HunyuanDiT 是由腾讯发布的文生图模型,适配中英双语。
在模型方面的改进,主要包括:
- transformer结构
- text encoder
- positional encoding
Improving Training Stability To stabilize training, we present three techniques:
- We add layer normalization in all the attention modules before computing Q, K, and V. This technique is called
QK-Norm, which is proposed in [13]. We found it effective for training Hunyuan-DiT as well.- We add layer normalization after the skip module in the decoder blocks to avoid loss explosion during training.
- We found certain operations, e.g., layer normalization, tend to overflow with FP16. We specifically switch
them to FP32 to avoid numerical errors.
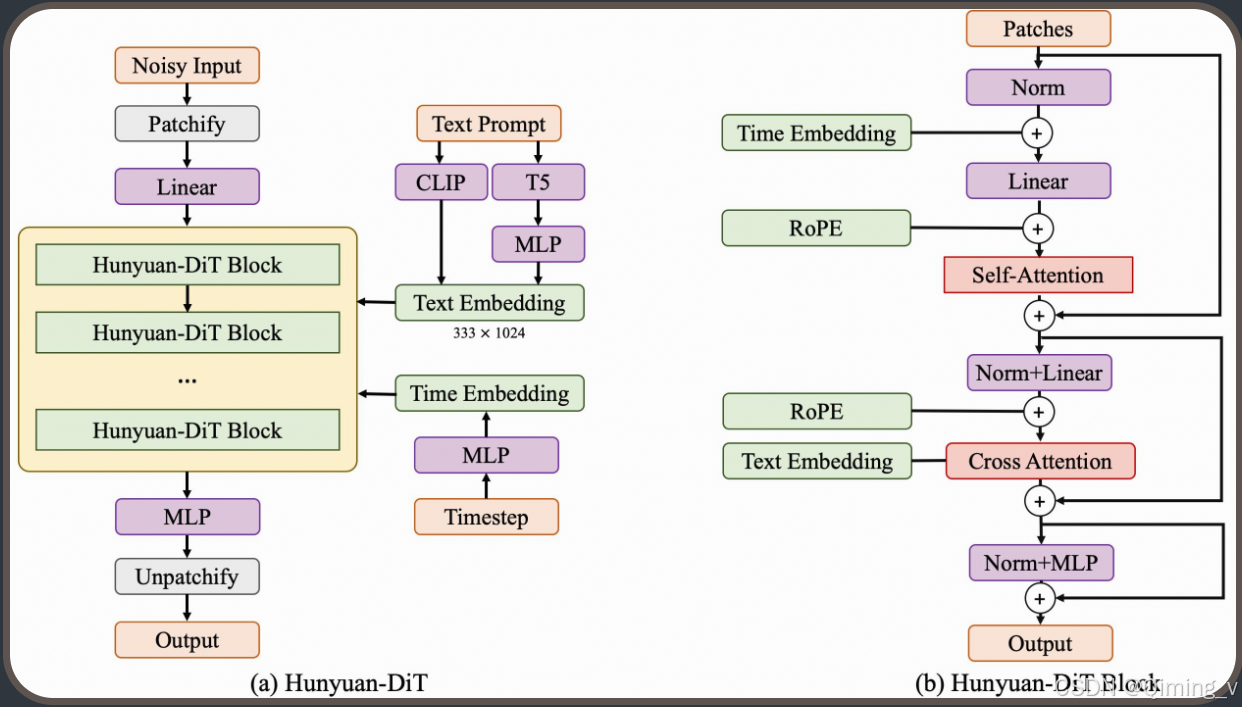
HunyuanDiT的模型结构
使用Diffusers中的HunyuanDiTPipeline。
import torch
from diffusers import HunyuanDiTPipeline
pipe = HunyuanDiTPipeline.from_pretrained("/disk2/modelscope/hub/Xorbits/HunyuanDiT-v1___2-Diffusers", torch_dtype=torch.float16)
pipe.to("cuda")
# You may also use English prompt as HunyuanDiT supports both English and Chinese
# prompt = "An astronaut riding a horse"
prompt = "一个宇航员在骑马"
image = pipe(prompt).images[0]
image.save("astronaut.jpg")
transformer结构
HunyuanDiT 共包括40个HunyuanDiTBlock。其中前20个的结果要skip到后20个模块中。skip的时候,仍然需要norm,然后使用Linear恢复到之前的维度。
skips = []
for layer, block in enumerate(self.blocks):
if layer > self.config.num_layers // 2:
if controlnet_block_samples is not None:
skip = skips.pop() + controlnet_block_samples.pop()
else:
skip = skips.pop()
hidden_states = block(
hidden_states,
temb=temb,
encoder_hidden_states=encoder_hidden_states,
image_rotary_emb=image_rotary_emb,
skip=skip,
) # (N, L, D)
else:
hidden_states = block(
hidden_states, #(2,4096,1408)
temb=temb, #(2,1408)
encoder_hidden_states=encoder_hidden_states, #(2,333,1024)
image_rotary_emb=image_rotary_emb,
) # (N, L, D)
if layer < (self.config.num_layers // 2 - 1):
skips.append(hidden_states)
HunyuanDiTBlock 的forward函数,和上图一致,看图更直观。
输入需要Norm,每次attention后需要Norm。在计算attention的时候,Q和K还要Norm。
def forward(
self,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
temb: Optional[torch.Tensor] = None,
image_rotary_emb=None,
skip=None,
) -> torch.Tensor:
