关于C++11右值引用的一篇译文。在转载过程中对文章进行了排版上的一些编辑,其他内容未动。
原文链接:
01.http://cpp-next.com/archive/2009/08/want-speed-pass-by-value/
02.http://cpp-next.com/archive/2009/09/move-it-with-rvalue-references/
03.http://cpp-next.com/archive/2009/09/making-your-next-move/
04.http://cpp-next.com/archive/2009/09/your-next-assignment/
05.http://cpp-next.com/archive/2009/10/exceptionally-moving/
06.http://cpp-next.com/archive/2009/12/onward-forward/
译文链接:
01.http://blog.csdn.net/alai04/article/details/6618502
02.http://blog.csdn.net/alai04/article/details/6625754
03.http://blog.csdn.net/alai04/article/details/6627954
04.http://blog.csdn.net/alai04/article/details/6656234
05.http://blog.csdn.net/alai04/article/details/6719603
06.http://blog.csdn.net/alai04/article/details/6724345
第一篇:想要快?就传值
实话实说,你对以下这段代码有何感觉?
- std::vector<std::string> get_names();
- …
- std::vector<std::string> const names = get_names();
坦白的说,虽然我知道没那么糟,但是我还是感觉不妙。原则上,当 get_names() 返回时,我们必须复制一个含有多个 string 的 vector。然后,我们在初始化 names 的时候还要再一次复制它,最后我们还要销毁第一份拷贝。如果在 vector 中有N个 string,那么每次复制可能需要多至N+1次内存分配,而且 string 内容的复制会导致一系列缓存失效的数据访问。
为了消除这种顾虑,我通常会使用传引用的方法来避免无用的复制:
- get_names(std::vector<std::string>& out_param );
- …
- std::vector<std::string> names;
- get_names( names );
不幸的是,这种做法也很不理想。
- 代码增长了150%。
- 我们必须去掉 const,因为我们要修改 names。
- 正如函数式编程的程序员经常提醒我们的,函数参数可被改写会使代码变得复杂,原因是它破坏了引用透明性和方程式推理。
- 对于 names,我们失去了严格的值语义。
难道真的必须这样来写代码才可以提高效率吗?幸好,答案是不必如此(特别是当你使用的是C++0x时)。我们有一系列文章探讨右值以及它对于提高C++值语义效率的影响,本文是这个系列中的第一篇。
右值
右值是指创建匿名临时对象的表达式。右值的名字来自这样一个事实,内置类型的右值表达式只能出现在赋值操作符的右侧。这一点和左值不同,不带 const 的时候,左值是可以出现在赋值操作符的左侧的,右值表达式生成的对象没有任何持久的标识用来向它赋值。
不过,我们要讨论的是匿名临时对象的另一个重要特性,就是它们可以在表达式中只使用一次。你怎么可能再一次提及这样的一个对象呢?它没有名字(即“匿名”);而且在整个表达式求值完毕后,对象即被销毁(即“临时”)!
如果你知道你是从一个右值进行复制的话,你就有可能从源对象处将复制开销较高的资源“偷过来”,在目标对象中使用它们而不会有任何人留意它。在前面的例子中,就是将源 vector 中动态分配的字符串数组的所有权传递给目标 vector。如果我们可以在某种程度上让编译器来为我们执行这种“转移”操作,那么从以传值方式返回的 vector 来初始化 names 的代价就非常低——几乎为零。
以上是关于第二次复制的,那么第一次复制呢?原则上,当 get_names 返回时,必须将函数的返回值从函数的内部复制到外部。很好,返回值具有与匿名临时对象一样的特性:它们马上就会被销毁,以后也不会再被用到。所以,我们可以用相同的方法来消除掉第一次复制,将资源从函数内部的返回值处转移给函数调用者可见的匿名临时对象。
复制省略和RVO
前面提到复制的时候,我都写上“原则上”,其原因是,实际上编译器都允许基于我们已经讨论过的那些原则来执行一些优化。这一类优化通常被称为复制省略。例如在返回值优化(RVO)中,调用者函数在其栈上分配空间,然后将这块内存的地址传给被调用函数。被调用函数可以在这块内存上直接构造返回值,以消除从函数内部至外部的复制。该复制被编译器省略,或者说“消掉”。因此在以下代码中,将不需要进行复制:
- std::vector<std::string> names = get_names();
同样,当一个函数参数以传值方式传递时,虽然编译器通常被要求建立一份拷贝(所以在函数内部修改该参数不会影响到调用者),但是当源对象是右值时,也允许省略这个复制而直接使用源对象本身。
- std::vector<std::string>
- sorted(std::vector<std::string> names)
- {
- std::sort(names);
- return names;
- }
- // names is an lvalue; a copy is required so we don't modify names
- std::vector<std::string> sorted_names1 = sorted( names );
- // get_names() is an rvalue expression; we can omit the copy!
