文章目录
原论文研究背景与研究意义概述
这篇论文由中国科学技术大学团队于2023年发表在TKDE期刊上,主要研究领域是基于用户-用户和用户-事件社会关系的推荐生成。由于这些社会关系可以轻松地用图结构数据来表示,因此图神经网络在这一领域具有很大的发展潜力。然而,现有的基于图的算法在处理数据时往往忽略了用户或事件的偏好偏移量。作者给出的一个示例说明了这种偏移量的重要性:挑剔的用户给出的低评分并不一定意味着他们对产品的态度是消极的,因为这些用户通常会给出低评分,这可能会导致图结构数据分析产生误差。现有的方法通常将这种偏差作为标量融入模型训练中,但作者认为这种做法不足以捕捉所有相关信息。此外,作者指出,用户之间的社会联系也应被考虑在内,因为具有相似偏好的用户往往会对彼此产生更大的影响。基于此,作者提出了一种新的算法来解决这些问题。
论文所提出算法的主要贡献
- 本文所涉及的所有资源的获取方式:https://www.aspiringcode.com/content?id=17176636216843&uid=e2e9019d4bf84a00b601b958967f9d54

这篇文章的主要贡献包括: 首先,作者将评价偏移量处理为向量,并将其融入到用户和事件的表征学习中。具体做法是计算用户与其他用户的评价差异向量,从而获得每个用户的评价偏移。具体做法是,他们对原始图进行去中心化处理,然后从中学习到用户和事件的表征。去中心化的图是基于原始图中的统计信息生成的。
接着,作者提出了一种用户-用户之间社会关系的建模方式,并将其融入到预测规则中,以提高推荐表现。
然后,基于去中心化图,他们提出了一种基于图神经网络(GNN)的社会推荐协同过滤模型。
最后,作者在两个数据集上验证了所提出算法的有效性,证明了其在处理用户偏好偏移量和社会关系建模方面的优势。
原论文中采用了大量的数学公式来表示算法过程,这里笔者认为实际上读起来有点费力,所以本文主要从感性的角度来对这篇论文进行讲解,尽量少用公式而是用文字描述来给大家建立一个感性的理解。
GDSRec算法原理与流程
问题定义
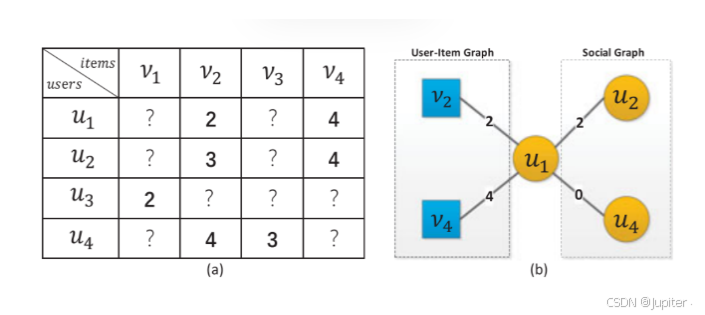

原文采用的建图方式是将用户和事件作为节点,用户-事件之间的连线权重为关系系数Tij,用于衡量两个用户的相似度。

关系系数的计算方式可以看作是设定一个阈值,当两个用户对同一个事件的评分差距在阈值之内时,就将相似度加一,累加起来就是两个用户的相似度,这里称为关系系数。而用户-事件连线的权重为用户对事件的评分。然而,作者指出,直接使用这种原始图会带来一些不足,也就是无法准确反映真正的用户偏好。这是因为用户对事件的评分可能受到不同用户的打分标准的影响,从而导致误解用户的真实偏好。因此,作者对图结构进行了去中心化处理,以更好地捕捉用户的真实偏好。
去中心化图(decentralized graph)
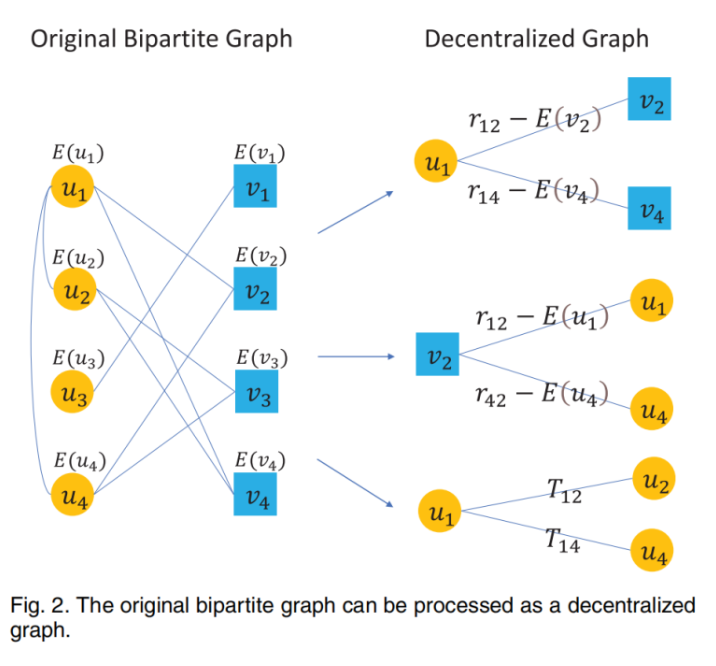
去中心化图有三种不同的边:用户-事件、事件-用户、用户-用户。对于每个用户-事件交互的边,用原始权重减去所有权重的平均值得到新的权重,而用户-用户连线的权重保持不变。通过这种方式,作者将统计信息融入到图中。接下来,作者针对这种去中心化图进行了对用户、事件、社会联系三种方向的建模,从而计算出三种潜在因素偏移量。依据这些偏移量,可以计算出最终用户ui和事件vj的最终偏好评分,即:
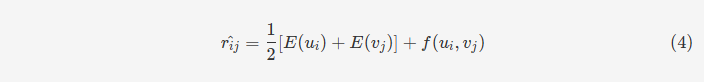
所提出方法(三种并行建模)
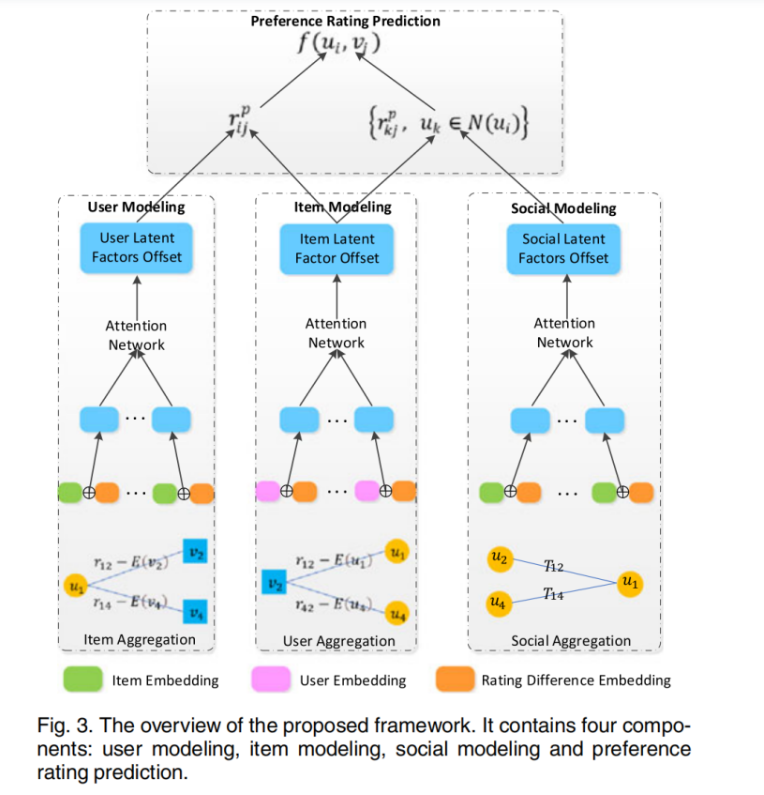
用户建模(user modelling)
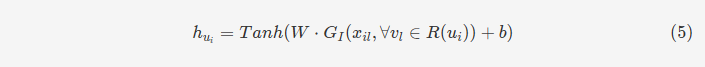
然后我们具体介绍一下作者提出的三种建模方式。我们以用户建模(user modeling)为例,期望得到的输出是潜在因素偏移量hui。整个流程可以用上面的公式表示,我们可以逐步拆分这个过程。
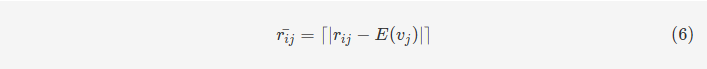
首先,需要提到的是,在这个过程中使用的用户-事件交互权重都是进行取整后的。原文指出,使用小数进行embedding不太方便,但同时也提到一些量化方法可以解决这个问题,他们将这部分留作未来工作。前面提到,这篇文章的一大贡献是将评价偏移量处理为向量。
