最近项目重构,用Caffeine+主从数据同步替代了Redis的功能,将原Redis中所有键值对迁移到一个大的Cache中存放。通过借鉴网上的博客资料,以及结合在项目中的实际使用,梳理整合了一下Caffeine。
一、简单介绍
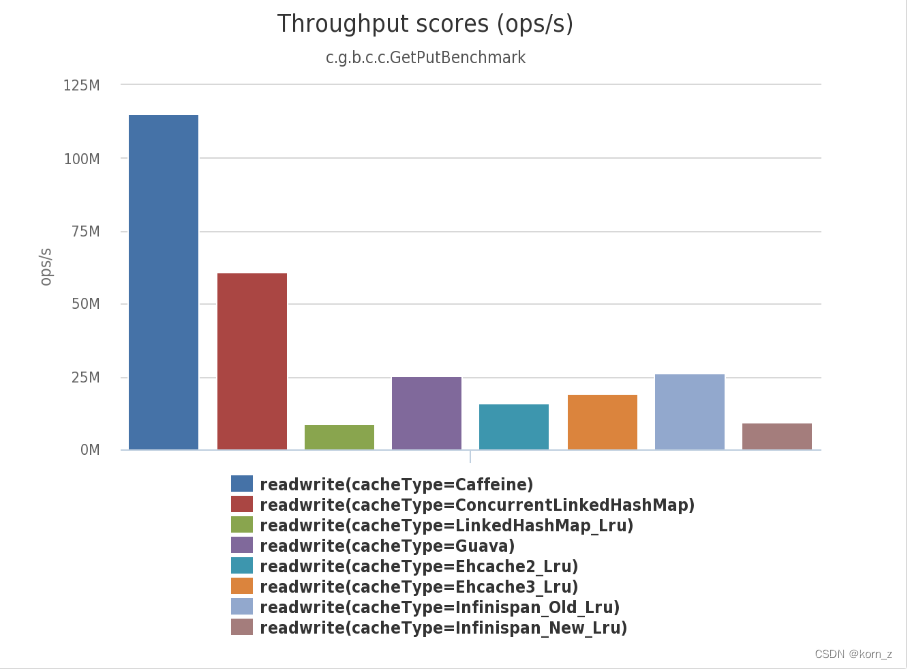
Caffeine的底层数据存储采用ConcurrentHashMap。在JDK8中ConcurrentHashMap增加了红黑树,在hash冲突严重时也能有良好的读性能。Caffeine是Spring 5默认支持的Cache,下面是它与其他缓存的对比图:
它能提供高命中率和出色的并发能力。
缓存的淘汰策略是为了预测哪些数据在短期内最可能被再次用到,从而提升缓存的命中率。LRU由于实现简单、高效的运行时表现以及在常规的使用场景下有不错的命中率,或许是目前最佳的实现途径。但LRU通过历史数据来预测未来是局限的,它会认为最后到来的数据是最可能被再次访问的,从而给与它最高的优先级。这样就意味着淘汰真正热点数据,为了解决这个问题业界运用一些数据结构上的改进巧妙的解决这个问题。
Caffeine提供了灵活的结构来创建缓存,并且有以下特性:
- 自动加载条目到缓存中,可选异步方式
- 可以基于大小剔除
- 可以设置过期时间,时间可以从上次访问或上次写入开始计算
- 异步刷新
- keys自动包装在弱引用中
- values自动包装在弱引用或软引用中
- 条目剔除通知
- 缓存访问统计
二、实际应用
1、在 pom.xml 中添加 caffeine 依赖
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.5.5</version>
</dependency>
2、使用JavaConfig方式配置Bean
@Configuration
public class BasicCommonCacheManager {
@Bean("basicCommonCache")
public Cache<String, CacheDataWrapper> initCache() {
return Caffeine.newBuilder()
// 设置软引用,当GC回收并堆内容空间不足,会回收缓存
.softValues()
// 初始的缓存空间大小
.initialCapacity(1000)
// 缓存的最大条数
.maximumSize(1000000)
// key过期策略
.expireAfter(new Expiry<Object, CacheDataWrapper>() {
//创建缓存设置过期时间,当TimeUnit参数为空时,不设置过期
@Override
public long expireAfterCreate(@Nonnull Object o, @Nonnull CacheDataWrapper cw, long l) {
if (cw.getUnit()!=null){
return cw.getUnit().toNanos(cw.getDelay());
}
return l;
}
//更新缓存(相同key)时,取新的过期时间设置
@Override
public long expireAfterUpdate(@Nonnull Object o, @Nonnull CacheDataWrapper cw, long l, long l1) {
if (cw.getUnit()!=null){
return cw.getUnit().toNanos(cw.getDelay());
}
return l;
}
//读完缓存不能影响过期时间
@Override
public long expireAfterRead(@Nonnull Object o, @Nonnull CacheDataWrapper cw, long l, long l1) {
return l1;
}
})
//缓存操作回调函数
.build();
}
}
Caffeine 类相当于建造者模式的 Builder 类,通过 Caffeine 类配置 Cache,配置一个Cache 有如下参数:
expireAfterWrite:写入间隔多久淘汰;
expireAfterAccess:最后访问后间隔多久淘汰;
refreshAfterWrite:写入后间隔多久刷新,该刷新是基于访问被动触发的,支持异步刷新和同步刷新,如果和 expireAfterWrite 组合使用,能够保证即使该缓存访问不到、也能在固定时间间隔后被淘汰,否则如果单独使用容易造成OOM;
expireAfter:自定义淘汰策略,该策略下 Caffeine 通过时间轮算法来实现不同key 的不同过期时间;
maximumSize:缓存 key 的最大个数;weakKeys:key设置为弱引用,在 GC 时可以直接淘汰;
weakValues:value设置为弱引用,在 GC 时可以直接淘汰;
softValues:value设置为软引用,在内存溢出前可以直接淘汰;
executor:选择自定义的线程池,默认的线程池实现是 ForkJoinPool.commonPool();
maximumWeight:设置缓存最大权重;weigher:设置具体key权重;
recordStats:缓存的统计数据,比如命中率等;
removalListener:缓存淘汰监听器;writer:缓存写入、更新、淘汰的监听器
其中.expireAfter()方法是实现了Expiry的三个方法自定义每个key不同的过期时间(网上不易找到详细的说明,在这个地方踩了不少坑)
-
