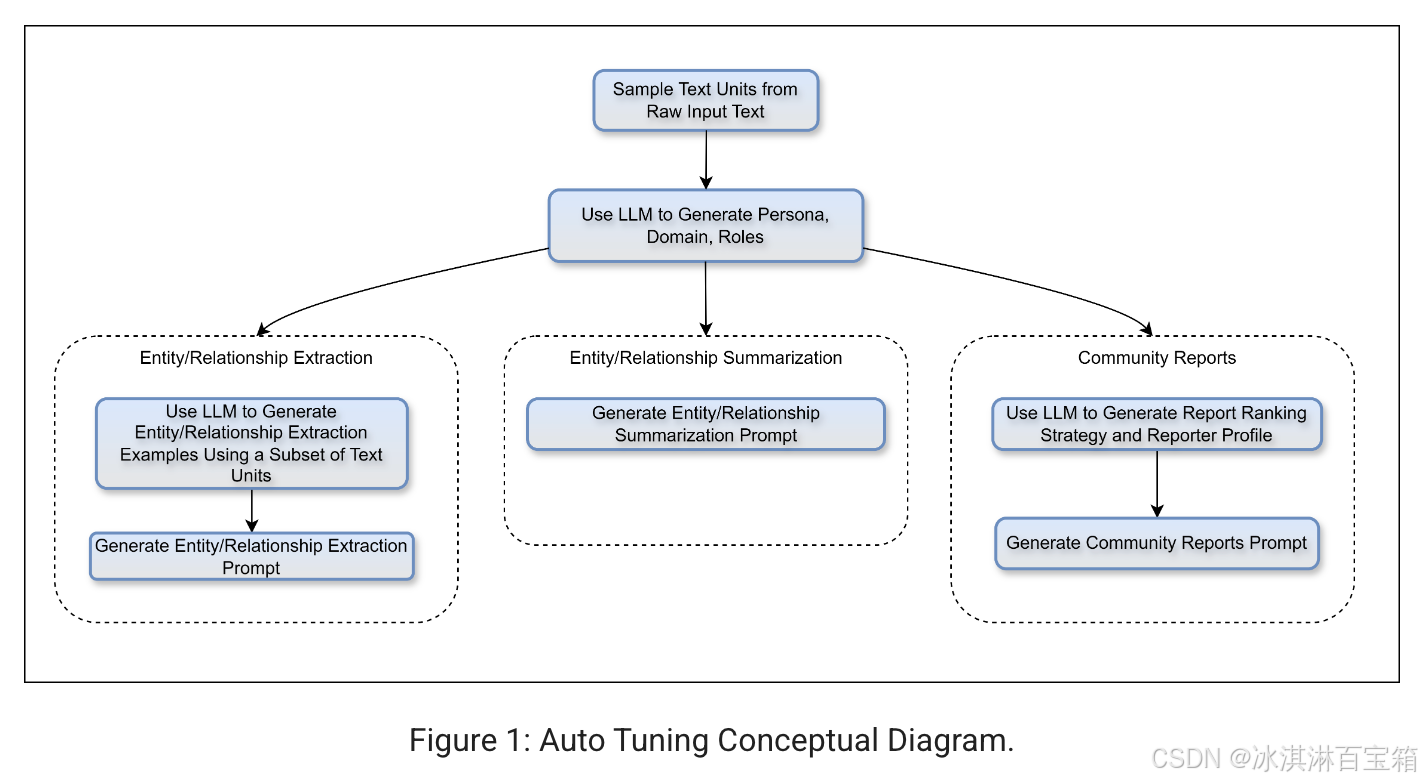
GraphRAG 的 Auto Prompt Tuning 功能是一个强大的工具,用于优化知识图谱的生成过程。以下是对该功能的详细介绍和分析:
自动提示调优(Auto Prompt Tuning)
1. 概念
GraphRAG 的自动提示调优功能旨在为特定领域的知识图谱生成创建适应性提示。这一过程通过加载输入数据,将其分割成多个文本单元(块),然后运行一系列大型语言模型(LLM)调用和模板替换,生成最终的提示。这些提示能够更好地适应特定领域的数据,从而提高生成模型的表现。
2. 先决条件
在运行自动提示调优之前,需要确保已经使用 graphrag init 命令初始化工作空间。这将创建必要的配置文件和默认提示。具体步骤如下:
sh复制
graphrag init3. 使用方法
可以通过命令行运行主脚本,并提供多种选项来执行自动提示调优。命令行的基本格式如下:
sh复制
graphrag prompt-tune [--root ROOT] [--config CONFIG] [--domain DOMAIN] [--selection-method METHOD] [--limit LIMIT] [--language LANGUAGE] \
[--max-tokens MAX_TOKENS] [--chunk-size CHUNK_SIZE] [--n-subset-max N_SUBSET_MAX] [--k K] \
[--min-examples-required MIN_EXAMPLES_REQUIRED] [--discover-entity-types] [--output OUTPUT]4. 命令行选项
-
--config(必需): 配置文件的路径,用于加载数据和模型设置。 -
--root(可选): 数据项目根目录,包括配置文件(YML、JSON或.env)。默认为当前目录。 -
--domain(可选): 与输入数据相关的领域,如“太空科学”、“微生物学”或“环境新闻”。如果留空,将从输入数据中推断领域。 -
--method(可选): 选择文档的方法,选项有all、random、auto或top。默认为random。 -
--limit(可选): 使用random或top选择时加载的文本单元数量。默认为15。 -
--language(可选): 用于输入处理的语言。如果与输入语言不同,LLM将进行翻译。默认为"",表示将自动从输入中检测语言。 -
--max-tokens(可选): 生成提示时的最大标记数。默认为2000。 -
--chunk-size(可选): 用于从输入文档生成文本单元的标记大小。默认为200。 -
--n-subset-max(可选): 使用auto选择方法时嵌入的文本块数量。默认为300。 -
--k(可选): 使用auto选择方法时选择的文档数量。默认为15。 -
--min-examples-required(可选): 实体提取提示所需的最小示例数量。默认为2。 -
--discover-entity-types(可选): 允许LLM自动发现和提取实体。当数据涵盖多个主题或高度随机化时,建议使用此选项。 -
--output(可选): 保存生成提示的文件夹。默认为"prompts"。
5. 示例用法
以下是一个完整的示例命令,展示了如何使用自动提示调优功能:
sh复制
python -m graphrag prompt-tune --root /path/to/project --config /path/to/settings.yaml --domain "environmental news" \
