其CLIP图像嵌入和从两个描述中产生的CLIP文本嵌入的归一化差异,应用于图像的文本差异。我们还进行了DDIM反转,以完美地重建第一列中的输入图像,并固定每一行的解码器DDIM噪声。
3.2插值
也有可能混合两幅图像x1和x2的变化(图4),遍历CLIP的嵌入空间中发生在它们之间的所有概念。为了做到这一点,我们使用球面插值在它们的CLIP嵌入zi1和zi2之间进行旋转,当θ从0到1变化时,产生中间的CLIP表示ziθ=slerp(zi1,zi2,θ)。
沿着轨迹产生中间的DDIM潜点有两种选择。第一种方案是在它们的DDIM倒置潜点xT1和xT2之间进行内插(通过设置xTθ=slerp(xT1, xT2, θ)),这就产生了一个端点重建x1和x2的单一轨迹。
第二种方法是将DDIM的潜势固定为轨迹中所有插值的随机抽样值。这导致在x1和x2之间有无限多的轨迹,尽管这些轨迹的端点通常不再与原始图像重合。我们在图4中使用了这种方法。
3.3文本差异
与其他图像表征模型相比,使用CLIP的一个关键优势是,它将图像和文本嵌入到相同的潜在空间,从而使我们能够应用语言引导的图像操作(即文本差异),我们在图5中展示了这一点。为了修改图像以反映一个新的文本描述y,我们首先获得其CLIP文本嵌入zt,以及描述当前图像的标题的CLIP文本嵌入zt04。然后,我们通过取其差值和归一化,从这些文本中计算出一个文本差异向量zd = norm(zt - zt0)。现在,我们可以使用spherical interpolation在图像CLIP嵌入zi和文本扩散向量zd之间进行旋转,产生中间的CLIP表示zθ=slerp(zi, zd, θ),其中θ从0线性增加到一个最大值,通常在[0.25, 0.50]。我们通过解码插值zθ产生最终输出,在整个轨迹中把基础DDIM噪声固定为xT。

图6:具有typographic attacks 的图像的Variations与CLIP模型在三个标签上的预测概率相匹配。令人惊讶的是,即使这个标签的预测概率接近0%,解码器仍然可以恢复Granny Smith苹果。我们还发现,我们的CLIP模型比[20]中调查的模型对 "披萨 "攻击的敏感度略低。
4.探究CLIP的潜在空间
我们的解码器模型提供了一个独特的机会,通过允许我们直接可视化CLIP图像编码器所看到的东西来探索CLIP的潜在空间。作为一个用例,我们可以重新审视CLIP做出不正确预测的情况,比如字体攻击。在这些对抗性图像中,一段文字被叠加在一个物体之上,这导致CLIP预测由文字描述的物体而不是图像中描绘的物体。这段文字本质上隐藏了输出概率方面的原始对象。在图6中,我们展示了一个来自这种attack的例子,其中一个苹果可以被错误地归类为一个iPod。

图7:从逐渐增加的PCA维度(20、30、40、80、120、160、200、320维度)重建CLIP潜像的可视化,原始源图像在最右边。较低的维度保留了粗略的语义信息,而较高的维度则编码了关于场景中物体的确切形式的更精细的细节。
