编译原理作业2
The Exercises of The Chapter Four
4.8 Consider the following grammar:
lexp→atom|list
atom →number|identifier
list→(lexp-seq)
lexp-seq→lexp-seq lexp|lexp
a. remove the left recursive.
b. Construct First and Follow sets for the nonterminals of the resulting grammar.
c. Show that the resulting grammar is LL(1).
d. Construct the LL(1) parsing table for the resulting grammar.
e. Show the actions of the corresponding LL(1) parser, given the input string (a (b (2)) ©).
a.remove the left recursive
lexp→atom|list
atom →number|identifier
list→(lexp-seq)
lexp-seq→lexp lexp-seq’
lexp-seq’→lexp lexp-seq’ | ε
b. Construct First and Follow sets for the nonterminals of the resulting grammar.
- First集合:
First(atom):number,identifier
Fisrt(list): (
First(lexp): First(lexp)∪First(atom)∪First(list)=number,identifier,(
First(lexp-sep):Fisrt(lexp-sep)∪First(lexp)=number,identifier,(
First(lexp-seq’):First(lexp-seq’)∪First(lexp)∪ ϵ {\epsilon} ϵ=number,identifier,(, ϵ \epsilon ϵ
- Follow集合:
第一轮:
Follow(lexp): $
Follow(atom): $
Follow(list): $
Follow(lexp-seq): )
Follow(lexp): Follow(lexp)∪( Fisrt(lexp-seq’)- ϵ {\epsilon} ϵ ) ∪ Follow(lexp-sep) =number,identifier,(,)
Follow(lexp-seq’):Follow(lexp-seq’)∪Follow(lexp-seq)=)
Follow(lexp):Follow(lexp)∪( First(lexp-seq’) - ϵ \epsilon ϵ ) ∪ ( Follow(lexp-seq’))=number,identifier,(,)
Follow(lexp-seq’):Follow(lexp-seq’)∪Follow(lexp-seq’)=)
第二轮:
Follow(lexp): $,number,identifier,(,)
Follow(atom): $,number,identifier,(,)
Follow(list): $,number,identifier,(,)
Follow(lexp-seq): )
Follow(lexp-seq’): )
c.Show that the resulting grammar is LL(1).
- 考虑 l e x p − > a t o m ∣ l i s t lexp->atom|list lexp−>atom∣list: F i r s t ( a t o m ) ∩ F i r s t ( l i s t ) = ϕ First(atom)∩First(list)=\phi First(atom)∩First(list)=ϕ;剩下的First集合中没有 ϵ \epsilon ϵ
- 考虑 a t o m − > n u m b e r ∣ i d e n t i f i e r atom->number|identifier atom−>number∣identifier:由于两个都是终结符,成立。
- 考虑 l i s t − > ( l e x p − s e q ) list->(lexp-seq) list−>(lexp−seq):考虑 F i r s t ( l i s t ) First(list) First(list)中没有 ϵ \epsilon ϵ,成立。
- 考虑 l e x p − s e q − > l e x p l e x p − s e q ′ lexp-seq->lexp lexp-seq' lexp−seq−>lexp lexp−seq′,只有一个选择。且first(lexp)中不包含 ϵ \epsilon ϵ,成立。
- 考虑 l e x p − s e q ′ − > l e x p l e x p − s e q ′ ∣ ϵ lexp-seq'->lexp lexp-seq' | \epsilon lexp−seq′−>lexp lexp−seq′∣ϵ : F i r s t ( l e x p l e x p − s e q ′ ) ∩ F i r s t ( ϵ ) = ϕ First(lexp lexp-seq') ∩ First(\epsilon)=\phi First(lexp lexp−seq′)∩First(ϵ)=ϕ;由于 F i r s t ( l e x p − s e q ′ ) First(lexp-seq') First(lexp−seq′)包含 ϵ \epsilon ϵ ,由于 F i r s t ( l e x p − s e q ′ ) ∩ F o l l o w ( l e x p − s e q ′ ) = ϕ First(lexp-seq')∩Follow(lexp-seq')=\phi First(lexp−seq′)∩Follow(lexp−seq′)=ϕ,成立。
综上判定为LL(1)文法
d.Construct the LL(1) parsing table for the resulting grammar.
