Task1:从零入门大模型微调
一、问题概述
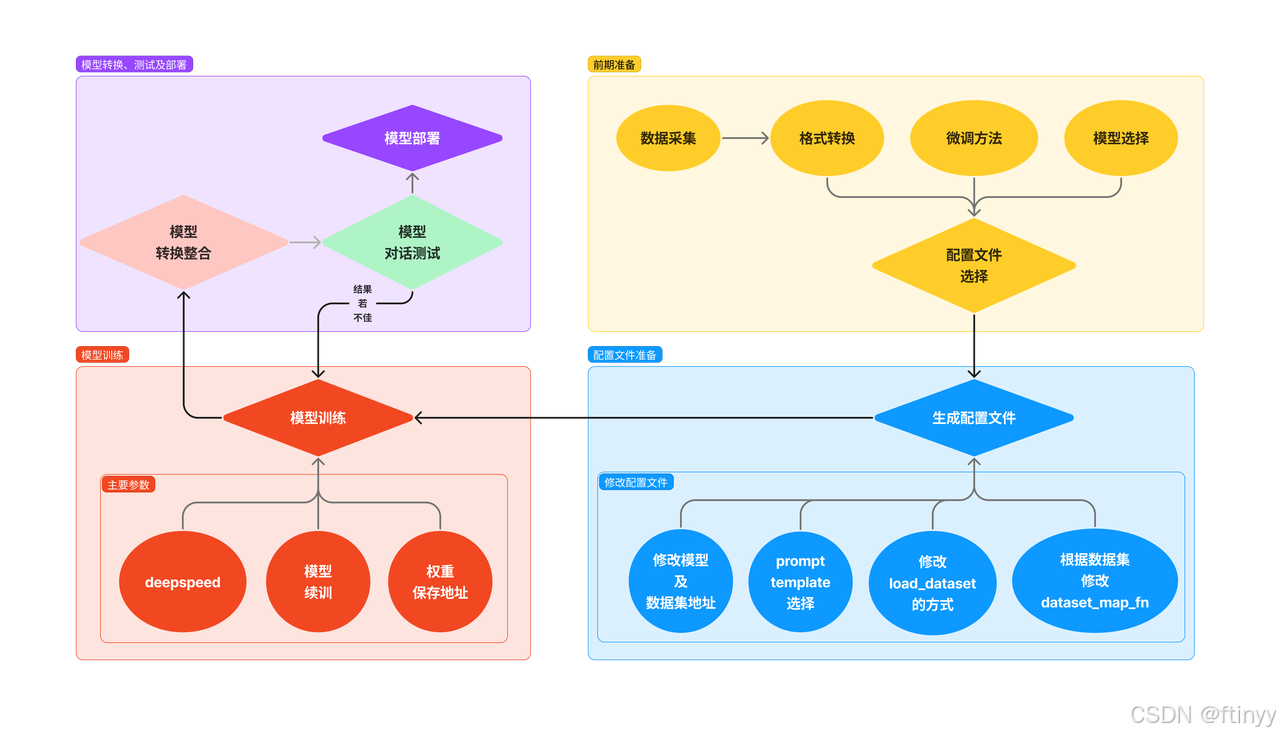
从零入门大模型微调 是 Datawhale 2024 年 AI 夏令营第四期的学习活动(“大模型技术”方向),基于讯飞开放平台“星火大模型驱动阅读理解题库构建挑战赛”开展的实践学习。学习内容:基于讯飞大模型定制训练平台和spark-13b微调模型,生成高考语文现代文阅读和英语阅读问题QA对。
二、操作步骤
可以根据上面链接的步骤顺利地跑通baseline,对大模型的微调有一个初步的了解。如果创建数据集时出现错误,我们可以尝试刷新或更换浏览器的方式来解决这个问题。按照步骤一步一步地来应该没有什么太大的问题。
还有就是我们创建自己的模型的时候要注意,框起来的这几个位置要记得保存一下。

因为回到我们的notebook里面需要我们填(下面红框这里),将刚才保存的那5个填到想应的位置即可。一一对应地填,因为有的位置可能和我们保存的那个位置有差别。
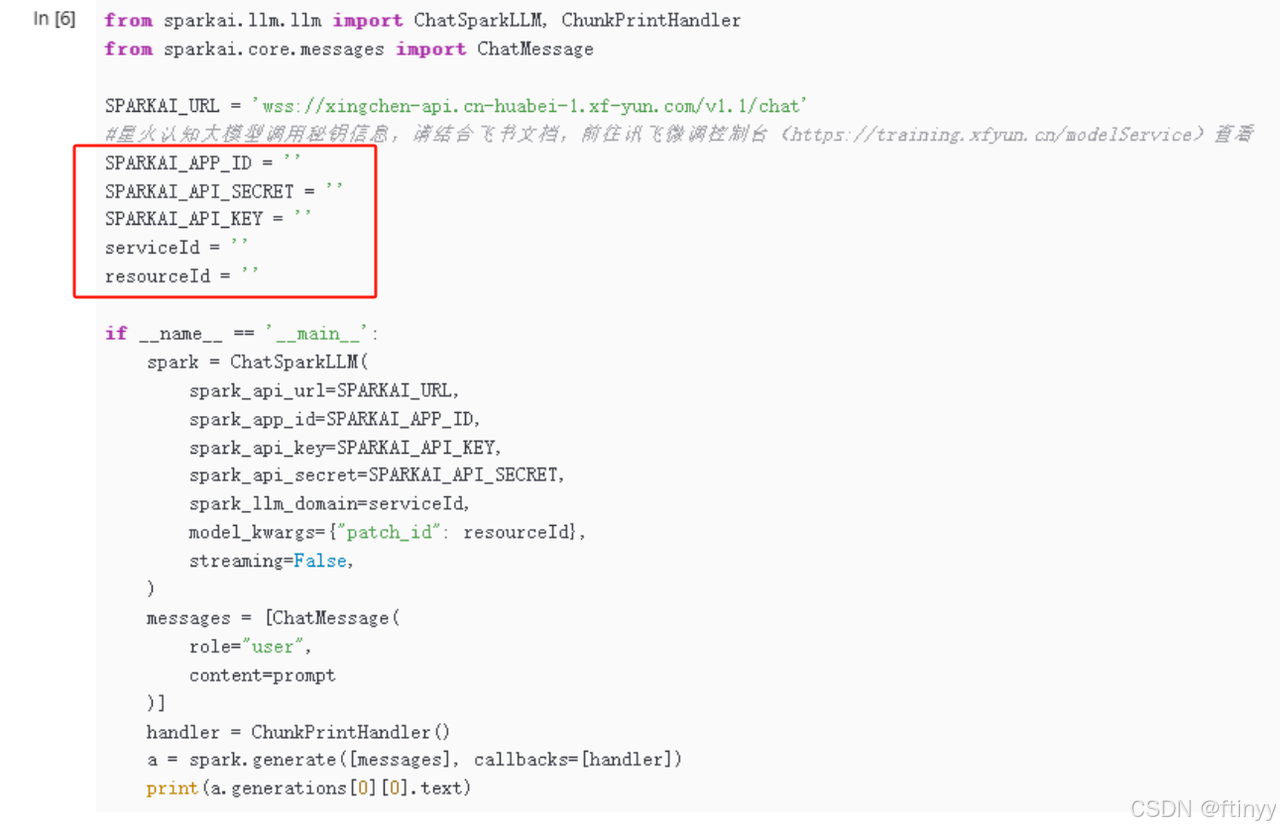
我按照上面的步骤跑完baseline时的可以达到65.83333,如果想要进一步提高分数,我们可以通过优化我们的数据集、更改学习率、基于我们仅有的数据集适当地提高训练轮次等。如果训练轮次太大容易发生过拟合。我将之前的学习率 lr=0.00008减小为0.00006,训练轮次调整为17,我的分数提升到68.125。
三、问题思考
大模型微调的挑战包括数据不足、过拟合、计算资源限制、超参数调整和模型泛化能力。解决方案有:使用数据增强、迁移学习、分布式训练、自动化超参数优化、正则化技术,以及模型剪枝和量化以提高效率。
评估大模型微调效果,可通过准确率、F1分数、召回率、精确度和AUC-ROC等指标。使用验证集进行性能测试,观察模型在未见数据上的表现。考虑模型的泛化能力和推理速度。交叉验证和混淆矩阵可辅助分析模型的优缺点。
Task2:baseline1精讲
注意:如果本次任务打卡中,如果你想要尽可能地提高分数,建议你可以通过修改Prompt部分来提高分数。
一、数据处理
(一)微调数据input部分
微调需要输入训练数据的阅读材料以及相关要求,这两部分组成我们的微调input内容。
阅读材料是我们的语文英语阅读题目,这部分材料分别对应语文和英语的阅读材料部分。即:notebook能看到在《训练集-语文.xlsx》《训练集-英语.xlsx》两个文件的材料,对应阅读文本数据列。
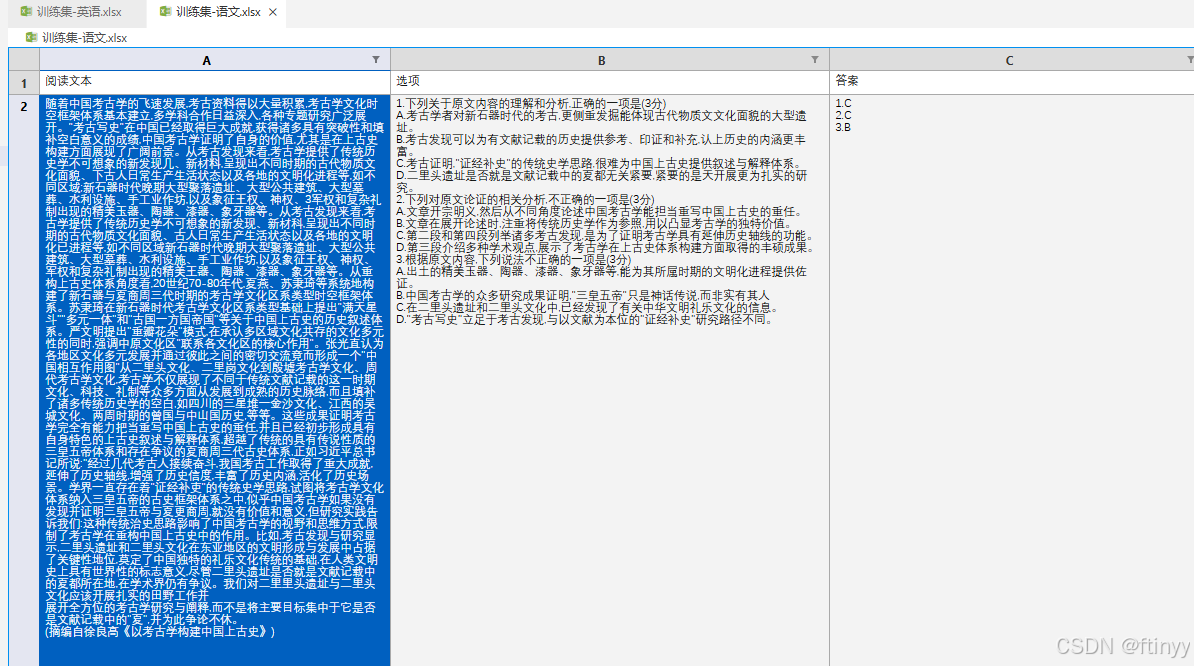
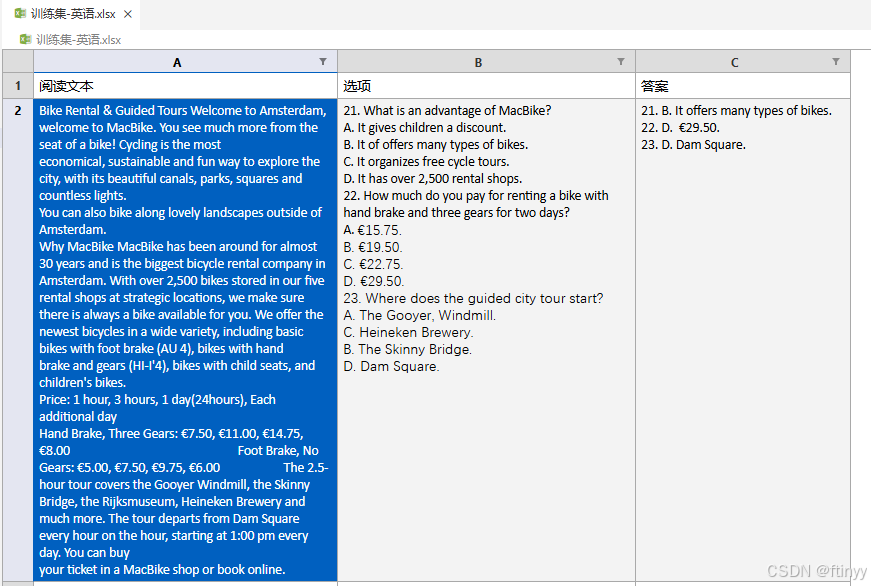
相关要求可以根据提示自己加以完善prompt,进一步完善prompt有助于我们后续成绩的提升。我们要修改的部分就是红框里面的部分,红框外面的部分一般不建议修改,因为这是官方的声明。下图的这部分内容在后续notebook的baseline1代码精讲部分会有所提及。

(二)微调数据target部分
大模型中我们知道是一个有输入送入模型,通过模型运行后给出文本输出这样的工作流程,那么我们期望大模型输出的就是选择题。 这里的选择题不单单指选择题的题干,还要有选项和参考答案,要有一定的格式。