expireAfterCreate(@Nonnull Object o, @Nonnull CacheDataWrapper cw, long l)
创建键值对后多少时间过期;
在此方法内将封装的过期时间取出来处理后转为纳秒返回,如果不需要设置过期时间直接retun l;
其中CacheDataWrapper 是对Value的一层包装如下:
@Data
@NoArgsConstructor
public class CacheDataWrapper {
//缓存内容
private Object data;
//缓存过期时间
private long delay;
//缓存过期时间单位
private TimeUnit unit;
public CacheDataWrapper(Object data, long delay, TimeUnit unit) {
this.data = data;
this.delay = delay;
this.unit = unit;
}
}
- expireAfterUpdate(@Nonnull Object o, @Nonnull CacheDataWrapper cw, long l, long l1)
更新缓存后多少时间过期;
比如:put时,key已存在,此时
//put后不影响第一次设置的过期时间
return l1
//put后该key永久不过期
return l
//put后从封装类中拿自定义的时间
return cw.getUnit().toNanos(cw.getDelay())
-
expireAfterRead(@Nonnull Object o, @Nonnull CacheDataWrapper cw, long
l, long l1)获取缓存后多少时间过期;
//获取后不影响第一次设置的过期时间
return l1
//获取后该key永久不过期
return l
//获取后从封装类中拿自定义的时间
return cw.getUnit().toNanos(cw.getDelay())```
3、创建缓存工具类
@Slf4j
@Component
public class BasicCommonCacheUtils {
//通用共享缓存
private static Cache<String, CacheDataWrapper> basicCommonCache;
@Resource(name = "basicCommonCache")
private Cache<String, CacheDataWrapper> basicCache;
//外层key和hash的Key用:连接作为新key存储hash的Value
private static String SEPARATOR = ":";
/**
* 1.@Resouece注入实例属性后赋值给静态变量
*/
@PostConstruct
public void init() {
this.basicCommonCache = basicCache;
}
/**
* 获取所有keys
*
* @return
*/
public static Set<String> getAllKeys() {
return basicCommonCache.asMap().keySet();
}
/**
* 获取所有缓存
*
* @return
*/
public static Map<String, CacheDataWrapper> getAllCache() {
return basicCommonCache.asMap();
}
/**
* 判断key是否存在 K:V
*
* @param key
* @return Boolean 是否存在
*/
public static Boolean exist(final String key) {
return basicCommonCache.asMap().containsKey(key);
}
/**
* 判断hashKey是否存在
*
* @param key
* @return Boolean 是否存在
*/
public static Boolean existHash(final String key, final String field) {
Set<String> keys = basicCommonCache.asMap().keySet();
if (keys.contains(key + SEPARATOR + field)) {
return true;
}
return false;
}
/**
* 存入缓存set
*
* @param key key
* @param value value
*/
public static void set(final String key, final Object value) {
try {
basicCommonCache.put(key, new CacheDataWrapper(value, 0l, null));
//涉及缓存变动时,采用okhttp异步发送请求更新从服务缓存数据
masterSynchroDataToSlave(SET_VALUE, null,new RequetParamForCacheDto(key, value));
} catch (Exception e) {
throw new CacheException(String.format("存入缓存异常:【%s】", e.getMessage()), e);
}
}
/**
* 存入缓存set,+ 过期时间
*
* @param key
* @param value