| number | identifier | ( | ) | ϵ \epsilon ϵ | |
|---|---|---|---|---|---|
| lexp | lexp->atom | lexp->atom | lexp->list | ||
| atom | atom->number | atom->identifier | |||
| list | list->(lexp-seq) | ||||
| lexp-seq | lexp-seq->lexp lexp-seq’ | lexp-seq->lexp lexp-seq’ | lexp-seq->lexp lexp-seq’ | ||
| lexp-seq’ | lexp-seq’->lexp lexp-seq’ | lexp-seq’->lexp lexp-seq’ | lexp-seq’->lexp lexp-seq’ | lexp-seq’-> ϵ \epsilon ϵ | lexp-seq’-> ϵ \epsilon ϵ |
e. Show the actions of the corresponding LL(1) parser, given the input string (a (b (2)) ©).
| 分析栈 | 输入 | 说明 |
|---|---|---|
| lexp# | (a (b (2)) ©)# | |
| list# | (a (b (2)) ©)# | lexp->list |
| ( lexp-seq )# | (a (b(2)) ©)# | list->(lexp-seq) |
| lexp-seq ) # | a (b(2)) © ) # | 匹配( |
| lexp lexp-seq’ )# | a (b(2)) © ) # | lexp-seq’ -> lexp lexp-seq’ |
| atom lexp-seq’) # | a (b(2)) © ) # | lexp->atom |
| identity lexp-seq’) # | a (b(2)) © ) # | 匹配 |
| lexp-seq’ )# | (b(2)) © ) # | atom->identifier |
| lexp lexp-seq’ )# | (b(2)) © ) # | lexp-seq’->lexp lexp-seq’ |
| list lexp-seq’ )# | (b(2)) © ) # | lexp-seq’->lexp lexp-seq’ |
| (lexp-seq) lexp-seq’ )# | (b(2)) © ) # | list->(lexp-seq) |
| lexp-seq) lexp-seq’ )# | b(2)) © ) # | 匹配 |
| lexp lexp-seq’ ) lexp-seq’ )# | b(2)) © ) # | lexp-seq->lexp lexp-seq’ |
| atom lexp-seq’) lexp-seq’ )# | b(2)) © ) # | lexp->atom |
| identifier lexp-seq’ ) lexp-seq’)# | b(2)) © ) # | lexp->atom |
| lexp-seq’ ) lexp-seq’ )# | (2)) © ) # | 匹配 |
| lexp lexp-seq’ ) lexp-seq’ )# | (2)) © ) # | lexp-seq’->lexp lexp-seq’ |
| list lexp-seq’ ) lexp-seq’ )# | (2)) © ) # | lexp->list |
| (lexp-seq) lexp-seq’ ) lexp-seq’ )# | (2)) © ) # | lisst->(lexp-seq) |
| lexp-seq) lexp-seq’ ) lexp-seq’ )# | 2)) © ) # | 匹配 |
| lexp lexp-seq’ ) lexp-seq’ ) lexp-seq’) # | 2)) © ) # | lexp-seq->lexp lexp-seq’ |
| atom lexp-seq’ ) lexp-seq’ ) lexp-seq’ )# | 2)) © ) # | lexp->atom |
| lexp-seq’ ) lexp-seq’ ) lexp-seq’ )# | )) © ) # | 匹配 |
| ) lexp-seq’ ) lexp-seq’ )# | )) © ) # | lexp-seq’-> ϵ \epsilon ϵ |
| lexp-seq’ ) lexp-seq’ )# | ) © ) # | 匹配 |
| ) lexp-seq’ )# | ) © ) # | lexp-seq’-> ϵ \epsilon ϵ |
| lexp-seq’ )# | © ) # | 匹配 |
| lexp lexp-seq’ )# | © ) # | lexp-seq’->lexp lexp-seq’ |
| list lexp-seq’ )# | © ) # | lexp->list |
| (lexp-seq) lexp-seq’ )# | © ) # | list->(lexp-seq) |
| lexp-seq) lexp-seq’ )# | c) ) # | 匹配 |
| lexp lexp-seq’)lexp-seq’)# | c) ) # | lexp-seq->lexp lexp-seq’ |
| atom lexp-seq’)lexp-seq’)# | c) ) # | lexp->atom |
| lexp-seq’)lexp-seq’)# | ) ) # | 匹配 |
| )lexp-seq’)# | ) ) # | lexp-seq’-> ϵ \epsilon ϵ |
| lexp-seq’)# | ) # | 匹配 |
| )# | ) # | lexp-seq’-> ϵ \epsilon ϵ |
| # | # | 匹配acc |
4.9 Consider the following grammar:
lexp→atom|list
atom →number|identifier
list→(lexp-seq)
lexp-seq→lexp,lexp-seq|lexp
a. Left factor this grammar.
b. Construct First and Follow sets for the nonterminals of the resulting grammar.
c. Show that the resulting grammar is LL(1).
d. Construct the LL(1) parsing table for the resulting grammar.
e. Show the actions of the corresponding LL(1) parser, given the input string (a,(b,(2)),©).
a. Left factor this grammar.
lexp→atom|list
atom→number|identifier
list→(lexp-seq)
lexp-seq→lexp lexp-seq’
lexp-seq’→ , lexp-seq | ε
b. Construct First and Follow sets for the nonterminals of the resulting grammar.
