一、Kafka优化总结
翻译原文如下:
https://www.infoq.com/articles/apache-kafka-best-practices-to-optimize-your-deployment
1. 设置日志配置参数以使日志易于管理
kafka 日志文档 https://kafka.apache.org/documentation/#log
kafka 压缩基础知识 https://kafka.apache.org/documentation/#design_compactionbasics
2. 了解 kafka 的 (低) 硬件需求
CPU :除非需要SSL和日志压缩,否则Kafka不需要强大的CPU。使用的内核越多,并行性能越好,大多数情况下压缩,压缩也不会产生影响,应该使用LZ4 编码器来提供最佳性能。
RAM:对特别重的负载生产负载,使用32GB一上的机器,将提高客户端吞吐量
磁盘:如果在RAIO设置中使用多个驱动器,就该Kafka大显身手。由于Kafka的顺序磁盘I/O范式,所有SSD不会提供太多的优势,不应该使用NAS
网络和文件系统:建议使用XFS,如果条件允许,还可以将集群放在单个数据中心。应尽量提供更多的网络带宽。
-
Apache Kafka 的基准测试:每秒 200 万次写 (在 3 台廉价的机器上)
https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
-
在 AWS 上的 Apache Kafka 负载测试
https://grey-boundary.io/load-testing-apache-kafka-on-aws/
-
性能测试
https://cwiki.apache.org/confluence/display/KAFKA/Performance+testing
3. 充分利用 Apache ZooKeeper
Zookeeper 节点的数量最大应该是五个。一个节点适合于开发环境,三个节点对于大多数产品Kafka集群足够了,虽然一个大型Kafka集群可能需要5个节点来减少延迟,必须考虑节点负载,近期版本的Kafka对Zookeeper的负载要低很多,早期版本使用Zookeeper来存储消费者偏移量。
为Zookeeper 提供最强大的网络带宽。使用最好的磁盘,分别存储日志、隔离Zookeeper进程、禁用交换,这些也会减少延迟。
4. 以正确的方式设置复制和冗余
5. 注意主题配置
6. 使用并行处理
7. 带着安全性思维配置和隔离 Kafka
8. 通过提高限制避免停机 Ulimit
-
1、创建一个新的文件:/etc/security/limits.d/nofile.conf
-
2、输入内容:
-
soft nofile 128000 hard nofile 128000
-
-
3、重新启动系统或重新登录。
-
4、通过以下命令来验证
-
ulimit -a
9. 保持低网络延迟
10. 利用有效的监控和警报
通过 Instaclustr 控制台中显示的 Kafka 监控图示例:监视系统指标 (如网络吞吐量、打开的文件句柄、内存、负载、磁盘使用情况和其他因素) 是必不可少的,同时还要密切关注 JVM 统计数据,包括 GC 暂停和堆使用情况。仪表板和历史回溯工具能够加速调试过程,可以提供大量的价值。与此同时,应该配置 Nagios 或 PagerDuty 等警报系统,以便在出现延迟峰值或磁盘空间不足等症状时发出警告
二、Kafka数据丢失解决方案
producer 数据不丢失:
1. 同步模式:配置=1 (只有Leader收到,-1 所有副本成功,0 不等待)Leader Partition挂了,数据就会丢失
解决:设置 -1 保证produce 写入所有副本算成功 producer.type = sync request.required.acks=-1
2. 异步模式,当缓冲区满了,如果配置为0(没有收到确认,一满就丢弃),数据立刻丢弃
解决:不限制阻塞超时时间。就是一满生产者就阻塞
producer.type = async
request.required.acks=1
queue.buffering.max.ms=5000
queue.buffering.max.messages=10000
queue.enqueue.timeout.ms = -1
batch.num.messages=200
Customer 不丢失数据
在获取kafka的消息后正准备入库(未入库),但是消费者挂了,那么如果让kafka自动去维护offset ,它就会认为这条数据已经被消费了,那么会造成数据丢失。