- std::vector<std::string> sorted_names2 = sorted( get_names() );
这真的很了不起。原则上,编译器可以消除在第12行中所有令人担心的复制,使得 sorted_names2 与 get_names() 中所创建的对象是同一个对象。但是在实践中,这一原则不会走得象我们所想的那么远,其原因我稍后解释。
启示
虽然复制省略从未被标准要求实现,但是我已测试过的每一个编译器的最新版本都已实现此种优化。即使你对于以传值方式返回那些重量级对象感到不舒服,复制省略还是会改变你编写代码的方式。
我们来看一下前面那个组 sorted(...) 函数的以下写法,它接受以 const 引用方式传入的 names 并进行一次显式的复制:
- std::vector<std::string>
- sorted2(std::vector<std::string> const& names) // names passed by reference
- {
- std::vector<std::string> r(names); // and explicitly copied
- std::sort(r);
- return r;
- }
虽然乍看起来 sorted 和 sorted2 是一样的,但是如果编译器实现了复制省略,它们会有巨大的性能差异。即便传给 sorted2 的实参是右值,进行复制的源对象 names 也是一个左值,因此复制不能被优化掉。从某种意义上说,复制省略是分离编译模式的牺牲品:在 sorted2 函数体内部,没有任何关于传给函数的实参是否为右值的信息;而在外部的调用点,也没有迹象显示该实参最终会被复制。
这一事实直接将我们引至出以下指引:
指引:不要复制你的函数参数。而应该以传值的方式来传递它,让编译器来做复制。
最坏的情况下,如果你的编译器不支持复制省略,性能也不会更坏。而最好的情况下,你会看到性能的极大提升。
你可以立即应用该指引的一个地方就是赋值操作符。规范的、易写的、保证正确的、强异常保证的、复制并交换的赋值操作符通常会这样写:
- T& T::operator=(T const& x) // x is a reference to the source
- {
- T tmp(x); // copy construction of tmp does the hard work
- swap(*this, tmp); // trade our resources for tmp's
- return *this; // our (old) resources get destroyed with tmp
- }
但是通过以上对复制省略的讨论,可以知道这种写法显然是低效的!显而易见,现在正确编写一个复制并交换的赋值操作应该是:
- T& operator=(T x) // x is a copy of the source; hard work already done
- {
- swap(*this, x); // trade our resources for x's
- return *this; // our (old) resources get destroyed with x
- }
真的假不了
当然,天下没有免费的午餐,所以我还有以下说明。
首先,当你以引用方式传递一个参数并在函数体内对其进行复制时,复制构造函数是从一个集中的地方被调用的。但是,当你以传值方式传递一个参数时,编译器为其生成的对复制构造函数的调用是位于每一次对左值进行传递的调用点。如果该函数在多个地方被调用,且代码大小或局部性是你的应用程序的关键重点,这的确会是一个问题。
另一方面,也可以很容易地建立一个包装函数,将复制局部化:
- std::vector<std::string>
- sorted3(std::vector<std::string> const& names)
- {
- // copy is generated once, at the site of this call
- return sorted(names);
- }
由于反之并不成立——你不能通过包装来取回已失去的复制省略的机会——所以我建议你还是要从前面的指引开始,然后仅在发现必须要做的时候才改变它。
其次,我还没有发现有哪个编译器可以在函数返回其参数时进行复制省略,正如我们的 sorted 实现。你可以想象一下如何进行这些复制省略:没有某种形式的跨函数优化,sorted 的调用者无从知晓其参数(而不是其它对象)最终会被返回,所以编译器必须在栈上分别为参数和返回值分配不同的空间。
如果你要返回一个函数的参数,你还是可以获得近似最优的性能,方法是与一个缺省构造的返回值进行交换(所提供的缺省构造函数和交换函数必须该是低开销的,通常也是如此):
- std::vector<std::string>
- sorted(std::vector<std::string> names)
- {
- std::sort(names);
- std::vector<std::string> ret;
- swap(ret, names);
- return ret;
- }
第二篇:用右值引用来转移
这是关于C++中的高效值类型的系列文章中的第二篇。在上一篇中,我们讨论了复制省略如何被用来消除可能发生的多次复制操作。复制省略是透明的,在看起来非常普通的代码中自动发生的,几乎没有任何缺点。好消息已经够多了;下面看看坏的消息:
- 复制省略不是标准强制要求的,因此你写不出可以保证它会发生的可移植代码。
- 有些时候这也做不到。例如:
被调用者最多可以将调用者传入的内存用于 var1 或 var2 其中一个。如果它选择将 var1 保存在该内存中,而 q 为 false,那么 var2 还是要被复制(反之亦然)。
- return q ? var1 : var2;
- 复制省略很有可能超出编译器的栈空间分配技巧的能力。
低效转移
当一个操作是要对数据进行重排时,有很多机会可以进行优化。以一个简单的泛型插入排序算法为例:
- template <class Iter>
- void insertion_sort(Iter first, Iter last)
- {
- if (first == last) return;
- Iter i = first;
- while (++i != last) // Invariant: elements preceding i are sorted
- {
- Iter next = i, prev = i;
- if (*--prev > *i)
- {
- typename std::iterator_traits<Iter>::value_type x(*next);
- do *next = *prev;
- while(--next != first && *--prev > x);
- *next = x;
- }
- }
- }
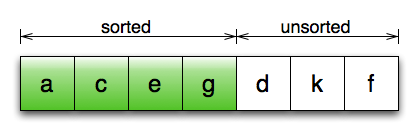
第7行:外层循环的不变式
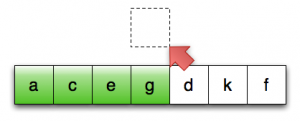
第12行:将第一个未排序元素复制至临时位置
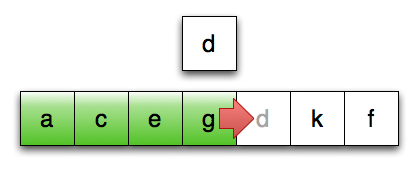
第13行:将最后一个已排序元素复制向后复制
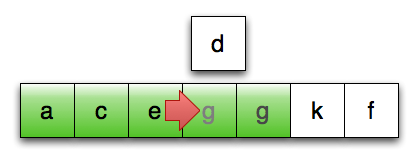
第13行:继续向后复制,直至找到合适位置
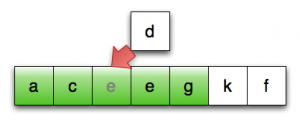
第15行:将临时位置的元素复制至正确位置
想象一下,如果进行排序的序列中的元素是 std::vector<std::string>,会发生什么:在第12、13、15行,我们要潜在地复制一个字符串 vector,这会导致大量的内存分配和数据复制。
由于排序操作从根本上说,是一种数据守恒的操作,所以这些数据复制的开销应该都是可避免的:原则上,我们真正要做的就是将对象在序列中移来移去。
对于这些高代价的复制操作,要留意的一个重点是,在所有情况下,源对象的值都不会再被使用。听起来很熟悉吧?是的,当源对象是右值时也是如此。不过这次源对象是左值:这些对象都是有地址的。
引用计数可以吗?
