一、Loki的基本介绍
1、基本介绍
Loki 是由 Grafana Labs 开发的一款水平可扩展、高性价比的日志聚合系统。它的设计初衷是为了有效地处理和存储大量的日志数据,与 Grafana 生态系统紧密集成,方便用户在 Grafana 中对日志进行查询和可视化操作。
从架构层面来说,Loki 主要由三个部分组成:
客户端(Agents):负责收集日志并将其发送到 Loki 服务器。这些客户端可以是各种应用程序或服务器上的日志收集代理,如 Promtail(专门为 Loki 设计的日志收集器)。Promtail 能够自动发现日志文件的变化,将新的日志行发送到 Loki。
服务器(Server):接收来自客户端的日志数据,对其进行处理和存储。Loki 服务器会将日志数据存储在一个分布式存储系统中,并且能够对日志进行索引,以便后续的快速查询。
查询前端(Query Frontend):作为用户查询日志的接口,它可以接收来自 Grafana 或其他工具的查询请求,将请求转发到合适的服务器进行处理,并将查询结果返回给用户。
2、特点
高效的存储成本
Loki 采用了一种不同于传统日志存储系统的存储策略。它基于标签(Labels)来对日志进行索引,而不是对每一条日志的全文进行索引。例如,一个 Web 应用的日志可能会有 “app_name”(应用名称)、“instance_id”(实例 ID)、“log_level”(日志级别)等标签。通过这种方式,Loki 可以显著减少存储索引所需的空间,从而降低存储成本。相比传统的全文索引日志系统,Loki 可以在存储大量日志数据时节省大量的存储空间。
与 Grafana 无缝集成