PCA重建提供了另一个探测CLIP潜在空间结构的工具。在图7中,我们采取了少数源图像的CLIP图像嵌入,并用逐渐增加的PCA维度来重建它们,然后用我们的解码器和固定种子上的DDIM来可视化重建的图像嵌入。这使我们能够看到不同维度所编码的语义信息。我们观察到,早期的PCA维度保留了粗粒度的语义信息,如场景中的物体类型,而后期的PCA维度则编码了更细粒度的细节,如物体的形状和具体形式。例如,在第一个场景中,早期的维度似乎编码了有食物,也许还有一个容器存在,而后期的维度则具体编码了西红柿和瓶子。图7也是AR先验建模的可视化,因为AR先验被训练为明确地预测这些主成分的顺序。
5.文本到图像的生成
5.1先验的重要性
尽管我们训练了一个先验,以便从字幕中生成CLIP图像嵌入,但先验对于字幕到图像的生成并非严格必要。例如,我们的解码器可以对CLIP图像嵌入和字幕进行调节,但在训练过程中,CLIP图像嵌入有5%的时间被放弃,以便实现无分类指导。因此,在采样时,我们可以只以标题为条件,尽管这低于完全以这种方式训练的模型(这个模型是GLIDE,我们在第5.2和5.3节与GLIDE做了彻底的比较)。另一种可能性是把CLIP的文本嵌入当作图像嵌入来喂给解码器,就像以前观察到的那样。图8的前两行描述了以这两种方式获得的样本;第三行描述了以先验获得的样本。仅以标题为条件的解码器显然是最差的,但以文本嵌入的zero-shot 为条件确实产生了合理的结果。基于这一观察,另一种方法是训练解码器以CLIP文本嵌入为条件,而不是CLIP图像嵌入(尽管我们会失去第4节中提到的能力)。
为了量化这些替代方法的有效性,我们训练两个模型:一个以CLIP文本嵌入为条件的小型解码器,以及一个小型非CLIP堆栈(扩散先验和解码器)。然后,我们比较了来自文本嵌入解码器的样本、来自unCLIP堆栈的样本,以及将文本嵌入送入unCLIP解码器zero-shot的样本,在所有模型的指导尺度上进行了扫描。我们发现,这些方法在测试集上的FID分别为9.16、7.99和16.55,表明unCLIP方法是最好的。我们还对前两种设置进行了人工评估,使用我们的人工评估代理模型(附录A)对每种设置的超参数进行了扫频采样。我们发现,人工在57.0%±3.1%的时间里喜欢完整的unCLIP堆栈,在53.1%±3.1%的时间里喜欢字幕相似度。
鉴于先验的重要性,值得对不同的训练方法进行评估。我们在整个实验中比较了AR和扩散先验。在所有情况下(第5.2、5.4和5.5节),我们发现,在可比的模型规模和减少的训练计算量方面,扩散先验优于AR先验。

图8:对同一解码器使用不同调节信号的样本。在第一行中,我们把文字标题传递给解码器,并为CLIP嵌入传递一个零矢量。在第二行,我们同时传递文字标题和CLIP文字嵌入的标题。在第三行,我们传递文本和由自回归先验生成的CLIP图像嵌入,用于给定的标题。请注意,这个解码器只在5%的时间里被训练成完成文本到图像的生成任务(没有CLIP图像表示)。
5.2人工评估
