定义:
设G = (V, E)是连通的无向图,T是图G的一个最小生成树.如果有另外一棵树T1,T1 ≠ T,满足不存在树T',T' ≠ T,w(T') < w(T1),则称T1是图G的次小生成树.
算法:
1:基本算法
最简单也最容易想到的是,设T是G的最小生成树,依次枚举T的边并去掉,再求最小生成树,所得到的这些值的最小值就是次小生成树,由于最小生成树有N-1条边,这种方法就相当于运行了N次最小生成树的算法,算法的时间复杂度比较高.大约是N * M的数量级.
2:算法二
定义由最小生成树T进行一次可行变化得到的新的生成树所组成的集合,称为树T的邻集,记为N(T).所谓可行变化即去掉T中的一条边,再新加入G中的一条边,使得新生成的图仍为树.设T是图G的最小生成树,如果T1满足w(T1) = min{ w(T') | T' E N(T)},则T1是图G的次小生成树.
定理:如果图G的点的个数V和边的个数E个不满足关系V = E-1,那么存在边(u,v) 属于 T 和(x, y)不属于T满足T \ (u, v) U (x, y)是图的一颗次小生成树.
既然存在边(u, v) 属于 T 和(x, y) 不属于T满足T \ (u, v) U (x, y)是图的一颗次小生成树,那么所有的T \ (u, v) U (x, y)刚好构成了T的邻集,则T的邻集中权值最小的就是次小生成树了,但是如果每次枚举(u, v)和(x, y),还要判断能否构成一棵树,复杂度太高.那么这里应该这么做,先加入(x,y),对于一棵树加入(x, y)后一定会成环,如果删去环上除(x ,y)以外权值最大的一条边,会得到加入(x,y)时权值最小的边.那么接下来的问题就是如何快速求得这个环上权值最大边了.最小生成树中x到y的最长边可以使用树形动态规划或者LCA等方法在O(N2)的时间复杂度内计算出来.但是如果使用的是Kruskal算法求最小生成树,可以在算法的运行过程中求出x到y路径上的最长边,因为每次合并两个等价类的时候,分别属于两个等价类的每两个点之间的最长边一定是当前加入的边,按照这条性质进行记录的话就可以求出来最小生成树中在每两个点的路径上的最长边.
算法实现上,首先用求最小生成树的算法求出其权值之和为mst,然后枚举不属于最小生成树的边(x, y),并添加到最小生成树中,那么树必定形成环,然后删掉这个环内(不包含(x,y))最长的边.然后计算权值之和,枚举所有不属于最小生成树的边,取其权值的最小值,就是次小生成树.
下面用图来说明下计算(x,y)之间的最长边:
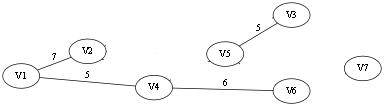
比如利用 kruskal 走到了上述步骤,接下来要添加边(V2, V5),已知权值为8,那么V2 和 V5 分别属于两个等价类<V2, V1, V4, V6> 和 <V5, V3> 的每两个点之间的距离应该都更新为7,即length[3][2] = length[3][1] = length[3][4] = length[3][6] = 8, length[5][2] = length[5][1] = length[5][4] = length[5][6] = 7,每增加一条边,就如此的更新下去,最后就可以得到图中两个节点之间的路径上的最长距离.
下面再用图简单阐述下算法:
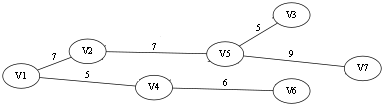
假设上图是图的最小生成树,并存在边(v5, v6),且其权值为8,那么当枚举到此条边时,在图中添加边(v5,v6),图中便有了一个环,在此环中找到除新加边以外最大的边的权值为7,那么删除此边,计算权值,然后继续枚举其他不存在于最小生成树的边,从中取得最小值,就是要求的答案.
复杂度分析:整个算法进行了一次Krusal算法,时间复杂度为O(mlogm),同时又对整个length[][]进行赋值,时间复杂度为O(n^2),最终又进行了时间复杂度为O(m)的遍历,总的时间复杂度是O(mlogm+n^2).
