学习内容:
- instructGPT
- VLTinT: Visual-Linguistic Transformer-in-Transformer for Coherent Video Paragraph Captioning
学习时间:
- 1.9 ~ 1.14
遇到的问题:
强化学习策略的使用:只看懂了HMN代码,没有完全看懂VPM中强化学习代码的具体使用方法,还没有设计好强化学习奖励函数。
学习笔记:
instructGPT
openai关于ChatGPT的论文暂时还没有出来,不过ChatGPT用到的技术和InstructGPT一样,区别是InstructGPT是在GPT3上微调,ChatGPT是在GPT3.5上微调。
1.introduction
语言模型是每次给定一段东西,然后去预测下一个词,是自监督学习,没有人工标注。如果想让语言模型去解释费马定理,那么训练文本中需要出现过相关的内容。而训练的文本一般是几百亿数量级,并不知道里面会有什么东西,只能全送进去期待大力出奇迹。
但是这样做会有两个问题:
- 有效性,想让模型去学做一件事,但是模型无法学会,这是因为文本中可能就没有相关的内容。
- 安全性,模型输出一些不应该输出(非法的、有害的等等)的内容。
解决这两个问题的办法,就是标一点数据,再把语言模型进行微调,效果会更好一些,能够更加服从人类的指示(instruction)。
这篇论文展示了怎么样对语言模型与人类意图进行匹配,核心思想是在人为的反馈上进行微调。
方法简介:收集很多问题,使用标注工具将问题的答案写出来,用这些数据集对GPT3进行微调。接下来再收集一个数据集,通过刚才微调的模型输入问题得到一些输出答案,人工对这些答案按好坏进行排序,然后通过强化学习继续训练微调后的模型,这个模型就叫InstructGPT
2.training strategy
重点:两个标注数据集,三个模型。
1、找人来写出各种各样的问题(或者从以前GPT3接口收集的问题),这些问题在GPT里面叫做prompt
例如:什么是月亮?
2、让人根据问题写答案
例如:围绕地球旋转的球形天体。
3、将问题和答案拼在一起,形成一段对话。大量这样的对话文本,形成第一个标注数据集。
例如:什么是月亮?围绕地球旋转的球形天体。
4、使用这些对话微调GPT3。GPT3的模型在人类标注的这些数据上进行微调出来的模型叫做SFT(supervised fine-tune),有监督的微调。这就是训练出来的第一个模型。
5、给出一个问题,通过SFT模型生成几个答案,这里假设生成四个答案。
例如:什么是月亮?
SFT模型生成了四个答案:
A、月亮是太阳系中离地球最近的天体。
B、月亮是太阳系中体积第五大的卫星。
C、月亮是由冰岩组成的天体,在地球的椭圆轨道上运行。
D、月亮是地球的卫星。