- First集合
First(atom):number identifier
First(list): (
First(lexp):number identifier (
First(lexp-seq):number identifier (
First(lexp-seq’): ε ,
- Follow集合
第一次Follow集合:
Follow(lexp): $ , )
Follow(atom): $
Follow(list): $
Follow(lexp-seq): )
Follow(lexp-seq’): )
第二次求Follow集合:
Follow(lexp): $ , )
Follow(atom): $ , )
Follow(list): $ , )
Follow(lexp-seq): )
Follow(lexp-seq’): )
c. Show that the resulting grammar is LL(1).
考虑 l e x p → a t o m ∣ l i s t lexp→atom|list lexp→atom∣list: F i r s t ( a t o m ) ∩ F i r s t ( l i s t ) = ϕ First(atom)∩First(list)=\phi First(atom)∩First(list)=ϕ;而且 F i r s t ( l e x p ) 没 有 ϵ First(lexp)没有\epsilon First(lexp)没有ϵ。
考虑 a t o m → n u m b e r ∣ i d e n t i f i e r atom →number|identifier atom→number∣identifier:都是终结符,满足; F i r s t ( a t o m ) 中 没 有 ϵ First(atom)中没有\epsilon First(atom)中没有ϵ。
考虑 l i s t → ( l e x p − s e q ) list→(lexp-seq) list→(lexp−seq):由于 l i s t 没 有 ϵ list没有\epsilon list没有ϵ因此该文法成立
考虑 l e x p − s e q → l e x p l e x p − s e q ′ lexp-seq→lexp lexp-seq' lexp−seq→lexp lexp−seq′:由 F i s r t ( l e x p − s e q ) 没 有 ϵ Fisrt(lexp-seq)没有\epsilon Fisrt(lexp−seq)没有ϵ,因此该文法成立
考虑 l e x p − s e q ′ → , l e x p − s e q ∣ ε lexp-seq'→, lexp-seq | ε lexp−seq′→,lexp−seq∣ε : F i r s t ( , ) ∩ F i r s t ( ϵ ) = ϕ First(,)∩First(\epsilon)=\phi First(,)∩First(ϵ)=ϕ,同时 F i r s t ( l e x p − s e q ′ ) 存 在 ϵ First(lexp-seq')存在\epsilon First(lexp−seq′)存在ϵ,且 F i r s t ( l e x p − s e q ′ ) ∩ F o l l o w ( l e x p − s e q ′ = ϕ First(lexp-seq')∩Follow(lexp-seq'=\phi First(lexp−seq′)∩Follow(lexp−seq′=ϕ
因此该文法满足LL(1)文法
d. Construct the LL(1) parsing table for the resulting grammar.
| number | identifier | ( | ) | ϵ \epsilon ϵ | , | |
|---|---|---|---|---|---|---|
| lexp | lexp->atom | lexp->atom | lexp->list | |||
| atom | atom->number | atom->identifier | ||||
| list | list->(lexp-seq) | |||||
| lexp-seq | lexp-seq->lexp lexp-seq’ | lexp-seq->lexp lexp-seq’ | lexp-seq->lexp lexp-seq’ | |||
| lexp-seq’ | lexp-seq’-> ϵ \epsilon ϵ | lexp-seq’-> ϵ \epsilon ϵ | lexp-seq’->, lexp-seq |
e. Show the actions of the corresponding LL(1) parser, given the input string (a,(b,(2)),©).
