上篇:机器学习(五) -- 监督学习(5) -- 线性回归1
下篇:
前言
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
三、***算法实现
为了加深理解哈,其实在日常中一般调用API。
1、获取数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib notebook
# 读入数据
train =pd.read_csv('csv/click.csv')
train_x=train['x']
train_y=train['y']
# 查看数据
plt.figure()
plt.scatter(train_x,train_y,c='r',marker='.')
# plt.plot(train_x,train_y,'ro')
plt.show() 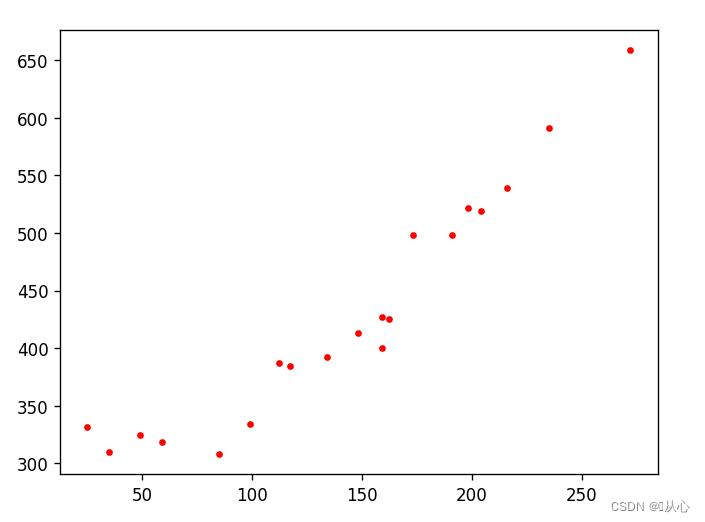
2、定义模型
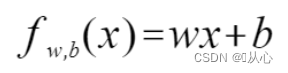
# 预测函数-定义模型
def f(x):
return theta0+theta1*x3、目标函数

# 目标函数
def E(x,y):
return 0.5*np.sum((y-f(x))**2)4、参数估计
先进行标准化,后绘图验证
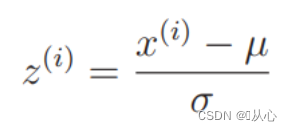
# 标准化、z-score规范化
mu = train_x.mean()
sigma = train_x.std()
def standardize(x):
return (x - mu) / sigma
train_z=standardize(train_x)
# 绘图
plt.figure()
plt.plot(train_z,train_y,'go')
plt.show()参数初始化、学习率等的设置
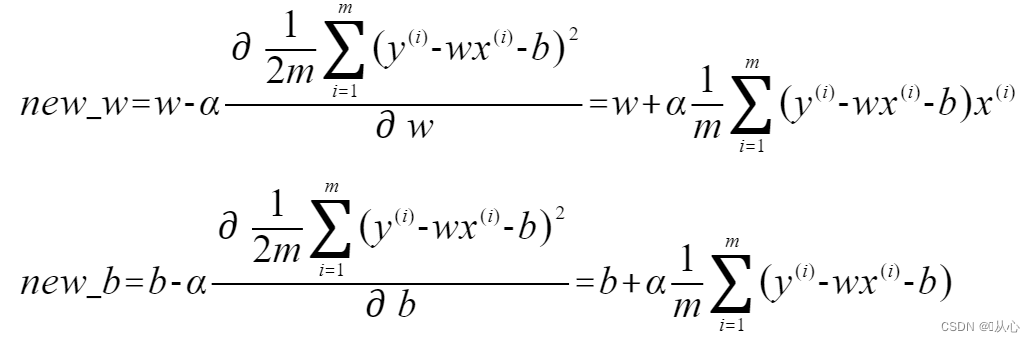
# 参数初始化
theta0=np.random.randn()
theta1=np.random.randn()
# 学习率
ETA = 1e-3 # 0.001
# 误差的差值
diff = 1
# 更新次数
count = 0
# 重复学习
error = E(train_z, train_y)
while diff > 1e-2:
# 更新结果保存到临时变量(防止更新1时使用更新后的0)
tmp_theta0 = theta0 - ETA * np.sum((f(train_z) - train_y))
tmp_theta1 = theta1 - ETA * np.sum((f(train_z) - train_y) * train_z)
# 更新参数
theta0 = tmp_theta0
theta1 = tmp_theta1
# 计算与上一次误差的差值
current_error = E(train_z, train_y)
diff = error - current_error
error = current_error
# 输出日志
count += 1
log = '第 {} 次 : theta0 = {:.3f}, theta1 = {:.3f}, 差值 = {:.4f}'
print(log.format(count, theta0, theta1, diff))
# 绘图确认
x = np.linspace(-3, 3, 100)# 定义均匀间隔创建数值序列
plt.figure()
# 数据点
plt.plot(train_z, train_y, 'o')
# 模型
plt.plot(x, f(x))
plt.show() 
5、验证
# 验证
x1=standardize(100)
y1=f(x1)
print(y1) # 370.9798855192978
plt.plot(x1,y1,'*')
四、接口调用--实际应用
1、波士顿数据集介绍
1.1、API
from sklearn.datasets import load_boston!!!导入波士顿数据集报错
ImportError:
`load_boston` has been removed from scikit-learn since version 1.2.
