目录
一、前言
ChatGPT 4推出之后,一大波强大而且实用的功能也出现在大家的视野中,比如可以实现定制化AI助手的GPTs,文本、数据分析,视觉输入输出等功能,尤其对于图像的处理上,不仅自身的大模型有了不错的支持,而且集成了不少第三方图像处理工具,比如 DALL·E ,midjourney等,利用GPT4,可以快速帮我们初步完成各类图像从生成到处理的事项,接下来进行详细的介绍。
二、ChatGPT 4 图片处理介绍
GPT4首次引入了图像输入功能,用户可以通过上传图片或直接在聊天窗口中粘贴图片来与机器进行交互。这一功能可以更好地满足用户的多样化需求,比如在描述复杂操作步骤或物品时,通过图像的直观展示可以大大提高沟通效率。
2.1 ChatGPT 4 图片处理概述
ChatGPT 4在图片处理方面具有多种功能,包括图像识别、图像搜索、图像生成、多模态理解、细粒度图像识别、生成式图像任务处理以及图像与文本互动等。
2.1.1 图像识别与分类
GPT 4可以通过深度学习算法对输入的图像进行识别和分类,识别出图像中物体的种类、数量、颜色等信息,并在对话中进行回复
2.1.2 图像搜索
GPT 4可以根据用户提供的关键词或描述,搜索到相关的图像,并在对话中展示给用户
2.1.3 图像生成
GPT 4可以通过生成模型,根据用户提供的关键词或场景描述,生成相关的图像,并在对话中展示给用户
2.1.4 多模态理解
GPT 4引入了多模态理解功能,意味着它能够同时处理和理解文本和图像信息。该模型使用深度学习算法对图像和文本输入进行联合分析,提升了理解复杂内容的能力