6、将四个答案让人根据好坏程度进行排序。
例如:张三觉得答案D是最好的,其次是C,C比A要好,A和B差不多。就是D>C>B=A。
7、将大量的人工排序整理为一个数据集,就是第二个标注数据集。
8、使用排序数据集训练一个 RM模型(reward model) 奖励模型。这是第二个模型。
模型输入:问题+答案
例如:什么是月亮?月亮是地球的卫星。
模型输出:分数,例如:9.4。
优化目标:问题+答案得到的分数要满足人工排序的顺序。
例如:
什么是月亮?月亮是太阳系中离地球最近的天体。 5.4
什么是月亮?月亮是太阳系中体积第五大的卫星。 5.4
什么是月亮?月亮是由冰岩组成的天体,在地球的椭圆轨道上运行。 8.2
什么是月亮?月亮是地球的卫星。 9.4
这里得到的分数就满足张三的排序:D>C>B=A。
9、继续给出一些没有答案的问题,通过强化学习继续训练SFT模型,新的模型叫做RL模型(Reinforcement Learning)。优化目标是使得RF模型根据这些问题得到的答案在RM模型中得到的分数越高越好。这是第三个模型。
10、最终微调后的RL模型就是InstructGPT模型。
备注:两次对模型的微调:GPT3模型—>SFT模型—>RL模型,其实这里始终都是同一个模型,只是不同过程中名称不一样。
需要SFT模型的原因:GPT3模型不一定能够保证根据人的指示、有帮助的、安全的生成答案,需要人工标注数据进行微调。
需要RM模型的原因:标注排序的判别式标注,成本远远低于生成答案的生成式标注。
需要RF模型的原因:在对SFT模型进行微调时,生成的答案分布也会发生变化,会导致RM模型的评分会有偏差,需要用到强化学习。
3.data collection
首先要收集问题集,prompt集:标注人员写出这些问题,写出一些指令,用户提交一些他们想得到答案的问题。先训练一个最基础的模型给用户试用,同时可以继续收集用户提交的问题。划分数据集时按照用户ID划分,因为同一个用户问题会比较类似,不适合同时出现在训练集和验证集中。
三个模型的数据集:
1、SFT数据集:13000条数据。标注人员直接根据刚才的问题集里面的问题写答案。
2、RM数据集:33000条数据。标注人员对答案进行排序。
3、RF数据集:31000条数据。只需要prompt集里面的问题就行,不需要标注。因为这一步的标注是RM模型来打分标注的。
openai专门找了40个标注人员进行标注,需要长期交流的合同工,因为这些标注任务需要一定熟练度、对业务的理解、并需要做到随时沟通。
4.models
4.1 SFT(Supervised fine-tuning)模型
把GPT3这个模型,在标注好的第一个数据集(问题+答案)上面重新训练一次。