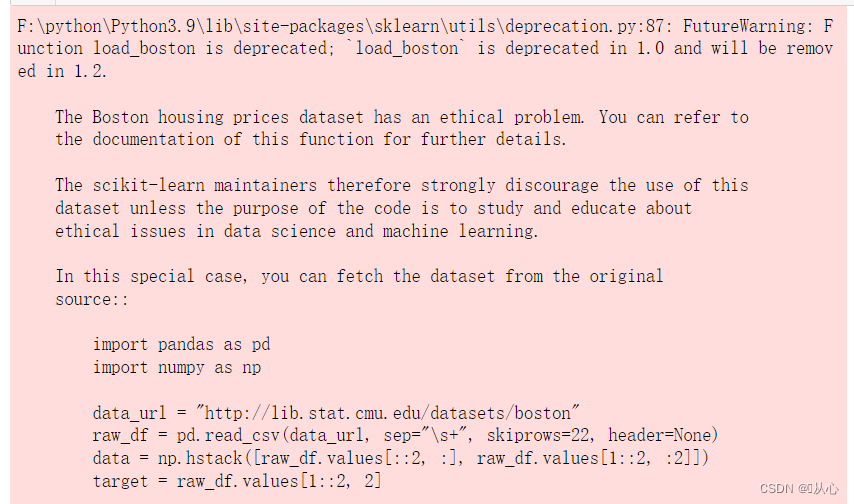
因为数据集涉及种族问题,所以在sklearn 1.2版本中被移除。
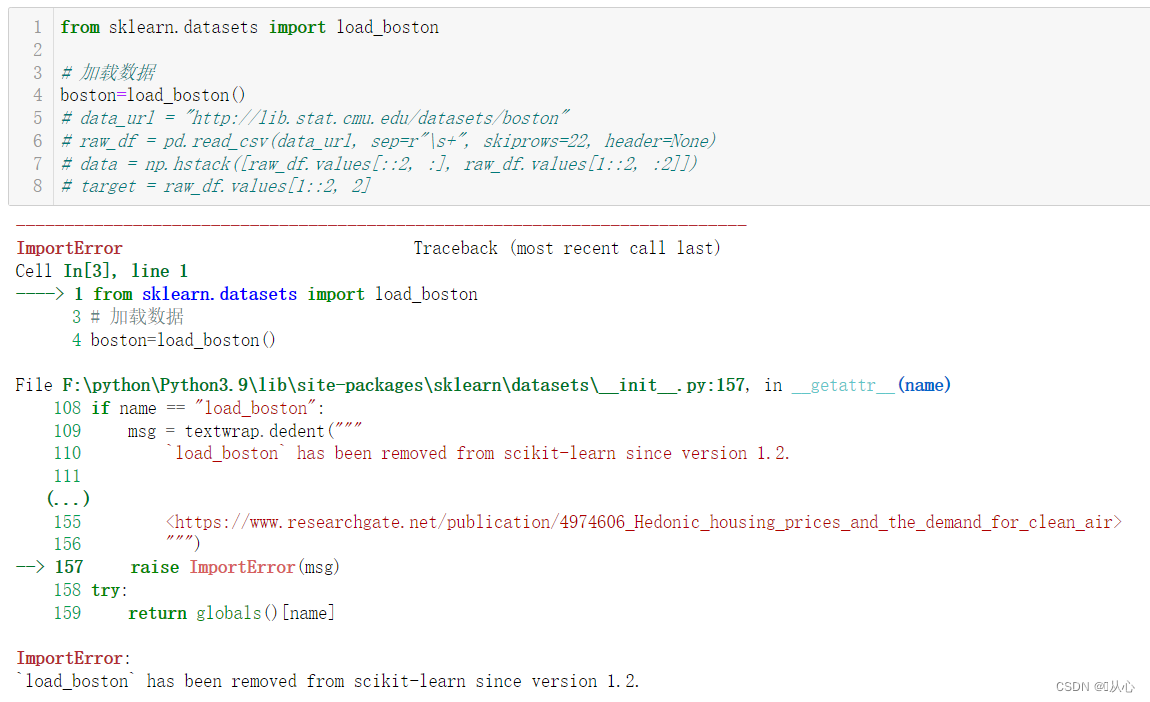
解决1:用在线网址导入(建议)
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep=r"\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]解决2:降低scikit-learn版本(不推荐,后面还有其他问题)
pip install -U scikit-learn==1.1.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
在jupyter中记得先查看库的环境哦(我这里是已经降级后的)
当然降级后还是有点问题
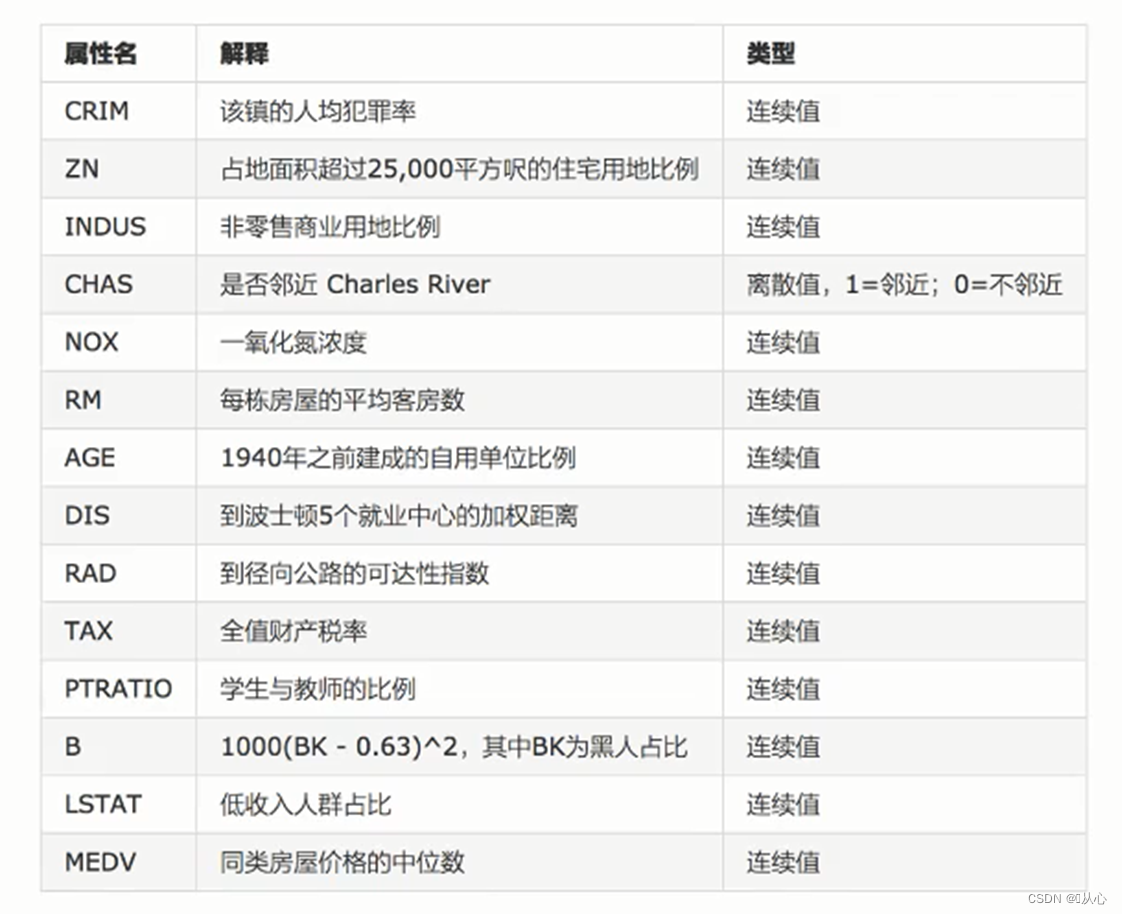
1.2、介绍
波士顿房价数据集共有506个样本,每个样本有13个特征及输出标签MEDV
特征信息:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
np.random.seed(1734)
#将生成的交互式图嵌入notebook中
%matplotlib notebook
#将生成的静态图嵌入notebook中
%matplotlib inline
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置字体为SimHei # 显示中文
plt.rcParams['axes.unicode_minus']=False # 修复负号问题
from sklearn.datasets import load_boston
# 加载数据
boston=load_boston()
# 键
print("波士顿房价数据集的键:",boston.keys())
# 描述
print("波士顿房价数据集的描述:",boston.DESCR)
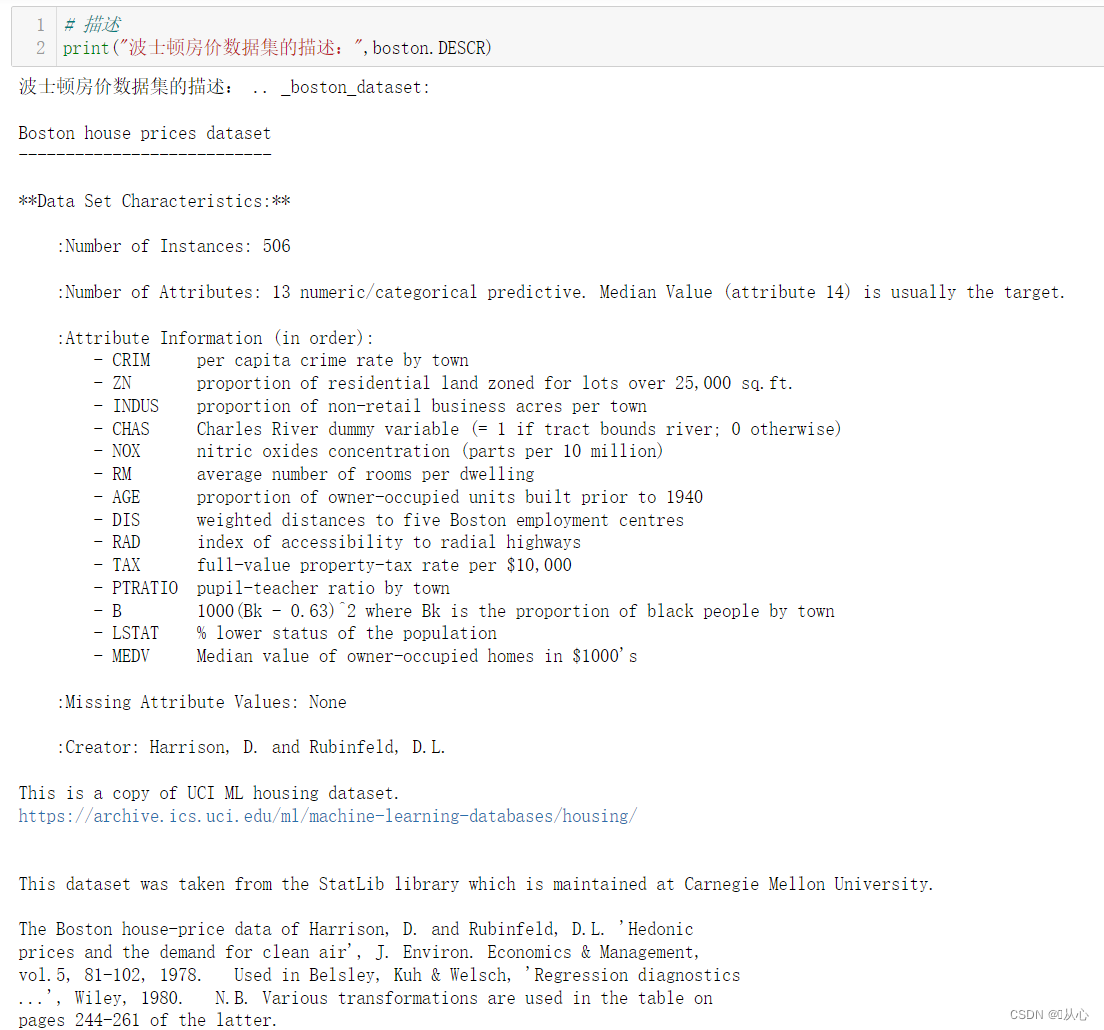
# 特征值名字
print("波士顿房价数据集的特征值名字:",boston.feature_names)
# 返回值、特征值、目标值
print("波士顿房价数据集的返回值:\n", boston)
# 数据形状
print("波士顿房价数据集的形状:",boston.data.shape)
print("波士顿房价数据集的特征值:",boston.data)
print("波士顿房价数据集的目标值:",boston.target)
1.3、可视化--查看数据分布(一个特征)
# 只展示一个属性对房价的影响
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(boston.data, boston.target, test_size=0.2, random_state=1473)
