基于知识图谱的智能问答系统是一种利用知识图谱结构化数据来回答自然语言问题的技术。知识图谱存储了实体(如人、地点、物品等)及其之间的关系,允许智能系统查询相关的信息并推理答案。
1、知识图谱的智能问答系统核心流程:
-
问题解析:
- 将用户输入的自然语言问题解析为适合查询的格式,通常使用自然语言处理技术(NLP)将问题拆解成可查询的实体和关系。
- 例如,问题 “波兰研制了哪些武器?” 可以解析为 “查找研制国家是波兰的武器”。
-
知识图谱查询:
- 基于解析的问题,系统生成一个查询,并使用类似于 Neo4j 的查询语言(如 Cypher)查询知识图谱。
- 对应的 Cypher 查询可能是:
MATCH (w:Weapon)-[:研制国家]->(c:Country {name: "波兰"}) RETURN w.name
-
结果推理与生成:
- 查询的结果可以直接返回给用户,或者系统可以基于多跳关系进一步推理答案。
- 例如,用户可能问“波兰研制的武器有哪些型号?” 系统可能通过多跳关系找到武器的型号信息:
MATCH (w:Weapon)-[:研制国家]->(c:Country {name: "波兰"}) MATCH (w)-[:型号]->(m:Model) RETURN w.name, m.name
-
答案呈现:
- 将查询结果转化为用户友好的自然语言回答,直接反馈给用户。例如:
- “波兰研制的武器包括:PZL P.6战斗机和PZL P.11战斗机等。”
2、知识图谱智能问答的示例场景:
-
实体查找:
- 问题: “波兰研制了哪些战斗机?”
- 处理: 识别出“波兰”是国家实体、“战斗机”是武器类型实体,查询相关武器。
- 查询:
MATCH (w:Weapon {type: "战斗机"})-[:研制国家]->(c:Country {name: "波兰"}) RETURN w.name
-
关系查询:
- 问题: “PZL P.11战斗机和其他设备有什么关系?”
- 处理: 查找所有与该武器相关的设备及其关系。
- 查询:
MATCH (w:Weapon {name: "PZL P.11战斗机"})-[r]->(e:Equipment) RETURN w.name, type(r), e.name
-
多跳推理:
- 问题: “波兰研制的战斗机有哪些制造公司?”
- 处理: 查找与波兰研制的战斗机相关联的制造公司。
- 查询:
MATCH (w:Weapon {type: "战斗机"})-[:研制国家]->(c:Country {name: "波兰"}) MATCH (w)-[:制造]->(m:Company) RETURN w.name, m.name
3、 构建智能问答系统的主要技术:
-
知识图谱构建:
- 数据收集:从多个来源(文本、数据库等)收集实体和关系信息,并将其结构化为图谱。
- 实体和关系抽取:使用NLP和信息抽取技术从非结构化数据中抽取出有价值的实体和关系。
-
自然语言处理(NLP):
- 问题理解:将自然语言问题转化为结构化查询(如Cypher),可以使用依赖句法分析、词性标注、命名实体识别(NER)等技术。