对应板题:传送门
对应Kruskal解法,附上代码:
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
const int maxn=150;
const int maxe=150*150;
const int inf=0x3f3f3f3f;
struct edge{
int u,v,w;
bool select;
};
edge edges[maxe];
bool cmp(edge a,edge b)
{
if(a.w!=b.w){
return a.w<b.w;
}
if(a.u!=b.u){
return a.u<b.u;
}
return a.v<b.v;
}
int t,n,m;
int pre[maxn];
struct node{
int to,next;
};
node link[maxn];
int head[maxn],endd[maxn],length[maxn][maxn];
void init()
{
for(int i=0;i<=n;i++){
pre[i]=i;
head[i]=endd[i]=-1;
}
}
int find(int x)
{
return x==pre[x]?x:pre[x]=find(pre[x]);
}
void merge(int x,int y)//注意此处改为靠右原则,因为集合合并问题
{
int fx=find(x),fy=find(y);
if(fx!=fy){
pre[fx]=fy;
}
}
int kruskal()
{
int mst=0;
init();
for(int i=1;i<=n;i++){
link[i].to=i;
link[i].next=head[i];
endd[i]=i;
head[i]=i;
}
sort(edges+1,edges+m+1,cmp);
int cnt=0;
for(int i=1;i<=m;i++){
if(cnt==n-1){
break;
}
int fx=find(edges[i].u);
int fy=find(edges[i].v);
if(fx!=fy){
for(int j=head[fx];j!=-1;j=link[j].next){
for(int k=head[fy];k!=-1;k=link[k].next){
length[link[j].to][link[k].to]=length[link[k].to][link[j].to]=edges[i].w;
}
}
//此处合并到右边这个集合中
link[endd[fy]].next=head[fx];
endd[fy]=endd[fx];
merge(fx,fy);
cnt++;
edges[i].select=true;
mst+=edges[i].w;
}
}
return mst;
}
int main()
{
scanf("%d",&t);
while(t--){
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++){
scanf("%d%d%d",&edges[i].u,&edges[i].v,&edges[i].w);
edges[i].select=false;
}
int mst=kruskal();
int secmst=inf;
for(int i=1;i<=m;i++){
if(!edges[i].select){
secmst=min(secmst,mst+edges[i].w-length[edges[i].u][edges[i].v]);
}
}
if(mst==secmst){
printf("Not Unique!\n");
}else{
printf("%d\n",mst);
}
}
return 0;
}
还有一种是prim解法,其中prim解法有两种,一种思想和kruskal解法思想一样,附上prim解法一代码:
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
const int inf=0x3f3f3f3f;
const int N=110;
int n,m,mapp[N][N];
int use1[N][N],maxn[N][N];
int sum;
void prim()
{
sum=0;
int vis[N],low[N],pre[N];
int bj,min1;
memset(vis,0,sizeof(vis));
memset(use1,0,sizeof(use1));
memset(maxn,0,sizeof(maxn));
vis[1]=1;
bj=1;
for(int i=2;i<=n;i++){
low[i]=mapp[bj][i];
pre[i]=1;
}
pre[1]=0;
for(int i=1;i<n;i++){
min1=inf;
for(int j=1;j<=n;j++){
if(!vis[j]&&min1>low[j]){
bj=j;
min1=low[j];
}
}
sum+=min1;
vis[bj]=1;
use1[bj][pre[bj]]=use1[pre[bj]][bj]=1;
for(int j=1;j<=n;j++){
if(vis[j]){
maxn[j][bj]=maxn[bj][j]=max(maxn[j][pre[bj]],low[bj]);
}
if(!vis[j]&&low[j]>mapp[bj][j]){
low[j]=mapp[bj][j];
pre[j]=bj;
}
}
}
}
int sprim()
{
int ans=inf;
for(int i=1;i<=n;i++){
for(int j=i+1;j<=n;j++){
if(!use1[i][j]&&mapp[i][j]!=inf){
ans=min(sum+mapp[i][j]-maxn[i][j],ans);
}
}
}
return ans;
}
int main()
{
int t;
scanf("%d",&t);
while(t--){
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
if(i==j){
mapp[i][j]=0;
}else{
mapp[i][j]=inf;
}
}
}
int u,v,w;
for(int i=1;i<=m;i++){
scanf("%d%d%d",&u,&v,&w);
mapp[u][v]=mapp[v][u]=w;
}
prim();
int mst=sum;
int secmst=sprim();
if(mst==secmst){
printf("Not Unique!\n");
}else{
printf("%d\n",mst);
}
}
return 0;
}