--method random --limit 10 --language English --max-tokens 2048 --chunk-size 256 --min-examples-required 3 \
--no-entity-types --output /path/to/output或者,使用最小配置(建议):
sh复制
python -m graphrag prompt-tune --root /path/to/project --config /path/to/settings.yaml --no-entity-types6. 文档选择方法
自动提示调优功能会读取输入数据,然后将其划分为指定大小的文本单元。接下来,它会使用以下选择方法之一来挑选样本用于提示生成:
-
random: 随机选择文本单元。这是默认且推荐的选项。 -
top: 选择前n个文本单元。 -
all: 使用所有文本单元进行生成。仅在数据集较小时使用,通常不推荐此选项。 -
auto: 在较低维空间中嵌入文本单元,并选择k个最近邻居。这在处理大型数据集时非常有用,可以选择一个具有代表性的样本。
7. 修改环境变量
运行自动提示调优后,需要修改以下环境变量(或配置变量),以便在索引运行时使用新的提示。请确保更新生成提示的正确路径,以下示例使用默认的"prompts"路径:
sh复制
GRAPHRAG_ENTITY_EXTRACTION_PROMPT_FILE = "prompts/entity_extraction.txt"
GRAPHRAG_COMMUNITY_REPORT_PROMPT_FILE = "prompts/community_report.txt"
GRAPHRAG_SUMMARIZE_DESCRIPTIONS_PROMPT_FILE = "prompts/summarize_descriptions.txt"或者在yaml配置文件中:
yaml复制
entity_extraction:
prompt: "prompts/entity_extraction.txt"
summarize_descriptions:
prompt: "prompts/summarize_descriptions.txt"
community_reports:
prompt: "prompts/community_report.txt"应用场景
自动提示调优功能在多种应用场景中都非常有用,例如:
-
学术论文分析:提取论文中的作者、出版日期、方法论、技术等实体。
-
新闻报道处理:提取新闻中的事件、人物、地点等实体。
-
医疗数据处理:提取病历中的症状、诊断、治疗等实体。
手动提示调优
虽然自动提示调优功能非常强大,但在某些情况下,可能需要手动调整提示以更好地适应特定需求。手动提示调优的步骤如下:
-
明确任务目标:确定需要从文本中识别的实体类型及其关系。
-
设计Prompt结构:编写包含任务目标、步骤、实体类型列表、示例等部分的Prompt。
-
借助AI助手生成示例:使用ChatGPT等AI助手生成示例,帮助定义实体类型和关系。
-
微调Prompt并测试:根据生成的示例和实际需求,对Prompt进行微调,并通过实际测试验证其效果。
-
应用于实际场景:将调整好的Prompt应用于实际场景,如学术论文分析、新闻报道处理等。
结论
GraphRAG 的自动提示调优功能是一个强大的工具,能够通过创建特定于领域的提示来提升知识图谱生成的效果。通过合理配置命令行选项和选择合适的文档选择方法,用户能够有效地生成高质量的提示,从而在后续的索引运行中获得更优的结果。同时,手动提示调优提供了更灵活的方式,可以进一步优化提示,以更好地适应特定需求。