(三)微调数据
阅读材料格式对题目影响不大,处理的核心在选项上。由于语文部分和英语部分不太一样,则应该分开处理。语文题目中,选项不光有选择的题目还包括简答题的题目。由于我们需要,那么需要区分出它们。语文题目中有()与分值,这个我们需要清洗出来。英语题目中选项用ABCD序号分开,但是有些序号按照ACBD的结构。答案有解释,需要思考怎么把答案选项抽取出来。
(四)数据处理方案
可以使用python中的正则表达式re来实现字符串的处理工作。使用pandas来做数据处理模块方便我们处理xlsx文件。处理目标:我们将文件中的数据读取出来,将语文数据与英语数据整理好后存储成可以微调的数据格式。可以微调的数据格式我们可以选择csv与jsonl类型。
Python 正则表达式:一个特殊的字符序列,能帮助你方便的检查一个字符串是否与某种模式匹配。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。re 模块使 Python 语言拥有全部的正则表达式功能。re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
pandas库: Python 语言的一个扩展程序库,用于数据分析。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
(四)处理流程
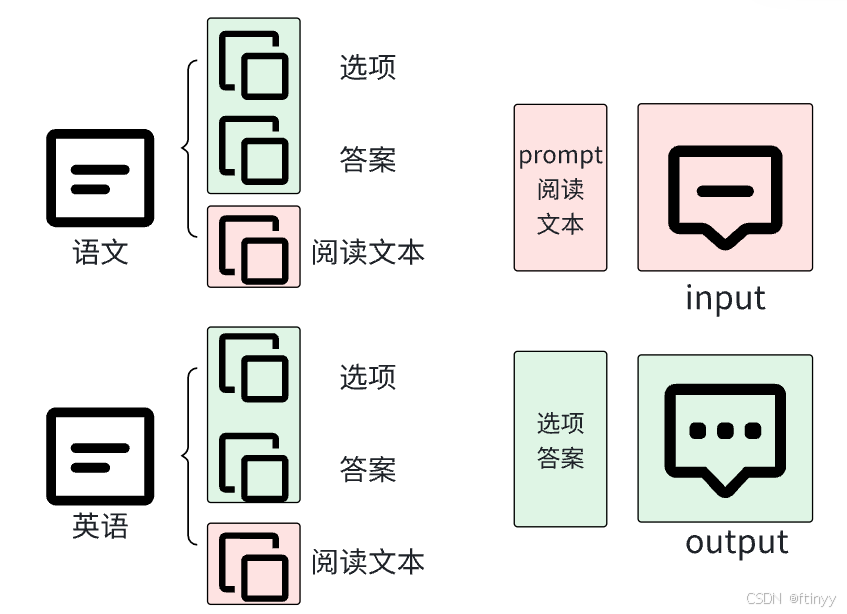
处理流程结构:将语文、英语训练集按照下图结构,选项与答案组成output模块,prompt+阅读文本组成input模块。
二、微调流程
(一)大语言模型
大语言模型(英文:Large Language Model,缩写LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。通常,大语言模型 (LLM) 指包含数十亿(Billion或更多)参数的语言模型,这些模型在大量的文本数据上进行训练,例如国外的有GPT-3 、GPT-4、PaLM 、Galactica 和 LLaMA 等,国内的有ChatGLM、文心一言、通义千问、讯飞星火、kimi等。
大模型的能力:上下文学习、指令遵循、逐步推理等。
大模型的特点:巨大的规模、预训练和微调、上下文感知、多语言支持、多模态支持、涌现能力、多领域应用、伦理和风险问题等。
(二)微调介绍
1.模型微调
相当于给你一个预训练模型(Pre-trained model),基于这个模型微调(Fine Tune)。预训练模型就是已经用数据集训练好了的模型。
 2.两种 Finetune 范式
2.两种 Finetune 范式
增量预训练微调 (Continue PreTraining),使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识,训练数据:文章、书籍、代码等。指令跟随微调 (Supervised Finetuning),使用场景:让模型学会对话模板,根据人类指令进行对话。训练数据:高质量的对话、问答数据。
3.微调的原因