我们在图1中观察到,unCLIP能够合成复杂、真实的图像。虽然我们可以使用FID将样本质量与过去的模型进行比较,但它并不总是与人工的判断相一致。为了更好地衡量我们系统的生成能力,我们进行了系统的人工评估,将unCLIP与GLIDE在逼真度、标题相似度和样本多样性方面进行比较。
对于标题的相似性,用户还被提示有一个标题,并且必须选择与标题更匹配的图片。在这两种评价中,都有第三个 "不确定 "选项。对于多样性,我们提出了一个新的评估方案,在这个方案中,人类被呈现在两个4×4的样本网格中,并且必须选择哪个更多样化(有第三个选项,"不确定")。
对于这个评价,我们使用MS-COCO验证集的1000个标题产生样本网格,并且总是比较同一标题的样本网格。在运行人类比较之前,我们使用经过训练的CLIP线性探针对每个模型的采样超参数进行扫瞄,以作为人类逼真度评价的代理(附录A)。这些超参数在所有三种类型的评价中都是固定的。

图9:增加unCLIP和GLIDE的引导尺度时的样本,使用的提示是:"一个装满红玫瑰的绿色花瓶坐在桌子上。" 对于unCLIP,我们固定了从先验取样的潜在向量,只改变解码器的引导尺度。对于这两种模型,我们固定每一列的扩散噪声种子。来自unCLIP的样本在质量上有所提高(更真实的照明和阴影),但在内容上并没有因为我们增加引导尺度而改变,即使在高解码器引导尺度下也能保持语义多样性。
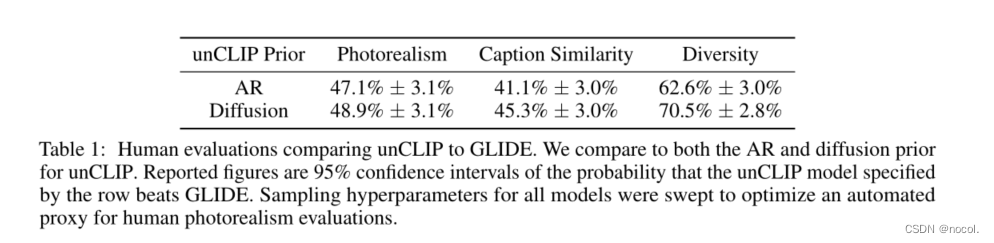
表1:人工对unCLIP和GLIDE的比较评价。我们与unCLIP的AR和扩散先验进行比较。报告中的数字是由行指定的unCLIP模型战胜GLIDE的概率的95%置信区间。所有模型的采样超参数都被扫描,以优化人工逼真度评估的自动代理。
我们在表1中展示了我们的结果。一般来说,在与GLIDE的配对比较中,扩散先验比AR先验表现得更好。我们发现,在逼真度方面,人类仍然略微偏爱GLIDE而不是unCLIP,但差距非常小。即使有相似的逼真度,unCLIP在多样性方面也比GLIDE更受青睐,这突出了它的一个优点。
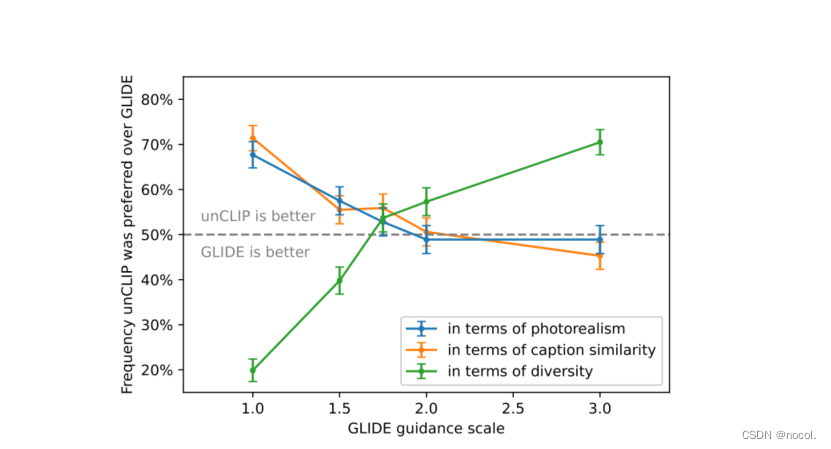
图10:当比较unCLIP(用我们的最佳采样设置)和GLIDE的各种指导尺度设置时,在每个比较中,人工评价者在逼真度、标题相似度和多样性中至少有一个轴上更喜欢unCLIP。在用于生成逼真图像的较高指导尺度下,unCLIP在可比的逼真度和标题相似度方面产生更大的多样性。
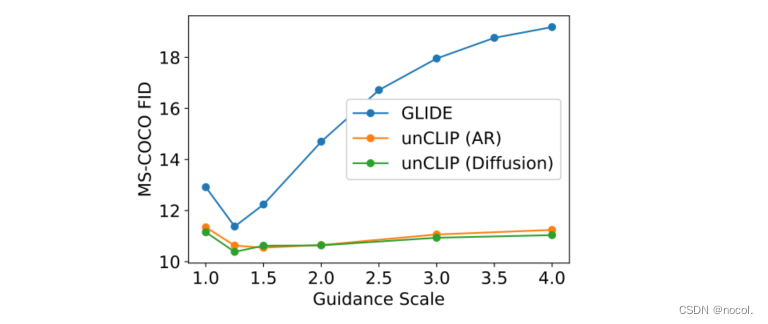
图11:unCLIP和GLIDE的FID与引导尺度的关系。对于unCLIP先验参数,我们扫过采样超参数并固定在具有最佳最小FID的设置上。
5.3改进的多样性-保真度权衡与指导
与GLIDE相比,我们从质量上观察到unCLIP能够产生更多不同的图像,同时利用引导技术来提高样本质量。为了理解原因,请看图9,在那里我们增加了GLIDE和unCLIP的引导规模。对于GLIDE,语义(相机角度、颜色、大小)随着我们增加引导规模而收敛,而对于unCLIP,场景的语义信息被冻结在CLIP图像嵌入中,因此在引导解码器时不会崩溃。
