1.数据倾斜的原理和影响
1.1 原理
数据倾斜就是数据的分布严重不均,造成一部分数据很多,一部分数据很少的局面。数据分布理论上都是倾斜的,符合“二八原理”:例如80%的财富集中在20%的人手中、80%的用户只使用20%的功能、20%的用户贡献了80%的访问量。 数据倾斜的现象,如下图所示。
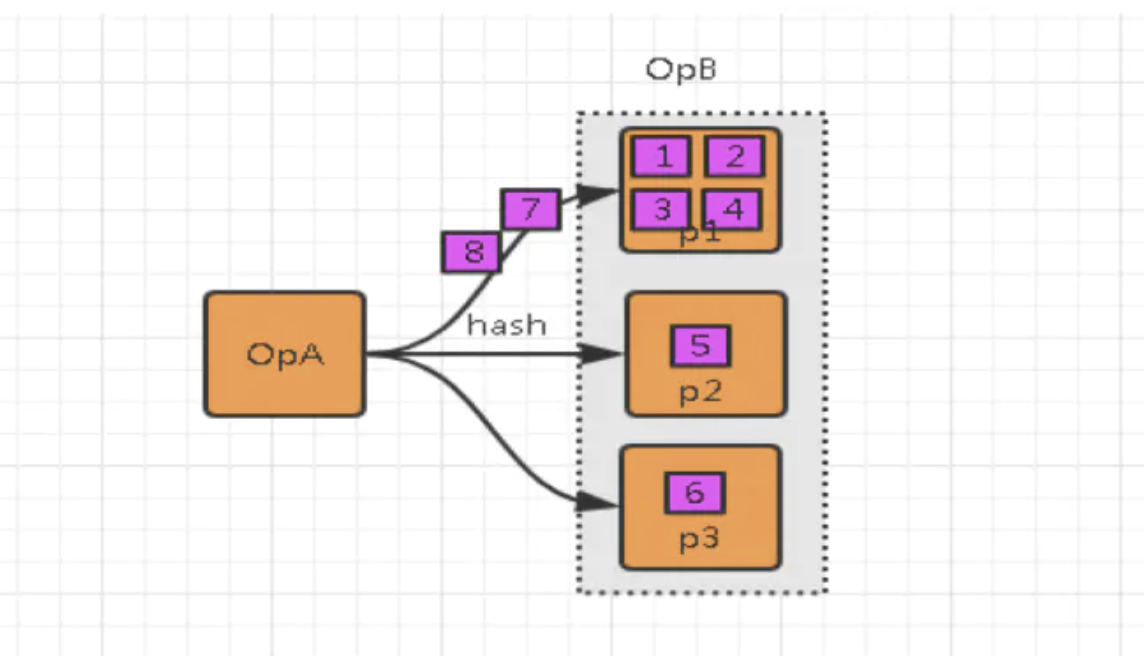
1.2 影响
(1)单点问题
数据集中在某些分区上(Subtask),导致数据严重不平衡。
(2)GC 频繁
过多的数据集中在某些 JVM(TaskManager),使得JVM 的内存资源短缺,导致频繁 GC。
(3)吞吐下降、延迟增大
数据单点和频繁 GC 导致吞吐下降、延迟增大。
(4)系统崩溃
严重情况下,过长的 GC 导致 TaskManager 失联,系统崩溃。

数据倾斜的影响
2.Flink 如何定位数据倾斜?
步骤1:定位反压
定位反压有2种方式:Flink Web UI 自带的反压监控(直接方式)、Flink Task Metrics(间接方式)。通过监控反压的信息,可以获取到数据处理瓶颈的 Subtask。
参考:【Flink 精选】如何分析及处理反压?
步骤2:确定数据倾斜
Flink Web UI 自带Subtask 接收和发送的数据量。当 Subtasks 之间处理的数据量有较大的差距,则该 Subtask 出现数据倾斜。如下图所示,红框内的 Subtask 出现数据热点。

Web UI 数据量监控
3.Flink 如何处理常见数据倾斜?