解决这类低效问题的一个常用方法是,在堆上分配元素并在序列(容器)中持有指向这些元素的引用计数智能指针,而不是直接保存这些元素。引用计数智能指针跟普通的指针类似,只是它还跟踪了有多少引用计数智能指针指向同一个对象,并且会在最后一个智能指针被删时销毁对象。复制一个引用计数指针只需递增其引用计数即可,这是很快的。对引用计数指针赋值则是递增一个引用计数且递减另一个。这也是很快的。
那么,还可以更快吗?当然是根本就不进行计数!另外,引用计数还有其它一些我们希望避免的弱点:
- 它的开销在多线程环境中是非常大的,因为计数本身要跨线程共享,这就需要同步。
- 在泛型代码中该方法要失效,因为元素的类型有可能是象 int 这样的轻量型类型。在这种情况下,引用计数的增减才是真正的性能开销。你要么忍受这种开销,要么就必须引入一个复杂的框架来确定哪些类型是轻量型的,应该直接保存,同时还要以统一的风格来访问这些值。
- 引用语义会使得代码难以阅读。例如:
将 s2 变为大写同时会修改到 s1 的值。这是一个比我们在这里讨论的要大得多的主题,简而言之,当数据共享被隐藏时,看似局部的修改,其效果却不一定是完全局部的。
- typedef std::vector<std::shared_ptr<std::string> > svec;
- …
- svec s2 = s1;
- std::for_each( s2.begin(), s2.end(), to_uppercase() );
引入C++0x的右值引用
为了解决这些问题,C++0x 引入了一种新的引用,右值引用。T 的右值引用写作 T&&(读作“tee ref-ref”),我们现在将原来的 T& 引用称为“左值引用”。就我们讨论的范围而言,左值引用与右值引用的主要区别在于,非 const 的右值引用可以绑定至右值。许多C++程序员都曾经遇到过这样的错误提示:
- invalid initialization of non-const reference of type 'X&'
- from a temporary of type 'X'
这类提示通常是由以下这样的代码引起的:
- X f(); // call to f yields an rvalue
- int g(X&);
- int x = g( f() ); // error
标准规定,非 const 的(左值)引用应绑定至一个左值,而不是一个临时对象(即一个右值)。这是有意义的,因为对引用所引向的临时对象进行的任何修改都肯定会丢失。与之相反,非 const 右值引用应绑定至一个临时对象,而不是一个左值:
- X f();
- X a;
- int g(X&&);
- int b = g( f() ); // OK
- int c = g( a ); // ERROR: can't bind rvalue reference to an lvalue
偷取资源
假设我们的函数 g() 要保存一份它的参数的拷贝,以备后用:
- static X cache;
- int g(X&& a)
- {
- cache = a; // keep it for later
- }
- int b = g( X() ); // call g with a temporary
依赖于类型 X,这个复制可能是开销很大的操作,可能引起内存分配和许多子对象的深度复制。
由于 g() 的参数是一个右值引用,我们知道它只能自动绑定到匿名临时对象,而不是其它对象。因此,
- 在我们把这个临时对象复制到 cache 之后不久,被复制的源对象就会被销毁。
- 我们对这个临时对象的任何修改,对于程序的其它地方都是不可见的。
这给了我们一个机会来执行一些新的优化,通过修改临时对象的值来避免多余的工作。最为常见的一种优化就是资源偷取。
资源偷取是指从一个对象取走资源(如内存、大的子对象)并将资源转移给另一个对象。例如,string 类可能拥有一个在堆上分配的字符缓冲区。复制一个 string 需要分配一块新的缓冲区并将所有字符复制到新的缓冲区中,这看起来很慢。而偷取一个 string 则只需要让另一个对象取走这个 string 的缓冲区并通知源对象它不再拥有有效的缓冲区——这个操作要快很多。使用右值引用,我们可以通过把从临时对象复制改为从临时对象偷取,来优化我们的代码。同时,由于只有临时对象被改变,所以这个优化在逻辑上是无改写的。
说明:从右值引用偷取(或修改)可以在逻辑上视为无改写操作。
右值重载用法
从以上说明我们可以得到一个新的维持语义的编程变化:我们可以用另一个在同一位置接受右值引用的版本来对接受一个(const)引用参数的任意函数进行重载:
- void g(X const& a) { … } // doesn't mutate argument
- void g(X&& a) { modify(a); } // new overload; logically non-mutating
g 的第二个重载版本可以修改它的参数,但不会对程序的其它地方产生影响,所以它具有与第一个重载版本相同的语义。
绑定与重载
下表总结了 C++0x 对于引用绑定与重载的完整规则:
| 表达式→ 引用类型↓ | T 右值 | const T 右值 | T 左值 | const T 左值 | 优先级 |
| T&& | X | 4 | |||
| const T&& | X | X | 3 | ||
| T& | X | 2 | |||
| const T& | X | X | X | X | 1 |
“优先级”一列描述了这些引用在重载决议中的行为。例如,给出以下重载:
- void f(int&&); // #1
- void f(const int&&); // #2
- void f(const int&); // #3
把一个 const int 类型的右值传入 f,将会调用#2,因为#1无法绑定而#3的优先级较低。
声明一个可转移的类型
有了以上方法,我们可以通过两个新的操作,转移构造和转移赋值,来令任意类型的右值成为可隐式转移的,这两个操作都是接受右值引用参数。例如,一个可转移的 std::vector 在 C++0x 中可能会这样写:
- template <class T, class A>
- struct vector
- {
- vector(vector const& lvalue); // copy constructor
- vector& operator=(vector const& lvalue); // copy assignment operator
- vector(vector&& rvalue); // move constructor
- vector& operator=(vector&& rvalue); // move assignment operator
- …
- };
转移构造函数和转移赋值操作符的工作就是从它的参数中“偷取”资源,然后将参数置于一个可析构或可赋值的状态。
在 std::vector 的例子中,这可能意味着将其参数置回空容器的状态。一个典型的 std::vector 实现包含有三个指针:一个指向已分配空间的起始,一个指向最后一个元素,还有一个指向已分配空间的结尾。所以,当容器为空时,这三个指针均为 null,转移构造函数会象这样:
- vector(vector&& rhs)
- : start(rhs.start) // adopt rhs's storage
- , elements_end(rhs.elements_end)
- , storage_end(rhs.storage_end)
- { // mark rhs as empty.