# 选择RM属性
rm=x_train[:,5]
prices=y_train
# 可视化
plt.figure()
plt.scatter(rm,prices)
plt.xlabel('rm')
plt.ylabel('prices')
plt.show()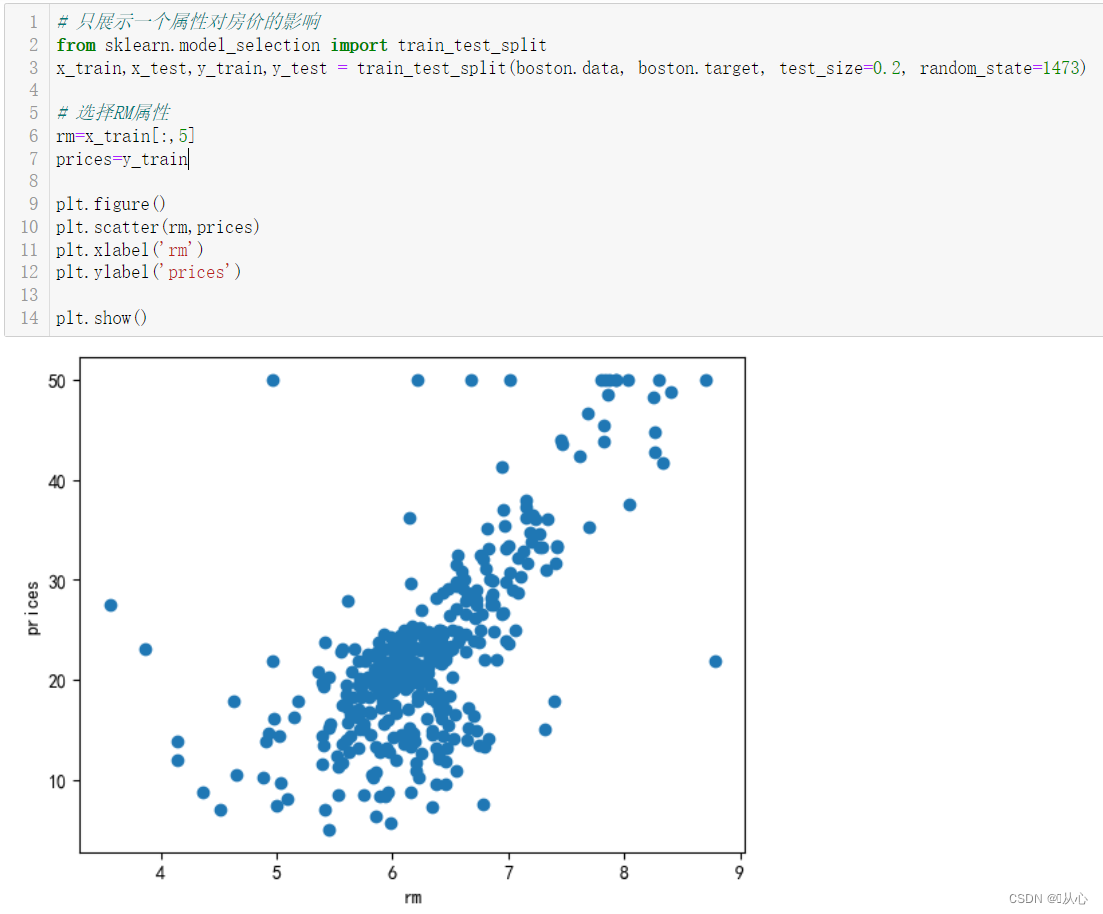
2、正规方程流程
2.0、正规方程API
sklearn.linear_model.LinearRegression
导入:
from sklearn.linear_model import LinearRegression
语法:
LinearRegression(fit_intercept=5,copy_X='auto',n_jobs)
# 通过正规方程优化
fit_intercept: 默认为True,是否在模型中包含截距(偏置)项
copy_X:默认为True,是否复制输入特征数据。
n_jobs:默认为None,模型拟合过程中的CPU核心数量,设置为-1,则使用所有可用的核心。
LinearRegression.coef_:回归系数coefficients
LinearRegression.intercept_:偏置2.1、获取数据
# from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
# 获取数据
# boston=load_boston()
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep=r"\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]2.2、数据预处理(划分数据集)
# 划分数据集
# x_train,x_test,y_train,y_test = train_test_split(boston.data, boston.target, test_size=0.2, random_state=1473)
# 划分数据集
x_train,x_test,y_train,y_test = train_test_split(data, target, test_size=0.2, random_state=1473) 2.4、特征工程
# # 标准化
# # 特征值和目标值是都必须进行标准化处理, 实例化两个标准化API
# # 特征值进行了标准化
# std_x = StandardScaler()
# x_train = std_x.fit_transform(x_train)
# x_test = std_x.transform(x_test)
# # 目标值进行了标准化(标准化只支持2维数据)
# std_y = StandardScaler()
# y_train = std_y.fit_transform(y_train.reshape(-1, 1)) # 目标值是一维的,这里需要传进去2维的
# y_test = std_y.transform(y_test.reshape(-1, 1))2.4、模型训练
#实例化学习器+模型训练(正规方程)