| 分析栈 | 输入 | 说明 |
|---|---|---|
| lexp# | (a,(b,(2)),©)# | # |
| list# | (a,(b,(2)),©)# | lexp->list |
| (lexp-seq)# | (a,(b,(2)),©)# | list->(lexp-seq) |
| lexp-seq ) # | a,(b,(2)),©)# | 匹配( |
| lexp lexp-seq’ )# | a,(b,(2)),©)# | lexp-seq’ -> lexp lexp-seq’ |
| atom lexp-seq’) # | a,(b,(2)),©)# | lexp->atom |
| identity lexp-seq’) # | a,(b,(2)),©)# | 匹配 |
| lexp-seq’ )# | ,(b,(2)),©)# | atom->identifier |
| , lexp-seq )# | ,(b,(2)),©)# | lexp-seq’->, lexp-seq |
| lexp-seq )# | (b,(2)),©)# | 匹配, |
| lexp lexp-seq’ )# | (b,(2)),©)# | lexp-seq->lexp lexp-seq’ |
| list lexp-seq’ ) # | (b,(2)),©)# | lexp->list |
| (lexp-seq) lexp-seq’ ) # | (b,(2)),©)# | list->(lexp-seq) |
| lexp-seq) lexp-seq’ ) # | b,(2)),©)# | 匹配( |
| lexp lexp-seq’ ) lexp-seq’ )# | b,(2)),©)# | lexp-seq->lexp lexp-seq’ |
| atom lexp-seq’ ) lexp-seq’ )# | b,(2)),©)# | lexp->atom |
| identiftier lexp-seq’ ) lexp-seq’ )# | b,(2)),©)# | atom->identifier |
| lexp-seq’ ) lexp-seq’ )# | ,(2)),©)# | 匹配idenitier |
| , lexp-seq ) lexp-seq’ )# | ,(2)),©)# | lexp-seq’->, lexp-seq |
| lexp-seq ) lexp-seq’ )# | (2)),©)# | 匹配, |
| lexp lexp-seq’ ) lexp-seq’ )# | (2)),©)# | lexp-seq->lexp lexp-seq’ |
| list lexp-seq’ ) lexp-seq’ )# | (2)),©)# | lexp->list |
| (lexp-seq) lexp-seq’ ) lexp-seq’ )# | (2)),©)# | list->(lexp-seq) |
| lexp-seq) lexp-seq’ ) lexp-seq’ )# | 2)),©)# | 匹配( |
| atom ) lexp-seq’ ) lexp-seq’ )# | 2)),©)# | lexp->atom |
| number) lexp-seq’ ) lexp-seq’ )# | 2)),©)# | 匹配number |
| ) lexp-seq’ ) lexp-seq’ )# | )),©)# | lexp-seq’-> ϵ \epsilon ϵ |
| lexp-seq’ ) lexp-seq’ )# | ),©)# | 匹配) |
| ) lexp-seq’ )# | ),©)# | lexp-seq’-> ϵ \epsilon ϵ |
| lexp-seq’ )# | ,©)# | 匹配) |
| , lexp-seq lexp-seq’ ) # | ,©)# | lexp-seq’->, lexp-seq |
| lexp-seq lexp-seq’ ) # | ©)# | 匹配, |
| lexp lexp-seq’ lexp-seq’ ) # | ©)# | lexp-seq->lexp lexp-seq’ |
| list lexp-seq’ lexp-seq’ ) # | ©)# | lexp->list |
| (lexp-seq)lexp-seq’ lexp-seq’ ) # | ©)# | list->(lexp-seq) |
| lexp-seq)lexp-seq’ lexp-seq’ ) # | c))# | 匹配( |
| lexp lexp-seq’ ) lexp-seq’ lexp-seq’ ) # | c))# | lexp-seq->lexp lexp-seq’ |
| atom lexp-seq’ ) lexp-seq’ lexp-seq’ ) # | c))# | lexp->atom |
| identifier lexp-seq’ ) lexp-seq’ lexp-seq’ ) # | c))# | atom->identifier |
| lexp-seq’ ) lexp-seq’ lexp-seq’ ) # | ))# | 匹配identifier |
| ) lexp-seq’ lexp-seq’ ) # | ))# | 匹配) |
| lexp-seq’ lexp-seq’ ) # | )# | lexp-seq’ -> ϵ \epsilon ϵ |
| lexp-seq’ ) # | )# | lexp-seq’ -> ϵ \epsilon ϵ |
| )# | )# | 匹配) |
| # | # | acc |
4.12
a. Can an LL(1) grammar be ambigous? Why or Why not?
不行。LL(1)文法需要构造分析预测表来找,而分析预测表是不能有二义性的。
b. Can an ambigous grammar be LL(1)? Why or Why not?
不行。二义性文法不能构造唯一的语法树,但是二义性是可以通过改写文法消除二义性的。
c. Must an unambigous grammar be LL(1)? Why or Why not?
一个没有二义性的文法也不一定能够是LL(1)文法。可能需要K>1来处理。
The Exercises of The Chapter Five
5.1 Consider the following grammar:
E→(L) | a
L→L,E|E
a. Construct the DFA of LR(0) items for this grammar.
b. Construct the general SLR(1) parsing table.
c. Show the parsing stack and the ations of an SLR(1) parse for the input string ((a),a,(a,a))
d. Is this grammer an LR(0) grammar? If not , describe the LR(0) conflict, if so, construct the LR(0) parsing table, and descrie how a parse might differ from an SLR(1) parse.
a. Construct the DFA of LR(0) items for this grammar.