在第5.2节中,我们观察到unCLIP实现了与GLIDE相似的逼真度,同时保持了更多的多样性,但是它的标题匹配能力略差。我们很自然地会问,GLIDE的指导尺度是否可以降低,以获得与unCLIP相同的多样性水平,同时保持更好的字幕匹配能力 。在图10中,我们对这个问题进行了更仔细的研究,在GLIDE的几个指导尺度上进行了人类评价。我们发现GLIDE在引导尺度为2.0时,非常接近unCLIP的逼真度和标题相似度,而产生的样本种类仍然较少。
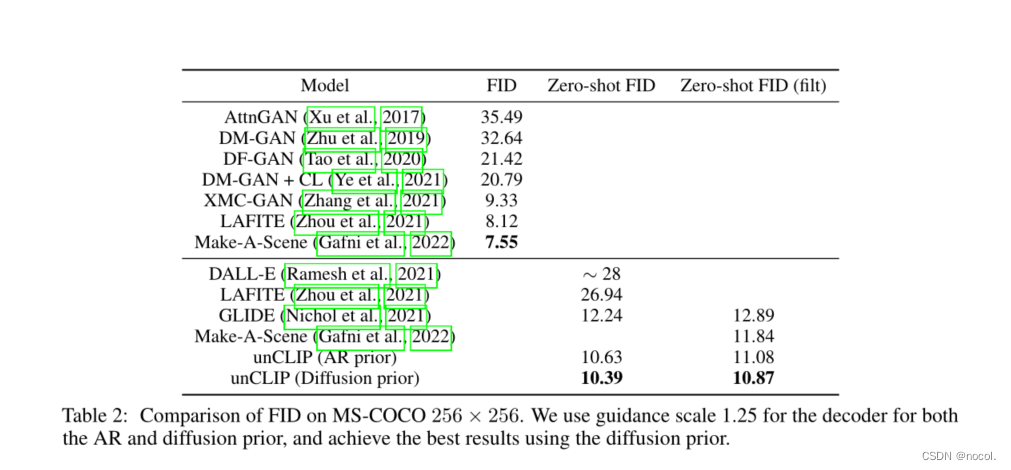
表2:MS-COCO 256×256上的FID比较。我们对AR和扩散先验的解码器都使用指导尺度1.25,使用扩散先验取得了最好的结果。
最后,在图11中,我们计算了MS-COCO的zero-shot FID,同时对unCLIP和GLIDE的引导规模进行了扫描,发现引导对unCLIP的FID的伤害比GLIDE小得多。在这个评估中,我们固定unCLIP先验的指导尺度,只改变解码器的指导尺度。
这也说明指导对GLIDE的多样性的伤害比unCLIP要大得多,因为FID严重地惩罚了非多样性的世代。
5.4 在MS-COCO的比较
在文本条件下的图像生成文献中,在MS-COCO[28]验证集上评估FID已经成为标准做法。我们在表2中介绍了这个基准的结果。像GLIDE和DALL-E一样,unCLIP没有直接在MS-COCO训练集上进行训练,但是仍然可以归纳到验证集的zero-shot。我们发现,与这些其他的零拍模型相比,unCLIP在用扩散先验取样时达到了新的最先进的FID,即10.39。在图12中,我们将unCLIP与最近在MS-COCO的几个标题上的各种文本条件图像生成模型进行了直观的比较。我们发现,和其他方法一样,unCLIP产生了捕捉文本提示的真实场景。
5.5美学质量比较
我们还对unCLIP和GLIDE进行了自动美学质量评估。我们进行这一评估的目的是评估每个模型在制作艺术插图和照片方面的表现。为此,我们使用GPT-3生成了512个 "艺术性 "标题,用现有艺术品(包括真实的和AI生成的)的标题来提示它。接下来,我们使用A V A数据集(附录A)训练一个CLIP线性探针来预测人类的审美判断。对于每个模型和一组采样超参数,我们为每个提示产生四张图片,并报告在整批2048张图片上预测的平均审美判断。
在图13中,我们展示了美学质量评估的结果。我们发现,对GLIDE和unCLIP来说,引导都能提高审美质量。对于unCLIP,我们只对解码器进行引导(我们发现引导先验会损害结果)。我们还绘制了审美质量与Recall5的对比图,因为引导通常会引起保真度和多样性之间的折衷。 有趣的是,我们发现指导unCLIP并没有降低召回率,而根据这个指标,仍然可以提高审美质量。

图12:MS-COCO提示的随机图像样本。
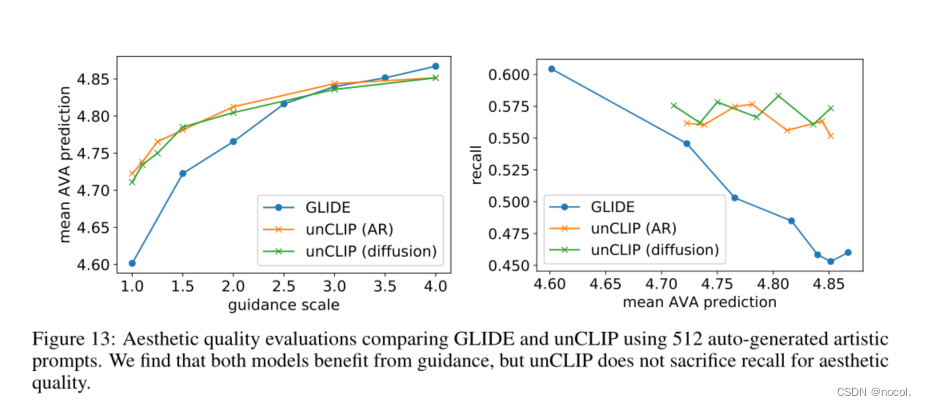
图13:使用512个自动生成的艺术提示对GLIDE和unCLIP进行审美质量评估。我们发现两个模型都从指导中受益,但是unCLIP并没有为审美质量牺牲回忆。