2.1.5 细粒度图像识别
GPT 4具备细粒度图像识别能力,能够更准确地识别图片中的复杂细节与对象,提供更加精确的图像内容解释
2.1.6 生成式图像任务处理
GPT 4能够在处理生成式图像任务时展示其创造性和灵活性,不仅能根据文本描述创建和编辑图像内容,还能对现有图像进行编辑和改进
2.1.7 图像与文本互动
GPT 4通过图像与文本的深度互动,能够更好地处理图像相关的问答和搜索任务,根据图像内容回答问题或生成相关描述
2.2 ChatGPT 4 图片处理应用场景
GPT 4 图片处理应用场景如下:
-
内容创作
-
ChatGPT 4可以根据用户提供的文本描述,生成与之匹配的图像内容,这在广告设计、产品展示等领域有广泛应用
-
-
教育领域
-
在教育领域,ChatGPT 4可以帮助教师和学生进行图像识别和解释,提升教学互动效果
-
-
问答系统
-
在问答系统中,ChatGPT 4可以分析图像内容,结合上下文生成准确的描述或答案,提升问答系统的准确性和用户体验
-
-
数据分析
-
在数据分析中,ChatGPT 4可以通过图像识别技术提取数据图表中的关键信息,辅助数据分析工作
-
三、文生图操作实践
接下来演示如何基于GPT4完成常用的文生图操作。
3.1 前置准备
3.1.1 文生图操作入口
GPT在今年的某个时间段之后直接在对话框中输入指令进行文生图,会出现错误,也叫”降智“,官方对外宣称是算力问题,后续会重新开放,不过基于这个情况也有解决办法,第一个是首先上传一张图片,然后继续输入指令,以对话的方式进行文生图操作,或者采用GPTs中内置的DALL-E进行使用,效果是一模一样的。GPTs的操作入口如下:
