阶段总结——基于深度学习的三叶青图像识别
文章目录
一、计算机视觉图像分类系统设计
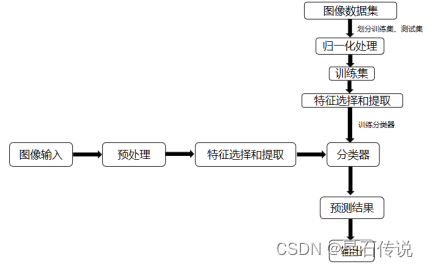
如图1所示,图像分类系统从输入图像开始,经过预处理,进行特征选择和提取,之后经过分类器进行分类,得出最后的预测结果,并输出。在获得训练样本之前,所有的图片都进行了预处理、归一化处理为固定分辨率的图片输入至网络中,然后对其进行特征选择和提取,进行训练得到分类器,从而达到预测目标的任务[1]。
图 1 图像分类系统图
二、训练模型
2.1. 构建数据集
考虑到最终是根据三叶青块根、叶片图片进行训练,并且是根据省份产地进行分类。故本实验的类别目前共有六种:云南省、广西省、未知、浙江省、贵州省、陕西省。其中未知类别的图片来自于从网络上爬取和本地相册中的图片;至于另外五种类别的图片则是自己构建的。获得图片数据集后,则是统一数据集图片的格式、大小。前面共采集了9214张图片,之后便是将数据集按照比例6:2:2分割为训练集、验证集、测试集。各类别图像数量的统计表格如表1所示。
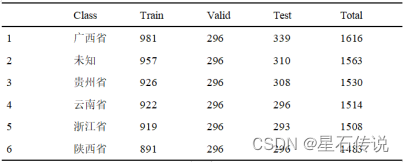
表 1 各类别图像数量的统计
2.2. 网络模型选择
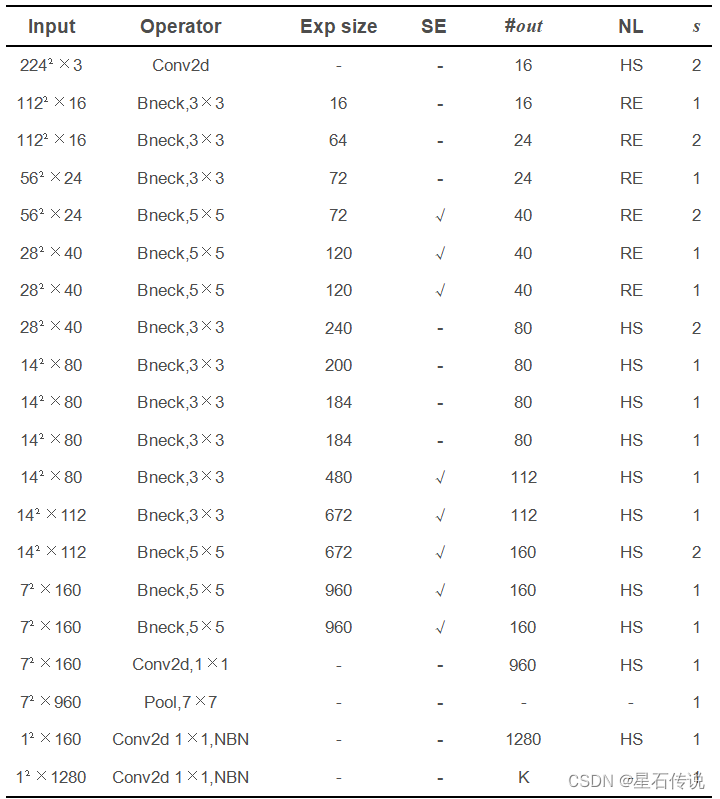
由于考虑到常规的CNN,推理需要很大的计算量,很难应用在移动端等资源受限的场景中。只有通过复杂的裁剪,量化才有可能勉强部署到移动端。本实验采用了MobileNetV3-Large模型,是谷歌提出的轻量化网络架构,引入MobileNetV1的深度可分离卷积、MobileNetV2的具有线性瓶颈的倒残差结构、加入神经网络架构搜索(NAS)和h-swish激活函数,并引入SE通道注意力机制,性能和速度都表现优异[2]。其网络模型结构如图2所示
图 2 MobileNetV3_Large模型架构
2.3. 图像数据增强与调参
在训练之前,先对训练集进行数据增强,通过随即裁剪、缩放图像、随机更改亮度、对比度和饱和度等方法对数据进行增强。之后使用迁移学习方法来训练模型,对MobileNetV3-Large模型进行微调,即改变模型的分类头,使输出大小与数据集的类别数相匹配,为6,故要将模型的最后一层1²×1280改为1²×6。
最后使用随机梯度下降(SGD)优化器,用于更新网络中的参数以最小化损失函数,使用网格搜索函数来搜索最佳超参数组合。
2.4. 部署模型到web端
使用flask+bootstrap+jquery+mysql搭建三叶青在线识别网站;最后使用nginx+gunicorn部署网站在腾讯云上,并配置SSL证书,方便后面微信小程序调用此网站的后端代码。