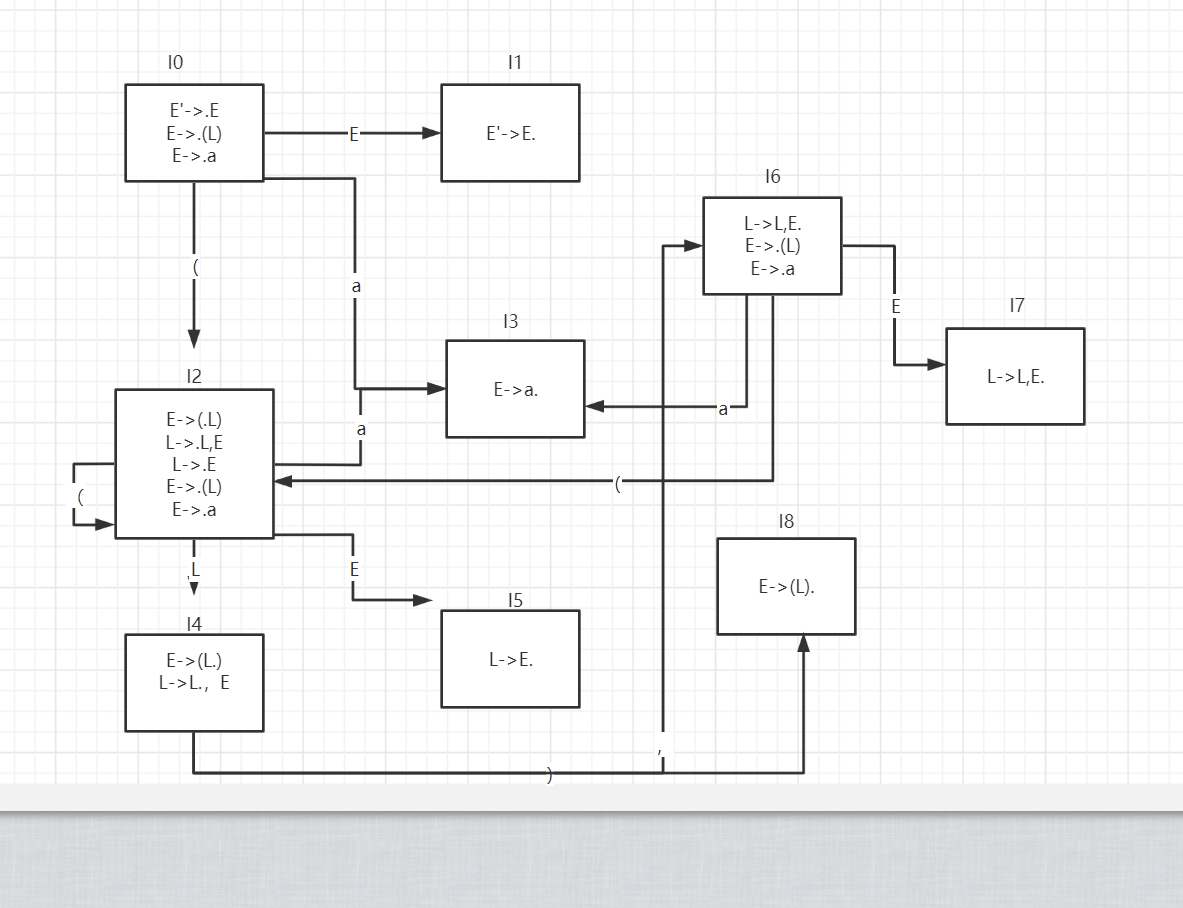
b. Construct the general SLR(1) parsing table.