* @param expire
* @param unit
*/
public static void set(final String key, final Object value, final Long expire, TimeUnit unit) {
try {
basicCommonCache.put(key, new CacheDataWrapper(value, expire, unit));
//涉及缓存变动时,采用okhttp异步发送请求更新从服务缓存数据
masterSynchroDataToSlave(SET_VALUE_WITH_EXPIRE, null,new RequetParamForCacheDto(key, value,expire,unit));
} catch (Exception e) {
throw new CacheException(String.format("存入缓存异常:【%s】", e.getMessage()), e);
}
}
/**
* 存入缓存 hput
*
* @param key
* @param field
* @param value
*/
public static void hPut(final String key, final String field, final Object value) {
try {
basicCommonCache.put(key + SEPARATOR + field, new CacheDataWrapper(value, 0l, null));
//涉及缓存变动时,采用okhttp异步发送请求更新从服务缓存数据
masterSynchroDataToSlave(PUT_HASH,null,new RequetParamForCacheDto(key,field,value));
} catch (Exception e) {
throw new CacheException(String.format("存入缓存异常:【%s】", e.getMessage()), e);
}
}
/**
* 存入缓存 hput + 过期时间
*
* @param key
* @param field
* @param value
* @param unit
*/
public static void hPut(final String key, final String field, final Object value, final Long expire, TimeUnit unit) {
try {
basicCommonCache.put(key + SEPARATOR + field, new CacheDataWrapper(value, expire, unit));
//涉及缓存变动时,采用okhttp异步发送请求更新从服务缓存数据
masterSynchroDataToSlave(PUT_HASH_WITH_EXPIRE,null,new RequetParamForCacheDto(key,field,value,expire,unit));
} catch (Exception e) {
throw new CacheException(String.format("存入缓存异常:【%s】", e.getMessage()), e);
}
}
/**
* String类型 获取缓存
*
* @param key 键
* @return Object 缓存
*/
public static Object get(final String key) {
try {
return basicCommonCache.getIfPresent(key).getData();
} catch (Exception e) {
throw new CacheException(String.format("获取缓存异常:【%s】", e.getMessage()), e);
}
}
/**
* Hash类型 获取缓存
*
* @param key key
* @param field field
* @return Object 缓存
*/
public static Object hGet(final String key, final String field) {
try {
return basicCommonCache.getIfPresent(key + SEPARATOR + field).getData();
} catch (Exception e) {
throw new CacheException(String.format("获取缓存异常:【%s】", e.getMessage()), e);
}
}
/**
* 删除指定key
*
* @param key key
*/
public static void delKey(final String key) {
try {
basicCommonCache.invalidate(key);
HashMap<String,String> map=new HashMap<>();
map.put("key",key);
masterSynchroDataToSlave(DEL_KEY,map,null);
Set<String> hashSet = basicCommonCache.asMap().keySet();
String pre = key + SEPARATOR;
//判断若存在hashKey,删除所有hashKey