lr = LinearRegression().fit(x_train, y_train)
print('建立的LinearRegression模型为:', '\n', lr) 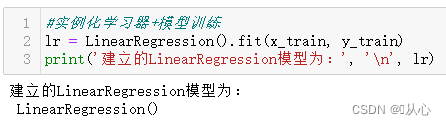
2.5、模型评估
# 用模型计算测试值,得到预测值
y_pred = lr.predict(x_test)
# # 特征工程后做:
# # 预测测试集的房子价格,通过inverse得到真正的房子价格
# y_pred = std_y.inverse_transform(y_pred)
print('预测前20个结果为:', '\n', y_pred[:20])
print("模型中的系数为:\n", lr.coef_)
print("模型中的偏置为:\n", lr.intercept_)
#
from sklearn.metrics import explained_variance_score, mean_absolute_error,mean_squared_error,median_absolute_error,r2_score
print('Boston数据线性回归模型的平均绝对误差为:', mean_absolute_error(y_test, y_pred))
print('Boston数据线性回归模型的均方误差为:', mean_squared_error(y_test, y_pred))
print('Boston数据线性回归模型的中值绝对误差为:',median_absolute_error(y_test, y_pred))
print('Boston数据线性回归模型的可解释方差值为:',explained_variance_score(y_test, y_pred))
print('Boston数据线性回归模型的R方值为:', r2_score(y_test, y_pred))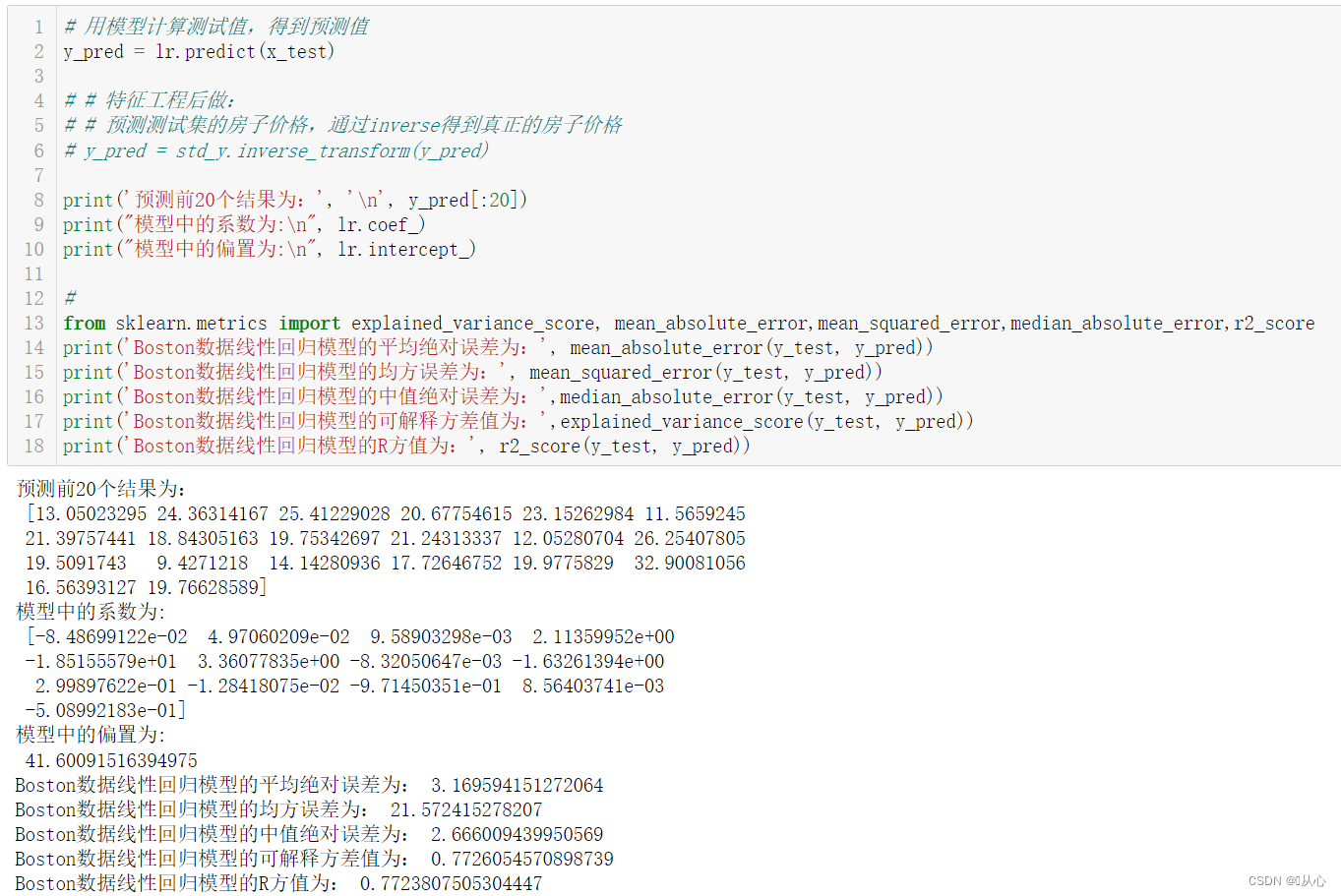
2.6、结果预测
x_real=[[0.00632,18.00,2.310,0,0.5380,6.5750,65.20,4.0900,1,296.0,15.30,396.90,4.98]]
y_real_pred = lr.predict(x_real)
print(y_real_pred)
2.7、模型保存
文件格式为“pkl”
import joblib
# 保存训练好的模型
joblib.dump(lr, "./model/lr_test.pkl")
2.8、模型载入
# 加载保存的模型
lr2 = joblib.load("./model/lr_test.pkl")
# 用加载的模型进行预测
x_real=[[0.00632,18.00,2.310,0,0.5380,6.5750,65.20,4.0900,1,296.0,15.30,396.90,4.98]]
y_real_pred = lr2.predict(x_real)