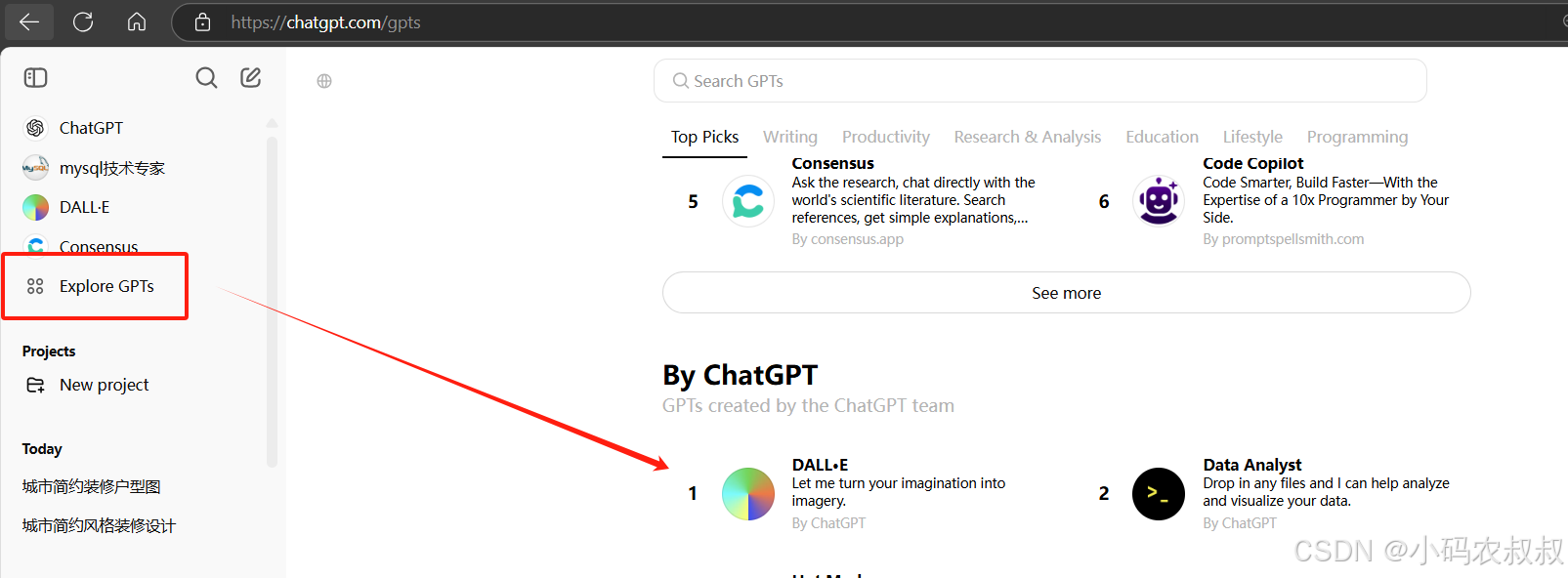
点击DALL-E图标,看到下面的对话窗口即可开始使用

3.1.2 DALL.E 简单简介
DALL·E 是由人工智能研究实验室 OpenAI 开发的一个生成模型,它能够根据文本描述创建图像。该模型的名字来源于将 WALL·E(皮克斯动画电影中的机器人角色)与 Salvador Dalí(著名的超现实主义艺术家)结合在一起。DALL·E 的独特之处在于它能够理解自然语言的复杂性,并以此为基础生成从简单对象到复杂场景的各种图像。
DALL.E 主要特点
-
文本到图像生成:用户可以输入一段描述性的文本,DALL·E 将尝试生成一个或多个符合该描述的图像。
-
多样化输出:DALL·E 可以生成不同风格、视角和构图的图像,包括但不限于写实、卡通、抽象等风格。
-
高分辨率图像:虽然早期版本生成的图像是低分辨率的,但更新后的版本如 DALL·E 2 能够生成更高质量、更高分辨率的图像。
-
编辑能力:除了创造新图像外,DALL·E 还支持对现有图像进行修改,例如添加或删除特定元素。
-
跨领域知识:它可以理解并反映广泛的知识领域,比如艺术、科学和技术,以及它们之间的交叉点。
3.2 文生图提示词使用技巧