作为 Grafana 生态系统的一部分,Loki 与 Grafana 的集成非常紧密。用户可以在 Grafana 中轻松地配置 Loki 数据源,然后使用 Grafana 强大的可视化功能来展示和分析日志。例如,用户可以创建仪表盘,将日志数据与指标数据(如 CPU 使用率、内存使用量等)结合起来展示,从而更全面地了解系统的运行状态。而且,在 Grafana 中查询 Loki 日志的操作非常直观,用户可以使用类似于 SQL 的查询语言来搜索日志,比如根据标签、时间范围和日志内容等条件进行查询。
水平可扩展性
Loki 能够很容易地进行水平扩展以应对不断增长的日志数据量。它的分布式架构使得可以通过添加更多的服务器节点来增加系统的处理能力和存储容量。例如,当一个企业的业务增长,日志数据量从每天几百万条增加到几千万条时,可以通过添加 Loki 服务器节点来确保系统能够继续高效地处理和存储这些日志,而不会出现性能瓶颈。
多租户支持
在一些复杂的企业环境中,可能需要对不同的用户、团队或项目的日志进行隔离和管理。Loki 提供了多租户支持,通过配置不同的租户 ID 和访问权限,可以确保每个租户的日志数据是独立的,并且只有授权的用户才能访问相应租户的日志。这对于云服务提供商或者大型企业内部的多个部门共享日志存储系统非常有用。
二、各组件的部署
1、Kafka集群的部署
详情请看之前的文章:抛弃zookeeper的Kafka集群,看这一篇就可以了_kafka集群搭建,不用zk-CSDN博客
部署Kafka集群,已经对应的Kafka-console-ui工具,用来辅助测试
2、部署grafana
具体请看前面的篇章:进阶 | Prometheus+Grafana 普罗米修斯-CSDN博客
3、部署loki
这里使用其二进制包进行安装:Releases · grafana/loki · GitHub