相对于从头开始训练(Training a model from scatch),微调可以省去大量计算资源和计算时间,提高了计算效率,甚至提高准确率。普通预训练模型的特点是:用了大型数据集做训练,已经具备了提取浅层基础特征和深层抽象特征的能力。
不做微调:从头开始训练,需要大量的数据,计算时间和计算资源。存在模型不收敛,参数不够优化,准确率低,模型泛化能力低,容易过拟合等风险。使用微调:避免了上述可能存在的问题。
4.使用微调的情况
使用的数据集和预训练模型的数据集相似。(如果不太相似,效果可能就没有那么好了,特征提取是不同的,所以相应的参数训练后也是不同的。)自己搭建或者使用的模型正确率太低。数据集相似,但数据集数量太少。计算资源太少。
5.不同数据集下使用微调
-
数据集1 - 数据量少,但数据相似度非常高在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。
-
数据集2 - 数据量少,数据相似度低在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
-
数据集3 - 数据量大,数据相似度低在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)。
-
数据集4 - 数据量大,数据相似度高这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
6.微调指导事项
-
通常的做法是截断预先训练好的网络的最后一层(softmax层),并用与我们自己的问题相关的新的softmax层替换它。例如,ImageNet上预先训练好的网络带有1000个类别的softmax图层。如果我们的任务是对10个类别的分类,则网络的新softmax层将由10个类别组成,而不是1000个类别。然后,我们在网络上运行预先训练的权重。确保执行交叉验证,以便网络能够很好地推广。
-
使用较小的学习率来训练网络。由于我们预计预先训练的权重相对于随机初始化的权重已经相当不错,我们不想过快地扭曲它们太多。通常的做法是使初始学习率比用于从头开始训练(Training from scratch)的初始学习率小10倍。
-
如果数据集数量过少,我们进来只训练最后一层,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。
这是因为前几个图层捕捉了与我们的新问题相关的通用特征,如曲线和边。我们希望保持这些权重不变。相反,我们会让网络专注于学习后续深层中特定于数据集的特征。
三、baseline1代码详解
环境准备
# 相关库的下载与安装
!pip install pandas openpyxl语文数据处理(数据处理)
这里我们使用pandas加载xlsx中的数据,这里面我们使用全局匹配,将训练集中的中文点与左侧括号匹配为英文类型。
# coding~
import pandas as pd
import re
# 读取Excel文件
df = pd.read_excel('训练集-语文.xlsx')
df = df.replace('.', '.', regex=True)
df = df.replace('(', '(', regex=True)