- rhs.start = rhs.elements_end = rhs.storage_end = 0;
- }
而转移赋值操作符可能会是这样:
- vector& operator=(vector&& rhs)
- {
- std::swap(*this, rhs);
- return *this;
- }
由于右值参数会马上被销毁,所以交换操作不仅获取它的资源,同时还将我们本来拥有的资源“安排好”准备销毁。
注意:先别太高兴,这个转移赋值操作符还不是很正确。
右值引用与复制省略
std::vector 的转移构造函数的开销非常低(大约只有对内存的3次读和6次写),但也还不是免费的。幸好,标准列明了复制省略(这是真正无代价的)的优先级高于转移操作。当你把一个右值以传值方式进行传递时,或是从某个函数返回一个值时,编译器首先应选择消除复制。如果复制不能被消除,而相应的类型又具有转移构造函数,编译器就被要求使用转移构造函数。最后,如果连转移构造函数都没有,编译器就只能使用复制构造函数了。
举例:
- A compute(…)
- {
- A v;
- …
- return v;
- }
- 如果 A 具有可访问的复制构造函数或转移构造函数,则编译器可以选择消除复制
- 否则,如果 A 具有转移构造函数,则 v 被转移
- 否则,如果 A 具有复制构造函数,则 v 被复制
- 否则,编译器报错
因此,上一篇文章中的指引依然有效:
指引:不要复制你的函数参数。而应该以传值的方式来传递它,让编译器来做复制。
以这个指引的提示下,你可能会问:“除了转移构造函数和转移赋值操作符,我还可以在哪里使用右值重载用法呢?一旦我的所有类型都是可转移的,那么还有什么要做的呢?”请看以下例子。
从左值转移
所有的这些转移优化都具有一个共通点:当我们不再使用源对象时才可以进行优化。但是有些时候,我们需要提醒一下编译器。例如:
- void g(X);
- void f()
- {
- X b;
- g(b);
- …
- g(b);
- }
在第8行中,我们以一个左值来调用 g,这样就不能进行资源偷取——即使我们知道 b 已不会再被用到。为了告诉编译器可以从 b 进行转移,我们可以用 std::move 来传递它:
- void g(X);
- void f()
- {
- X b;
- g(b); // still need the value of b
- …
- g( std::move(b) ); // all done with b now; grant permission to move
- }
注意,std::move 本身并不做任何转移。它只是将参数变为一个右值引用,以便于在符合“转移优化”的环境中可以采用转移优化。当你看到 std::move 时,你可以这样想:授予转移的权限。你也可以将 std::move(a) 看作是 static_cast<X&&>(a) 的描述方式。
高效转移
现在我们有办法对左值进行转移了,我们可以将前几节中的 insertion_sort 算法优化一下:
- template
- void insertion_sort(Iter first, Iter last)
- {
- if (first == last) return;
- Iter i = first;
- while (++i != last) // Invariant: [first, i) is sorted
- {
- Iter next = i, prev = i;
- if (*--prev > *i)
- {
- typename std::iterator_traits::value_type
- x( std::move(*next) );
- do *next = std::move(*prev);
- while(--next != first && *--prev > x);
- *next = std::move(x);
- }
- }
- }
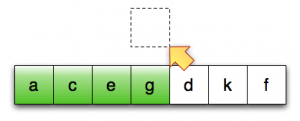
第12行:将第一个未排序元素移至临时位置
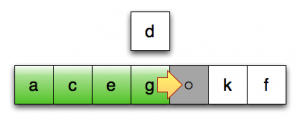
第13行:将最后一个已排序元素向后移
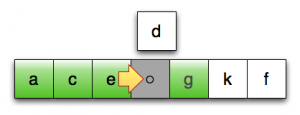
第13行:继续后移
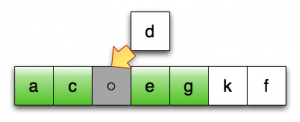
第15行:将临时位置中的元素移至正确位置
除了格式上的差异以外,这个版本与前一个的区别仅在于增加了对 std::move 的调用。值得指出的是,我们只需要这一个 insertion_sort 的实现,不论元素类型是否具有转移构造函数。这是典型的可转移代码:右值引用的设计是让你“在可以的时候转移,有必须的时候复制”。
第三篇:你的下一步转移
这是关于C++中的高效值类型的系列文章中的第三篇。在上一篇中,我们介绍了C++0x的右值引用,描述了如何建立一个可转移类型,并示范了如何显式地利用可转移性。现在我们来看看转移优化的其它一些机会,开拓一些关于转移方面的新领域。
复活一个右值
在开始讨论进一步的优化之前,我们要先了解,一个匿名的右值引用是右值,而一个命名的右值引用则是左值。我把它写下来以便你记得更清楚:
切记:一个命名的右值引用是左值。
我承认这有点不合情理,但是请看以下例子:
- int g(X const&); // logically non-mutating
- int g(X&&); // ditto, but moves from rvalues
- int f(X&& a)
- {
- g(a);
- g(a);
- }
如果我们把 f 中的 a 视为右值,那么第一次对 g 的调用将会从 a 进行转移,第二次调用将会看到一个被修改过的 a。这不仅是反直觉的;而且它违反了一个保证,即调用 g 不会有可见的对任何东西的修改。所以,一个命名的右值引用是和其它引用一样的,只有匿名的右值引用才被特殊对待。为了给第二次的 g 调用一个机会进行转移,我们必须如下重写:
- #include <utility> // for std::move
- int f(X&& a)
- {
- g(a);
- g( std::move(a) );
- }
要记得 std::move 本身并不进行转移。它只是将其参数转换为匿名右值引用,这样接下来就可以进行转移。
二元操作符
转移语义对于优化二元操作符的使用尤其有用。考虑以下代码:
- class Matrix
- {
- …
- std::vector<double> storage;
- };
- Matrix operator+(Matrix const& left, Matrix const& right)
- {
- Matrix result(left);
- result += right; // delegates to +=
- return result;
- }
- Matrix a, b, c, d;
- …
- Matrix x = a + b + c + d;