-
找到您要安装的版本的“资产”部分。
-
下载与您的系统相对应的 Loki 和 Promtail 归档文件。
此时请勿下载 LogCLI 或 Loki Canary。LogCLI 允许您在命令行界面中运行 Loki 查询。Loki Canary 是一个用于审核 Loki 性能的工具。
-
将包内容提取到同一目录中。这两个程序将在该目录中运行。
-
在命令行中,将目录更改 (大多数系统上的
cd) 到包含 Loki 和 Promtail 的目录。将以下命令复制并粘贴到您的命令行中,以下载通用配置文件。
使用与您下载的 Loki 版本匹配的 Git 引用来获取正确的配置文件。
wget https://raw.githubusercontent.com/grafana/loki/main/cmd/loki/loki-local-config.yaml
wget https://raw.githubusercontent.com/grafana/loki/main/clients/cmd/promtail/promtail-local-config.yaml这里的配置是通用配置

进行修改配置,然后启动Loki程序
server:
# Loki 服务监听的 HTTP 端口号
http_listen_port: 3100
schema_config:
configs:
- from: 2024-07-01
# 使用 BoltDB 作为索引存储
store: boltdb
# 使用文件系统作为对象存储
object_store: filesystem
# 使用 v11 版本的 schema
schema: v11
index:
# 索引前缀
prefix: index_