# 读取第二行(即第三行)“选项”列的内容
# 可以使用loc获取某行的数据
second_row_option_content = df.loc[2, '选项']
# 显示第二行“选项”列的内容
print(second_row_option_content)语文数据处理(抽取问题)
这里主要是为了抽取题目及答案,并且过滤简答题。大家可以阅读详细的注释理解问题抽取的函数如何工作。
def chinese_multiple_choice_questions(questions_with_answers):
# 输入的题目文本
text = questions_with_answers
question_pattern = re.compile(r'\d+\..*?(?=\d+\.|$)', re.DOTALL)
# 这一行作用是匹配一个以数字开头、后面跟着一个点字符的字符串,
#。直到遇到下一个数字和点字符或字符串结束。
choice_pattern = re.compile(r'([A-D])\s*(.*?)(?=[A-D]|$|\n)', re.DOTALL)
# 这一行作用是匹配一个以字母[A到D]开头、后面跟着一个点字符的字符串,
#直到遇到下一个[A到D]或字符串结束。
# 找到所有问题
questions = question_pattern.findall(text)
# 初始化选择题和简答题列表
multiple_choice_questions = []
short_answer_questions = []
# 处理每个问题
for id,question in enumerate(questions):
# 这里取到的question,如果是选择题会带着选择题的选项。
# 检查是否是选择题 因为选择题内有ABCD这样的选项
if re.search(r'[A-D]', question):
# 如果有选项,提取出选项的内容
choices = choice_pattern.findall(question)
# 这里提取了题目的内容,因为每个题目都会有一个打分的(X分)这样的标记
# 以左括号为目标,截取选择题选项中的内容
question_text = re.split(r'\n', question.split('(')[0])[0]
pattern_question = re.compile(r'(\d+)\.(.*)')
# 这里清洗了选择题的编号,重新用循环中的id进行编号。
# 如果不做这一步可以发现给定的数据中编号是乱序的。
matches_question = str(id+1)+'.'+ pattern_question.findall(question_text)[0][1] # 取出问题后重排序
# print(str(id+1)+'.'+matches_question)
# 这里我们实现声明好了存储的列表
# 将每个问题和选项以字典的形式存入方便我们处理
multiple_choice_questions.append({
'question': matches_question,
'choices': choices
})
else:
