1、hive 与iceberg版本匹配:
| 操作 | Hive 2.x | Hive 3.1.2 |
| CREATE EXTERNAL TABLE | √ | √ |
| CREATE TABLE | √ | √ |
| DROP TABLE | √ | √ |
| SELECT | √ | √ |
| INSERT INTO | √ | √ |
2、环境
2.1 添加jar包
下载 iceberg-hive-runtime.jar, 在hive shell中使用命令 add jar /path/to/iceberg-hive-runtime.jar 添加到hive中。
下载 libfb303-0.9.3.jar, 在hive shell中使用命令 add jar /path/to/ libfb303-0.9.3.jar 添加到hive中


2.2 修改 hive-site.xml,启用对iceberg的支持,增加如下配置: vi /etc/hive/conf/hive-site.xml (全局)
3、设置iceberg.catalog :定义iceberg元数据存储的方式,默认使用hiveCatalog进行管理。
| Config Key | Description |
| iceberg.catalog.<catalog_name>.type | type of catalog: hive, hadoop, or left unset if using a custom catalog |
| iceberg.catalog.<catalog_name>.catalog-impl | catalog implementation, must not be null if type is empty |
| iceberg.catalog.<catalog_name>.<key> | any config key and value pairs for the catalog |
例如:
建表时使用:
自定义catalog属性:


实际上就是使用的hive的catalog,这种方式与第一种方式不设置效果一样,创建后的表存储在hive默认的warehouse目录下。
指定hadoop存储iceberg catalog,并自定义表存储路径:


4、读写表示例:
创建表
插入数据:
hive> insert into test_iceberg_tbl1 values(1, 'zhangsan', 20, '20220909');
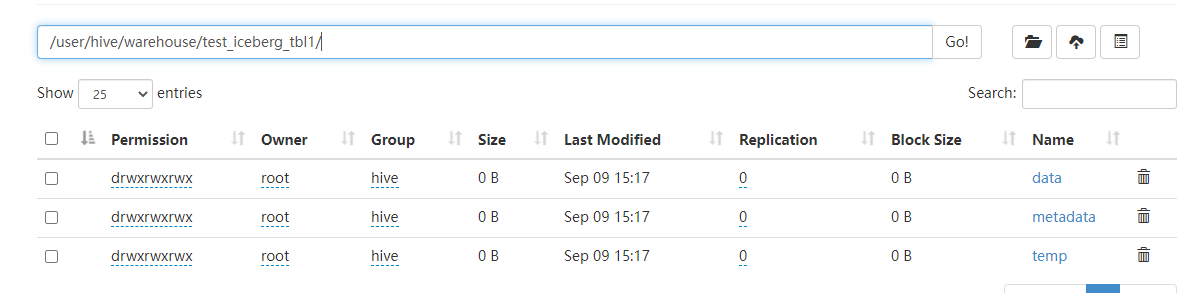
iceberg 元数据
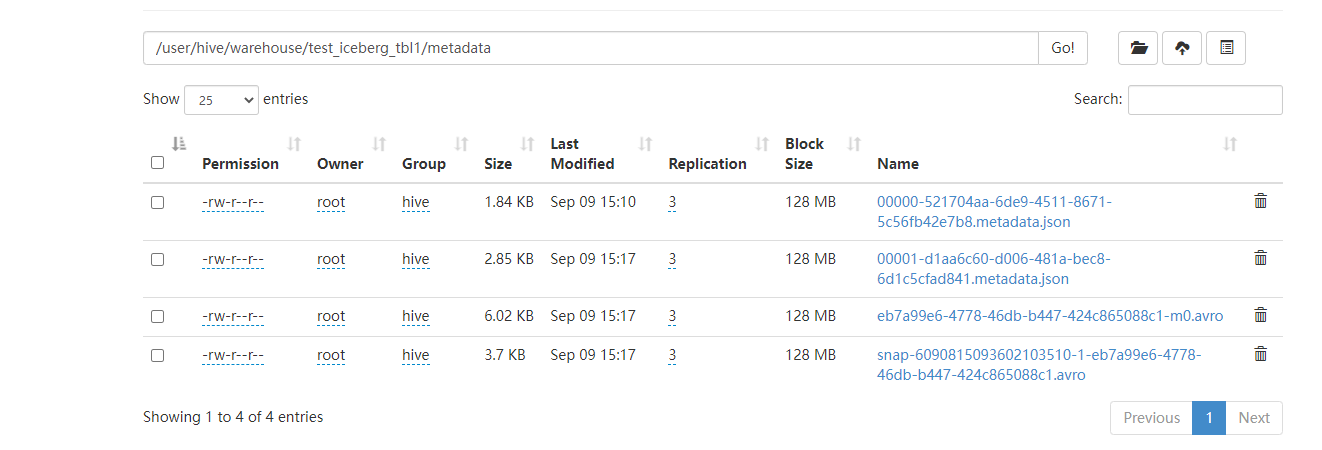