由于只有13000个数据,1个epoch就过拟合,不过这个模型过拟合也没什么关系,甚至训练更多的epoch对后续是有帮助的,最终训练了16个epoch。
4.2 RM(Reward modeling)模型
参数解释:
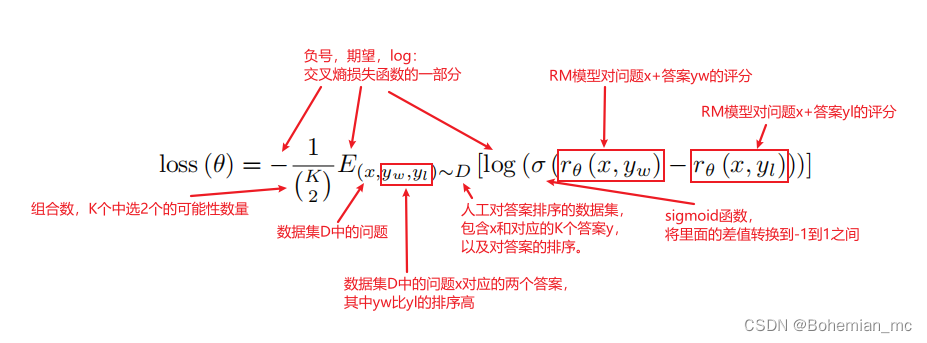
1、D:第二个数据集,人工对答案进行排序。
2、x:第二个数据集D中的问题,每个问题对应K个答案,答案的顺序已经人工标注好了。
3、yw和yl:x对应的K个答案中的两个,其中yw排序比yl高,因为是一对,所以叫pairwise。
4、rθ(x,y):即需要训练的RM模型,对于输入的一对x和y得到的标量分数。
5、θ:需要优化的参数。
把SFT模型最后的unembedding层去掉,即最后一层不用softmax,改成一个线性层,这样RM模型就可以做到输入问题+答案,输出一个标量的分数。
RM模型使用6B,而不是175B的原因:
- 小模型更便宜
- 大模型不稳定,loss很难收敛。如果你这里不稳定,那么后续再训练RL模型就会比较麻烦。
损失函数,输入是排序,需要转换为值,这里使用Pairwise Ranking Loss。
损失函数的理解:
1、x和yw这一对问题和答案,放进RM模型中算出一个分数rθ(x,yw)
2、x和yl这一对问题和答案,放进RM模型中算出一个分数rθ(x,yl)
3、因为人工标注出yw的排序要比yl高,r(x,yw)得到的分数应该比r(x,yl)得到的分数高,所以rθ(x,yw)-rθ(x,yl)这个差值要越大越好
4、把相减后的分数通过sigmoid,那么这个值就在-1到1之间,并且我们希望σ(rθ(x,yw)-rθ(x,yl))越大越好
5、这里相当于将排序问题转换为了分类问题,即σ(rθ(x,yw)-rθ(x,yl))越接近1,表示yw比yl排序高,属于1这个分类,反之属于-1这个分类。所以这里就用logistic
loss,由于是二分类,也相当于是交叉熵损失函数。
6、对于每个问题有K个答案,所以前面除以C(K,2),使得loss不会因为K的变化而变化太多。
7、最后是最小化loss(θ),就是要最大化rθ(x,yw)-rθ(x,yl)这个值,即如果一个答案的排序比另一个答案排序高的话,我们希望他们通过RM模型得到的分数之差能够越大越好。
4.3 RL(Reinforcement learning)模型
参数解释:
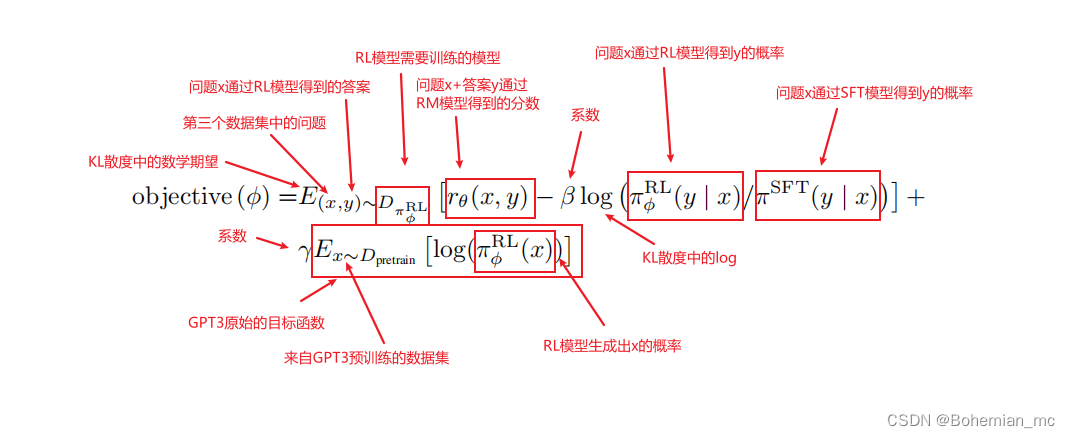
1、πSFT:SFT模型。
2、πφRL:强化学习中,模型叫做Policy,πφRL就是需要调整的模型,即最终的模型。初始化是πSFT。
3、(x,y)∼DπφRL:x是第三个数据集中的问题,y是x通过πφRL模型得到的答案。
4、rθ(x,y):对问题x+答案y进行打分的RM模型。