每一次调用 operator+ 时,都要执行 Matrix 的复制构造函数来创建 result。因此,即使RVO可以消除返回时对 result 的复制,上述表达式还要是进行三次 Matrix 的复制(每个 + 各一次),每次都要构造一个很大的 vector。复制省略可以让这些 result 矩阵中的一个与 x 成为同一个对象,但是另外两个还是要被销毁的,这是额外的开销。
我们可以写一个令这个表达式表现更好的 operator+,这种方法在C++03中也是可以的:
- // Guess that the first argument is more likely to be an rvalue
- Matrix operator+(Matrix x, Matrix const& y)
- {
- x += y; // x was passed by value, so steal its vector
- Matrix temp; // Compiler cannot RVO x, so
- swap(x, temp); // make a new Matrix and swap
- return temp;
- }
- Matrix x = a + b + c + d;
一个可以尽可能消除复制的编译器按此实现可以做到近似最优的结果,只创建一个临时对象并将其内容直接转移给 x。但是,以下这种难看的写法可以很容易地让我们的优化失效:
- Matrix x = a + (b + (c + d));
实际上,这比我们原来的实现更糟糕:现在右值总是出现在 + 号的右边而被显式地复制。左值却总是出现在左边,但由于它是传值的,所以隐式的复制无法被消除,这样我们得到了六次复制的代价。
不过,有了过右值引用,我们可以通过在原有实现上增加一些重载来进行可靠的优化工作:
- // The "usual implementation"
- Matrix operator+(Matrix const& x, Matrix const& y)
- { Matrix temp = x; temp += y; return temp; }
- // --- Handle rvalues ---
- Matrix operator+(Matrix&& temp, const Matrix& y)
- { temp += y; return std::move(temp); }
- Matrix operator+(const Matrix& x, Matrix&& temp)
- { temp += x; return std::move(temp); }
- Matrix operator+(Matrix&& temp, Matrix&& y)
- { temp += y; return std::move(temp); }
只可转移的类型
有些类型确实不应该被复制,但是以传值方式传递它们、从函数返回它们、把它们保存在容器中却又非常有意义。一个你可能很熟悉的例子就是 std::auto_ptr<T>:你可以调用它的复制构造函数,实际上但却并没有进行复制。相反...进行了转移!从方程式推理来讲,以复制语义从左值进行转移甚至比引用语义更为糟糕。如果从容器中复制一个值会改变原序列的话,那么对一个 auto_ptr 的容器进行排序有什么意义。
由于这些原因,原标准明确禁止将 auto_ptr 放入标准容器中,而且在C++0x中 auto_ptr 已被淘汰。取而代之的是一个不能复制只能转移的新型智能指针:
- template <class T>
- struct unique_ptr
- {
- private:
- unique_ptr(const unique_ptr& p);
- unique_ptr& operator=(const unique_ptr& p);
- public:
- unique_ptr(unique_ptr&& p)
- : ptr_(p.ptr_) { p.ptr_ = 0; }
- unique_ptr& operator=(unique_ptr&& p)
- {
- delete ptr_; ptr_ = p.ptr_;
- p.ptr_ = 0;
- return *this;
- }
- private:
- T* ptr_;
- };
unique_ptr 可以被放在标准容器中,也可以做 auto_ptr 能做的任意事情,除了隐式地从左值转移。如果你想从左值转移,你只要用 std::move 来传递它即可:
- int f(std::unique_ptr<T>); // accepts a move-only type by value
- unique_ptr<T> x; // has a name so it's an lvalue
- int a = f( x ); // error! (requires a copy of x)
- int b = f( std::move(x) ); // OK, explicit move
C++0x中的其它只可转移的类型还包括流类型、线程和锁(新的多线程支持),所有的标准容器都可以持有只可转移的类型。
第四篇:再论赋值
这是关于C++中的高效值类型的系列文章中的第四篇。在上一篇中,我们讨论了如何处理右值引用函数参数并介绍了只可转移的类型。这次,我们重温一下转移赋值,并且看看如何才能正确并高效地把它写出来。
在本系列文章的第二篇中,我们示范了一个 vector 转移赋值的实现,但其中隐藏着一个微妙的问题。以下列代码为例:
- mutex m1, m2;
- std::vector<shared_ptr<lock> > v1, v2;
- v1.push_back(shared_ptr<lock>(new lock(m1)));
- v2.push_back(shared_ptr<lock>(new lock(m2)));
- v2 = v1; // #1
- …
- v2 = std::move(v1); // #2 - Done with v1 now, so I can move it
- …
赋值#1释放了 v2 所独占的所有锁(并让 v2 成为 v1 所拥有的所有东西的共用者)。但是赋值#2并没有即时效果,除了交换各自的锁拥有权。在#2的情况下,原来由 v2 所持有的锁不会释放,直至 v1 离开其范围域,这可能是很久很久以后。上锁与解锁的顺序与否是正确的多线程程序和死锁之间的区别,所以这是一个严重的问题,我们前面的关于转移赋值的描述需要加以修正:
转移赋值的语义:转移赋值操作符从“偷取”它的参数的值,将该参数置于可析构和可赋值的状态,并保留左操作数的任何用户可见的副作用。
有了以上指引的帮助,现在我们可以修改我们对 std::vector 的转移赋值实现:
- vector& operator=(vector&& rhs)
- {
- this->clear();
- std::swap(*this, rhs);
- return *this;
- }
在实践中,最先的 clear() 通常没有什么作用(也没有什么开销),因为转移赋值的目标通常已经是空的了,通常它本身就是前面某次转移赋值的源对象。在大多数标准算法以及前面我们作为了一个例子的插入排序算法中,这确实是真的。不过,加上这一个 clear() 可以在向一个非空的左操作数进行转移赋值时避免麻烦。
规范性的赋值?