对大模型来说,优秀的提示词(Prompt)是基础,不管是使用AI大模型生成各类文案、对话、作品还是你需要得到的答案,文生图也是同样的道理,优秀的提示词可以提升最终生成出来的图片的质量,从而缩短创作时间提升效率。下面是一些常用的有关文生图提示词编写技巧。
-
明确描述
-
具体化:尽可能详细地描述你想要的图像内容。包括对象、颜色、风格、背景等细节。
-
结构清晰:用简单明了的语言表达你的需求,避免过于复杂的句子结构。
-
示例
-
不好的描述:“画一个房子”
-
好的描述:“画一座位于海边的白色两层小楼,周围有椰树和沙滩,天空中有夕阳。”
-
-
-
使用限定词
-
添加形容词:利用形容词来增强图像的具体性和独特性,比如“古老的”、“现代的”、“卡通风格的”等。
-
指定风格:可以提及某种艺术风格或艺术家的名字,如“梵高风格”、“赛博朋克风格”。
-
示例:“一幅赛博朋克风格的城市夜景图,高楼林立,霓虹灯闪烁。”
-
-
分步骤引导
-
如果你有一个复杂的想法,可以尝试分多次输入逐步细化。第一次给出大体框架,之后再补充更多细节。
-
示例
-
第一步:“一个充满未来感的室内设计场景。”
-
第二步:“在刚才的基础上加入透明材质的家具和浮动屏幕。”
-
-
-
尝试不同的表达方式
-
如果初次生成的结果不理想,试着改变描述的方式或者用词,可能会得到意想不到的好结果。
-
-
利用对比度
-
描述中加入对比元素可以使图像更加生动有趣,例如“明亮的灯光照亮黑暗的街道”。
-
-
控制图像的比例和尺寸
-
某些情况下,你可以通过特别说明希望得到的图片比例(如正方形、宽屏)或尺寸来影响输出格式。
-
示例
-