5、πφRL(y | x):问题x通过πφRL得到答案y的概率,即对于每一个y的预测和它的softmax的输出相乘。
6、πSFT(y | x):问题x通过πSFT得到答案y的概率。
7、x∼Dpretrain:x是来自GPT3预训练模型的数据。
8、β、γ:调整系数。
这里用的是强化学习,因为他的数据分布是随着策略的更新,环境会发生变化的。优化算法是PPO,Proximal Policy Optimization,近端策略优化。简单来说,就是对目标函数objective(φ)通过随机梯度下降进行优化。
目标函数理解:优化目标是使得目标函数越大越好,objective(φ)可分成三个部分,打分部分+KL散度部分+GPT3预训练部分
1、将第三个数据集中的问题x,通过πφRL模型得到答案y
2、把一对(x,y)送进RM模型进行打分,得到rθ(x,y),即第一部分打分部分,这个分数越高就代表模型生成的答案越好
3、在每次更新参数后,πφRL会发生变化,x通过πφRL生成的y也会发生变化,而rθ(x,y)打分模型是根据πSFT模型的数据训练而来,如果πφRL和πSFT差的太多,则会导致rθ(x,y)的分数估算不准确。因此需要通过KL散度来计算πφRL生成的答案分布和πSFT生成的答案分布之间的距离,使得两个模型之间不要差的太远。
4、我们希望两个模型的差距越小越好,即KL散度越小越好,前面需要加一个负号,使得objective(φ)越大越好。这个就是KL散度部分。
5、如果没有第三项,那么模型最终可能只对这一个任务能够做好,在别的任务上会发生性能下降。所以第三部分就把原始的GPT3目标函数加了上去,使得前面两个部分在新的数据集上做拟合,同时保证原始的数据也不要丢,这个就是第三部分GPT3预训练部分。
6、当γ=0时,这个模型叫做PPO,当γ不为0时,这个模型叫做PPO-ptx。InstructGPT更偏向于使用PPO-ptx。
7、最终优化后的πφRL模型就是InstructGPT的模型。
VLTinT: Visual-Linguistic Transformer-in-Transformer for Coherent Video Paragraph Captioning

论文链接:
https://arxiv.org/abs/2211.15103
代码链接:
https://github.com/UARK-AICV/VLTinT
1.introduction
视频段落字幕生成任务要求模型对未处理的一段长视频生成概况性的文字描述,且该视频中所描述的连贯故事严格遵循一定的时间位置。这要求模型具有很强的时空事件提取能力。
作者遵循人类观看视频时的感知过程,通过将视频场景分解为视觉(例如人类、动物)和非视觉成分(例如动作、关系、逻辑)来层次化的理解场景,并且提出了一种称为Visual-Linguistic(VL)的多模态视觉语言特征。在VL特征中,一个完整的视频场景主要由三种模态进行建模,包括:
- 全局视觉环境表征:代表周围整体场景
- 局部视觉主体表征:代表当前进行中的事件
- 语言性场景元素:代表视觉和非视觉元素
作者设计了一种自回归Transformer结构(TinT)来对这三种模态进行表征和建模,可以同时捕获视频中事件内和事件间内容的语义连贯性。为了更加高效的训练模型,作者还配套提出了一种全新的VL多模态对比损失函数,来保证学习到的嵌入特征与字幕语义相匹配,作者在多个段落级字幕生成基准上对模型进行了评估,结果表明本文方法在字幕生成的准确性和多样性方面性能达到SOTA。
2.overview of VLTinT:
作为密集视频字幕生成(Dense Video Captioning,DVC) 的简化版本,视频段落字幕(Video Paragraph Captioning,VPC) 的目的是对给定的视频生成概括性的段落描述,从而简化事件解析和描述的流程。
之前的VPC方法大多使用一个基于CNN的黑盒网络来对视频特征进行编码,这种做法可能会忽略视频中视频和语言模态之间的交互。
本文提出的VLTinT模型将视频场景分解为三种模态,以达到对视频中视觉和非视觉元素的细粒度描述。此外,为了关注对当前事件具有核心影响的主要代理主体,作者对其加入了混合注意机制(Hybrid Attention Mechanism,HAM) 进行学习。下图展示了本文所提VLTinT模型与其他常规方法的对比。
在上图中展示的Trans.XL和MART方法中,每个事件依然是独立解码,没有考虑事件间的一致性。
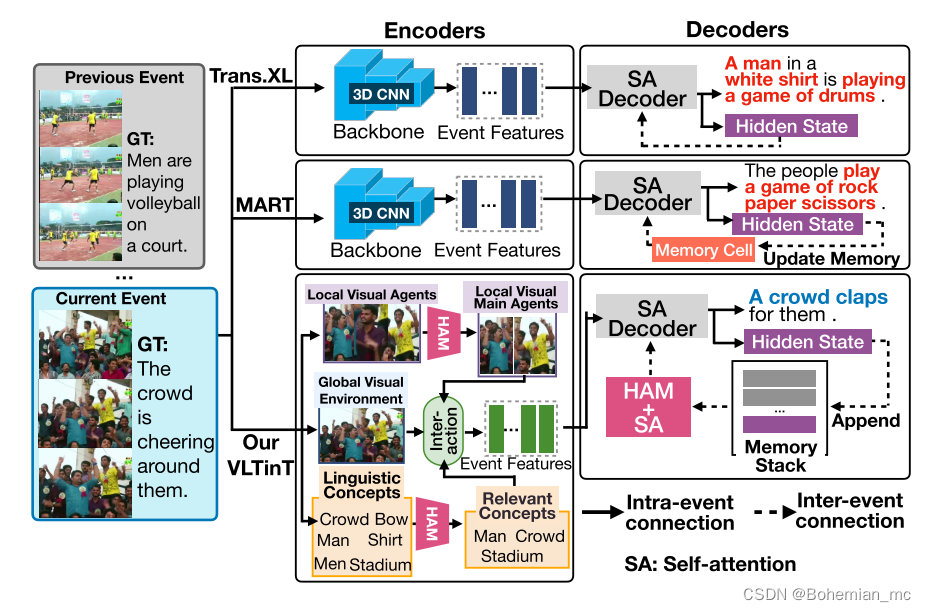
为此,作者提出了Transformer in Transformer架构(TinT),TinT Decoder可以同时兼顾一段视频中事件内和事件间的依赖关系建模。相比之前方法简单的使用最大似然估计损失(MLE)来训练模型,作者引入了一个新的多模态VL对比损失来保持在训练过程中对视觉和语言语义的学习,而不增加额外的计算成本。
3. method
本文的VLTinT由两个主要模块构成,分别对应一个编码器VL Encoder和解码器TinT Decoder。
VL Encoder:主要负责对一段视频中的不同事件提取特征表示
TinT Decoder:主要负责对这些特征进行解码生成每个事件的文字描述,同时对事件内和事件间的一致性进行建模
这两个模块都通过本文提出的VL对比损失以端到端的方式进行训练,VLTinT的整体架构如下图所示:
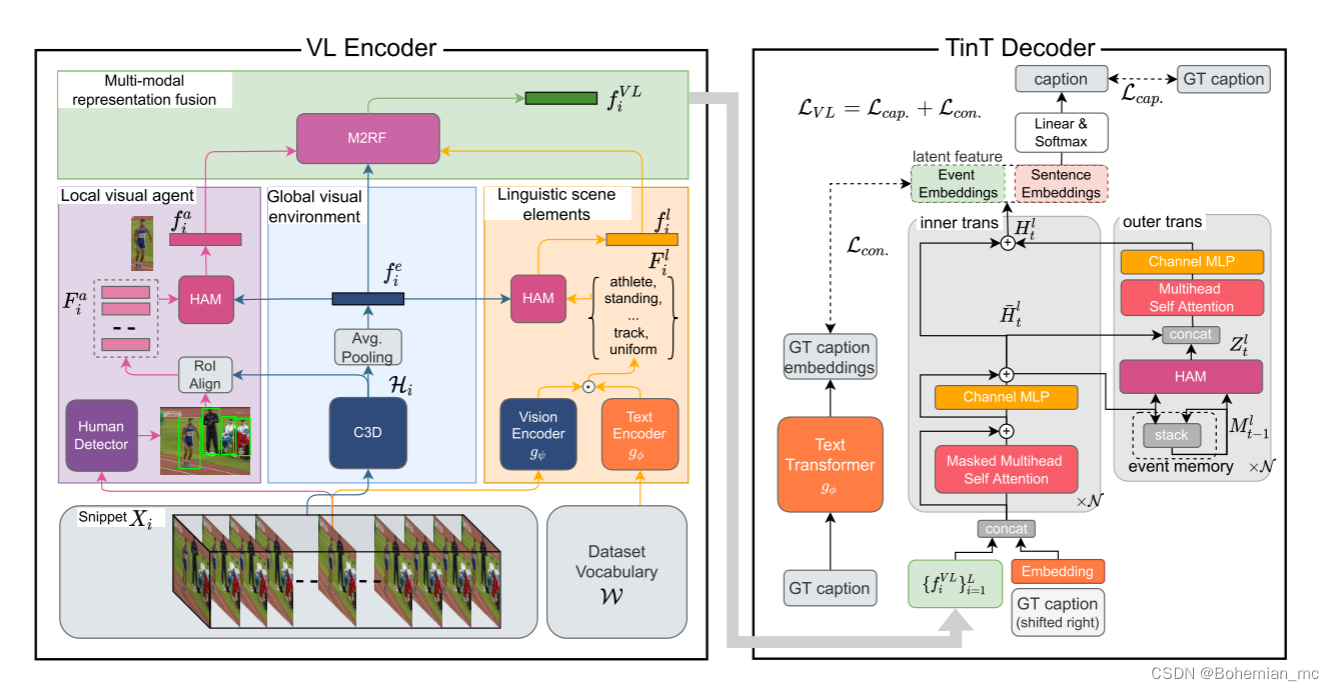
待续
文章算法实现部分还没看明白,下周会继续研究这方面的内容。