# 大家可以想想这里怎么用?
short_answer_questions.append(question.strip())
# 最后我们返回抽取后的选择题字典列表
return multiple_choice_questions语文数据处理(抽取问题的结果)
这里我们抽取刚才我们拿到的选择题的答案部分。
def chinese_multiple_choice_answers(questions_with_answers):
# 首先清洗输入字段,因为答案字段中的格式不统一,清洗后便于统一处理。
# 这里删除了所有的换行和空格
questions_with_answers = questions_with_answers.replace(" ", "").replace("\n", "")
# print(questions_with_answers)
# 使用正则表达式匹配答案
# 这里我们主要使用第一个匹配 一个数字+点+字母ABCD之间一个
choice_pattern = re.compile(r'(\d+)\.([A-Z]+)')
# 下面这句匹配的是简答题答案~ 目前可以忽略
short_pattern = re.compile(r'(\d+)\.([^A-Z]+)')
# 找到所有匹配的答案
choice_matches = choice_pattern.findall(questions_with_answers)
short_matches = short_pattern.findall(questions_with_answers)
# 将匹配结果转换为字典
choice_answers = {int(index): answer for index, answer in choice_matches}
short_answers = {int(index): answer for index, answer in short_matches}
# 按序号重新排序
sorted_choice_answers = sorted(choice_answers.items())
sorted_short_answers = sorted(short_answers.items())
answers = []
# 输出结果
# print("选择题答案:")
for id in range(len(sorted_choice_answers)):
# 这里我们也将重新编号号的答案作为返回,返回的是一个列表,方便与问题字典列表匹配~
answers.append(f"{id+1}. {sorted_choice_answers[id][1]}")
return answers语文prompt设计
我们使用要求+阅读材料组成prompt,作为input部分。之前在数据处理那里提及过,代码的具体实现过程如下:
def get_prompt_cn(text):
prompt = f'''
你是⼀个⾼考选择题出题专家,你出的题有⼀定深度,你将根据阅读文本,出4道单项选择题,包含题目选项,以及对应的答案,注意:不⽤给出原文,每道题由1个问题和4个选项组成,仅存在1个正确答案,请严格按照要求执行。 阅读文本主要是中文,你出的题目需要满足以下要点,紧扣文章内容且题干和答案为中文:
### 回答要求
(1)理解文中重要概念的含义
(2)理解文中重要句子的含意
(3)分析论点、论据和论证方法
### 阅读文本
{text}
'''
return prompt 中文数据处理主函数
将input与output部分进行组合,按照列表序号一一对应。
def process_cn(df):
# 定义好返回列表
res_input = []
res_output = []
for id in range(len(df)):
# 逐个遍历每行的选项、答案、阅读文本的内容
data_options = df.loc[id, '选项']
data_answers = df.loc[id,'答案']
data_prompt = df.loc[id,'阅读文本']
# 处理选项部分,抽取出选择题题目及选项
data_options = chinese_multiple_choice_questions(data_options)
# 处理答案部分,抽取出选择题答案
data_answers = chinese_multiple_choice_answers(data_answers)
# 抽取阅读材料组合成input内容
data_prompt = get_prompt_cn(data_prompt)
# print(data_options)
# print(data_answers)
# 做数据验证,因为训练数据格式不能确定每组数据都能被正常处理(会有一部分处理失败)
# 我们验证一下两个列表的长度 如果相同代表数据处理正确
if(len(data_answers)==len(data_options)):
# 定义output的数据字符串
res = ''
# 处理选择题目中的每个数据,逐个拼入到output字符串
for id_,question in enumerate(data_options):
# 首先放入题目
res += f'''
{question['question']}?