正如前一篇所提到的,复制赋值有一种“规范性的实现”,基于一次复制构造和一次交换:
- T& operator=(T rhs) { swap(*this, rhs); return *this; }
它有很多好处:
- 很容易写对
- 与“手工实现”相比,极大地减少了复杂度
- 利用了复制省略
- 提供了强异常保证,如果 swap 是无抛出的
只要你实现了转移构造和廉价、无抛出的交换,以上也可以看作是一个好的转移赋值操作符的实现。右值参数可以转移构造至 x 然后交换给 *this。华而不实!如果你已经使用了规范的复制赋值操作符,毕竟你可能就不需要再写一个转移赋值操作符了。
这就是说,即使是在C++03中,这种“规范实现”往往过早地从左值进行复制。对于 std::vector 的情形,在赋值号左边的对象也许有足够的空间,你只需要销毁其中的元素然后将右边的元素复制过来就可以了,这样可以避免一次昂贵的内存分配,而且如果源 vecotr 非常大的话,可能会导致内存不足。
所以,std::vector 使用了一种更为经济的赋值操作符,其签名为 vector& operator=(vector const&),该实现允许将左值的复制延迟至已确认了必须要复制之后。不幸的是,如果我们试图将这个规范的复制赋值签名用于右值的话,将产生歧义的重载。相反,我们需要类似的东西,即效果相同但是将临时对象的生成移至赋值操作符之内:
- vector& operator=(vector&& rhs)
- {
- vector(std::move(rhs))
- .swap(*this);
- return *this;
- }
看上去,这确实就是转移赋值语义的泛型实现,不过这里有另外一个问题。我们来计算一下这个操作的总开销:
- 第3行:3次内存读和4-6次的内存写(视实现而定)
- 第4行:6次读和6次写
- 第5行:*this 原用内容的析构
现在来和“清除后交换”的实现比较一下:
- vector& operator=(vector&& rhs)
- {
- this->clear();
- std::swap(*this, rhs);
- return *this;
- }
- 第3行:*this 原用内容的析构
- 第4行:6次读和6次写
回想一下早前我们提到过的,多数(甚至可能是绝大多数)转移赋值的左操作数是一个刚刚被转移走的对象。在一般情形下,析构 *this 原用内容——通过 clear 或是通过临时对象的析构——的开销只是单次的测试和跳转。所以,其它的操作是主要开销,而“清除后交换”的实现要比另一个实现差不多快上两倍。
实际上,我们可能还可以做得更好。是的,理论上 swap 操作可以让我们回收利用左操作数的空间而不是过早地把它处理掉,但实际问题是该什么时候做呢?答案是仅当从一个已被 std::move 的左值进行赋值的时候,因为真正的右值很快会被销毁。那么有多大机会左操作数真的有足够空间呢?机会不大,因为左操作数通常都是一个刚刚被转移走的对象。因此,以下这样的实现有可能是真正最高效的:
- vector& operator=(vector&& rhs)
- {
- if (this->begin_)
- {
- this->destroy_all(); // destroy all elements
- this->deallocate(); // deallocate memory buffer
- }
- this->begin_ = rhs.begin_;
- this->end_ = rhs.end_;
- this->cap_ = rhs.cap_;
- rhs.begin_ = rhs.end_ = rhs.cap_ = 0;
- return *this;
- }
说的够多了,我要看数字!
如果你想知道以上各种实现的实际效果, 我用了这个测试文件来证明不仅可以通过实现转移语义来提高速度,还可以进一步地优化它。这个测试是对一个 std::vector 和一个 boost::array 使用支持转移语义的 std::rotate 算法。如你所见,对于 std::vector,“规范的”转移语义实现要比“清除后交换”实现好一点点,不过,通过以最少操作实现转移赋值,还可以更快。
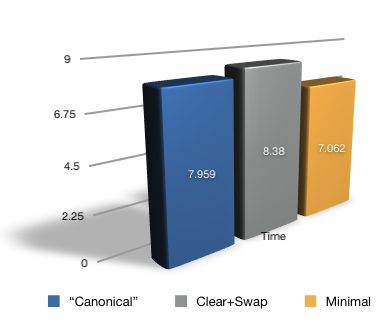
vector 转移赋值的实现比较
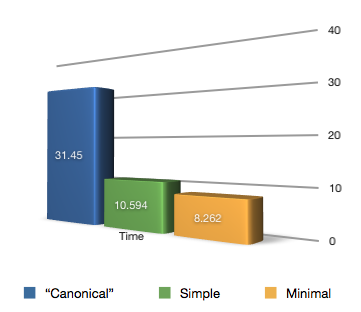
array 转移赋值的实现比较
对于 boost::array(我们假设其结构类似于 boost::tuple),轮到使用 swap 的实现比最简单的一个一个元素的转移实现差不多慢上三倍,而经过仔细优化,我们还可以做得更好。
因此,这个故事的寓意是:要警惕公式化的转移操作实现;记住,转移语义就是为了优化,所以转移操作必须是非常快的,这里一点开销,那里一点开销,就有可能产生明显的差异。
第五篇 异常安全的转移
原文来自:http://cpp-next.com/archive/2009/10/exceptionally-moving/
欢迎来到关于C++中的高效值类型的系列文章中的第五篇。在上一篇中,我们停留在对转移赋值最优实现的不断找寻中。今天,我们将要找到一条穿过这个“转移城市(Move City)”的道路,在这里,最普通的类型都可能有令人惊讶的冲突。
在前面的文章中,我们看到,通过提供”转移的权限”,可以让同一段代码同时用于可转移类型和不可转移类型,并在可能的时候尽量利用转移优化。这种“在可能的时候转移,在必须的时候复制”的方法,对于代码优化是很有用的,也兼容于那些没有转移构造函数的旧类型。不过,对于提供强异常保证的操作来说,却增加了新的负担。
强异常保证,强异常要求
实现强异常保证要求将某个操作的所有步骤分为两类:
- 有可能抛出异常但不包含任何不可逆改变的操作
- 可能包含不可逆改变但不会抛出异常的操作
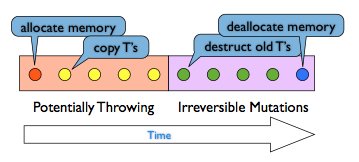
强异常保证依赖于对各步操作的分类
如果我们将所有动作分入这两类,且保证任何第1类的动作都在第2类动作之前发生,就没我们什么事了。在C++03中有一个典型例子,当 vector::reserve() 需要为新元素分配内存时:
- void reserve(size_type n)
- {
- if (n > this->capacity())
- {
- pointer new_begin = this->allocate( n );
- size_type s = this->size(), i = 0;
- try
- {
- // copy to new storage: can throw; doesn't modify *this
- for (;i < s; ++i)
- new ((void*)(new_begin + i)) value_type( (*this)[i] );
- }
- catch(...)