# # 因为目标值进行了标准化,一定要把预测后的值逆向转换回来
# y_real_pred = std_y.inverse_transform(y_real_pred)
print(y_real_pred)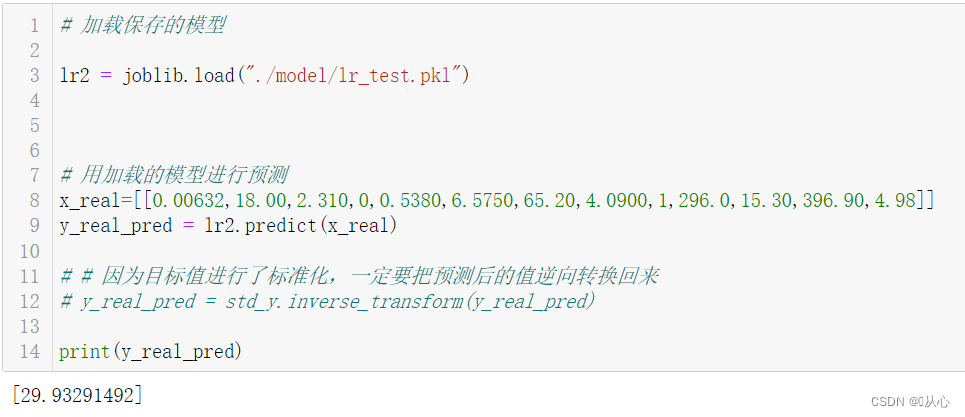
3、梯度下降流程
3.0 、梯度下降API
sklearn.linear_model.SGDRegressor
导入:
from sklearn.linear_model import SGDRegressor
语法:
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate='invscaling', eta0=0.01)
##SGDRegressor类实现了随机梯度下降学习,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型。
loss:损失类型,loss=”squared_loss”: 普通最小二乘法
fit_intercept:是否计算偏置
learning_rate : 学习率调整方式
'constant': eta = eta0
'optimal': eta = 1.0 / (alpha * (t + t0)) [default]
'invscaling': eta = eta0 / pow(t, power_t)
power_t=0.25:存在父类当中,对于一个常数值的学习率来说,可以使用learning_rate=’constant’ ,并使用eta0来指定学习率。
eta0:学习率调整数值
early_stopping:损失没有改进,提前停止训练
penalty:惩罚,分为L1和L2
alpha:正则化力度,值越高,正则化力度越强
SGDRegressor.coef_:回归系数
SGDRegressor.intercept_:偏置
L1 与 L2 的区别:
L1正则化产生稀疏的权值, L2正则化产生平滑的权值,
L1正则化偏向于稀疏,它会自动进行特征选择,去掉一些没用的特征,也就是将这些特征对应的权重置为0.
L2主要功能是为了防止过拟合,当要求参数越小时,说明模型越简单,而模型越简单则,越趋向于平滑,从而防止过拟合。
3.1、获取数据
# from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import SGDRegressor
# 获取数据
# boston=load_boston()
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep=r"\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]3.2、数据预处理(划分数据集)