解决:使用kafka高级API,自己手动维护偏移量,当数据入库之后进行偏移量的更新(适用于基本数据源)
流式计算。高级数据源以kafka为例,由2种方式:receiver (开启WAL,失败可恢复) director (checkpoint保证)
流处理中的几种可靠性语义:
1. at most once 每条数据最多被处理一次(0次或1次),会出现数据丢失的问题
2. at least once 每条数据最少被处理一次(1次或更多),这个不会出现数据丢失,但是会出现数据重复
3. exactly once 每种数据只会被处理一次,没有数据丢失,没有数据重复,这种语义是大家最想实现的,也是最难实现的
但是开启WAL后,依旧存在数据丢失问题,原因是任务中断时receiver 也被强行终止了,将会造成数据丢失
在Streaming程序的最后添加代码,只有在确认所有receiver都关闭的情况下才终止程序
三、Kafka特点、优点、应用场景
1、kafka 特点
分布式:1.多分区 2. 多副本 3. 多订阅者(订阅者数量小于等于partition数量)4. 基于Zookeeper调度
高性能:1. 高吞吐量 2. 低延迟 3. 高并发 4. 时间复杂度为O(1)
持久性与扩展性:1. 数据可持久化 2. 容错性(多副本和Consumer Group 支持了容错性) 3.支持在线水平扩展(Broker 有一个或多个Partition ,Topic 有一个或多个Partition,Consumer Group 变化,我们增加了新的机器,就可以放新的topic和新的Partition)4. 消息自动平衡(消息在服务端进行平衡,consumer在消费的时候进行平衡)
Kafka 高级特性--消息事务
数据传输的事务定义:
最多一次:消息不会被重复发送、最多被传输一次、但也有可能一次不传输
最少一次:消息不会被漏发送,最少被传输一次,但也有可能重复传输(消费端需要判断处理)
精确的一次(Exactly once):不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅传输一次
事务保证
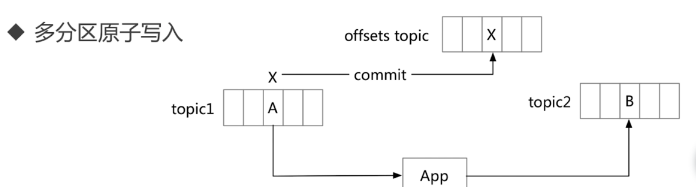
Produce幂等处理、多分区原子写入(事务要保证kafka下每一分区的原子写入,原子是一个读取--处理--写入操作)
事务保证--避免僵尸实例
每个事务Producer 分配一个transactional.id ,在进程重新启动时能够识别相同的Producer实例
kafka 增加了一个与transactional.id 相关的epoch, 存储每个transactional.id 内部元数据
一旦epoch 被触发,任何具有相同的transactional.id 和更旧的epoch的Producer 被视为僵尸,Kafka会拒绝来自这些Procedure的后续事务写入
kafka高性能--零拷贝
网络传输持久性日志块(消息)
零拷贝建立在:Java Nio channel.transforTo()方法 实际是调用 Linux sendfile 系统调用
文件传输到网络的公共数据路径
1. 操作系统将数据从磁盘读入到内核空间的页缓存
2. 应用程序将数据从内核空间读入到用户空间缓存中
3. 应用程序将数据写回到内核空间到socket 缓存中
4. 操作系统将数据从socket缓冲区复制到网卡缓冲区,一便将数据经网络发出
零拷贝过程:(内核空间和用户空间零拷贝)
1.操作系统将数据从磁盘读入到内核空间的页缓存
2.将数据的位置和长度的信息的描述符增加至内核空间(socket缓存区)
3.操作系统将数据从内核拷贝到网卡缓冲区,以便将数据经网络发出
2、Kafka优点
高吞吐量、低延迟、高并发、高性能的消息中间件。Kafka 集群甚至可以做到每秒几十万、上百万的超高并发写入
页面缓存技术+磁盘顺序写+零拷贝技术
3、Kafka 应用场景
1. 消息对列
2. 行为跟踪(用户的行为跟踪直接发送到topic ,时时处理或离线数据存储)
3. 元数据监控(操作信息运维数据监控)
4. 日志收集
5. 流处理(收集上游流数据,经过处理,发布到新的topic 中,进行处理,中间可以进行实时计算、数据处理)
6. 事件源(将状态转移作为记录,按照时间顺序的序列,我们可以回溯整个时间的变更)
7. 持久性日志(commit log ,就是说在节点之后进行一个持久性日志记录,日志可以在节点间备份一份数据,并且给故障节点间恢复提供一种机制)