'''+'\n'
# 然后找到选择题的每个选项,进行choices列表循环
for choise in question['choices']:
# 逐个将选项拼接到字符串
res = res+ choise[0] + choise[1]+ '\n'
# 最后将答案拼接到每个选择题的最后
# 以 答案:题号.选项的格式
res = res + '答案:' + str(data_answers[id_].split('.')[-1]) + '\n'
# 最后将处理得到的input、output数据存入到列表
res_output.append(res)
res_input.append(data_prompt)
# break
return res_input,res_output
英文数据处理(数据处理)
这里我们使用pandas加载xlsx中的数据,这里面我们使用全局匹配。
# coding~
import pandas as pd
# 读取Excel文件
df = pd.read_excel('训练集-英语.xlsx')
# 英文数据处理中有一部分ocr识别的题目,这种题目中看上去是字母A,但是实际为俄文的字母,,
# 所以开始使用全局匹配做了清洗……
df = df.replace('.', '.', regex=True).replace('А.', 'A.', regex=True).replace('В.', 'B.', regex=True).replace('С.', 'C.', regex=True).replace('D.', 'D.', regex=True)
# df = df.replace('(', '(', regex=True)
# 读取第二行(即第三行)“选项”列的内容
second_row_option_content = df.loc[0, '选项']
# 显示第二行“选项”列的内容
print(second_row_option_content)英文数据处理(抽取问题)
英文问题数据相对标准,但是也有不少小问题。比如ABCD的顺序可能是ACBD。我们看看这些如何解决。
import re
# 示例文本
text = second_row_option_content
def get_questions(text):
# 数据清洗,将所有换行改为两个空格方便统一处理
text = text.replace('\n', ' ')+' '
# print(text)
# 正则表达式模式
# 通过匹配以数字开头然后带一个点,为题干
# 然后抽取选项A 以A开头 后面带一个点 最后以两个空格结尾
# 为什么是两个空格?部分数据换行时为换行符,我们已经换成了两个空格,有些是以多个空格分割,我们默认为两个空格
# 接着匹配B C D选项内容
# 最后有一个
pattern = re.compile(r'(\d+\..*?)(A\..*?\s{2})([B-D]\..*?\s{2})([B-D]\..*?\s{2})(D\..*?\s{2})', re.DOTALL)
# 查找所有匹配项
matches = pattern.findall(text)
# 存储结果的字典列表
questions_dict_list = []
# 打印结果
for match in matches:
question, option1, option2, option3, option4 = match
pattern_question = re.compile(r'(\d+)\.(.*)')
# 第一个为选择题的题目 提前存到question_text
question_text = pattern_question.findall(question.strip())[0][1]
# 提取选项字母和内容
options = {option1[0]: option1, option2[0]: option2, option3[0]: option3, option4[0]: option4}
question_dict = {
'question': question_text,
# 这一步就是防止ACBD这种乱序,我们进行重新匹配,将可能是ACBD的数据以首字母按位置排好号
'options': {
'A': options.get('A', '').strip(),
'B': options.get('B', '').strip(),
'C': options.get('C', '').strip(),
'D': options.get('D', '').strip()
}
}
questions_dict_list.append(question_dict)
# 最后获得
return questions_dict_list
# 调用函数并打印结果
questions = get_questions(text)
for q in questions:
print(q)英文数据处理(抽取问题的结果)
# 首先做数据清洗,将空格、换行符及点都删除
def remove_whitespace_and_newlines(input_string):
# 使用str.replace()方法删除空格和换行符
result = input_string.replace(" ", "").replace("\n", "").replace(".", "")
return resultimport re
# 示例文本
text = """
32. B. The underlying logic of the effect. 33.D. estimates were not fully independent.
34.C. The discussion process. 35.D. Approving.
"""
def get_answers(text):
text = remove_whitespace_and_newlines(text)
# 正则表达式模式
# 这里是一个数字加一个A-D的大写字母表示为答案区域,因为有些答案中有解释,这样的匹配规则可以尽可能匹配到答案
pattern = re.compile(r'(\d)\s*([A-D])')
# 查找所有匹配项
matches = pattern.findall(text)
res = []
# 打印结果
for match in matches:
number_dot, first_letter = match
res.append(first_letter)
return res英文prompt设计
我们使用要求+阅读材料组成prompt,作为input部分。之前在数据处理那里提及过,代码的具体实现过程如下:
def get_prompt_en(text):
prompt = f'''
你是⼀个⾼考选择题出题专家,你出的题有⼀定深度,你将根据阅读文本,出4道单项选择题,包含题目选项,以及对应的答案,注意:不⽤给出原文,每道题由1个问题和4个选项组成,仅存在1个正确答案,请严格按照要求执行。
The reading text is mainly in English. The questions and answers you raised need to be completed in English for at least the following points:
### 回答要求
(1)Understanding the main idea of the main idea.
(2)Understand the specific information in the text.
(3)infering the meaning of words and phrases from the context
### 阅读文本
{text}
'''
return prompt 英文数据处理主函数
def process_en(df):
res_input = []
res_output = []
for id in range(len(df)):
data_options = df.loc[id, '选项']
data_answers = df.loc[id,'答案']
data_prompt = df.loc[id,'阅读文本']
data_options = get_questions(data_options)
data_answers = get_answers(data_answers)
data_prompt = get_prompt_en(data_prompt)
# print(data_options)
# print(data_answers)
if(len(data_answers)==len(data_options)):
res = ''
for id,question in enumerate(data_options):
res += f'''
{id+1}.{question['question']}
{question['options']['A']}
{question['options']['B']}
{question['options']['C']}
{question['options']['D']}
answer:{data_answers[id]}
'''+'\n'
res_output.append(res)
res_input.append(data_prompt)
return res_input,res_output
# break
数据合并
因为微调需要150条数据,数据处理后得到有效数据为102,从中文抽取30条,英文抽取20条组成152条数据作为微调数据。
# 将两个列表转换为DataFrame
df_new = pd.DataFrame({'input': cn_input+cn_input[:30]+en_input+en_input[:20], 'output': cn_output+cn_output[:30]+en_output+en_output[:20]})Task3:数据增强与评分
如果我们想要尽可能地提分,可以根据下面我所给出的链接作为参考进行提分。
一、数据增强
数据增强思路:数据增强为了补充一些数据,一方面是在先前生成的结果上做一些优化,一方面可以再生成一些补充数据以作增强。
(一)使用大模型完成答案生成
训练数据:|| 阅读文本 || 选项 || 答案 ||
如果咱们使用大模型,如何直接生成我们需要的QA数据呢?这里我们使用大模型完成,想必聪明的大家已经想到了这个方法,不过不知道怎么入手。这里就从prompt到实践介绍核心代码,大家自行再baseline1上修改即可。
prompt设计
给出主要需求:你是一个高考语文阅读题出题专家,请阅读材料,需要参考参考内容 按照要求将题目、选项、答案对其补充完整。
接着给出参考材料:###阅读材料 {reading}
接着给出具体要求:
###要求
1.需要将序号对应的题目与答案做匹配。
2.匹配后格式按照问题、ABCD四个选项顺序、答案的结构组合,按照参考内容格式输出。
3.如果选择题目数量不够四个请根据阅读材料及出题思路再生成题目,总题目达到四个。
4.题目中不能出现任何不合理的词汇、语法错误。
5.如果有简答题目与答案请忽略这部分内容,只处理选择题目。
接着给出参考内容:{cankao_content}
cankao_content = '''
1. 以下哪个选项是“具身认知”的定义?