6.相关工作
合成图像生成是一个研究得很好的问题,大多数流行的无条件图像生成技术也被应用于文本条件的设置。以前的许多工作都在公开的图像说明数据集上训练了GANs,以产生文本条件的图像样本。
合成图像生成是一个研究得很好的问题,大多数流行的无条件图像生成技术也被应用于文本条件的设置。许多先前的工作在公开的图像标题数据集上训练GANs,以产生文本条件的图像样本。其他作品通过在文本标记后的图像标记序列上训练自回归变换器,将VQ-V AE方法适应于文本条件的图像生成。最后,一些作品将扩散模型应用于该问题,用辅助文本编码器训练连续或离散扩散模型来处理文本输入。

图14:unCLIP和GLIDE对 "一个红色立方体在一个蓝色立方体的上面 "的提示的样本。
训练以来自对比模型的图像表示为条件的扩散模型。虽然扩散模型本身不能无条件地生成图像,但作者尝试了一种简单的两阶段图像生成方法,即采用核密度估计法对图像表征进行采样。通过将这些生成的表征反馈给扩散模型,他们可以以类似于我们所提出的技术的方式,端到端生成图像。然而,我们的工作在两个方面与此不同:首先,我们使用多模态对比表征,而不是只使用图像表征;其次,我们在生成层次的第一阶段采用了强大得多的生成模型,而且这些生成模型是以文本为条件。
7.限制和风险
虽然以CLIP嵌入为条件的图像生成提高了多样性,但这种选择确实有一定的局限性。特别是,unCLIP在将属性绑定到对象上的能力比相应的GLIDE模型差。在图14中,我们发现unCLIP比GLIDE在必须将两个单独的对象(立方体)与两个单独的属性(颜色)结合起来的提示下更加艰难。我们假设这是因为CLIP嵌入本身没有明确地将属性绑定到对象上,并且发现来自解码器的重建经常将属性和对象混在一起,如图15所示。
一个类似的、可能相关的问题是,unCLIP在产生连贯的文本方面很吃力,如图16所示;可能是CLIP的嵌入没有精确地编码渲染文本的拼写信息。这个问题可能变得更糟,因为我们使用的BPE编码对模型来说掩盖了标题中单词的拼写,所以模型需要独立地看到训练图像中写出的每个标记,以便学习渲染它。
我们还注意到,我们的堆栈仍然很难在复杂场景中产生细节(图17)。我们假设这是我们的解码器层次的限制,在64×64的基本分辨率下产生一个图像,然后对其进行升采样。在更高的基础分辨率下训练我们的unCLIP解码器应该能够缓解这个问题,但要付出额外的训练和推理计算的代价。
正如GLIDE论文中所讨论的,图像生成模型具有与欺骗性和其他有害内容有关的风险。unCLIP的性能改进也提高了GLIDE的风险状况。随着技术的成熟,它留下的关于输出是人工智能生成的痕迹和指标越来越少,这使得人们更容易将生成的图像误认为是真实的图像,反之亦然。还需要对架构的变化如何改变模型在训练数据中学习偏见的方式进行更多研究。这些模型的风险应结合特定的部署环境进行评估,其中包括训练数据、到位的防护措施、部署空间以及谁将有权限。

图17:unCLIP样本对一些复杂场景显示出低水平的细节