# 划分数据集
# x_train,x_test,y_train,y_test = train_test_split(boston.data, boston.target, test_size=0.2, random_state=1473)
# 划分数据集
x_train,x_test,y_train,y_test = train_test_split(data, target, test_size=0.2, random_state=1473) 3.3、特征工程
3.4、模型训练
# 实例化学习器(梯度下降法)
SGDR = SGDRegressor(max_iter=1000)
# SGDR = SGDRegressor(max_iter=1000,learning_rate="constant",eta0=0.1)
# 模型训练
SGDR.fit(x_train,y_train)
print('建立的LinearRegression模型为:', '\n', SGDR)
3.5、模型评估
# 用模型计算测试值,得到预测值
y_pred = SGDR.predict(x_test)
print('预测前20个结果为:', '\n', y_pred[:20])
print("模型中的系数为:\n", SGDR.coef_)
print("模型中的偏置为:\n", SGDR.intercept_)
#
from sklearn.metrics import explained_variance_score, mean_absolute_error,mean_squared_error,median_absolute_error,r2_score
print('Boston数据线性回归模型的平均绝对误差为:',mean_absolute_error(y_test, y_pred))
print('Boston数据线性回归模型的均方误差为:',mean_squared_error(y_test, y_pred))
print('Boston数据线性回归模型的中值绝对误差为:',median_absolute_error(y_test, y_pred))
print('Boston数据线性回归模型的可解释方差值为:',explained_variance_score(y_test, y_pred))
print('Boston数据线性回归模型的R方值为:', r2_score(y_test, y_pred))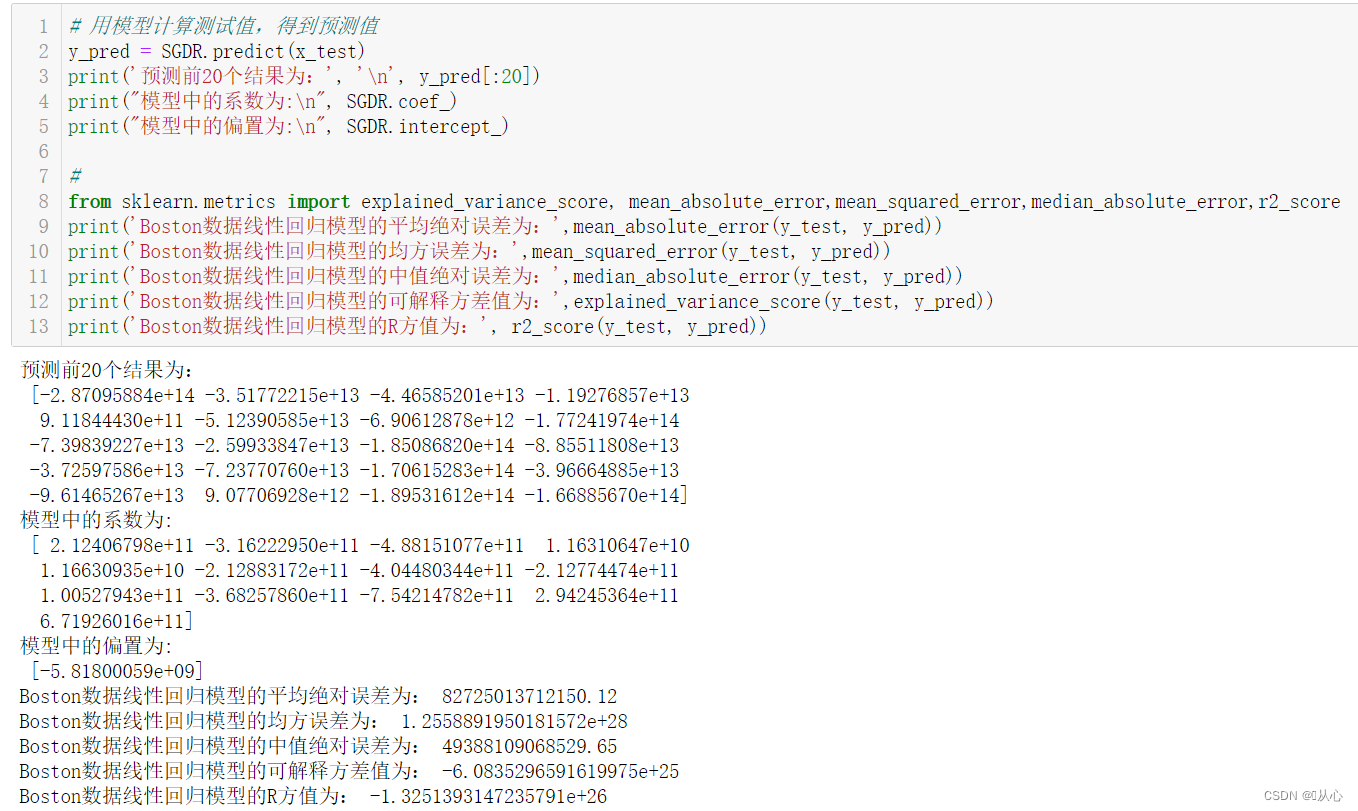
3.6、结果预测
经过模型评估后通过的模型可以代入真实值进行预测。
4、岭回归流程
4.0、岭回归API
sklearn.linear_model.Ridge
# 导入
from sklearn.linear_model import Ridge
# 语法
Ridge(alpha=1.0, fit_intercept=True,solver="auto", normalize=False)
具有l2正则化的线性回归
alpha:正则化力度,也叫 λ;λ取值:0~1 1~10
solver:会根据数据自动选择优化方法
sag:如果数据集、特征都比较大,选择该随机梯度下降优化
normalize:数据是否进行标准化