List<String> sortedList = new ArrayList<>(hashSet);
for (String s : sortedList) {
if (s.startsWith(pre)) {
basicCommonCache.invalidate(s);
HashMap<String,String> map2=new HashMap<>();
map2.put("key",s);
masterSynchroDataToSlave(DEL_KEY,map2,null);
}
}
} catch (Exception e) {
throw new CacheException(String.format("删除缓存异常:【%s】", e.getMessage()), e);
}
}
}
三、具体分析
1.缓存填充算法
Caffeine 提供了三种缓存填充策略:手动、同步和异步加载。
- 手动加载
每次通过 get key 的时候可以指定一个同步的函数,当 key 不存在时调用函数生成 value 同时将 KV 存入 Cache 中。
Cache<String, Object> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.MINUTES)
.maximumSize(100)
.build();
String key = "hello";
// 使用getIfPresent方法,如果缓存中不存在该值,则此方法将返回null
Object o = cache.getIfPresent(key);
// 使用put方法手动填充缓存
cache.put(key, "world");
// 通过get方法获取值,如果键在缓存中不存在,则此函数将用于提供备用值,该键将在计算后插入到缓存中
cache.get(key, value -> "world");
// 手动使某些缓存的值无效
cache.invalidate(key);
get 方法优于 getIfPresent,因为 get 方法是原子操作,即使多个线程同时要求该值,计算也只进行一次
- 同步加载
构造 Cache 的时候,build 方法中传入 CacheLoader 的实现类,重写 load 方法,通过 key 可以加载 value。
/**
* 方式一
*/
public Object syncLoad(String key) {
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.MINUTES)
.maximumSize(100)
.build(new CacheLoader<String, Object>() {
@Nullable
@Override
public Object load(@NonNull String key) throws Exception {
return key + " world";
}
});
return cache.get(key);
}
/**
* 方式二
*/
public Object syncLoad1(String key) {
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.MINUTES)
.maximumSize(100)
.build(k -> setValue(key).get());
return cache.get(key);
}
public Supplier<Object> setValue(String key) {
return () -> key + " world";
}
- 异步加载
该策略与同步加载策略相同,但是异步执行操作,并返回保存实际值的 CompletableFuture。可以调用 get 或 getAll 方法调用获取返回值。
/**
* 方式一
*/
public Object asyncLoad(String key) {
AsyncLoadingCache<String, Object> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.MINUTES)
.maximumSize(100)
.buildAsync(new AsyncCacheLoader<String, Object>() {
@Override
public @NonNull CompletableFuture<Object> asyncLoad(@NonNull String key, @NonNull Executor executor) {
return CompletableFuture.supplyAsync(() -> key + " world", executor);
}
});
return cache.get(key);
}
/**
* 方式二
*/
public Object asyncLoad1(String key) {
AsyncLoadingCache<String, Object> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.MINUTES)
.maximumSize(100)
.buildAsync(k -> setValue(key).get());
return cache.get(key);
}
public CompletableFuture<Object> setValue(String key) {
return CompletableFuture.supplyAsync(() -> key + " world");