优化前
场景一:数据源 source 消费不均匀
解决思路:通过调整并发度,解决数据源消费不均匀或者数据源反压的情况。例如kafka数据源,可以调整 KafkaSource 的并发度解决消费不均匀。调整并发度的原则:KafkaSource 并发度与 kafka 分区数是一样的,或者 kafka 分区数是KafkaSource 并发度的整数倍。
场景二:key 分布不均匀的无统计场景
说明:key 分布不均匀的无统计场景,例如上游数据分布不均匀,使用keyBy来打散数据。
解决思路: 通过添加随机前缀,打散 key 的分布,使得数据不会集中在几个 Subtask。

优化后
具体措施:
① 在原来分区 key/uid 的基础上,加上随机的前缀或者后缀。
② 使用数据到达的顺序seq,作为分区的key。
场景三:key 分布不均匀的统计场景
解决思路:聚合统计前,先进行预聚合,例如两阶段聚合(加盐局部聚合+去盐全局聚合)。
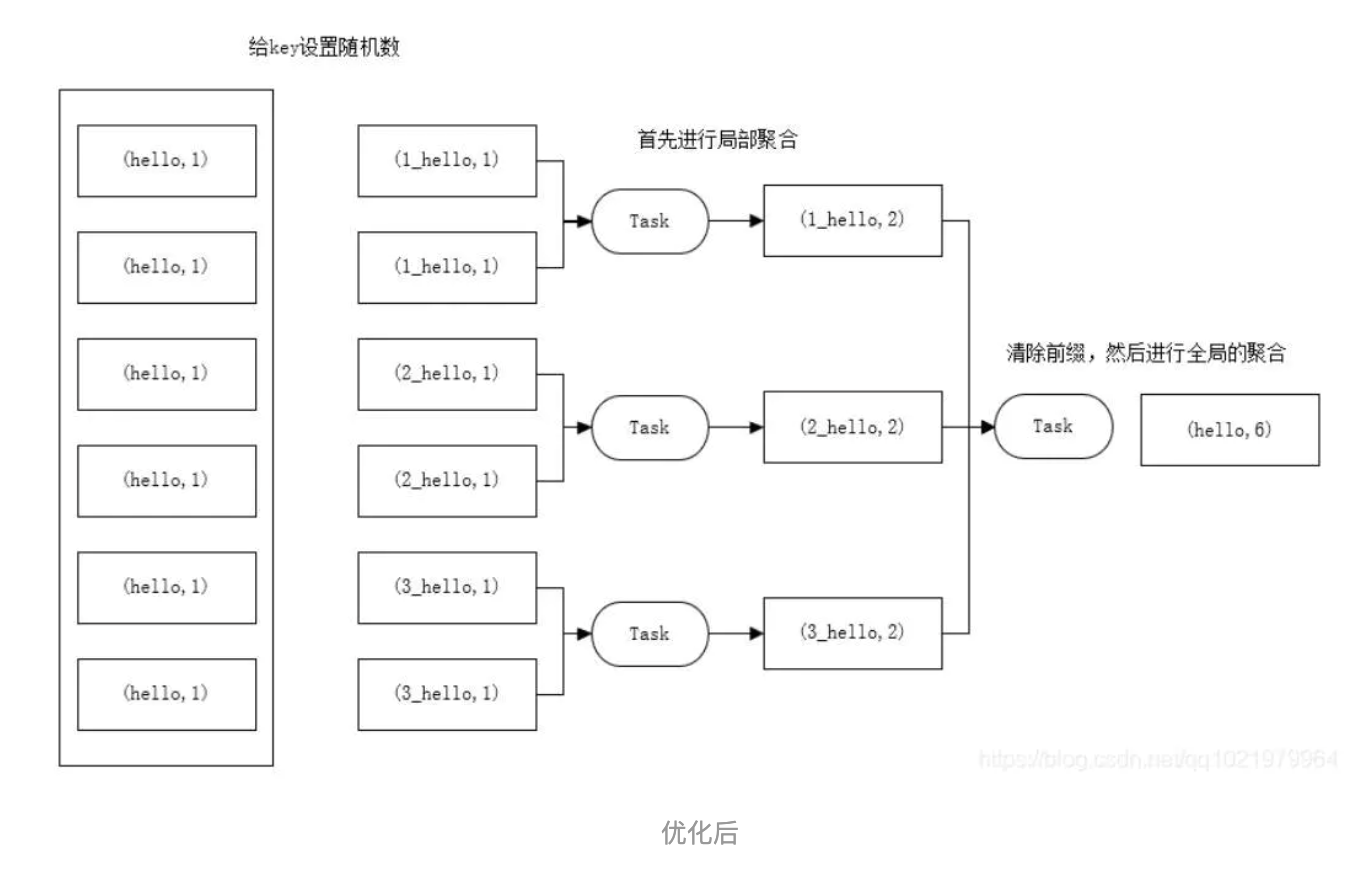
优化后
两阶段聚合的具体措施:
① 预聚合:加盐局部聚合,在原来的 key 上加随机的前缀或者后缀。
② 聚合:去盐全局聚合,删除预聚合添加的前缀或者后缀,然后进行聚合统计。
参考: https://www.jianshu.com/p/4ae20202e06d
方法1:调整并行度
方法2:加随机前缀或后缀
方法3:两阶段聚合(加盐局部聚合+去盐全局聚合)