“请生成一张适合手机壁纸的纵向图片,内容是…” 或者 “生成一张适合桌面背景的宽屏图片…”
-
-
3.3 文图案例演示一
3.3.1 生成营销海报
尽可能清楚的描述你的需求,在刚刚接触AI大模型的时候,首先要学习的就是提示词,而首先要注意的就是提示词尽可能清楚表达你的意图。提示词如下:
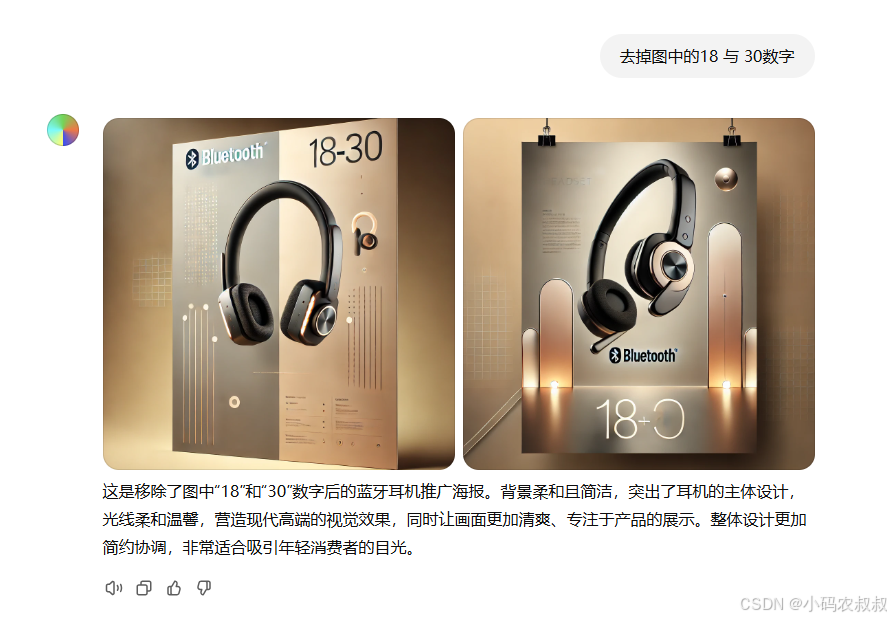
生成一张蓝牙耳机的推广海报,图片内容简约大气,富有科技感和立体感,背景元素不要太复杂,面向的用户群体主要是18~30之间的年轻人,并给出图片的介绍
将提示词输入文本框,默认生成了2张效果还不错富有科技感的图片,同时附上了产品的简单介绍


3.3.2 多轮对话对图片精修
如果对于生成出来的图片效果不是很满意怎么办,就像之前学习Prompt技巧时那样,第一种方式可以通过多轮对话不断逼近,另一种方式就是优化和完善自己的提示词,但是在GPT的文生图中,还提供了另一种方式,即在线对图片进行精修,然后实时生成新的图片,下面通过操作分别演示说明。
1)多轮对话
重新调整色调

2)重新调整背景

3)重去掉不需要的元素
3.3.3 在线精修图片
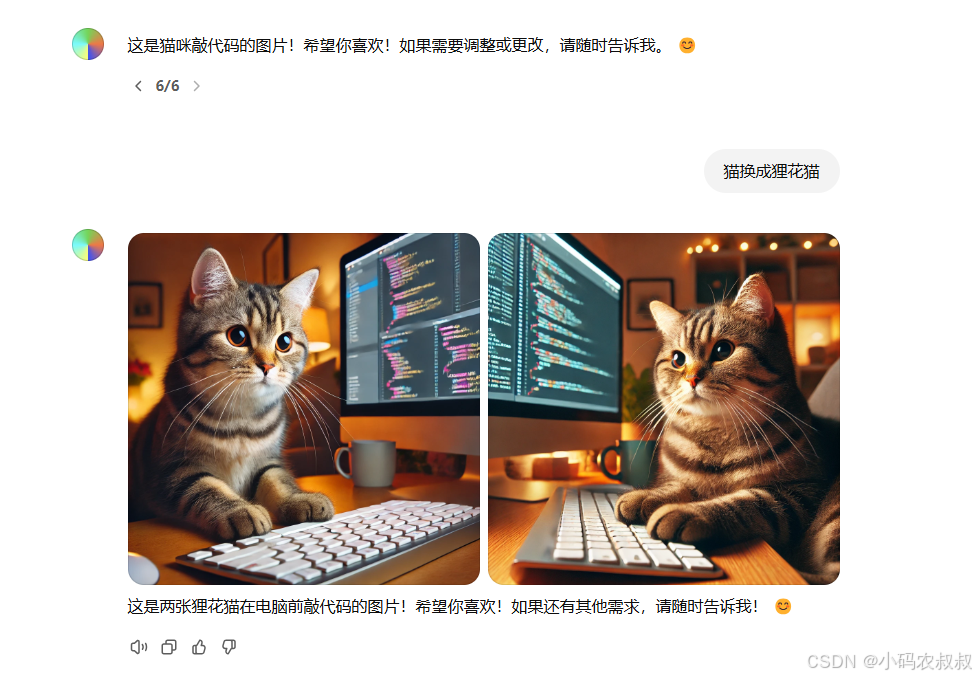
除了上述多轮对话的方式,DALL.E也提供了在线编辑图片和精修的功能,有点类似于PS的功能,如下,我们首先生成一张”猫编程“的图片
如果对第一次生成的图片不满意,直接点击其中一张图片,点击进去之后就到了下面的工作区,左侧是选中的图片,右侧是一个小的对话框,左侧可以理解是图片编辑的工作区,右侧是根据工作区笔刷选中待调整的内容进行指令重新输入的地方