}
2.驱逐策略
Caffeine 提供三种数据驱逐策略:基于大小驱逐、基于时间驱逐、基于引用驱逐。
- 基于大小 (Size-Based) 的驱逐策略
基于大小的驱逐策略有两种方式:一种是基于缓存数量,一种是基于权重。maximumSize 与 maximumWeight 不可同时使用。
public void sizeBasedEviction() {
// 根据缓存的数量进行驱逐
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(10000)
.build(key -> function(key));
// 根据缓存的权重来进行驱逐(权重只是用于确定缓存大小,不会用于决定该缓存是否被驱逐)
LoadingCache<String, Object> cache1 = Caffeine.newBuilder()
.maximumWeight(10000)
.weigher(key -> function1(key))
.build(key -> function(key));
}
- 基于时间 (Time-Based) 的驱逐策略
基于时间的驱逐策略有三种类型:
expireAfterAccess (long, TimeUnit):在最后一次访问或者写入后开始计时,在指定的时间后过期。假如一直有请求访问该 key,那么这个缓存将一直不会过期。
expireAfterWrite(long, TimeUnit): 在最后一次写入缓存后开始计时,在指定的时间后过期。
expireAfter(Expiry): 自定义策略,过期时间由 Expiry 实现独自计算。
缓存的删除策略使用的是惰性删除和定时删除。
public void timeBasedEviction() {
// 基于固定的到期策略进行退出
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.expireAfterAccess(5, TimeUnit.MINUTES)
.build(key -> function(key));
LoadingCache<String, Object> cache1 = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(key -> function(key));
// 基于不同的到期策略进行退出
LoadingCache<String, Object> cache2 = Caffeine.newBuilder()
.expireAfter(new Expiry<String, Object>() {
@Override
public long expireAfterCreate(String key, Object value, long currentTime) {
return TimeUnit.SECONDS.toNanos(seconds);
}
@Override
public long expireAfterUpdate(@Nonnull String s, @Nonnull Object o, long l, long l1) {
return 0;
}
@Override
public long expireAfterRead(@Nonnull String s, @Nonnull Object o, long l, long l1) {
return 0;
}
}).build(key -> function(key));
}
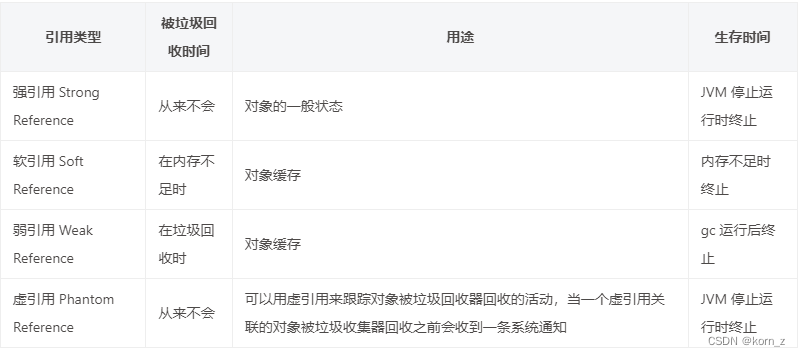
- 基于引用 (Reference-Based) 的驱逐
Java 中四种引用类型:
public void referenceBasedEviction() {
// 当key和value都弱引用时驱逐缓存
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.build(key -> function(key));
// 当垃圾收集器需要释放内存时驱逐
LoadingCache<String, Object> cache1 = Caffeine.newBuilder()
.softValues()
.build(key -> function(key));
}
注意:
- AsyncLoadingCache 不支持弱引用和软引用。
- Caffeine.weakValues () 和 Caffeine.softValues () 不可以一起使用。
3、移除监听器(Removal)
概念理解:
- 驱逐(eviction):由于满足了某种驱逐策略,后台自动进行的删除操作
- 无效(invalidation):表示由调用方手动删除缓存
- 移除(removal):监听驱逐或无效操作的监听器
public void removalListener() {
Cache<String, Object> cache = Caffeine.newBuilder()
.removalListener((String key, Object value, RemovalCause cause) ->
System.out.printf("Key %s was removed (%s)%n", key, cause))
.build();
}
您可以通过Caffeine.removalListener(RemovalListener)为缓存指定一个删除监听器,以便在删除数据时执行某些操作。RemovalListener可以获取到key、value和RemovalCause(删除的原因)。