题目没让消原来文法的左递归,就不要消。直接在含有递归的文法上求follow本身没有 ϵ \epsilon ϵ是可以不通过first直接求follow的
Follow(E)= ), \
Follow(L)=) ,
| State | Input | Goto | |||||
|---|---|---|---|---|---|---|---|
| ( | ) | a | , | $ | E | L | |
| 0 | s2 | s3 | 1 | ||||
| 1 | acc | ||||||
| 2 | s2 | s3 | 5 | 4 | |||
| 3 | r(E->a) | r(E->a) | r(E->a) | ||||
| 4 | s8 | s6 | |||||
| 5 | r(L->E) | r(L->E) | |||||
| 6 | s2 | s3 | 7 | ||||
| 7 | r(L->L,E) | r(L->L,E) | |||||
| 8 | r(E->(L)) | r(E->(L)) | r(E->(L)) |
c. Show the parsing stack and the ations of an SLR(1) parse for the input string ((a),a,(a,a))
| 符号栈 | 匹配栈 | 输入 | 说明 |
|---|---|---|---|
| 0 | # | ((a),a,(a,a))# | action(0,( )=s2 |
| 02 | #( | (a),a,(a,a))# | action(2,( )=s2 |
| 022 | #(( | a),a,(a,a))# | action(2,a)=s3 |
| 0223 | #((a | ),a,(a,a))# | action(3,) )=r(E->a) |
| 022 | #((E | ),a,(a,a))# | GOTO(2,E)=5 |
| 0225 | #((E | ),a,(a,a))# | action(5, , )=r(L->E) |
| 022 | #((L | ),a,(a,a))# | GOTO(2,L)=4 |
| 0224 | #((L | ),a,(a,a))# | action(4,) )=s4 |
| 02248 | #((L) | ,a,(a,a))# | action(4,) ) =s8 |
| 02 | #(E | ,a,(a,a))# | action(8, ,)=r(E->(L)) |
| 025 | #(E | ,a,(a,a))# | GOTO(2,E)=5 |
| 02 | #(L | ,a,(a,a))# | action(5, ,)=r(L->E) |
| 024 | #(L | ,a,(a,a))# | GOTO(2,L)=4 |
| 0246 | #(L, | a,(a,a))# | s6 |
| 02463 | #(L,a | ,(a,a))# | s3 |
| 0246 | #(L,E | ,(a,a))# | r(E->a) |
| 02467 | #(L,E | ,(a,a))# | GOTO(6,E)=7 |
| 02 | #(L | ,(a,a))# | r(L->L,E) |
| 024 | #(L | ,(a,a))# | GOTO(2,L)=4 |
| 0246 | #(L, | (a,a))# | s6 |
| 02462 | #(L,( | a,a))# | s2 |
| 024623 | #(L,(a | ,a))# | s3 |
| 02462 | #(L,(E | ,a))# | r(E->a) |
| 024625 | #(L,(E | ,a))# | GOTO(2,E)=5 |
| 02462 | #(L,(L | ,a))# | r(L->E) |
| 024624 | #(L,(L | ,a))# | GOTO(2,L)=4 |
| 0246246 | #(L,(L, | a))# | s6 |
| 02462463 | #(L,(L,a | ))# | s3 |
| 0246246 | #(L,(L,E | ))# | r(E->a) |
| 02462467 | #(L,(L,E | ))# | GOTO(7,E)=7 |
| 02462 | #(L,(L | ))# | r(L->L,E) |
| 024624 | #(L,(L | ))# | s8 |
| 0246248 | #(L,(L) | )# | r(E->(L)) |
| 0246 | #(L,E | )# | GOTO(6,E)=7 |
| 02467 | #(L,E | )# | r(L->L,E) |
| 02 | #(L | )# | GOTO(2,L)=4 |
| 024 | #(L | )# | s8 |
| 0248 | #(L) | # | r(E->(L)) |
| 0 | #E | # | GOTO(0,E)=1 |
| 01 | #E | # | acc |
d. Is this grammer an LR(0) grammar? If not , describe the LR(0) conflict, if so, construct the LR(0) parsing table, and descrie how a parse might differ from an SLR(1) parse.
观察LR(0)的DFA可得没有移进归约冲突。该文法是LR(0)文法。
| State | Input | Goto | |||||
|---|---|---|---|---|---|---|---|
| ( | ) | a | , | $ | E | L | |
| 0 | s2 | s3 | 1 | ||||
| 1 | acc | ||||||
| 2 | s2 | s3 | 5 | 4 | |||
| 3 | r(E->a) | r(E->a) | r(E->a) | r(E->a) | r(E->a) | ||
| 4 | s8 | s6 | |||||
| 5 | r(L->E) | r(L->E) | r(L->E) | r(L->E) | r(L->E) | ||
| 6 | s2 | s3 | 7 | ||||
| 7 | r(L->L,E) | r(L->L,E) | r(L->L,E) | r(L->L,E) | r(L->L,E) | ||
| 8 | r(E->(L)) | r(E->(L)) | r(E->(L)) | r(E->(L)) | r(E->(L)) |
LR(0)和SLR(1)分析预测表区别就是前者对应一行全部写归约。
5.2 Consider the following grammar:
E→(L) | a
L→L,E|E
a. Construct the DFA of LR(1) items for this grammar.
b. Construct the general LR(1) parsing table.
c. Construct the DFA of LALR(1) items for this grammar.
d. Construct the LALR(1) parsing table.
e. Describe any difference that might occur between the actions of a general LR(1) parser and an LALR(1) parser.
a. Construct the DFA of LR(1) items for this grammar.