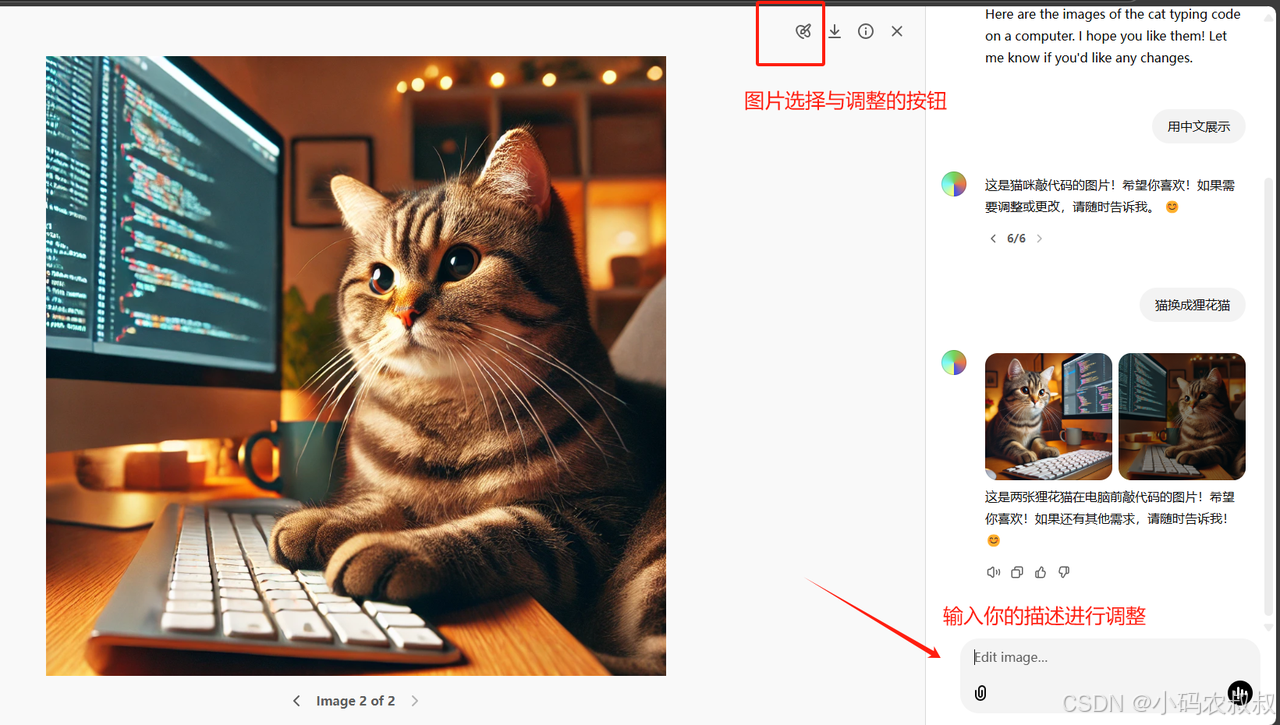
点击选择按钮,可以用笔刷对图片局部不满意的或者需要调整的位置勾选,比如下面这里,我们希望图片中的键盘更换为机械键盘
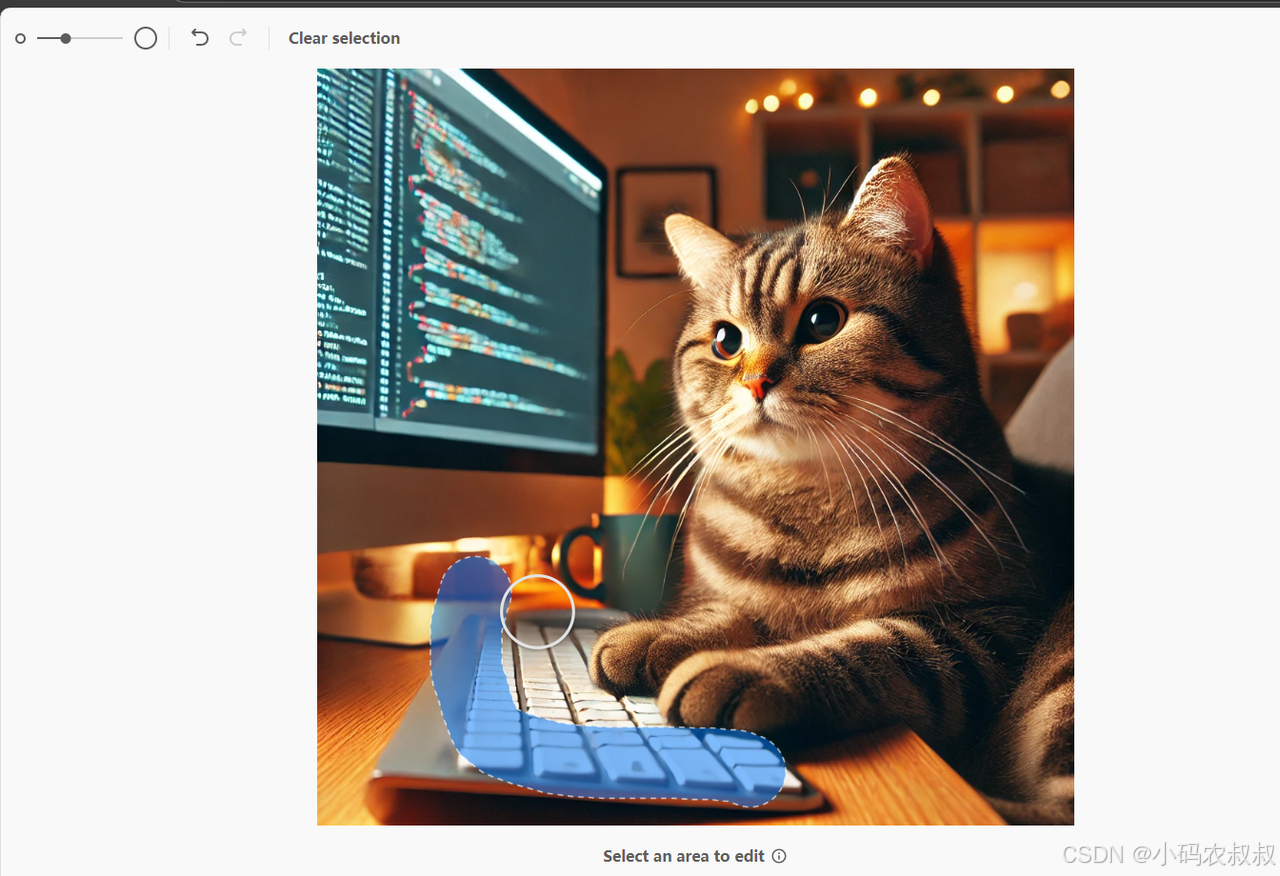

再比如我希望调整一下猫的侧身方向
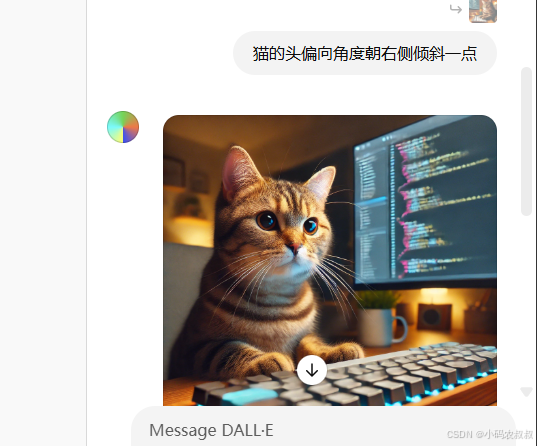
总的来说,在线对图片精修只需要两个操作,第一使用选择的笔刷勾选你要调整的区域,勾选完成,再在对话框里面输入你的需求描述,最后等待图片的重新生成即可
3.4 文图案例演示二
有时候一开始你只是有一个简单的创意,或者是一个轮廓,并没有对最后要生成的图片长什么样有很明确的描述,此时就可以采用”分步引导“的方式来完成。这种方式其实也是很多领域的创作者在真实的创作场景中的一种使用模式。一开始只是一个灵感的闪现,然后通过工具先绘制出一个轮廓,而后不断调整,调整的过程中才能对作品进行丰富和完善,最后形成一个比较完美的作品呈现。
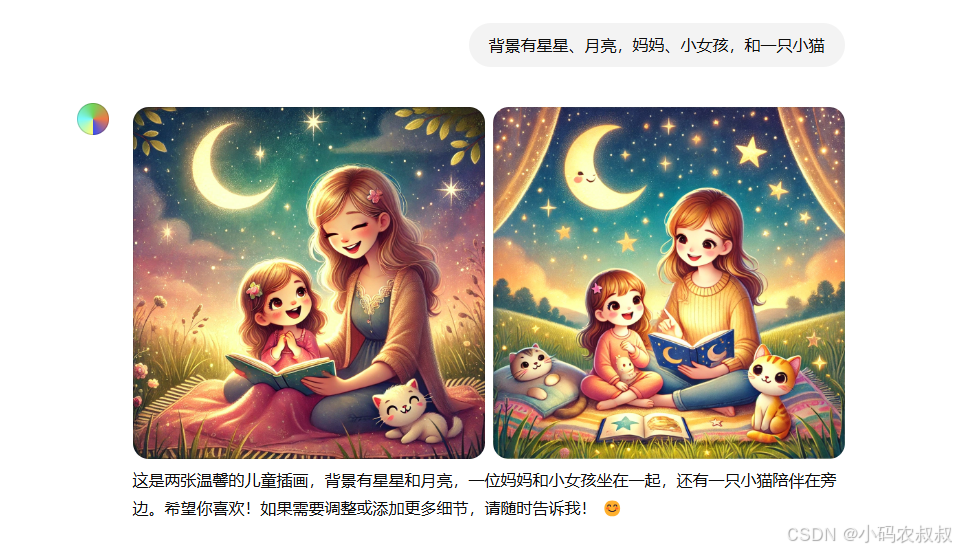
比如,我们的需求是生成一张儿童插画。首先输入下面的提示词。

第一次随机生成的图片我们觉得背景不太符合要求,于是补充自己想要添加的元素
接下来,还希望图片中局部的元素或动作按照自己的预期再调整一下从而更完美