删除监听器的里面的操作是使用Executor来异步执行的。默认执行程序是ForkJoinPool.commonPool(),可以通过Caffeine.executor(Executor)覆盖。当操作必须与删除同步执行时,请改为使用CacheWrite;
4、淘汰算法
4.1、常见算法
对于 Java 进程内缓存我们可以通过 HashMap 来实现。不过,Java 进程内存是有限的,不可能无限地往里面放缓存对象。这就需要有合适的算法辅助我们淘汰掉使用价值相对不高的对象,为新进的对象留有空间。常见的缓存淘汰算法有 FIFO、LRU、LFU。
FIFO(First In First Out):先进先出。
它是优先淘汰掉最先缓存的数据、是最简单的淘汰算法。缺点是如果先缓存的数据使用频率比较高的话,那么该数据就不停地进进出出,因此它的缓存命中率比较低。
LRU(Least Recently Used):最近最久未使用。
它是优先淘汰掉最久未访问到的数据。缺点是不能很好地应对偶然的突发流量。比如一个数据在一分钟内的前59秒访问很多次,而在最后1秒没有访问,但是有一批冷门数据在最后一秒进入缓存,那么热点数据就会被冲刷掉。
LFU(Least Frequently Used):
最近最少频率使用。它是优先淘汰掉最不经常使用的数据,需要维护一个表示使用频率的字段。
主要有两个缺点:
一、如果访问频率比较高的话,频率字段会占据一定的空间;
二、无法合理更新新上的热点数据,比如某个歌手的老歌播放历史较多,新出的歌如果和老歌一起排序的话,就永无出头之日。
4.2、W-TinyLFU 算法
Caffeine 使用了 W-TinyLFU 算法,解决了 LRU 和LFU上述的缺点。W-TinyLFU 算法由论文《TinyLFU: A Highly Efficient Cache Admission Policy》提出。
它主要干了两件事:
一、采用 Count–Min Sketch 算法降低频率信息带来的内存消耗;
二、维护一个PK机制保障新上的热点数据能够缓存。
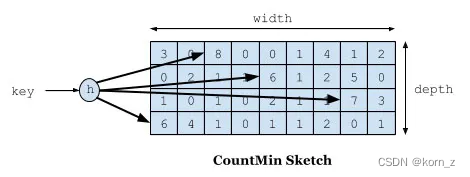
如下图所示,Count–Min Sketch 算法类似布隆过滤器 (Bloom filter)思想,对于频率统计我们其实不需要一个精确值。存储数据时,对key进行多次 hash 函数运算后,二维数组不同位置存储频率(Caffeine 实际实现的时候是用一维 long 型数组,每个 long 型数字切分成16份,每份4bit,默认15次为最高访问频率,每个key实际 hash 了四次,落在不同 long 型数字的16份中某个位置)。读取某个key的访问次数时,会比较所有位置上的频率值,取最小值返回。对于所有key的访问频率之和有个最大值,当达到最大值时,会进行reset即对各个缓存key的频率除以2。
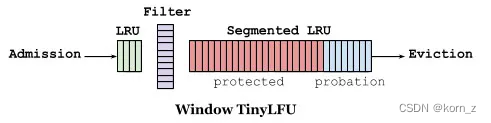
如下图缓存访问频率存储主要分为两大部分,即 LRU 和 Segmented LRU 。新访问的数据会进入第一个 LRU,在 Caffeine 里叫 WindowDeque。当 WindowDeque 满时,会进入 Segmented LRU 中的 ProbationDeque,在后续被访问到时,它会被提升到 ProtectedDeque。当 ProtectedDeque 满时,会有数据降级到 ProbationDeque 。数据需要淘汰的时候,对 ProbationDeque 中的数据进行淘汰。具体淘汰机制:取ProbationDeque 中的队首和队尾进行 PK,队首数据是最先进入队列的,称为受害者,队尾的数据称为攻击者,比较两者 频率大小,大胜小汰。
总的来说,通过 reset 衰减,避免历史热点数据由于频率值比较高一直淘汰不掉,并且通过对访问队列分成三段,这样避免了新加入的热点数据早早地被淘汰掉。
5、高性能读写
Caffeine 认为读操作是频繁的,写操作是偶尔的,读写都是异步线程更新频率信息
5.1、读缓冲
传统的缓存实现将会为每个操作加锁,以便能够安全的对每个访问队列的元素进行排序。一种优化方案是将每个操作按序加入到缓冲区中进行批处理操作。读完把数据放到环形队列 RingBuffer 中,为了减少读并发,采用多个 RingBuffer,每个线程都有对应的 RingBuffer。环形队列是一个定长数组,提供高性能的能力并最大程度上减少了 GC所带来的性能开销。数据丢到队列之后就返回读取结果,类似于数据库的WAL机制,和ConcurrentHashMap 读取数据相比,仅仅多了把数据放到队列这一步。异步线程并发读取 RingBuffer 数组,更新访问信息,这边的线程池使用的是下文实战小节讲的 Caffeine 配置参数中的 executor。
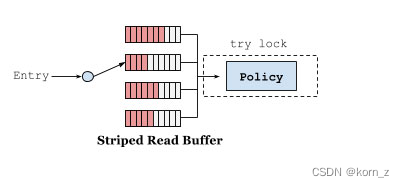
5.2、写缓冲
与读缓冲类似,写缓冲是为了储存写事件。读缓冲中的事件主要是为了优化驱逐策略的命中率,因此读缓冲中的事件完整程度允许一定程度的有损。但是写缓冲并不允许数据的丢失,因此其必须实现为一个安全的队列。Caffeine 写是把数据放入MpscGrowableArrayQueue 阻塞队列中,它参考了JCTools里的MpscGrowableArrayQueue ,是针对 MPSC- 多生产者单消费者(Multi-Producer & Single-Consumer)场景的高性能实现。多个生产者同时并发地写入队列是线程安全的,但是同一时刻只允许一个消费者消费队列。