A. 认知在功能上的独立性、离身性构成了两种理论的基础。
B. 认知在很大程度上是依赖于身体的。
C. 认知的本质就是计算。
D. 认知和心智根本就不存在。
答案:B
2. 以下哪个实验支持了“具身认知”的假设?
A. 一个关于耳机舒适度的测试。
B. 一个关于眼睛疲劳程度的测试。
C. 一个关于人类感知能力的实验。
D. 一个关于人类记忆力的实验。
答案:A
3. 以下哪个选项是“离身认知”的教育观的特点?
A. 教育仅仅是心智能力的培养和训练,思维、记忆和学习等心智过程同身体无关。
B. 教育观认为身体仅仅是一个“容器”,是一个把心智带到课堂的“载体”。
C. 教育观认为知识经验的获得在很大程度上依赖于我们身体的体验性。
D. 教育观认为知识经验的获得在很大程度上依赖于我们大脑的记忆能力。
答案:A
4. 以下哪个选项是“具身认知”带来的教育理念和学习理念的变化?
A. 更强调全身心投入的主动体验式学习。
B. 更注重操作性的体验课堂,在教学过程中将学生的身体充分调动起来,这在教授抽象的概念知识时尤为重要。
C. 更强调教师的教学方法和学生的学习方法。
D. 更注重教师的教学技巧和学生的学习技巧。
答案:A'''
【这里的参考内容即为我们的标准参考答案,这里给出了语文部分,如果大家想对英语部分修改直接拿输出样例文件中的英语部分即可。为什么我们要给参考内容呢,其实我们使用了one shot learining策略,具体内容请学习这篇论文One-Shot Learning as Instruction Data Prospector for Large Language Models】
最后给出题目和答案
def get_adddata_prompt_zero(reading, cankao_content, question, answer):
prompt = f'''你是一个高考英语阅读题出题专家,请阅读材料,需要参考参考内容 按照要求将题目、选项、答案对其补充完整。
###阅读材料
{reading}
###要求
1.需要将序号对应的题目与答案做匹配。
2.匹配后格式按照问题、ABCD四个选项顺序、答案的结构组合,按照参考内容格式输出。
3.如果选择题目数量不够四个请根据阅读材料及出题思路再生成题目,总题目达到四个。
4.题目中不能出现任何不合理的词汇、语法错误。
5.如果有简答题目与答案请忽略这部分内容,只处理选择题目。
###参考内容
{cankao_content}
###题目
{question}
###答案
{answer}
'''
return prompt(二)使用大模型增强数据
增强思路1.补全四个选项及答案
由于之前生成的数据中我们处理的数据不一定满足四个选项与答案,这里我们需要将答案补全,我们看看如何使用大模型补全。这里我们的增强prompt如下,这里的题目与答案是我们baseline1生产的output部分内容。这里我们主要要求大模型生成四个答案,这是我们的核心目标。
def get_adddata_prompt_rebuild(reading, cankao_content, output):
prompt = f'''你是一个高考英语阅读题出题专家,请阅读材料,需要参考参考内容 按照要求将题目、选项、答案对其补充完整。
###阅读材料
{reading}
###要求
1.如果选择题目不足四个需要根据参考内容出选择题补充。
2.补充内容格式按照问题、ABCD四个选项顺序、答案的结构组合,按照参考内容格式输出。
3.如果选择题目数量不够四个请根据阅读材料及出题思路再生成题目,总题目达到四个,如果够四个则不做多余补充。
4.题目中不能出现任何不合理的词汇、语法错误。
###参考内容
{cankao_content}
###题目与答案
{output}
'''
return prompt这里#####之后是大模型补充的内容。
1.'下列对本文相关内容和艺术特色的分析鉴赏,不正确的一项是?
A.小龙与“我"父亲毛羽的电话,既介绍了本文故事发生的起因,表现了书匠老董
B.“老董穿了一件卡其布的工作服,肩膀上挎了个军挎”,“踩着辆二八型的自行
C.小松鼠跳到地上,“像人- -样站起了身,前爪紧紧擒着一颗橡子”,渲染了此处的
D.“仪器做了电子配比都没辙”,老董却用传统工艺修复了稀见典籍,说明在科技发
答案: C
########### 2. 老董为什么要自己染制蓝色的绢?