- 词向量和知识表示:通过预训练的词嵌入(如Word2Vec或BERT)来理解问题中的实体与关系。
-
知识图谱查询:
- 查询语言:使用 Cypher、SPARQL 等图数据库查询语言来执行具体查询,获取相关信息。
- 推理:基于已有的实体与关系,系统可以进行多跳推理,回答更复杂的问题。
-
系统架构:
- 图数据库:如 Neo4j、JanusGraph、Amazon Neptune 用于存储知识图谱。
- 智能问答接口:通过 REST API、GraphQL 等接口接收用户输入,并返回答案。
4、实现步骤:
- 构建知识图谱:将现有的领域数据(如武器、装备等)转换为结构化的图数据。
- 开发 NLP 模块:实现问句解析、实体识别及关系推理。
- 图数据库集成:使用 Neo4j 或其他图数据库进行实体和关系的查询。
通过这些步骤,你可以构建一个基于知识图谱的智能问答系统,支持用户通过自然语言查询复杂的关系和实体信息。
4.1、构建知识图谱
请参考:https://blog.csdn.net/zhanghan11366/article/details/142029311?spm=1001.2014.3001.5502【基于开源WQ装备数据的知识图谱全流程构建】
4.2、开发 NLP 模块
4.2.1、问句解析:
提取问题中的WQ名称及对应的关系类型:
- WQ名称:查询语句 MATCH (w:Weapon) RETURN w.name AS weapon_name 获取所有武器节点的名称。查询结果会被存储在全局变量 cached_weapons 中。缓存的逻辑确保在程序运行时只进行一次数据库查询,后续问题解析时直接使用缓存。从缓存的wq节点中遍历,如果问题中包含武器名称,相关wq会被添加到 weapons 列表中。
# 获取所有武器节点,并缓存
def cache_weapons():
global cached_weapons
if not cached_weapons: # 如果缓存为空,则查询Neo4j数据库
query = "MATCH (w:Weapon) RETURN w.name AS weapon_name"
result = query_neo4j(query)
cached_weapons = [record['weapon_name'] for record in result]
- 关系类型:通过遍历预定义的关系列表(如 “研制国”, “研发单位” 等),如果问题中包含这些词汇,它们会被添加到 relations 列表中。
def parse_question(question):
# 缓存武器节点
cache_weapons()
keywords = {
'relations': [], # 支持多个关系
'weapons': [] # 支持多个武器
}
# 常见关系类型,动态识别多个关系
relations = ["研制国", "研发单位", "武器类型", "武器前身", "研发时间"]
for relation in relations:
if relation in question:
keywords['relations'].append(relation)