# Notice that normalization is always applied before the real computation in the following blocks.
# 0. Long Skip Connection
if self.skip_linear is not None:
cat = torch.cat([hidden_states, skip], dim=-1)
cat = self.skip_norm(cat)
hidden_states = self.skip_linear(cat)
# 1. Self-Attention
norm_hidden_states = self.norm1(hidden_states, temb) ### checked: self.norm1 is correct
attn_output = self.attn1(
norm_hidden_states,
image_rotary_emb=image_rotary_emb,
)
hidden_states = hidden_states + attn_output
# 2. Cross-Attention
hidden_states = hidden_states + self.attn2(
self.norm2(hidden_states), ###
encoder_hidden_states=encoder_hidden_states,
image_rotary_emb=image_rotary_emb,
)
# FFN Layer ### TODO: switch norm2 and norm3 in the state dict
mlp_inputs = self.norm3(hidden_states)
hidden_states = hidden_states + self.ff(mlp_inputs)
return hidden_states
text encoder
HunyuanDiT 使用CLIP和T5两个文本编码器。CLIP提取文本和图像的关系特征,T5则加强对于prompt的理解。
CLIP 生成的embedding 维度为(1,77,1024),T5生成的embedding 维度为 (1,256,2048)。
使用PixArtAlphaTextProjection,将T5的embedding 对齐到CLIP,然后将两个序列拼到一起。
encoder_hidden_states = torch.cat([encoder_hidden_states, encoder_hidden_states_t5], dim=1) #(2,333,1024)
positional encoding
代码预设的长宽是512,公式中的S就是32,

base_size = 512 // 8 // self.transformer.config.patch_size #32
grid_crops_coords = get_resize_crop_region_for_grid((grid_height, grid_width), base_size) #((0, 0), (32, 32)),crop latent
image_rotary_emb = get_2d_rotary_pos_embed(
self.transformer.inner_dim // self.transformer.num_heads,
grid_crops_coords,
(grid_height, grid_width),
device=device,
output_type="pt",
)
# get_resize_crop_region_for_grid实现公式
def get_resize_crop_region_for_grid(src, tgt_size):
th = tw = tgt_size
h, w = src
r = h / w
# resize
if r > 1:
resize_height = th
resize_width = int(round(th / h * w))
else:
resize_width = tw
resize_height = int(round(tw / w * h))
crop_top = int(round((th - resize_height) / 2.0))
crop_left = int(round((tw - resize_width) / 2.0))
return (crop_top, crop_left), (crop_top + resize_height, crop_left + resize_width)
既然是图像的RoPE,那么也只能加在图像的Q和K上,在cross_attention中,K和V来自于prompt。
# Apply RoPE if needed
if image_rotary_emb is not None:
query = apply_rotary_emb(query, image_rotary_emb)
if not attn.is_cross_attention:
key = apply_rotary_emb(key, image_rotary_emb)