- 扩展文法
E ′ − > E E'->E E′−>E
E − > ( L ) ∣ a E->(L)|a E−>(L)∣a
L − > L , E ∣ E L->L,E|E L−>L,E∣E
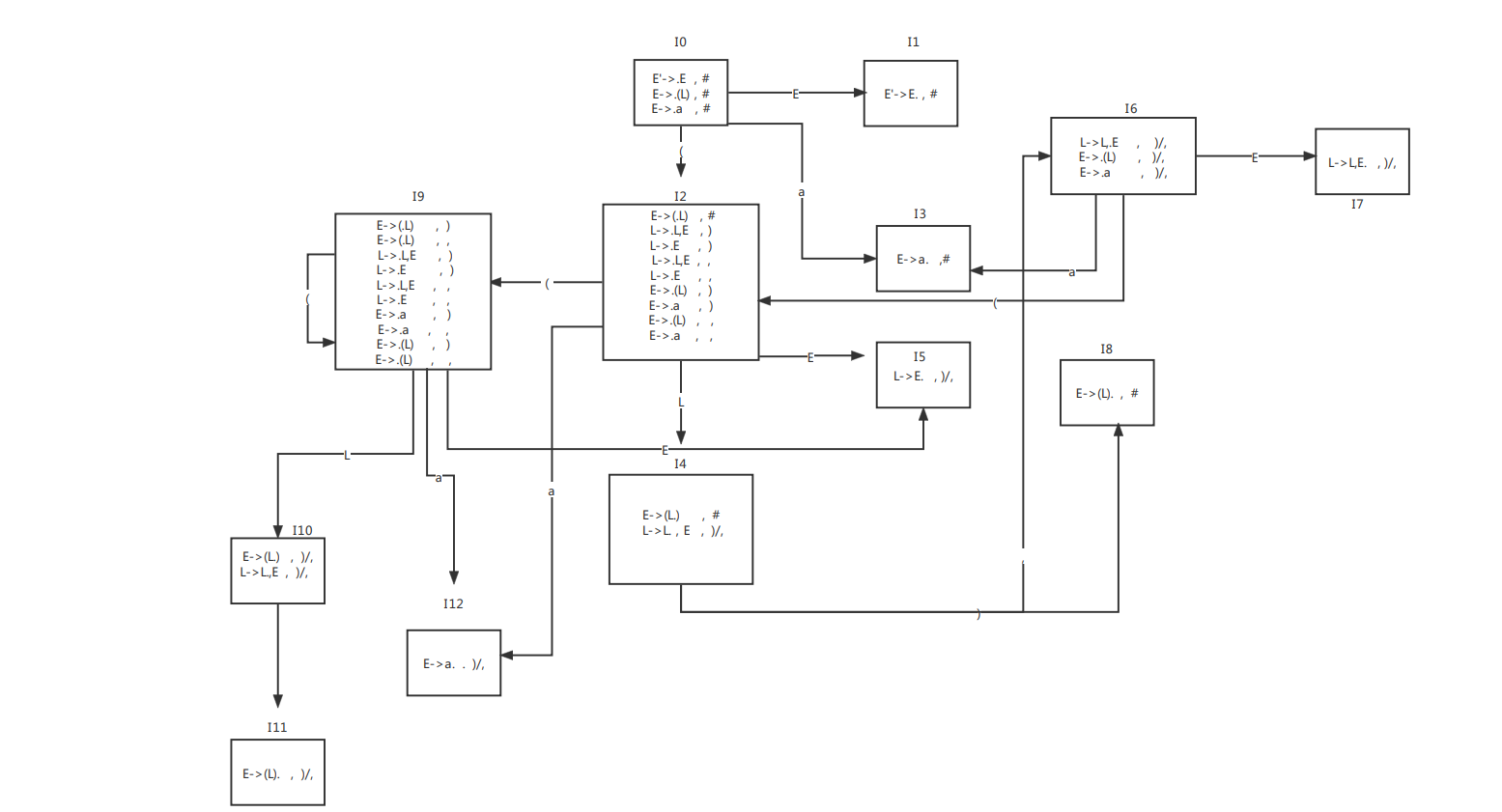
b. Construct the general LR(1) parsing table.