# 遍历缓存的武器节点,匹配问题中的武器名称
for weapon_name in cached_weapons:
if weapon_name in question:
keywords['weapons'].append(weapon_name)
return keywords
4.3、图数据库集成
将抽取的WQ名称和关系转为 Cypher查询语句
# 构建查询语句
query = (
f"MATCH (w:Weapon {{name: $weapon}})-[r:`{relation}`]->(e) "
"RETURN e.name AS entity"
)
result = query_neo4j(query, parameters={"weapon": weapon})
4.4、最终测试
验证:
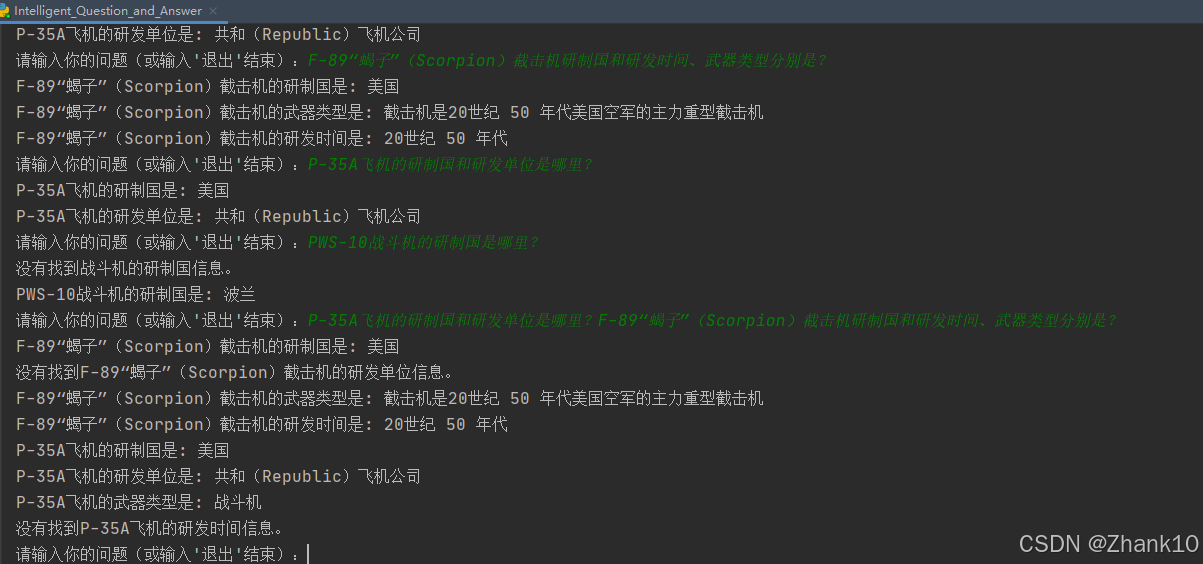
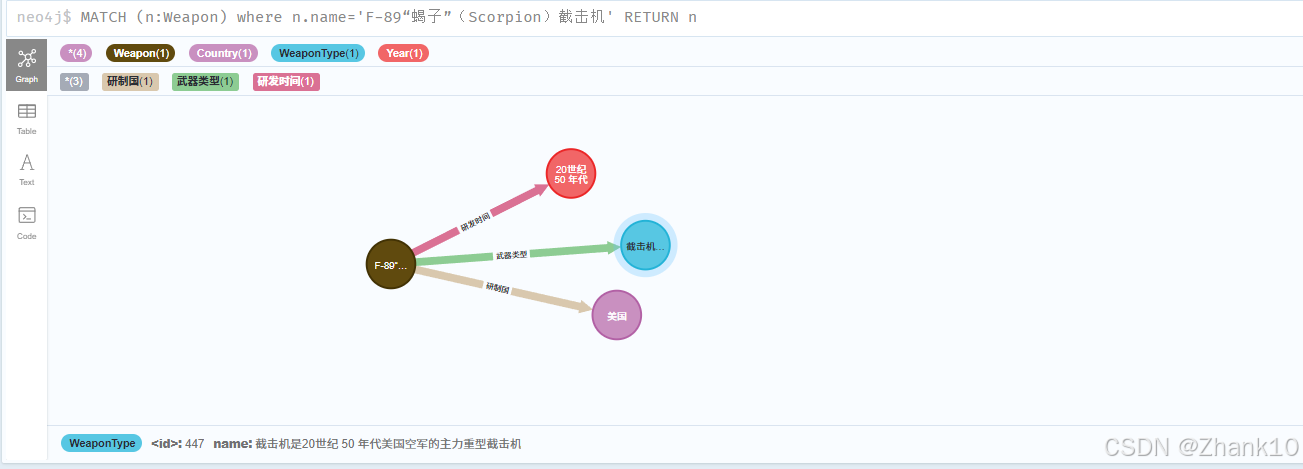
F-89“蝎子”(Scorpion)截击机研制国和研发时间、武器类型分别是?
F-89“蝎子”(Scorpion)截击机的研制国是: 美国
没有找到F-89“蝎子”(Scorpion)截击机的研发单位信息。
F-89“蝎子”(Scorpion)截击机的武器类型是: 截击机是20世纪 50 年代美国空军的主力重型截击机
F-89“蝎子”(Scorpion)截击机的研发时间是: 20世纪 50 年代
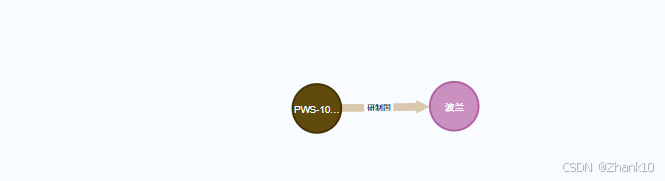
PWS-10战斗机的研制国是哪里?
PWS-10战斗机的研制国是: 波兰
4.5、不足之处
1)目前问题解析只使用匹配的方式,wq和抽取属性没有直接相关。例如:P-35A飞机的研制国和研发单位是哪里?F-89“蝎子”(Scorpion)截击机研制国和研发时间、武器类型分别是?会把两个WQ所有的研制国、研发单位、研发时间、武器类型返回出来。而我需要的P-35A飞机的研制国和研发单位,F-89“蝎子”(Scorpion)截击机研制国和研发时间、武器类型。后续会添加分句和nlp中的依法句存来优化。
2)目前不支持多级查询,例如多个武器前身
3)问题的目前不能太过复杂,目前只设置一中返回句式。
query = (
f"MATCH (w:Weapon {{name: $weapon}})-[r:`{relation}`]->(e) "
"RETURN e.name AS entity"
)
result = query_neo4j(query, parameters={"weapon": weapon})
# 生成单个武器-关系的回答
if result:
entity_list = [record["entity"] for record in result]
answers.append(f"{weapon}的{relation}是: {', '.join(entity_list)}")
else:
answers.append(f"没有找到{weapon}的{relation}信息。")