其中metadata目录存放元数据管理层的数据:数据存储层支持不同的文件格式,目前支持Parquet、ORC、AVRO。
●version[number].metadata.json 元数据文件 VersionMetadata存储当前版本的元数据信息(所有snapshot信息);Snapshot表示当前操作的一个快照,每次commit都会生成一个快照
●snap-[snapshotID]-[attemptID]-[commitUUID].avro(snapshot文件) 快照文件 一个快照中包含多个Manifest,基于snapshot的管理方式,iceberg能够进行time travel(历史版本读取以及增量读取),并且提供了serializable isolation。
●[commitUUID]-m-[manifestCount].avro(manifest文件) 清单文件 每个Manifest中记录了当前操作生成数据所对应的文件地址,也就是data files的地址。
data目录组织形式类似于hive,都是以分区进行目录组织(上图中id为分区列),最终数据可以使用不同文件格式进行存储:
●[sparkPartitionID]-[sparkTaskID]-[UUID]-[fileCount].[parquet | avro | orc]
数据查找逻辑:
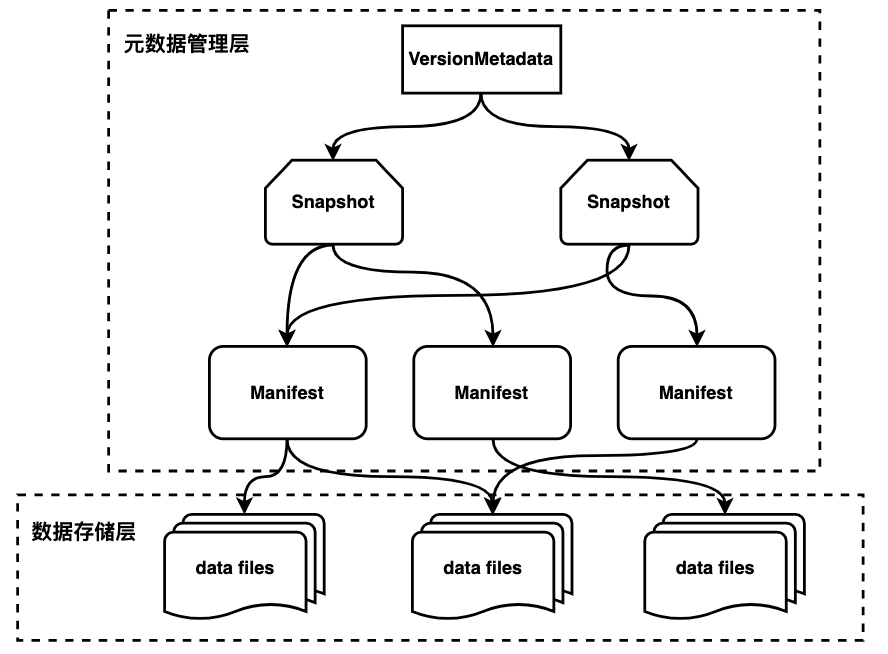
查询数据:元数据--> 快照文件 --> 清单文件 --> data 数据