| State | Input | GOTO | |||||
|---|---|---|---|---|---|---|---|
| ( | a | ) | , | $ | E | L | |
| 0 | s2 | s3 | 1 | ||||
| 1 | acc | ||||||
| 2 | 5 | 4 | |||||
| 3 | r(E->a) | ||||||
| 4 | s8 | s6 | |||||
| 5 | r(L->E) | r(L->E) | |||||
| 6 | s12 | s9 | 7 | ||||
| 7 | r(L->L,E) | r(L->L,E) | |||||
| 8 | r(E->(L)) | ||||||
| 9 | s9 | 5 | 10 | ||||
| 10 | s11 | s6 | |||||
| 11 | r(E->(L)) | r(E->(L)) | |||||
| 12 | r(E->a) | r(E->a) | |||||
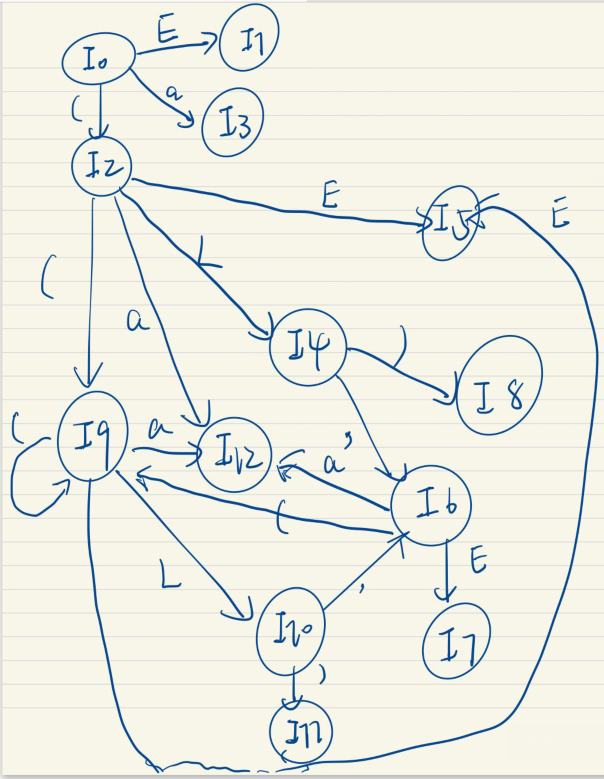
c. Construct the DFA of LALR(1) items for this grammar.
LALR(1)的关键是合并LR(1)的同心项目。
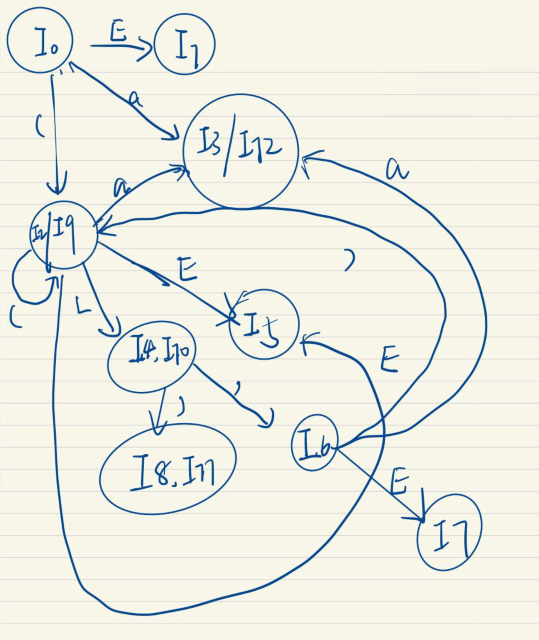
d. Construct the LALR(1) parsing table.
| State | input | GOTO | |||||
|---|---|---|---|---|---|---|---|
| ( | a | ) | , | $ | L | E | |
| 0 | s2/s9 | s3/s12 | 1 | ||||
| 1 | acc | ||||||
| 2/9 | s2/s9 | 4/10 | 5 | ||||
| 3/12 | r(E->a) | r(E->a) | r(E->a) | ||||
| 4/10 | s8/s11 | s6 | |||||
| 5 | r(L->E) | r(L->E) | |||||
| 6 | s2/s9 | s3/s12 | 7 | ||||
| 7 | r(L->L,E) | r(L->L,E) | |||||
| 8/11 | E->(L) | E->(L) | E->(L) |
e. Describe any difference that might occur between the actions of a general LR(1) parser and an LALR(1) parser.
LALR(1)的转化式子和LR(1)的转化式子相比,在LALR(1)显示出error的时候已经进行了一些错误的转化。
5.12 Show that the following grammar is LR(1) but not LALR(1):
S→aAd|bBd|aBe|bAe
A→c
B→c


LALR(1)光是归约就存在冲突了
