
正则表达式,又称为regex,是一种广泛使用的文本操作工具。它提供了一种强大而灵活的方法来搜索、替换、提取文本信息。通过正则表达式,我们可以轻松地匹配、处理和操作文本。本文将介绍一些常用的正则表达式及其应用场景。

正则表达式的语法
正则表达式使用特定的语法来表示模式。以下是一些常用的正则表达式语法:
元字符:
. 匹配除换行符以外的任意字符。
^ 匹配行的开头。
$ 匹配行的结尾。
\d 匹配任何十进制数字,相当于[0-9]。
\D 匹配任何非数字字符。
\s 匹配任何空白字符,相当于[\t\n\r\f\v]。
\S 匹配任何非空白字符。
\w 匹配任何字母数字字符,相当于[a-zA-Z0-9_]。
\W 匹配任何非字母数字字符。字符类:
[...] 表示可以匹配的字符集合。例如,[A-Za-z]匹配任何一个字母A到z的大写或小写。
[^...] 表示不包含在字符集中的字符。例如,[^A-Za-z]匹配除了字母A到z的大写或小写以外的字符。
[a-z] 表示匹配a到z的任何小写字母。
[A-Z] 表示匹配A到Z的任何大写字母。
[0-9] 表示匹配0到9的数字。数量词:
{n,m} 表示匹配前面的子表达式至少n次,但不超过m次。
{n,} 表示匹配前面的子表达式至少n次。
{n} 表示精确匹配前面的子表达式n次。
表示匹配前面的子表达式零次或多次。
表示匹配前面的子表达式一次或多次。特殊字符:
\ 用来转义特殊字符,例如反斜杠本身就是一个特殊字符,可以用“\”来表示一个反斜杠。
^ 在[]内部表示否定,在开头表示字首;
表示零次或多次;
表示一次或多次;
? 表示零次或一次;
{n} 表示刚好匹配n次;
{n,} 表示至少匹配n次;
{n,m} 表示在n到m次之间,包括n和m次。这些只是正则表达式的基本语法,实际上正则表达式还有更多的语法和特性,可以根据具体的需求来灵活运用。
正则表达式应用场景
正则表达式可以用于各种文本操作和处理的场景,以下是几个常见的应用场景:
1. 搜索和替换:使用正则表达式可以轻松地搜索和替换文本中的特定模式。例如,可以使用正则表达式来搜索所有的邮箱地址并替换为其他文本。
2. 数据验证:通过正则表达式可以验证文本的格式是否符合特定的规则。例如,验证用户输入的手机号是否符合规定的格式。
3. 文本提取:使用正则表达式可以提取文本中的特定信息。例如,从一段HTML代码中提取链接或从CSV文件中提取数据。
4. 自动化操作:正则表达式可以用于自动化脚本中,对文本进行批量处理和操作。例如,在Unix系统中使用sed和grep等工具进行自动化操作。
这些只是正则表达式的一些应用场景,实际上它的应用非常广泛,可以用于编辑器、开发工具、脚本语言等环境中。

练习和示例
为了更好地理解正则表达式,让我们通过一些实际示例来演示其用法和功能。
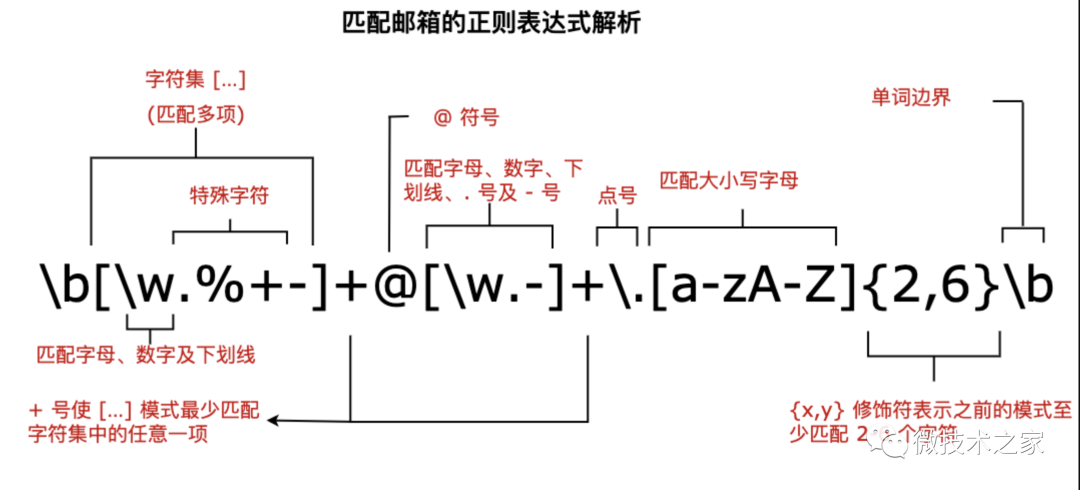
匹配邮箱地址:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$这个正则表达式可以匹配常见的邮箱地址格式。有效的邮箱地址示例:
匹配手机号码:
^(?:(?:\+|00)86)?1[3-9]\d{9}$这个正则表达式可以匹配国内和国际的手机号码格式。有效的手机号码示例:
13812345678
0086-13912345678
+86-13912345678
匹配身份证号:
^\d{17}(?:\d|X)$这个正则表达式可以匹配18位身份证号的格式。有效的身份证号示例:
123456789012345678
98765432109876543X
匹配URL地址:
^(http|https):\/\/[^\s/$.?#].[^\s]*$这个正则表达式可以匹配常见的URL格式。下面是一些有效的URL示例:
http://www.example.com
https://www.example.org
http://example.net
这些示例只是正则表达式应用的一小部分,实际上正则表达式的功能非常强大,可以根据具体的需求来灵活运用。希望本文可以帮助大家了解到正则表达式,如果在学习和使用过程中遇到什么问题和想法,欢迎发消息给我们。
✨✨ 欢迎关注 ✨✨