# 索引周期为 24 小时
period: 24h
ingester:
lifecycler:
# 设置本地 IP 地址
address: 127.0.0.1
ring:
kvstore:
# 使用内存作为 kvstore
store: inmemory
# 复制因子设置为 1
replication_factor: 1
# 生命周期结束后的休眠时间
final_sleep: 0s
# chunk 的空闲期为 5 分钟
chunk_idle_period: 5m
# chunk 的保留期为 30 秒
chunk_retain_period: 30s
storage_config:
boltdb:
# BoltDB 的存储路径
directory: D:\software\loki-windows-amd64.exe\BoltDB
filesystem:
# 文件系统的存储路径
directory: D:\software\loki-windows-amd64.exe\fileStore
limits_config:
# 不强制执行指标名称
enforce_metric_name: false
# 拒绝旧样本
reject_old_samples: true
# 最大拒绝旧样本的年龄为 168 小时
reject_old_samples_max_age: 168h
# 每个用户每秒的采样率限制为 32 MB
ingestion_rate_mb: 32
# 每个用户允许的采样突发大小为 64 MB
ingestion_burst_size_mb: 64
chunk_store_config:
# 最大可查询历史日期为 28 天(672 小时),这个时间必须是 schema_config 中 period 的倍数,否则会报错
max_look_back_period: 672h
table_manager:
# 启用表的保留期删除功能
retention_deletes_enabled: true
# 表的保留期为 28 天(672 小时)
retention_period: 672h
指定配置文件运行
./loki-linux-amd64 -config.file=loki-local-config.yaml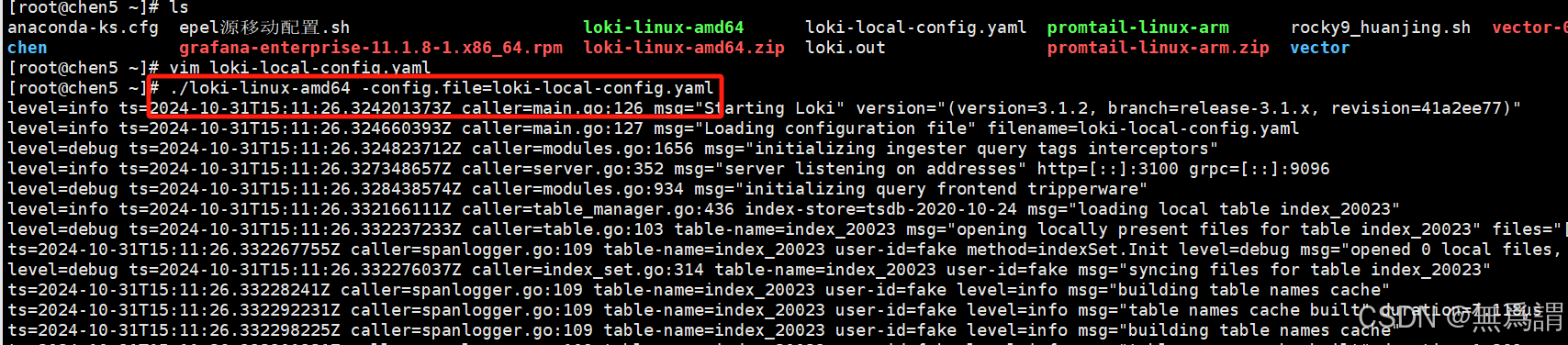
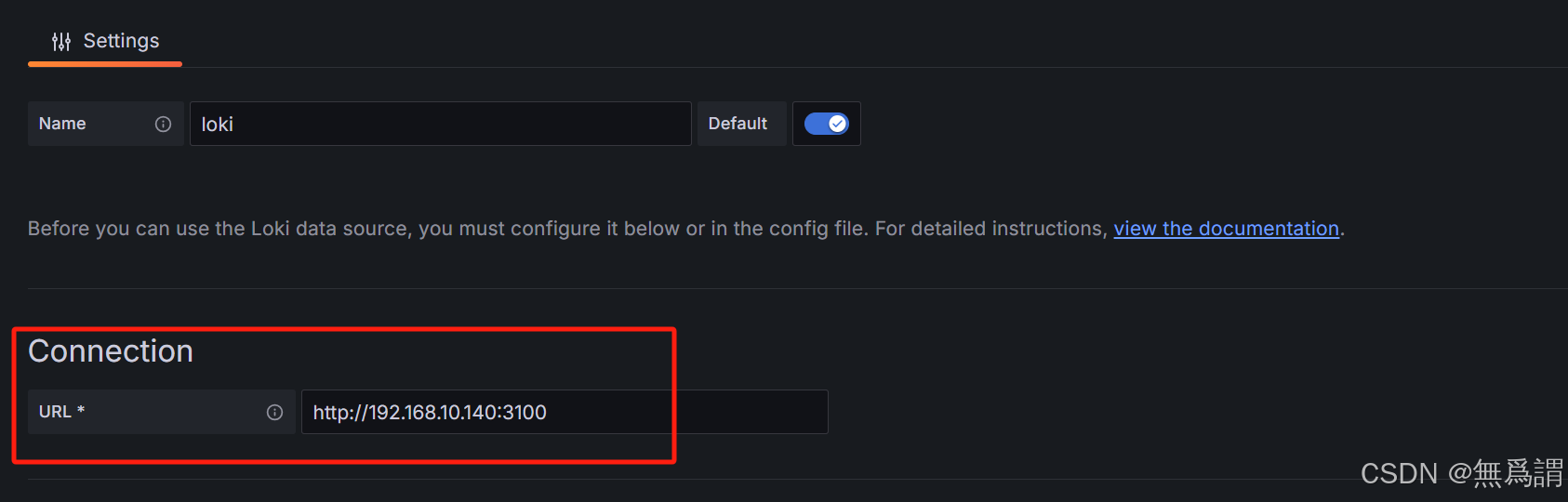
访问grafana使其关联对应的Loki

绑定对应的Loki地址和端口
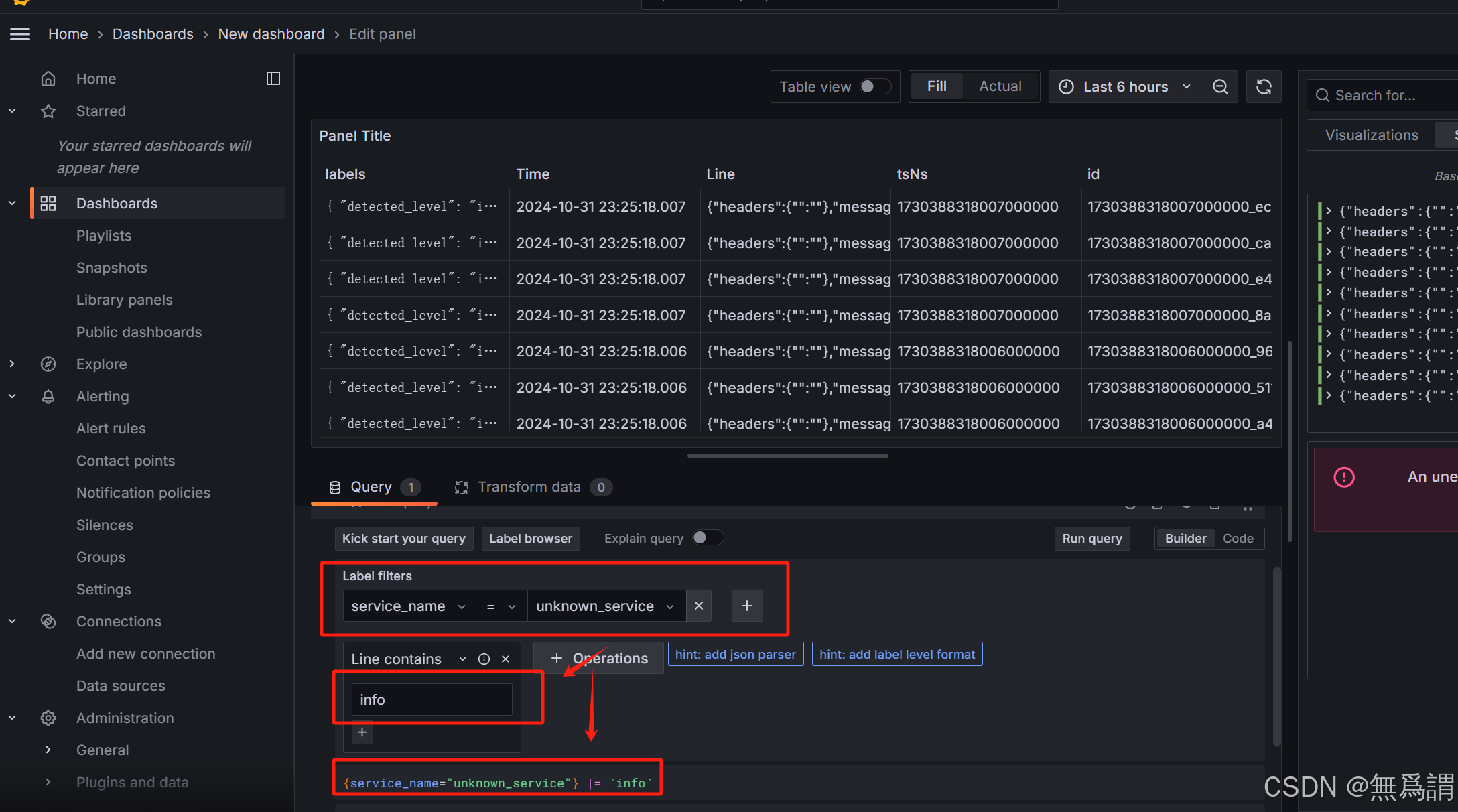
然后dashboard大盘,创建仪表盘,选择Loki就可以了
没数据时,默认是这样的
4、部署vector
1、基本介绍
Vector 是一个高性能、轻量级的数据收集、转换和发送工具。它可以处理各种类型的数据,如日志、指标等,并且能够将这些数据发送到多个不同的目标,如 Elasticsearch、Loki、Kafka 等。
2、配置文件结构
Vector 的配置主要通过一个 TOML 格式的文件(通常是vector.toml)来完成。TOML 是一种易于阅读和编写的配置文件格式。
一个基本的配置文件通常包含三个主要部分:sources(数据源)、transforms(数据转换)和sinks(数据接收器)。
这里使用的是二进制安装包进行安装的,下载位置:Download | Vector

修改配置文件,使其将Kafka中的数据传输到Loki上