A. 因为市面上找不到合适的蓝色绢。
B. 因为老董对现代染色技术不满意。
C. 因为老董想要证明传统技艺的可行性。
D. 因为老董需要修复一本珍贵的古籍。
答案:D
3. 根据文章内容,老董为什么每年都会去东郊的城墙处?
A. 为了寻找橡碗用于制作染料。
B. 为了纪念已故的老馆长。
C. 为了享受大自然的美景。
D. 为了教授“我”关于自然的知诀。
答案:B
4. 以下哪个选项不是老董使用传统技艺修复书籍的原因?
A. 传统技艺可以更精确地匹配原书皮的颜色和质地。
B. 老董想通过这种方式保存并传承传统的修书技艺。
C. 老董认为只有传统方法才能达到他想要的修复效果。
D. 老董希望通过现代科技手段来提高修复效率。
答案:D增强思路2.拿到思路1的数据后做答案扩展
这里需要自行尝试,阅读题目不变,然后再生成四组QA。这样生成几次就可以把数据集扩充几倍!这个思路如果不新增阅读材料的情况下很有效果。
二、结果评分
(一)大模型评分
大模型目前可以弥补一些人类评分的痛点,提升评分效率。掌握这个方法对日后完成评价类任务有很大帮助。评分技术不光用在agent设计,还可以优化推荐算法等等,以此提升算法质量。
1. 人类评分的痛点
主观性和不一致:不同评分者可能因个人标准和偏见导致评分不一致。
时间和资源密集:手动评分耗时且需要大量人力资源,限制了评分任务的可扩展性和效率。
疲劳和认知限制:评分者易受疲劳和认知限制影响,影响评分质量和一致性。
缺乏细致反馈:难以提供针对绩效特定方面的详细反馈。
2. AI在评分方面的优势
一致性和标准化:LLMs通过训练和微调,确保评分的一致性。
效率和可扩展性:AI系统能快速处理大量数据,提高评分效率。
客观性和公正性:减少人类主观性和偏见,促进公平。
细致且可操作的反馈:提供针对绩效各方面的详细反馈。
(二)星火大模型评分
定义评分思路,赋分情况以及打分标准
首先满足题目数量及含有对应答案。
接着对给出的答案匹配情况做打分设定。
对选项和文章匹配程度做打分设定。
对选项和高考考试要求做打分设定。
对输出情况做设定。
满足上面条件后输出结果。
judgement = f'''
你是一个高考阅读题目出题专家,你需要根据下面要求结合阅读文章对题目及答案这样的出题情况进行打分,根据要求一步一步打分,得到有效分数后你将得到100万元的报酬,给出最终得分情况,以“总分:XX分”的形式返回。
### 阅读文章
{reading}
### 题目及答案
{QA}
### 要求
1. 判断给出的题目及答案,题目是否为四道,如果不满足四道,少一道题扣10分,如果每个题目没有答案,少一个答案扣5分。
1. 给出题目选项与答案匹配正确度给分,通过阅读文章每分析道题目正确,则给5分,如果错误给0分。四道题满分20分。
2. 给出题目与选项在阅读文章中的匹配程度给分,每道题目符合阅读文章且选择答案复合题目并可用通过阅读文章分析得到,完全符合给3分,完全不符合给0分。四道题满分12分。
3. 给出题目与选项是否符合高考难度,每道题目与答案是否符合高考的难度,完全符合给3分,完全不符合给0分。四道题满分12分。
4. 给出最终得分情况,对上面三个分数进行求和得到总分,以“总分:XX分”的形式返回,三个问题满分共44分。
'''
score = call_sparkai(judgement)
score使用正则表达式简单处理就能得到数字分数
import re
text = score.replace(' ', '')
# 使用正则表达式匹配阅读文本后的内容
match = re.search(r'总分:(\d+)分', text)
if match:
content = match.group(1)
print(int(content))
else:
print("未找到匹配的内容")附件:基础补充
python知识
对baseline1的代码仍然充满困惑,那么推荐你从学习python开始,打好基础再来尝试也不迟,
你可以学习《聪明办法学python第二版》 打扎实深度学习相关的python基础知识。
Pandas学习推荐

Datawhale有一个开源教程项目叫 Joyful Pandas,出版图书
豆瓣链接:pandas数据处理与分析 (豆瓣)
文字版教程链接:Home — Joyful Pandas 1.0 documentation
视频教程链接:Pandas中文教程《Joyful-Pandas》视频讲解_哔哩哔哩_bilibili
机器学习材料推荐
Datawhale翻译了李宏毅老师的机器学习教程,可在处学习查看。
Datawhale
LoRA
一种高效微调方法,深入了解其原理可参见博客:[知乎|深入浅出Lora] 。
arxiv.org/pdf/2106.09685
huggingface.co
大语言模型知识
大模型白盒子构建指南:从原理出发、以“白盒”为导向、围绕大模型全链路的“手搓”大模型指南
https://github.com/datawhalechina/tiny-universe
大模型基础: 一文了解大模型基础知识
GitHub - datawhalechina/so-large-lm: 大模型基础: 一文了解大模型基础知识
如果你想从0手写代码,构建大语言模型,本项目很适合你。
吴恩达系列课程
GitHub - datawhalechina/llm-cookbook: 面向开发者的 LLM 入门教程,吴恩达大模型系列课程中文版
大模型评分
https://huggingface.co/learn/cookbook/en/llm_judge