normalize=False:可以在fit之前调用preprocessing.StandardScaler标准化数据
Ridge.coef_:回归权重
Ridge.intercept_:回归偏置
sklearn.linear_model.RidgeCV(_BaseRidgeCV, RegressorMixin)
具有l2正则化的线性回归,可以进行交叉验证
RidgeCV.coef_:回归系数
class _BaseRidgeCV(LinearModel):
def __init__(self, alphas=(0.1, 1.0, 10.0),
fit_intercept=True, normalize=False,scoring=None,
cv=None, gcv_mode=None,
store_cv_values=False):Ridge方法相当于SGDRegressor(penalty='l2', loss="squared_loss"),只不过SGDRegressor实现了一个普通的随机梯度下降学习,推荐使用Ridge(实现了SAG)
注意观察正则化程度的变化,对结果的影响
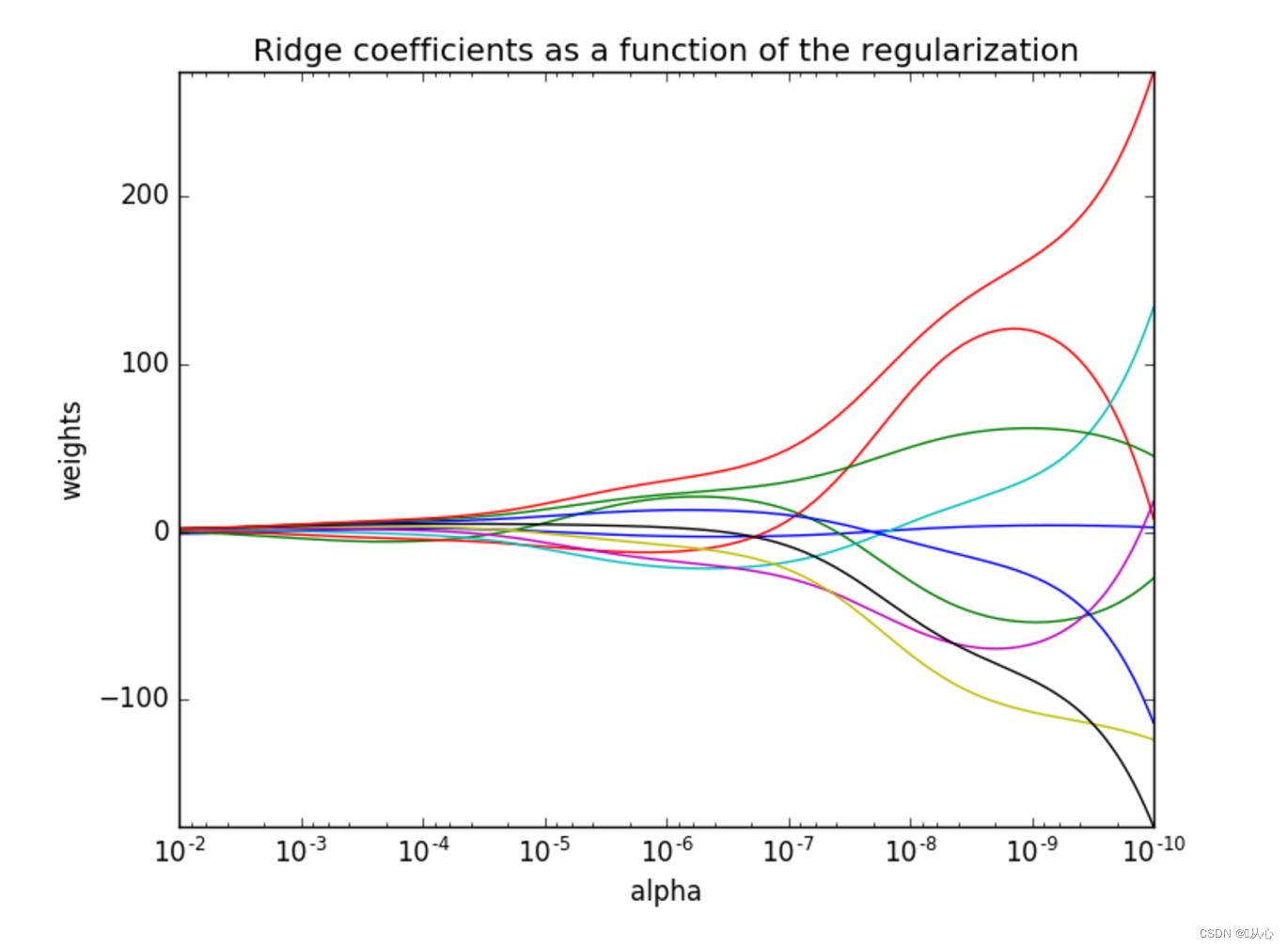
4.1、获取数据
# from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import SGDRegressor
# 获取数据
# boston=load_boston()
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep=r"\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]4.2、数据预处理(划分数据集)
# 划分数据集
# x_train,x_test,y_train,y_test = train_test_split(boston.data, boston.target, test_size=0.2, random_state=1473)
# 划分数据集
x_train,x_test,y_train,y_test = train_test_split(data, target, test_size=0.2, random_state=1473) 4.3、特征工程
# # 标准化
# # 特征值和目标值是都必须进行标准化处理, 实例化两个标准化API
# # 特征值进行了标准化
# std_x = StandardScaler()
# x_train = std_x.fit_transform(x_train)
# x_test = std_x.transform(x_test)
# # 目标值进行了标准化(标准化只支持2维数据)
# std_y = StandardScaler()
# y_train = std_y.fit_transform(y_train.reshape(-1, 1)) # 目标值是一维的,这里需要传进去2维的
# y_test = std_y.transform(y_test.reshape(-1, 1))4.4、模型训练
#实例化学习器