具体做法是将事件𝑣𝑙vl与
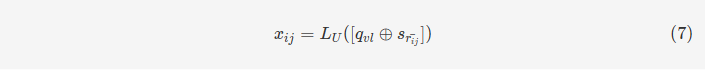
用户-事件交互的权重进行embedding后的表征进行拼接,然后通过一个多层感知机进行处理,从而融入到学习过程中。𝑞,𝑠q,s分别是事件𝑢u和社会关联𝑟r的表征,𝐿𝑈LU是多层感知机,这种方法可以将该向量融入用户表征的学习过程中

同时,作者指出,一个用户和相关联事件之间的每个关联对用户潜在因素的影响贡献是不同的。因此,他们采用了注意力机制来捕捉用户偏好中的差异。公式8中𝑥x前面乘的系数实际上是注意力权重。需要注意的是,在输入注意力网络时,他们将前面的评价偏移向量与用户的embedding向量进行了拼接,然后通过一个两层神经网络进行处理。通过这一流程,就可以得到用户的潜在因素偏移量hui。
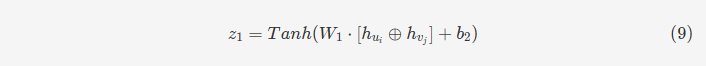
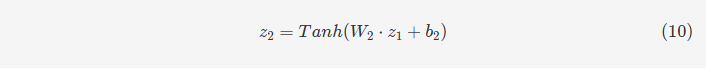
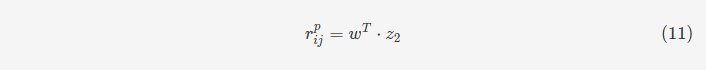
事件建模(item modeling)和社会关系建模(social modeling)的处理方式与用户建模类似。三种建模处理后,我们可以得到三种潜在因素偏移量。基于此,偏好评分可以通过三层神经网络获得,用公式9,10,11表示。这个偏好评分可以理解为包括用户自己的意见和对其社会关联用户评级的参考。对于用户ui的社会关联用户,我们可以用相同的方式得到他们的偏好评分,从而得到方程f的返回值,计算方式如公式12。
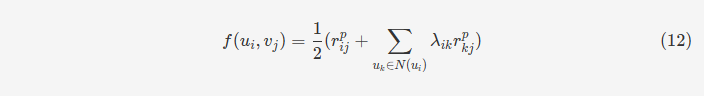
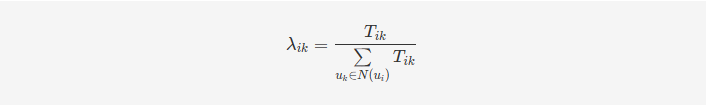
最终,我们回到前面公式4就可以计算出用户ui和事件vj之间的最终评分。以这种方式就可以实现对用户更全面偏好信息的捕获,以及考虑到有着更强社会关联的用户对用户ui的影响。
模版代码讲解
main.py顶层文件:用于集成模与函数功能
main.py文件在这里仍然是起到一个调用模型和所有函数进行数据输入、处理、训练、结果输出的功能,值得注意的是这里原文作者使用了config参数定义的方式,让整个工程看起来更加简洁、标准
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
import pickle
import torch
from torch.utils.data import DataLoader
from utils import collate_fn
from model.GDSRec_model import GDSRec_Engine
config = {
'model': 'GDSRec',
'dataset': 'Ciao', # Ciao/Epinions
'optimizer': 'adam',
'l2_regularization': 0.01,
'embed_size': 64,
'batch_size': 128,
'layers': [256,128,128,64,64],
'epoch': 20,
'lr': 0.0005, # 0.01, 0.001, 0.0001
'lr_dc': 0.1, # learning rate decay
'lr_dc_step': 100, # the number steps for decay
'test':False,
'model_dir': 'checkpoints/{}_{}_best_checkpoint.model'
}
print(config)
here = os.path.dirname(os.path.abspath(__file__))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
config['device'] = device
workdir = 'C:/Users/meicr/Desktop/GDSRec_rank/data/'
with open(workdir + config['dataset'] + '/' + config['model'] + '_dataset.pkl', 'rb') as f:
train_dataset, evaluate_dataset, test_dataset, user_count, item_count = pickle.loads(f.read())
config['num_users'] = user_count
config['num_items'] = item_count
config['num_rates'] = 5
if config['test'] is False:
engine = GDSRec_Engine(config)
train_loader = DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True, collate_fn=collate_fn)
evaluate_loader = DataLoader(evaluate_dataset, batch_size=config['batch_size'], shuffle=False,
collate_fn=collate_fn)
index_sum = []
for epoch in range(config['epoch']):
print('Epoch {} starts !'.format(epoch))
engine.train_an_epoch(train_loader, epoch)
recall, ndcg = engine.evaluate(evaluate_loader, epoch)
if epoch == 0:
pre_sum = recall + ndcg
index_sum.append(0)
else:
if recall + ndcg < pre_sum:
index_sum.append(1)
else:
pre_sum = recall + ndcg
index_sum.append(0)
if sum(index_sum[-10:]) == 10:
break
if epoch == 0:
best_sum = recall + ndcg
engine.save()
elif recall + ndcg > best_sum:
best_sum = recall + ndcg
engine.save()
else:
engine = GDSRec_Engine(config)
print('Load checkpoint and testing...')
engine.resume()
test_loader = DataLoader(test_dataset, batch_size=config['batch_size'], shuffle=True, collate_fn=collate_fn)
recall, ndcg = engine.evaluate(test_loader, epoch_id=0)
preprocess.py:对输入数据进行预处理符合模型输入要求
这里preprocess.py文件的作用是对我们输入的数据进行了处理和分析得到模型可以处理的对象,主要包括格式转换、用户相似度计算之类的功能
"""
@author: Jiajia Chan
@date: 20 June, 2020
"""
import random
import argparse
import pickle
import pandas as pd
from scipy.io import loadmat
from rating_data import SingleGenerator
from trust_data import SocialGenerator
random.seed(1234)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', default='Ciao', help='dataset name: Ciao/Epinions')
parser.add_argument('--test_prop', default=0.2, help='the proportion of data used for test')
args = parser.parse_args()
workdir = 'data/'
click_f = loadmat(workdir + args.dataset + '/rating.mat')['rating']
trust_f = loadmat(workdir + args.dataset + '/trustnetwork.mat')['trustnetwork']
click_dt = pd.DataFrame(click_f)
trust_dt = pd.DataFrame(trust_f, columns=['userID', 'freID'])
click_dt = click_dt[[0, 1, 3]]
click_dt.dropna(inplace=True)
click_dt.drop_duplicates(inplace=True)
click_dt.columns = ['userID', 'itemID', 'rating']
trust_dt.dropna(inplace=True)
trust_dt.drop_duplicates(inplace=True)
single_generator = SingleGenerator(ratings=click_dt, prob=args.test_prop)
social_generator = SocialGenerator(singlegenerator=single_generator, trust=trust_dt)
GDSRec_dataset = social_generator.instance_GDSRec_dataset()
general_dataset = single_generator.instance_general_dataset()
with open(workdir + args.dataset +'/' + 'GDSRec' + '_dataset.pkl', 'wb') as f:
str1 = pickle.dumps(GDSRec_dataset)
f.write(str1)
f.close()
model.py:GDSRec模型实现
这个文件里面存放的就是所提出方法和相关算法的所有实现,原理和流程就如上述介绍所示
from torch import nn
from torch.nn import init
import torch
import numpy as np
class _MultiLayerPercep(nn.Module):
def __init__(self, input_dim, output_dim):
super(_MultiLayerPercep, self).__init__()
self.mlp = nn.Sequential(
nn.Linear(input_dim, input_dim // 2, bias=True),
nn.ReLU(),
nn.Linear(input_dim // 2, output_dim, bias=True),
)
def forward(self, x):
return self.mlp(x)
class _MultiLayerPercep_tanh(nn.Module):
def __init__(self, input_dim, output_dim):
super(_MultiLayerPercep_tanh, self).__init__()
self.mlp = nn.Sequential(
nn.Linear(input_dim, input_dim // 2, bias=True),
nn.Tanh(),
nn.Linear(input_dim // 2, output_dim, bias=True),
)
def forward(self, x):
return self.mlp(x)
class _Aggregation(nn.Module):
def __init__(self, input_dim, output_dim):
super(_Aggregation, self).__init__()
self.aggre = nn.Sequential(
nn.Linear(input_dim, output_dim, bias=True),
nn.Tanh(),
)
def forward(self, x):
return self.aggre(x)
class _UserModel(nn.Module):
''' User modeling to learn user latent factors.
User modeling leverages two types aggregation: item aggregation and social aggregation
'''
def __init__(self, emb_dim, user_emb, item_emb, rate_emb):
super(_UserModel, self).__init__()
self.user_emb = user_emb
self.item_emb = item_emb
self.rate_emb = rate_emb
self.emb_dim = emb_dim
self.g_v = _MultiLayerPercep_tanh(2 * self.emb_dim, self.emb_dim)
self.user_items_att = _MultiLayerPercep(2 * self.emb_dim, 1)
self.aggre_items = _Aggregation(self.emb_dim, self.emb_dim)
self.combine_mlp = nn.Sequential(
nn.Linear(2 * self.emb_dim, self.emb_dim, bias=True),
nn.Tanh(),
nn.Linear(self.emb_dim, self.emb_dim, bias=True),
nn.Tanh(),
nn.Linear(self.emb_dim, self.emb_dim, bias=True),
nn.Tanh(),
)
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# used for preventing zero div error when calculating softmax score
self.eps = 1e-10
def forward(self, uids, u_item_pad):
# item aggregation
q_a = self.item_emb(u_item_pad[:, :, 0])
mask_u = torch.where(u_item_pad[:, :, 0] > 0, torch.tensor([1.], device=self.device),
torch.tensor([0.], device=self.device))
u_item_er = self.rate_emb(u_item_pad[:, :, 1])
x_ia = self.g_v(torch.cat([q_a, u_item_er], dim=2).view(-1, 2 * self.emb_dim)).view(
q_a.size())
## calculate attention scores in item aggregation
p_i = mask_u.unsqueeze(2).expand_as(x_ia) * self.user_emb(uids).unsqueeze(1).expand_as(
x_ia)
alpha = self.user_items_att(torch.cat([x_ia, p_i], dim=2).view(-1, 2 * self.emb_dim)).view(
mask_u.size()) # B x maxi_len
alpha = torch.exp(alpha) * mask_u
alpha = alpha / (torch.sum(alpha, 1).unsqueeze(1).expand_as(alpha) + self.eps)
h_iI = self.aggre_items(torch.sum(alpha.unsqueeze(2).expand_as(x_ia) * x_ia, 1)) # B x emb_dim
return h_iI
class _ItemModel(nn.Module):
'''Item modeling to learn item latent factors.
'''
def __init__(self, emb_dim, user_emb, item_emb, rate_emb):
super(_ItemModel, self).__init__()
self.emb_dim = emb_dim
self.user_emb = user_emb
self.item_emb = item_emb
self.rate_emb = rate_emb
self.g_u = _MultiLayerPercep_tanh(2 * self.emb_dim, self.emb_dim)
self.item_users_att = _MultiLayerPercep(2 * self.emb_dim, 1)
self.aggre_users = _Aggregation(self.emb_dim, self.emb_dim)
self.combine_mlp = nn.Sequential(
nn.Linear(2 * self.emb_dim, self.emb_dim, bias=True),
nn.Tanh(),
nn.Linear(self.emb_dim, self.emb_dim, bias=True),
nn.Tanh(),
nn.Linear(self.emb_dim, self.emb_dim, bias=True),
nn.Tanh(),
)
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.eps = 1e-10
def forward(self, iids, i_user_pad):
# user aggregation
p_t = self.user_emb(i_user_pad[:, :, 0])
mask_i = torch.where(i_user_pad[:, :, 0] > 0, torch.tensor([1.], device=self.device),
torch.tensor([0.], device=self.device))
i_user_er = self.rate_emb(i_user_pad[:, :, 1])
f_jt = self.g_u(torch.cat([p_t, i_user_er], dim=2).view(-1, 2 * self.emb_dim)).view(p_t.size())
# calculate attention scores in user aggregation
q_j = mask_i.unsqueeze(2).expand_as(f_jt) * self.item_emb(iids).unsqueeze(1).expand_as(f_jt)
miu = self.item_users_att(torch.cat([f_jt, q_j], dim=2).view(-1, 2 * self.emb_dim)).view(mask_i.size())
miu = torch.exp(miu) * mask_i
miu = miu / (torch.sum(miu, 1).unsqueeze(1).expand_as(miu) + self.eps)
z_jU = self.aggre_users(torch.sum(miu.unsqueeze(2).expand_as(f_jt) * f_jt, 1))
return z_jU
class _SocialModel(nn.Module):
'''
socialmodel to learn the rating for specific user exploiting social related users
'''
def __init__(self, emb_dim, user_emb, item_emb, rate_emb, sim_emb):
super(_SocialModel, self).__init__()
self.emb_dim = emb_dim
self.user_emb = user_emb
self.item_emb = item_emb
self.rate_emb = rate_emb
self.sim_emb = sim_emb
self.g_v = _MultiLayerPercep_tanh(2 * self.emb_dim, self.emb_dim)
self.user_items_att = _MultiLayerPercep(2 * self.emb_dim, 1)
self.user_users_att = _MultiLayerPercep(2 * self.emb_dim, 1)
self.aggre_items = _Aggregation(self.emb_dim, self.emb_dim)
self.combine_mlp = nn.Sequential(
nn.Linear(2 * self.emb_dim, self.emb_dim, bias=True),
nn.Tanh(),
nn.Linear(self.emb_dim, self.emb_dim, bias=True),
nn.Tanh(),
nn.Linear(self.emb_dim, self.emb_dim, bias=True),
nn.Tanh(),
)
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.eps = 1e-10
def forward(self, u_user_pad, u_user_item_pad):
q_a_s = self.item_emb(u_user_item_pad[:, :, :, 0])
mask_s = torch.where(u_user_item_pad[:, :, :, 0] > 0, torch.tensor([1.], device=self.device),
torch.tensor([0.], device=self.device))
u_user_item_er = self.rate_emb(u_user_item_pad[:, :, :, 1])
x_ia_s = self.g_v(torch.cat([q_a_s, u_user_item_er], dim=3).view(-1, 2 * self.emb_dim)).view(
q_a_s.size())
p_i_s = mask_s.unsqueeze(3).expand_as(x_ia_s) * self.user_emb(u_user_pad[:, :, 0]).unsqueeze(2).expand_as(
x_ia_s)
alpha_s = self.user_items_att(torch.cat([x_ia_s, p_i_s], dim=3).view(-1, 2 * self.emb_dim)).view(
mask_s.size())
alpha_s = torch.exp(alpha_s) * mask_s
alpha_s = alpha_s / (torch.sum(alpha_s, 2).unsqueeze(2).expand_as(alpha_s) + self.eps)
h_oI_temp = torch.sum(alpha_s.unsqueeze(3).expand_as(x_ia_s) * x_ia_s, 2)
h_oI = self.aggre_items(h_oI_temp.view(-1, self.emb_dim)).view(h_oI_temp.size())
return h_oI
class GDSRec(nn.Module):
'''
Args:
number_users: the number of users in the dataset.
number_items: the number of items in the dataset.
num_rate_levels: the number of rate levels in the dataset.
emb_dim: the dimension of user and item embedding (default = 64).
'''
def __init__(self, num_users, num_items, num_rate_levels, emb_dim=64):
super(GDSRec, self).__init__()
self.num_users = num_users
self.num_items = num_items
self.num_rate_levels = num_rate_levels
self.emb_dim = emb_dim
self.user_emb = nn.Embedding(self.num_users, self.emb_dim, padding_idx=0)
self.item_emb = nn.Embedding(self.num_items, self.emb_dim, padding_idx=0)
self.rate_emb = nn.Embedding(self.num_rate_levels, self.emb_dim, padding_idx=0)
self.sim_dim = nn.Embedding(self.num_items, self.emb_dim, padding_idx=0)
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.eps = 1e-10
self.user_model = _UserModel(self.emb_dim, self.user_emb, self.item_emb, self.rate_emb)
self.item_model = _ItemModel(self.emb_dim, self.user_emb, self.item_emb, self.rate_emb)
self.social_model = _SocialModel(self.emb_dim, self.user_emb, self.item_emb, self.rate_emb, self.sim_dim)
self.rate_pred = nn.Sequential(
nn.Linear(2 * self.emb_dim, self.emb_dim, bias=True),
nn.Tanh(),
nn.Linear(self.emb_dim, self.emb_dim, bias=True),
nn.Tanh(),
nn.Linear(self.emb_dim, 1),
)
def forward(self, uids, iids, u_itemdiv_pad, u_avgs, u_user_pad, u_user_item_pad, i_user_pad, i_avgs):
'''
Args:
uids: the user id sequences.
iids: the item id sequences.
u_itemdiv_pad: the padded user-item-div graph
u_item_pad: the padded user-item graph.
u_avgs: the avg rating of user
u_user_pad: the padded user-user graph.
u_user_item_pad: the padded user-user-item graph.
i_user_pad: the padded item-user graph.
i_avgs: the avg rating of item
Shapes:
uids: (B).
iids: (B).
u_item_pad: (B, ItemSeqMaxLen, 2).
u_avgs: (B)
u_user_pad: (B, UserSeqMaxLen).
u_user_item_pad: (B, UserSeqMaxLen, truncate_len, 2).
i_user_pad: (B, UserSeqMaxLen, 2).
i_avgs: (B)
Returns:
the predicted rate scores of the user to the item.
'''
h_i = self.user_model(uids, u_itemdiv_pad)
z_j = self.item_model(iids, i_user_pad)
y_i = self.social_model(u_user_pad, u_user_item_pad)
mask = u_user_pad[:, :, 1].unsqueeze(2).float()
# make prediction
r_ij_1 = self.rate_pred(torch.cat([h_i, z_j], dim=1))
r_ij_2 = torch.sum(self.rate_pred(torch.cat([y_i, z_j.unsqueeze(1).expand_as(y_i)], dim=2)) * mask, dim=1)\
/(torch.sum(mask, dim=1) + self.eps)
r_ij = 0.5 *(r_ij_1 + r_ij_2) + 0.5*(u_avgs.unsqueeze(1) + i_avgs.unsqueeze(1))
return r_ij
本地部署方法
我们在github官方链接上只能找到一个数据集Ciao(原论文是在Ciao和Epinions上都进行了实验),我们需要将数据集整理成上述格式,这里可以打开看一下。整理的格式如右图所示,第一列是学生id, 第二列是问题id,第三列是无关变量原文代码中并没有用到,第四列是rating,trustnetwork.mat文件中保存的是学生与学生之间的关系网络。因此我们在进行本地私有数据集训练时也需要将数据处理成对应的格式

该篇论文作者在github上公布了源代码,但笔者下载下来实际运行了之后发现完全按照模版代码运行仍然会出现一些问题。研究之后发现可能是原作者在编写代码后改动了数据集目录格式,导致一些设定的环境路径参数错误。如果我们想要跑通代码或者在本地运行自己的数据集进行实验,还需要对相应的参数进行修改,修改后的代码我已经放在本文附件中了,并且在附件的压缩包内新增了一个Readme文件来提示大家如何修改数据集路径为自己的私有数据集
- 本文所涉及的所有资源的获取方式:https://www.aspiringcode.com/content?id=17176636216843&uid=e2e9019d4bf84a00b601b958967f9d54