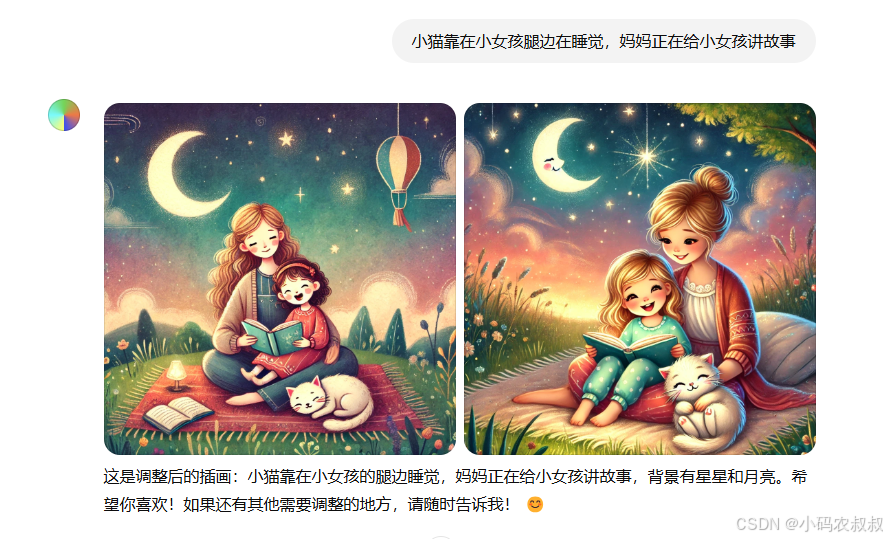
最后再调整一下背景的色调,这样一幅相对符合自己期望的儿童插画就完成了
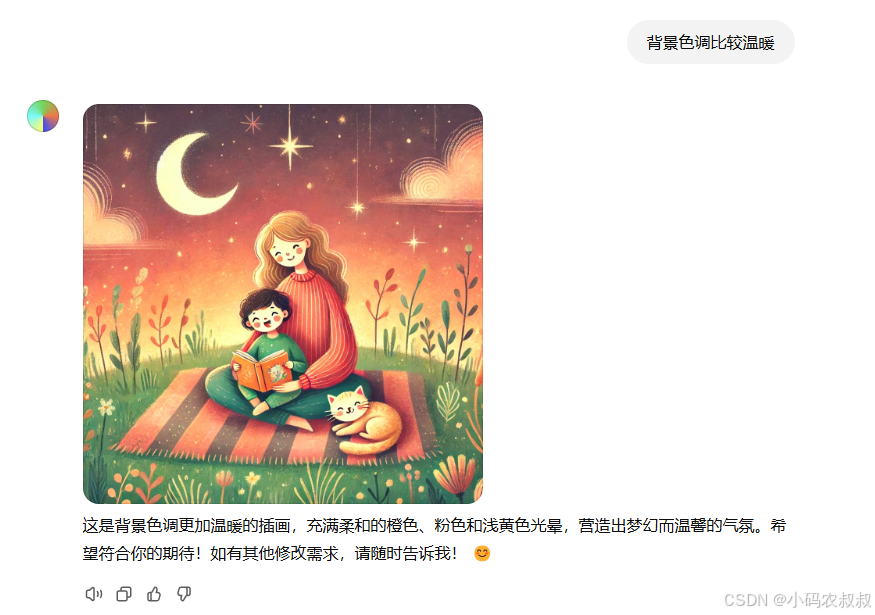
总结:
-
从上面这个生成插画的过程不难看出,整个流程中,我们就像是面对面一个画家,以聊天对话的方式对每一次生成的图片进行微调和细调,直至生成效果满意的图片为止。
四、图生图
利用GPT等AI大模型工具强大的图片处理能力,我们还可以利用GPT解析图片内容,从而分析图片内容并生成我们需要的文案,或者生成新的图片,从而达到图片处理的效果,下面看具体的操作案例。
4.1 图生图
顾名思义,即GPT根据你上传的图片进行推理解析,然后按照你的要求生成一张新的图片
4.1.1 使用GPT图生图功能
首先上传一张图片

看看GPT生成的新图片效果,当然,如果你觉得生成的图片效果不够理想,还可以像上面那样通过对话的方式进行修正微调,直至满意为止

4.1.2 使用DALL.E 图生图功能
下面再来看看DALL.E的生成效果

总结与对比:
-
相对来说,DALL.E比起GPT似乎更胜一筹,毕竟是专业做这个的。
4.2 图片解析
图片解析是指使用GPT或其他大模型工具对上传的图片内容进行推理或分析,按照用户的要求提取、分析图片内容,或者进行其他的动作,接下来看看两个简单的操作示例。
4.2.1 DALL.E 解析图片内容并总结
仍然以上面这张图片为例,让大模型解析和总结图片内容
-
不难看出,DALL.E对于图片的理解、推理分析以及最后的总结还是很全面的。