- {
- while (i > 0) // clean up new elements
- (new_begin + --i)->~value_type();
- this->deallocate( new_begin ); // release storage
- throw;
- }
- // -------- irreversible mutation starts here -----------
- this->deallocate( this->begin_ );
- this->begin_ = new_begin;
- this->end_ = new_begin + s;
- this->cap_ = new_begin + n;
- }
- }
如果是在支持转移操作的实现中,我们需要在 try 块中加上一个对 std::move 的显式调用,将循环改为:
- for (;i < s; ++i)
- new ((void*)(new_begin + i)) value_type( std::move( (*this)[i] ) );
在这点变化中,有趣的是,如果 value_type 是支持转移的,那么在循环中会改写 *this (从左值进行显式的转移请求,是一种逻辑上有改写的操作)。
现在,如果转移操作会抛出异常,这个循环就会产生不可逆转的变化,因为要回滚一个部分完成的循环是需要更多的转移操作。因此,要在 value_type 支持转移的情况下保持强异常保证,它的转移构造函数必须是无抛出的。

可能有抛出的转移操作不能做到无潜在再次抛出的回滚
结果
C++0x 标准草案中基本上是反对可抛出的转移构造函数的,我们建议你遵守此规则。不过,转移构造函数必须无抛出这条规则并不总是那么容易遵守的。以 std::pair<std::string,UserType> 为例,其中 UserType 是带有可抛出复制构造函数的类型。在 C++03 中,这个类型是没有问题的,可以用在 std::vector 中。但是在 C++0x 中,std::string 带有转移构造函数,std::pair 同样也有:
- template <class FirstType, class SecondType>
- pair<FirstType,SecondType>::pair(pair&& x)
- : first(std::move(x.first))
- , second(std::move(x.second))
- {}
这里就有问题了。second 的类型是 UserType,它没有转移构造函数,这意味着 second 的构造是一次(有可能抛出的)复制构造,而不是转移构造。所以,pair<std::string, UserType> 给出的是一个可抛出的转移构造函数,它不能再用于 std::vector 中而不破坏强异常保证了。
今天,这意味着我们需要一些类似于以下代码的东西来令 pair 可用。
- template
- pair(pair&& rhs
- , typename enable_if< // Undocumented optional
- mpl::and_< // argument, not part of the
- boost::has_nothrow_move // public interface of pair.
- , boost::has_nothrow_move
- >
- >::type* = 0
- )
- : first(std::move(rhs.first)),
- second(std::move(rhs.second))
- {};
通过使用 enable_if,可以令到这个构造函数“消失”,除非 has_nothrow_move 对于 T1 和 T2 均为 true。
我们知道,没有办法检测是否存在一个转移构造函数,更不要说它是否无抛出了,因此,在我们得到新的语言特性之前,boost::has_nothrow_move 都是补救的方法之一,它对于用户自定义类型返回 false,除非你对它进行了特化。所以,在你编写一个转移构造函数时,应该对这个 trait 进行特化。例如,如果我们为 std::vector 和 std::pair 增加了转移构造函数,我们还应该加上:
- namespace boost
- {
- // All vectors have a (nothrow) move constructor
- template <class T, class A>
- struct has_nothrow_move<std::vector<T,A> > : true_type {};
- // A pair has a (nothrow) move constructor iff both its
- // members do as well.