rr = Ridge(alpha=1)
# 模型训练
rr.fit(x_train,y_train)
print('建立的岭回归模型为:', '\n', rr)

!!!注意:
调用Ridge这个模型的 fit() 方法时,报了一个很诡异的错误:
TypeError: solve() got an unexpected keyword argument 'sym_pos'


通过反复试验,发现是scikit-learn版本的问题,为了直接使用波士顿数据集,之前回退安装了scikit-learn=1.1.1版本,调用岭回归的时候就会报错,后来通过升级scikit-learn=1.3.0后解决此问题。
pip install -U scikit-learn==1.3.1 -i https://pypi.tuna.tsinghua.edu.cn/simple

然后就可以成功了

4.5、模型评估
# 用模型计算测试值,得到预测值
y_pred = rr.predict(x_test)
# # 特征工程后做:
# # 预测测试集的房子价格,通过inverse得到真正的房子价格
# y_pred = std_y.inverse_transform(y_pred)
print('预测前20个结果为:', '\n', y_pred[:20])
print("模型中的系数为:\n", rr.coef_)
#
from sklearn.metrics import explained_variance_score, mean_absolute_error,mean_squared_error,median_absolute_error,r2_score
print('Boston数据线性回归模型的平均绝对误差为:', mean_absolute_error(y_test, y_pred))
print('Boston数据线性回归模型的均方误差为:', mean_squared_error(y_test, y_pred))
print('Boston数据线性回归模型的中值绝对误差为:',median_absolute_error(y_test, y_pred))
print('Boston数据线性回归模型的可解释方差值为:',explained_variance_score(y_test, y_pred))
print('Boston数据线性回归模型的R方值为:', r2_score(y_test, y_pred))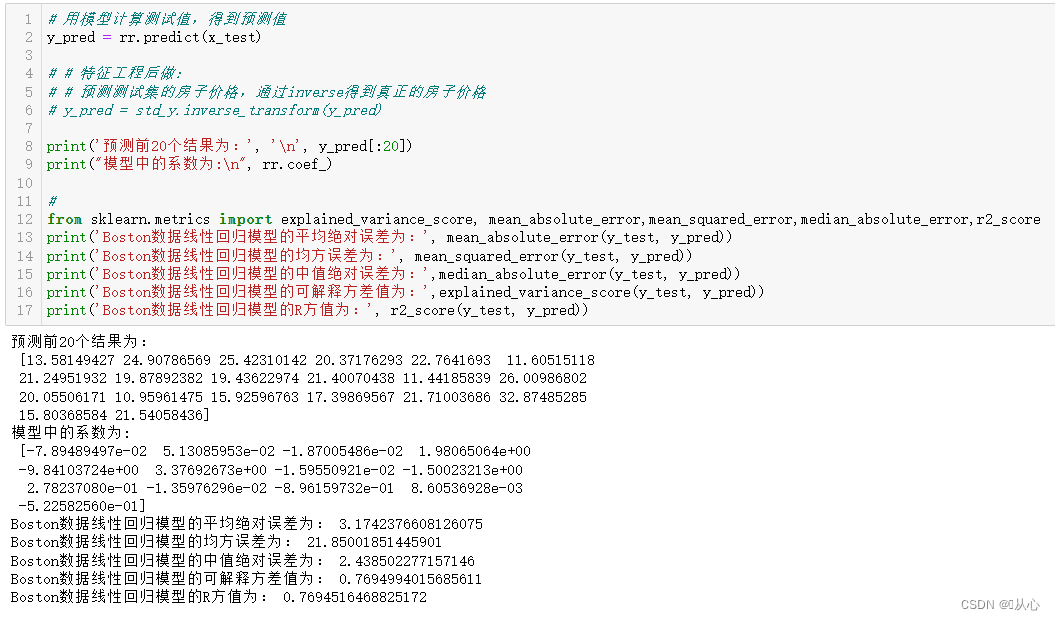
4.6、结果预测
x_real=[[0.00632,18.00,2.310,0,0.5380,6.5750,65.20,4.0900,1,296.0,15.30,396.90,4.98]]
y_real_pred = rr.predict(x_real)
print(y_real_pred)
旧梦可以重温,且看:机器学习(五) -- 监督学习(5) -- 线性回归1
欲知后事如何,且看: