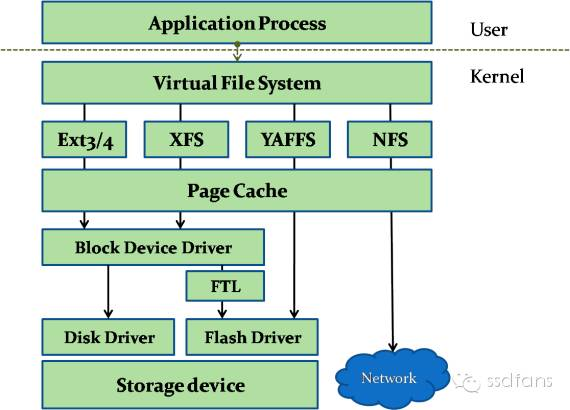
一:VFS
我们知道SSD是一场存储革命,设计和制造一个好的SSD固然重要,但如何正确使用以充分发挥SSD性能同样重要。SSD内在的并行性和先擦再写的特性决定了它不同于机械硬盘简单的LBA和存储块一一对应,要充分挖掘SSD的并行性,提升性能,延长寿命,缩短延迟,就必须在上层应用做出改动。很多SSD的使用大户都作出了这种尝试,从国外的Google,Microsoft,Facebook,到国内的Baidu,Alibaba等,本站就曾经介绍过百度的软件定义闪存,把对象存储和SSD内部结构统一起来使用。但对大部分企业来讲,这种结构还是太独特了,我们还是要关注通用的架构,首先来了解离硬盘最近的软件:文件系统。本系列文章将以Linux系统最常见的EXT4文件系统为例,从SSD爱好者的角度来揭开文件系统的庐山真面目。
VFS架构
要说Linux文件系统,不得不说VFS:Virtual File System,如上图,Linux设计了一个文件系统的中间层,上层用户都直接和VFS打交道,文件系统开发者再把VFS转换为自己的格式。这样做的优点主要有:
用户层应用不用关心具体用的是什么文件系统, 使用统一的标准接口进行文件操作;
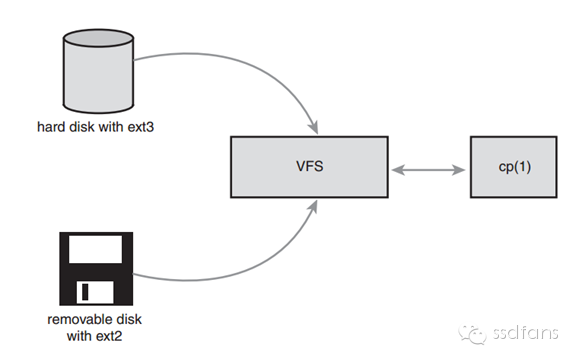
如果一个系统包含不同分区,不同分区使用不同的文件系统,他们之间可以通过这个VFS交互,比如从U盘、网盘拷数据到硬盘就得通过VFS转换管理信息,如下图;
可以动态支持很多文件系统,添加一个只需要安装驱动就可以了,不需要内核重新编译。
我们来看看这张文件系统层次图中的每一层。
用户层:最上面用户层就是我们日常使用的各种程序,需要的接口主要是文件的创建、删除、打开、关闭、写、读等。
VFS层:我们知道Linux分为用户态和内核态,用户态请求硬件资源需要调用System Call通过内核态去实现。用户的这些文件相关操作都有对应的System Call函数接口,接口调用 VFS对应的函数。
文件系统层:不同的文件系统实现了VFS的这些函数,通过指针注册到VFS里面。所以,用户的操作通过VFS转到各种文件系统。文件系统把文件读写命令转化为对磁盘LBA的操作,起了一个翻译和磁盘管理的作用。
缓存层:文件系统底下有缓存,Page Cache,加速性能。对磁盘LBA的读写数据缓存到这里。
块设备层:块设备接口Block Device是用来访问磁盘LBA的层级,读写命令组合之后插入到命令队列,磁盘的驱动从队列读命令执行。Linux设计了电梯算法等对很多LBA的读写进行优化排序,尽量把连续地址放在一起。
磁盘驱动层:磁盘的驱动程序把对LBA的读写命令转化为各自的协议,比如变成ATA命令,SCSI命令,或者是自己硬件可以识别的自定义命令,发送给磁盘控制器。Host Based SSD甚至在块设备层和磁盘驱动层实现了FTL,变成对Flash芯片的操作。
磁盘物理层:读写物理数据到磁盘介质。
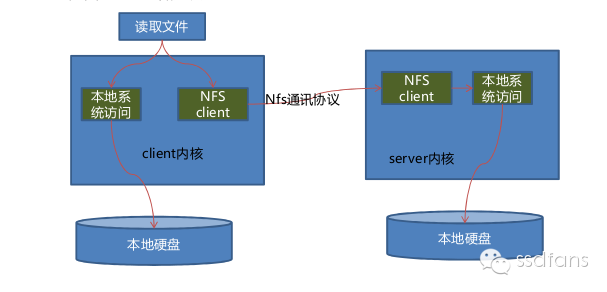
网络文件系统NFS把文件层之后的操作在远端实现。下面是NFS基本原理。
VFS组成
尽管Linux内核是C语言写的,但VFS是一种面向对象的框架,把文件相关的东西分为4个对象:
Superblock:一个文件系统有一个,含有文件系统的属性和接口,
属性:文件系统的一些参数;
接口:mount和umount接口等。
Inode:一个文件有一个,含有文件的属性和文件属性的接口(不是文件读写的接口)。文件夹也当成文件处理,有自己的inode。
属性:文件名,创建时间,修改时间,访问权限,文件保存的LBA等;
接口:创建,删除文件夹等。
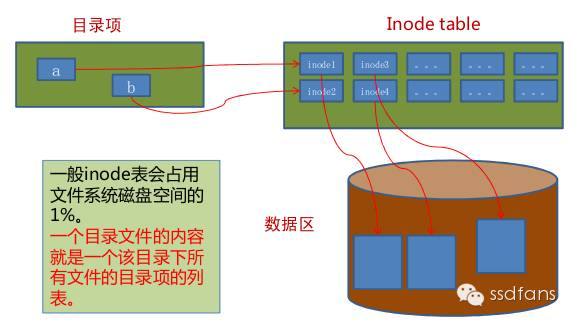
Dentry :一个目录有一个,用来方便目录查找等。访问文件的时候,用户发下来文件路径,VFS通过Hash的方法直接通过路径查到最终Dentry,找到inode,来直接查找一个路径,而不是一级级翻下来。
属性:目录名等;
接口:查找文件路径等。
File :对文件进行操作的接口,这个是大家最熟悉的了,读写都通过它。
属性:文件锁,当前访问的偏移地址等;
接口:fopen,fclose,fwrite,fread,fsync,异步读写等。
这些对象平时保存在磁盘上,使用时加载到内存并给各种属性和接口赋值,同时inode和dentry都是有缓存的,这样每次查找一个路径,就不用等啊等啊读磁盘了,翻一下缓存就能快速找到。
下面是一个文件结构示例:
Unix风格文件
那么问题来了,挖掘机技术到底哪家强?有人要问,真的靠一个VFS能统一所有的文件系统操作吗?微软那么配合啊,会采用和Linux一样的接口?所以VFS要求文件系统要有Unix风格,主要是三种Style:
文件夹和文件都是一样的处理;
文件的信息和文件数据分开,文件信息放在inode里面,数据放在数据块里面;
Superblock来表示文件系统的信息。
Windows的文件系统FAT,NTFS其实不太一致,有的文件信息不专门用inode来存,有的文件夹和文件区别开来,这些文件系统磁盘里面没有superblock,inode,需要在内存中生成inode和superblock来模拟。
引用
Robert Love, Linux Kernel Development.
https://swbae98.wordpress.com/tag/ext4/
二:饿想她超市血拼记
自从二十多年前一些追寻自由的人建立了Linux市以来,饿想她超市就开始经营超市业务,并且不断扩大,每开一家新店,就会用更先进的技术管理商品,给顾客更好的购物体验,所以现在饿想她已经是Linux市最有人气的大超市了,市民们的各种日用品都去里面采购,每天人声鼎沸,熙熙攘攘。

话说有一个小青年叫蛋蛋,刚从著名的Linux市代码农业职业技术学院毕业,成为了一名光荣的码农。租好了房之后,他听说著名的”饿想她”超市在附近新开了第四家分店,叫做EXT4,蛋蛋决定去买些吃的回来。这里我们要提醒一句了,Linux市已经进入了信息化社会,信息就是能量,居民们吃的食物叫做数据,单位是字节。

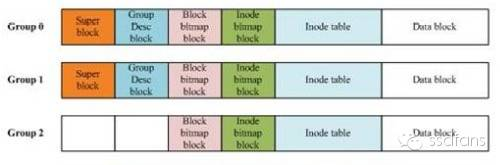
货架Block Group
民以食为天,蛋蛋怀着饥饿的心情,来到饿想她超市大门口,看到了亮闪闪的Logo,兴奋的已经饱了半分。饿想她是个工业化的超市,所有的物品都放在一个叫做sector的盒子里,每个sector大小是512字节,但是饿想她真正登记货物的最小盒子叫Block,里面放了8个sector,总大小4k字节。

饿想她超市把整个超市划分成很多货架,叫做Block Group,每个货架上放了32768个Block盒子。每个货架上的东西如下图,后面将一一介绍。Superblock是超市概览,Group Descriptor 是货架介绍,Block bitmap是盒子的分布表,Inode Bitmap是货物标签分布表,Inode Table是标签存放的地方,Data Block是货物存放的地方。
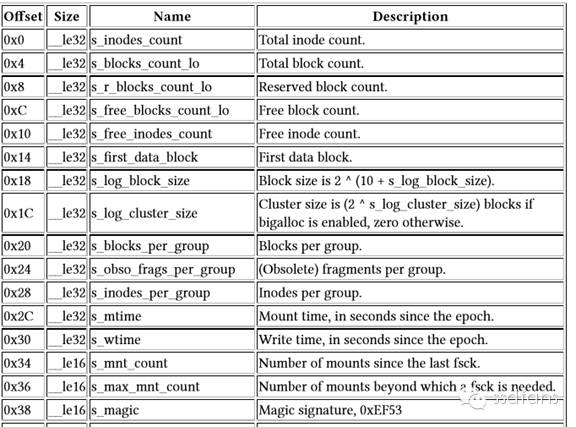
超市概览Superblock
如上图,蛋蛋提着个购物篮快步走到了一个长长的货架前面,看着玲琅满目的商品,不禁一头雾水:天哪,我该怎么找东西啊?还好,旁边有一位美丽的导购姐姐带蛋蛋来到货架最前面,拿起一本小册子给蛋蛋,上面是整个饿想她超市的介绍,叫做Superblock。里面的主要内容就是下面这张表,冒出了一大堆的名词,但谁叫蛋蛋是农业技术学校毕业的呢,一看就明白了。这里面说了,超市有多少个block盒子,多少个货物的标签inode,每个货架有多少的盒子block per group,超市的开张时间mount time,蛋蛋想一定要记住,周年庆了就来捡便宜货,嘿嘿~
引用
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout
三:超市货架的秘密
上回说到,蛋蛋来到饿想她超市第四家分店EXT4,发现每个货架Block Group上都有一份超市概览Super block的副本供顾客查阅。凭着代码农业扎实的基础,蛋蛋终于搞清楚了货架的秘密。

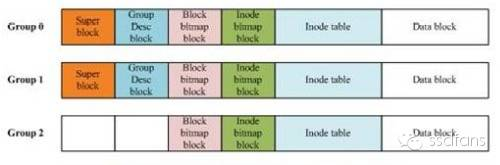
首先我们还是得介绍一下Linux市民和我们当代人类的有一个不同。看过三体的人都知道,三体人没有语言,而是直接看到对方的思想,不能掩藏自己的想法。Linux市民没有嘴巴,他们只能通过数据来交流,这就是他们以数据为食物的原因:说多了,数据用没了,饿了!
货架说明Block Group Descriptor
蛋蛋看完了超市概览,就把它放回第一个大盒子block里。然后,打开第二个大盒子,从这里开始的几个大盒子是货架说明,Block Group Descriptor。

如下图,这里面写了这个货架上标签分布表inode bitmap、标签表inode table在哪里,货物分布表block bitmap在哪里,货架上还有多少空盒子free block count,空标签等等,最后还有一些特殊的字符checksum来帮助检验有些重要数据是不是写错了。
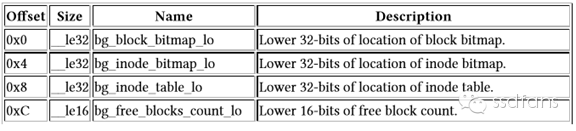
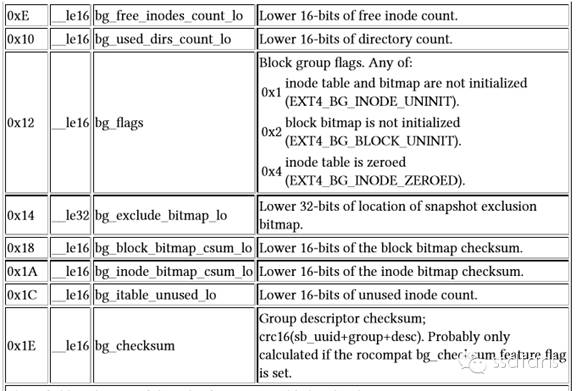
标签和数据分布表bitmap
蛋蛋合起盒子,按照货架说明的指示,打开后面的几个盒子,分别找到了标签分布表inode bitmap和盒子分布表block bitmap。前者表示标签表inode table哪些条目是占用的,后者表示哪些盒子里面有数据。他们的内容都是用一个bit是0或者1表示空或者非空。Bit是Linux市民食物字节的基本元素,8个bit组成了一个字节。
标签表inode table
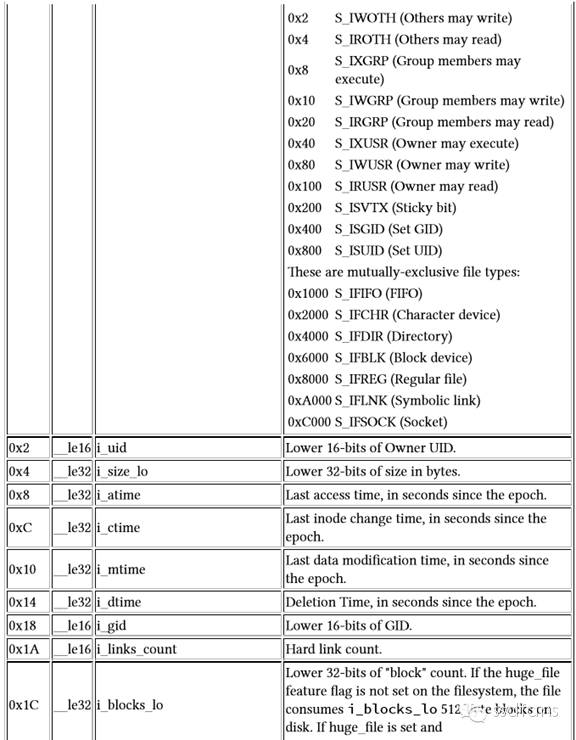
蛋蛋看完两个分布表,就知道货架上的一个基本情况了,于是关起盒子,按照货架说明的指示,打开了有一个盒子,上面写着:标签表。我们要透漏Linux市的第三个特征了,他们的货物叫做文件,每个文件在超市里面都有一个标签来说明和索引,方便查找和管理,叫做inode。

标签表里面有货架上所有货物的标签,每个标签的主要内容如下表。包括了:
货物的权限,是否是VIP专享,是不是私人定制的,是不是共享的。
是不是某些特殊的货物,他们并不是拿来吃的,而是一些设备,能够使用。比如char设备,block设备,都是一些机器,char设备能够执行用户的命令,block设备可以批量执行用户的一串命令,存数据,查看数据。
货物的大小,用了多少个字节,用了多少个盒子block。
货物的最近查看时间,维修时间,移走时间等。

引用
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout
四:神奇的标签
上回我们说到,蛋蛋从标签表中看到了一个标签inode的内容,inode里面包含的东西除了那些,还有个更重要的就是货物的位置:到底放哪些盒子里面?

要知道Linux市的货物是用字节组成的长串,有的只占了一个盒子,有的占了多个盒子,甚至成千上万个盒子,而标签表只留了60个字节保存查找信息,根本放不下那么多盒子的位置信息,那么到底该怎么办?我们来看看聪明的饿想她超市怎么解决这个查找的难题。
三级映射
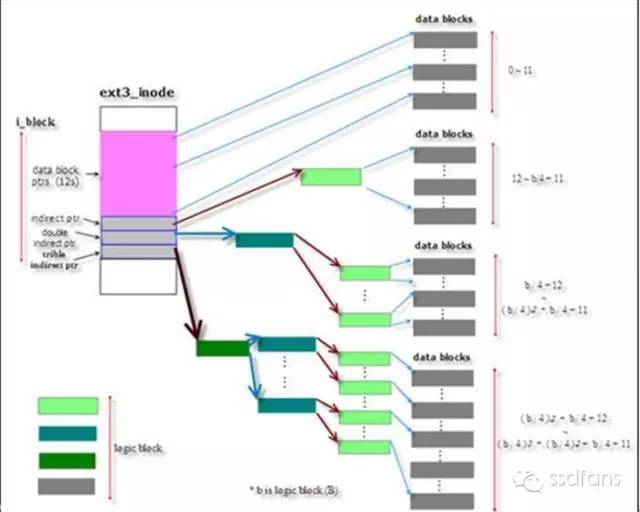
俗话说,有钱能使鬼推磨,为了降低成本,给顾客提供更大的便利,饿想她超市的老板命令工程师赶快解决上面这个问题,搞定了工资翻番,否则卷铺盖走人。工程师老蛋刚刚开始Linux的码农生涯,就接了这么个活,站在自己家的大树底下冥思苦想,想了几天几夜,还是没有头绪。一气之下,他一头撞在树皮上,心想自己要跟月亮上的吴刚一样,一辈子要跟这棵树为伴了。唉,树啊!哎,树!哈哈哈哈!大树底下传来了老蛋的四声大笑:我终于明白了,在这个60个字节里面可以用三级映射来存放货物的地址,就跟树的枝干一样,一级级细分。
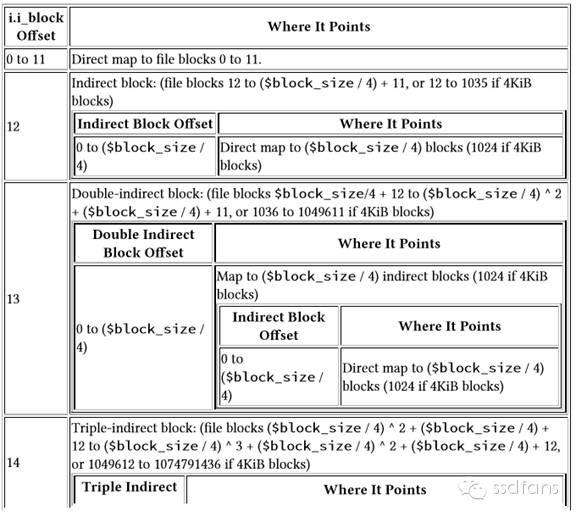
如下图,开始是头几个数据盒子的位置,对那种小货物足够了。后面是一级映射表的盒子位置,找到这个盒子就能找到所有的1024个数据盒子,因为里面放了1024个盒子的位置。如果还不够,那么就用后面的二级映射,里面是所有一级映射的位置,从一级映射的盒子里面再找到所有的数据盒子位置,这样就是1024*1024个盒子了。尼玛,还不够,嘿嘿,后面还有三级映射,总共包含1024*1024*1024个数据盒子的位置。

扩展树:真正的树
老蛋得到了饿想她超市创始老板的嘉奖,成了公司技术骨干。但是,后来超市创始老板退休,少老板接班,新官上任三把火,决定建设一个更厉害的第四家分店ext4。他年轻有为,找到老蛋说:蛋仔,你这个三级映射太麻烦了,位置都是固定死的,修改什么的太麻烦,而且如果盒子都是连续放置的,还得在映射里面一条条保存他们的位置,一点都不高效,太浪费空间了。回去给我弄个更好的办法,完不成提头来见!
老蛋觉得自己受到了侮辱,成名作被一个小年轻贬的一文不值,忍着内心的悲愤回到家,跟老婆说自己都想跳槽了。老婆听了,瞪了他一眼:没本事整更牛的,躲开算什么男人。老蛋一想,脑子也转过来了,于是又来到熟悉的大树下,想啊想,还是没办法。突然,他想,瞅瞅大树肯定有办法,一抬头,心中顿时豁然开朗:树啊树,又是你帮了我,不禁老泪纵横~
老蛋这次设计了一棵真正的大树来放货物的地址。如下图,树有一个根节点,后面有很多子节点,每个节点都有一个header,header后面的数据有两种类型,第一种是索引,就是树枝的位置,第二种是叶子,放数据盒子的位置。这样一级级就可以查到,而且数据节点表示的是一串连续盒子的开头位置和数量,而不用全都一个个列出来。老蛋再次得到了少庄主的嘉奖,他得意地回家对老婆说:每一个成功的男人背后都有一个不认输的女人!
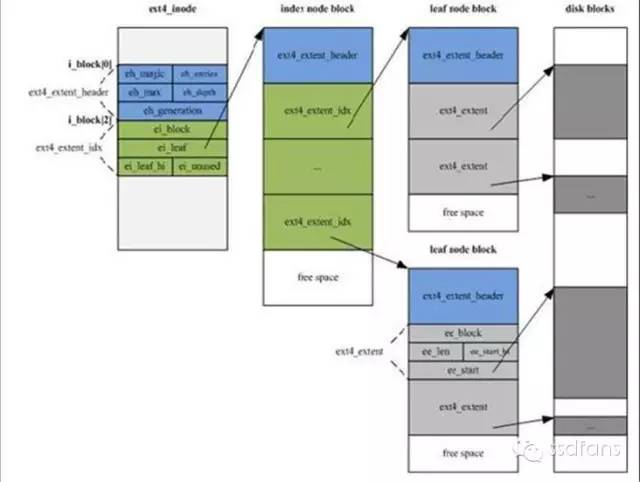

节点头

树枝内容,指向更细的树枝
叶子内容
引用
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout http://www.datarecoverytools.co.uk/2009/11/16/learn-more-about-ext4/ http://blog.chinaunix.net/uid-26430381-id-4559492.html
五:按图索骥找吃的
蛋蛋自以为搞清楚了货物标签的来龙去脉,突然他发现了一个重要的问题:货物的名字在哪里?是啊,标签inode里面那么多东西,为什么偏偏没有货物的名字呢?那么文件名到底藏在哪里,蛋蛋带着疑问继续翻盒子,终于找到了真相。

话说古代有个人,拿着马经去找马,按照图纸牵了一匹马回来,没想到大家发现他找到的是一只大蟾蜍!这就是上面这张图,按图索骥的故事,讽刺刻板按照图纸做事,但其实应该怪写马经的人,写得不严谨,不精确,让人找到错的东西。Linux市经济发达,货物众多,仅仅取个名很容易混淆,而且也不好管理。饿想她超市的人为了精确的表示每一个货物,给每个货物按个名字的同时,还加了个目录,每个目录里面有文件,也有目录,最上面是个根目录,这样,从根目录出发,一级级找下去,就能找到最终的货物。
路径Dentry
如下图,要找一个文件/var/test.txt,这条路有两条路径,/->var,var -> test.txt,合起来就成了完整的路。每一个目录有一个inode,同时也有dentry。先拿到根目录/的dentry,得到它的inode地址,从inode又知道了data block位置,data block里面是个大数组,依次放着所有这个目录里面一级目录和文件的dentry。把var和每一个dentry的文件名一一比较,就找到了var的dentry,按同样的方法,继续重新开始,最终就找到了test.txt的数据盒子block了。
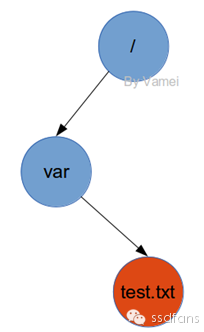
通过根目录/的dentry得到inode 2,到目录盒子和每个dentry比较,发现var的dentry;
找到var的inode 10747905,到目录盒子和每个dentry比较,发现test.txt的dentry;
找到test.txt的inode,知道了所有的数据盒子位置,可以访问数据了。

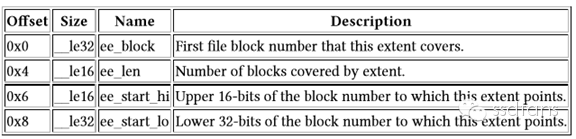
Dentry的内容如下,主要是文件名和inode的编号。

Hash Tree快速查找
了解到这里,蛋蛋真是烦透了:买个东西这么麻烦啊!要在每个dentry的盒子里面和所有下一级dentry一个个比较,真是累死人了!还想不想做生意了,搞得哥不爽,去别家买了。扭头便走,走到门口又停下来了:我是不是低估了饿想她超市的智商,他们生意做得这么好,肯定不会一直用这么麻烦的流程。蛋蛋又回去逛了逛:原来前面那一套都是旧的超市用的过时的方法,最近新开的店都用了更先进的方法:Hash Tree。什么,又是一棵树,你们超市工程师以前都是种树的吧?
如下图,根目录的盒子里面是个表,每个路径用hash算法算出一个hash值,每个hash值有一个自己的盒子,里面是所有的dentry,如果多个路径是同样的hash值,那么就在这个hash的盒子里面放所有的dentry。这样,最快查一次就查到一个路径的dentry了,毕竟hash重复的概率还是不大的。
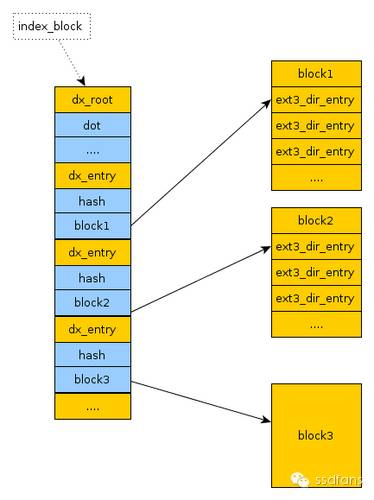
每个hash条目的内容如下,32位Hash值和对应的盒子地址。

引用
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout
http://www.cnblogs.com/vamei/p/3506566.html
http://oldblog.donghao.org/2011/03/ext3adir-indexioo.html
六:诺兰,记忆碎片,掉电恢复
自从蝙蝠侠系列,盗梦空间和星际穿越全球热映之后,导演克里斯托弗•诺兰成了票房的保证。

诺兰早期拍过一部电影——记忆碎片,主人公的妻子被人奸杀,自己脑部受伤,从此患上了一种失忆症:没办法形成新的记忆,因为新的记忆只能持续10分钟。但是他还是要找到真凶,为爱妻报仇。为了让自己记忆,他不断的在身上写笔记,拍立得拍照片,腿上贴便签,记下新的进展和下次的行动。每次醒来后从这些记录搞清楚情况,继续报仇之路。剧透就到这里,要想知道凶手的结局,请观看这部精彩的影片。
SSD掉电恢复
老子说祸兮福之所倚,这个人经历了这么多磨难,终于成为了一个杰出的存储系统数据恢复专家。存储系统掉电之后就类似于人的失忆,必须通过之前记的记录恢复出数据的索引表。要像他一样不断做记录,还要做的有规则,乱记了下次醒来就南辕北辙了。对于SSD来说,要恢复出映射表,才能知道用户地址到内部物理地址的对应关系。具体掉电恢复的技术brokenegg大神已经介绍过,请点击本文末尾的阅读原文查看。
Journal——EXT3/4文件系统掉电恢复利器

本文介绍文件系统EXT4(不是EXO)的掉电恢复利器日志(Journal)。
如果你看了公众号前面文件系统的文章,就知道最核心的数据是lnode,文件系统的映射表,记录了每个文件数据块的地址。
当文件数据已经写入磁盘,但是inode还没写下去,发生了异常掉电,那么就没办法读到这些数据了。日志的作用是为了加速异常掉电的恢复过程。对于要保护的数据,每写一份,就会在日志中留下一条记录,日志数据会定期备份到磁盘上,叫做Checkpoint。
以前的文件系统,掉电恢复要扫描整个磁盘才能把inode和数据块正确对应起来,有了日志之后,就不用这样慢悠悠扫全盘了,只要把上次Checkpoint保存的日志扫一遍就可以了。已经删除的文件,只要数据块还没被覆盖,也能通过journal恢复出来。
引用:
https://view.officeapps.live.com/op/view.aspx?src=http%3A%2F%2Fwww.cs.umd.edu%2Fprojects%2Fshrug%2Fppt%2F5-Oct-2001.ppt
七:最适合SSD的文件系统
饿想她超市和GRE单词
我之前用饿想她超市的例子介绍了EXT4文件系统,SSDFans的不少读者从事技术研发,功力深厚,觉得这样写显得太业余了:还不如直接看技术文档爽快!有个读者回复让我们直接改名叫SSD业余粉丝o(^▽^)o

我先不直接说明原因,来说说GRE单词吧。不少人可能背过俞敏洪的GRE红宝书,为了帮助背单词,俞敏洪把很多单词进行了拆分联想,帮助记忆。比如Vulnerable这个单词,可以读音理解成汉语的温拿(winner),温拿过得比较舒服,温室里的花朵,很脆弱,所以就想到了单词的意思:脆弱的,容易受伤害的。还有一种记忆法是重复,不断重复背诵,再难的也记住了。我们工作中大部分记忆都是后者,为什么大家对自己的专业领域如此精通?就是通过一遍遍工作中的重复劳动牢牢掌握了这些技能,用的时候信手拈来。
对于不了解文件系统的人,工作中也不会大量接触,就没办法通过重复法记住,那只能通过联想法了,这就是我用饿想她超市来类比文件系统的原因:不了解文件系统的人,只要记住文件系统是个超市,文件是货物,放在盒子block里面,inode是货物的标签,记录了货物的盒子位置,就掌握了文件系统的精髓。如果只是看看技术文档,估计过不了一个月就忘得一干二净了。
适合SSD的文件系统最需要什么?
其实最需要的就是文件的inode映射表和SSD内部的FTL映射表统一成一个表,这样就解决了大部分问题。可以参考本站的从此,SSD不用再伪装成HDD(http://www.ssdfans.com/?p=832)一文,这样做有几个优点:
文件查询快,FTL的查询效率是很高的。
SSD通过文件知道数据的相关性,可以最高效的分布一个文件到每个chip上,提高读写速度。
只需要在SSD做垃圾回收,整合磁盘整理。
SSD知道哪些文件被删除了,这些删除的数据不用再占用空间,因此垃圾回收的速度变快了。
复制操作很简单:复制映射表就可以了。为什么机械硬盘不能这么做?机械硬盘如果两个文件对应到同样的一组LBA,其中一个修改就很麻烦,需要把改动的LBA重新映射到新的LBA上,维护一个重定向表。其实很多存储系统的snapshot就是这么做的,弄一个增量表。而对SSD而言,修改就是新的写操作,需要写到新的物理地址,必然要更新映射表,所以天然的实现了重定向。
适合SSD的文件系统在哪里?

这样看来,目前并没有免费开放的SSD专用文件系统,因为大部分SSD为了适应HDD的框架,都是把LBA作为基本单位,文件系统来访问LBA,机械硬盘时代发明的LBA隔断了SSD和文件系统的联系。就像上图,SSD是那个铁路和火车,但是悲哀的是没有火车头,车都是马来拉的,速度自然提不上去了。
SSD没有一个通用的协议来开放内部数据通道给上层软件,如果有这样一个开放的接口,那么诞生可以融合SSD内部FTL的文件系统也是自然的事 。
本文转载自SSDFans:

(完)
更多精彩,尽在"Linux阅码场",扫描下方二维码关注

你的随手转发或点个在看是对我们最大的支持!