# Change this to use a non - default directory for Vector data storage:
data_dir: "/var/lib/vector"
# Source: Kafka
sources:
kafka_source:
bootstrap_servers: "192.168.10.110:9092,192.168.10.120:3092"
group_id: "test"
topics:
- "test"
type: "kafka"
# Sink: Loki
sinks:
loki_sink:
endpoint: "http://192.168.10.140:3100"
inputs:
- "kafka_source"
type: "loki"
encoding:
codec: "json" # 这里假设使用json编码,你可以根据实际情况修改
labels:
key: "your_label_key"
value: "your_label_value"
运行并查看是否报错
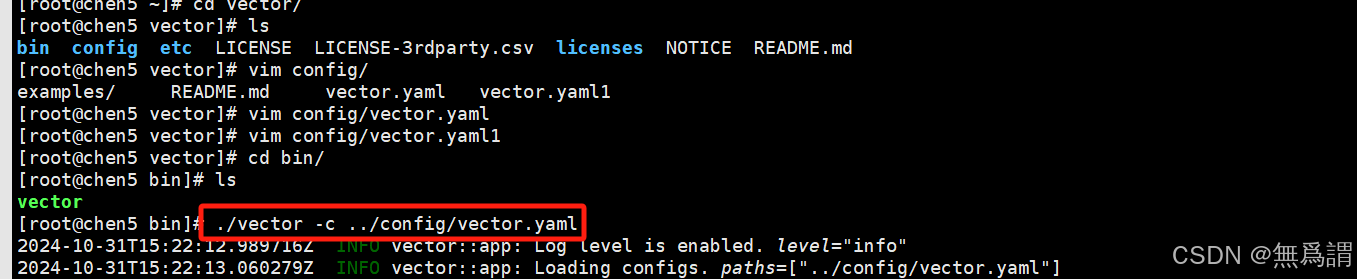
5、验证与测试
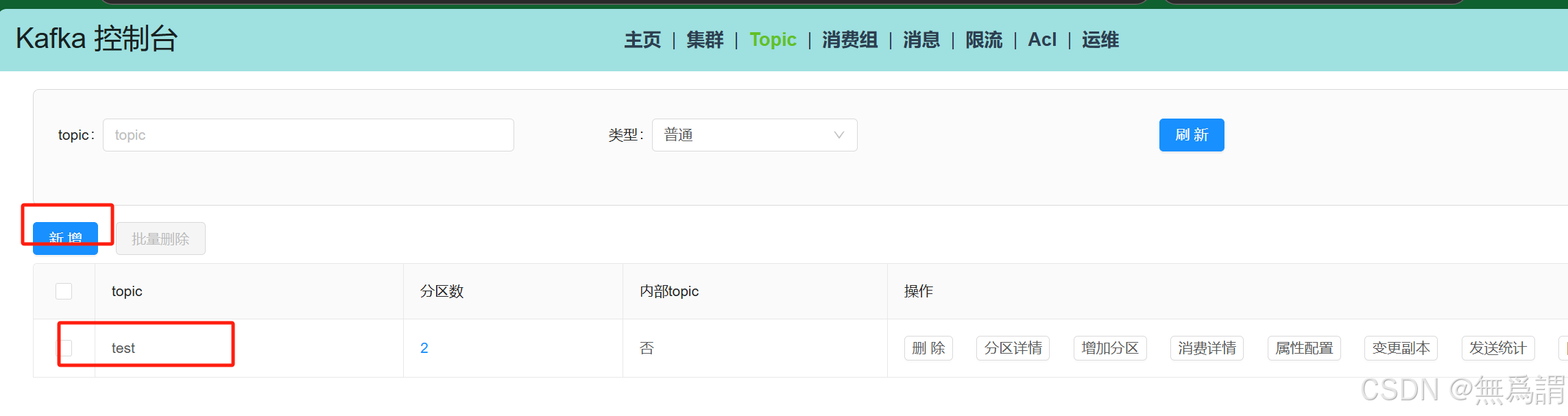
从上面的vector配置文件可以知道,其使用的是Kafka集群的test topic作为测试对象
通过kafka-console-ui工具创建对应的topic
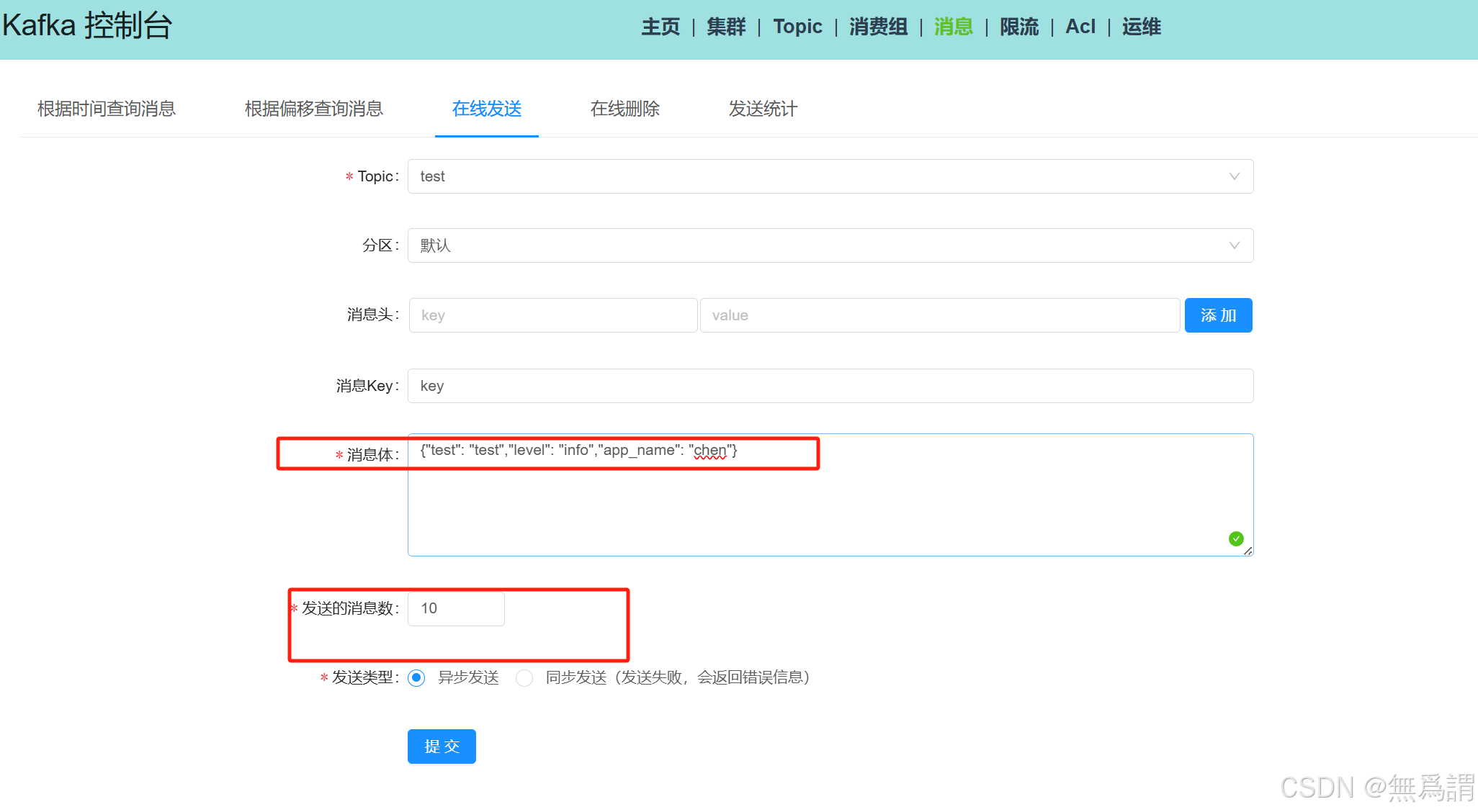
在线写入数据,用于验证数据的传输
在grafana中进行查看
通过标签和条件进行索引,这里因为没有定义标签名,所以是未知的服务