- template <class First, class Second>
- struct has_nothrow_move<std::pair<First,Second> >
- : mpl::and_<
- boost::has_nothrow_move<First>
- , boost::has_nothrow_move<Second>
- > {};
- }
我们承认这很不好看。C++委员会还在讨论如何解决这个问题的细节,不过以下一些事情都已经获得普通同意:
- 我们不能由于静静地放弃了强异常保证而破坏现有的代码。
- 可以通过在适当的时候生成缺省的转移构造函数——正如 Bjarne Stroustrup 在 N2904 中所建议的——减小这个问题。这可以修复 pair 以及所有类似类型的问题,同时通过增加生成的转移优化,还可以“免费”提升一些代码的速度。
- 还是有些类型需要我们“手工”来处理。
“有问题的类型”
归为有问题的类型通常都带有我们想要转移的子对象——已提供了安全实现——和其它一些我们需要“其它操作”的子对象。std::vector 就是一个例子,它带有一个分配器,其复制构造函数有可能会抛出异常:
- vector(vector&& rhs)
- : _alloc( std::move(rhs._alloc) )
- , _begin( rhs._begin )
- , _end( rhs._end )
- , _cap( rhs._cap )
- {
- // "something else"
- rhs._begin = rhs._end = rhs._cap = 0;
- }
一个简单的成员式转移,例如在 N2904 中所说的缺省生成的那个,在这里将不具有正确的语义。尤其是,它不会把 rhs 的 _begin, _end 以及 _cap 置零。但是,如果 _alloc 不具有一个无抛出的转移构造函数,那么在第2行中就只能进行复制。如果该复制可以有抛出异常,那么 vector 提供的就是可抛出的转移构造函数。
对于语言设计者来说,挑战是如何避免要求用户两次提供相同的信息。既要在转移构造函数的签名中指明成员的类型是可转移的(前面的 pair 转移构造函数中的第5、6行),又要在成员初始化列表中再真正对成员进行转移(第10、11行)。目前正在讨论的一个可能性是使用一个新的属性语法,令到 vector 的转移构造函数可以这样写:
- vector(vector&& rhs) [[moves(_alloc)]]
- : _begin( rhs._begin )
- , _end( rhs._end )
- , _cap( rhs._cap )
- {
- rhs._begin = rhs._end = rhs._cap = 0;
- }
这个构造将被 SFINAE 掉,除非 _alloc 本身具有无抛出的转移构造函数,且这个成员会从 rhs 的相应成员转移过来,从而被隐式地初始化。
不幸的是,对于C++0x中属性的应有作用一直存在一些分歧,所以我们还不知道委员会会接受怎样的语法,但至少我们认为原则上我们已经理解了问题何在,以及如何解决它。
后续
好了,感谢你的阅读;今天就到此为止。下一篇我们将讨论完美转发,还有,我们也没有忘记还欠你一个关于C++03的转移模拟的调查。
第六篇 向前!向前
除了提供转移语义,右值引用的另一个主要用途是解决“完美转发”。在这里,“转发”的指将一个泛型函数的实参转发至另一个函数而不会拒绝掉第二个参数可接受的任何参数,也不会丢失关于这些参数的cv限定或左右值属性的任何信息,而且还无须采用重载。在C++03中,最佳的近似是将所有右值变为左值,并且需要两个重载。
为什么要解决这个问题?
考虑以下例子:
- template <class F>
- struct unary_function_wrapper
- {
- unary_function_wrapper(F f) : f(f) {}
- template <class ArgumentType>
- void operator()( ArgumentType x ) { f(x); }
- private:
- F f;
- };
这种方式是不行的,因为我们的函数调用操作符是传值的,它会拒绝所有不可复制/不可转移的类型,即便 f 可以接受这些类型。如果我们把它改为:
- template <class ArgumentType>
- void operator()( ArgumentType& x ) { f(x); }
那么我们会拒绝所有非常量性的右值。我们可以加一个重载:
- template <class ArgumentType>
- void operator()( ArgumentType& x ) { f(x); }
- template <class ArgumentType>
- void operator()( ArgumentType const& x ) { f(x); }
但是这也和前面的一样,会丢失右值性,而我们本想保留它的,以便 f 可以利用那些我们在前面几篇文章中讨论过的转移优化。引入第二个重载还会带来另一个问题:它不能扩展至多个参数的情形。一个 binary_function_wrapper 就需要四个重载,再来一个 ternary_function_wrapper 就需要八个重载了,完美转发 n 个参数需要 2^n 个重载。
可行的解决方案
对于右值引用,我们可以利用一些特殊设计的语言规则来解决这个问题:
- template <class ArgumentType>
- void operator()( ArgumentType && x )
- { f( std::forward<ArgumentType>(x) ); }
这两个特殊规则是:
- 关于右值引用消除的规则。在C++0x中,很早以前就决定了如果 T 为 U&,则 T& 也为 U&。这是左值引用消除。而对于右值引用,规则被更改为:
- & + & 变为 &
- & + && 变为 &
- && + & 变为 &
- && + && 变为 &&
即,任一”左值性”都会令结果变为左值。
- 关于推定“全泛化右值引用”参数(如上例中的 ArgumentType)的规则。该规则规定,如果实参是一个右值,则 ArgumentType 被推定为非引用类型,而如果实参是一个左值,则 ArgumentType 则被推定为左值引用类型。
当实参为类型 Y 的右值时,这两个规则的结果是:ArgumentType 被推定为 Y,因此这里只有一个引用且没有被消除:函数的参数类型为 Y&&。
当实参是类型 Y 的左值时,ArgumentType 被推定为 Y& (或 Y const&),且引用消除规则会起作用,使得实例化的函数的参数类型为 Y& && 即 Y&...它刚好被绑定到一个左值。
最后一个要点是 forward 函数,它的任务是,当 ArgumentType 为非引用时,“重建”实参的右值性,从而无干扰地把它传递给 f。
和 std::move 一样,std::forward 是一个零开销的操作。虽然它不是一个真正的转换,但是你可以把 std::forward<ArgumentType>(x) 想象为 static_cast<ArgumentType&&>(x) 的描述性表示:当实参是一个右值时,我们把 x 转型为一个匿名右值引用,但是当实参是一个左值时,ArgumentType 就是一个左值引用且引用消除会起作用,因此 static_cast 的结果仍是一个左值引用。
“forward” 实际上意味着什么?
最近,关于 forward 的定义是否应该进行调整以适用于除“完美转发”以外的用途,产生了一些实质性的异议,这些其它用途包括:用于类似于 std::tuple 这样的类型的转移构造函数,这些类型可能含用引用成员,并且要防止将左值引用绑定到右值成员这样的危险情形。被建议的调整通常被称为帮助你“把一个 X 当作一个 Y 来转发”。有关这些调整的细节,请参考 N2951。
我从来没有认同过这个方向的调整,因为“转发一个函数的实参并保持它们的cv限定及右值性”对我来说非常有意义,而“把 X 当作 Y 来转发”则没有明显的意义。换句话说,这种 forward 如何使用以及为何要用,并没有明显的心理模型:我们没有与之对应的编程模型。我最终放弃对此的抵抗,这是因为我看到,它在某些用户必须要处理的与类相关的一些问题方面是有用的,但是我仍然认为,我们必须指出它的意义所在,并且把它解释清楚。