4.2.2 GPT 解析图片内容并总结
接下来再使用GPT看看处理的效果如何
-
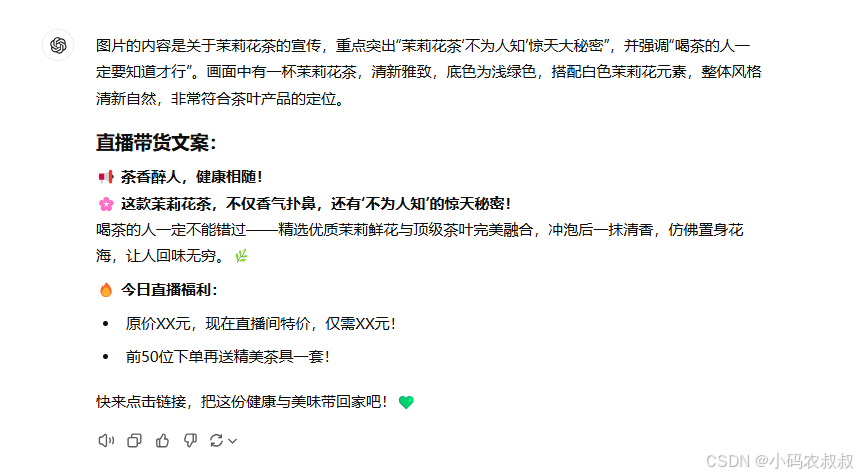
对比来说,GPT给出的结论更加简洁一点,DALL.E似乎更全面一些

4.2.3 图片数据提取与分析
还记得GPT问世之前,如果需要识别一张图片中的关键内容,比如识别图片中的人物、或提取图片中的数据时,还需要借助第三方付费平台提供的API能力去完成,现在有了GPT等AI工具之后,就可以直接在对话中完成对图片中的关键信息进行提取+分析的过程,比如在下面我们上传一张图片,让GPT提取图片中的excel数据

4.3 图生文
图生文主要是大模型根据上传的图片进行内容的分析推理,然后根据用户的需求描述,生成文案,用户可以根据拿到的文案,辅助进行二次或后续的多次创作,典型的场景就是解析产品海报,然后生成新的产品文案,或宣传文案,或直播文案,或视频脚本等等。参考下面的案例。
4.3.1 DALL.E生成直播文案
上传一张带有带货产品的图片,然后生成带货的文案


4.3.2 GPT生成直播文案
再看看GPT的生成效果

五、写在文末
本文通过案例与操作演示详细介绍了使用ChatGPT等AI大模型工具处理图片的各类使用场景,图片可以说在当下的各类互联网应用场景下成为不可或缺的元素,有了AI大模型等工具的加持,可以让更不懂设计的普通人都能参与到图片的设计中来,可以说应用前景是非常光明的,希望对看到的同学有用,本篇到此结束,感谢观看。