该网站实现了登录注册、在线识别、图片瀑布流展示、用户数据展示以及其它等功能。
2.5. 开发图像识别小程序
使用uniapp+微信开发者工具+flask后端开发三叶青图像识别微信小程序。此微信小程序主要分为三叶青图像识别功能、图片瀑布流展示、历史记录、登录/注册功能等。
三、实验结果
3.1. 模型训练
其中设置样本批量大小batch_size为128;类别数量num_classes为6;学习率lr为1e-4;权重衰减wd为1e-4;动量momentum为0.9;学习率衰减的周期lr_period为2;学习率衰减的比例lr_decay为1。训练时设置的训练总轮数num_epochs为300;在Epoch197时验证集的准确度最高。运行结果如图3
图 3 模型训练结果
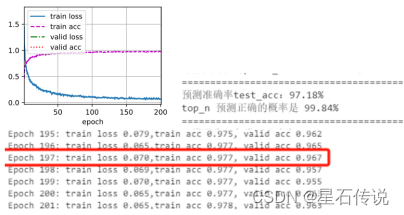
最后,训练集的损失为0.070,训练集的准确度为0.977,验证集的准确度为0.967,测试集上的准确度为0.9718。其中top_n预测正确的概率为99.84%(即在预测得到的置信度排前三的类别中有正确类别的概率)。除了上述的损失、准确率和top-n准确率,还有许多其他的模型精度评估指标,例如分类报告、各类别准确率(如表2所示)、混淆矩阵、PR曲线、AUC-ROC曲线(如图4所示)。
表 2 分类报告与各类别准确率
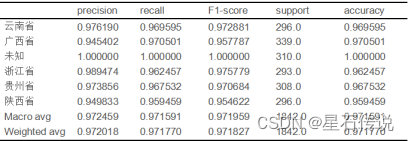
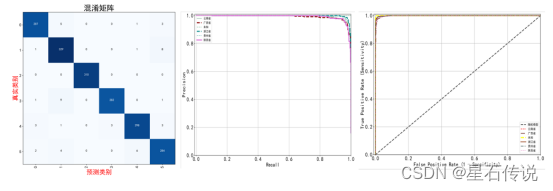
图 4 混淆矩阵、PR曲线、ROC曲线
3.2. 模型部署
利用pytorch框架训练得到的.pth模型文件转换为onnx文件,并使用ONNX
Runtime来执行模型推理。在此基础上,我们开发了一个三叶青块根图像产地鉴别的在线识别网站(https://www.whtuu.cn),以及一个微信小程序(三叶识青),使得用户可以在各种设备和平台上方便地使用我们的模型进行预测。
四、讨论
本研究的图像分类任务采用了MobileNetV3-Large模型,通过对模型的微调训练、测试、验证工作,对于采集的多产地的三叶青块根图像完成了图像分类,达到了很高的识别准确率,并且识别速度快,模型部署在web端和移动端,操作方便。
但是在此次研究中也发现了一些问题,(1)若想要提高识别率,数据集的构建至关重要,提供的训练集一定要大量、各类别的样本量也要平均,差异不能过大;(2)要采集不同背景下的三叶青块根照片,这样虽然会让识别率降低,但是在实际应用中却是十分必要的;(3)图像数据增强和调参过程很重要,对于模型的精度的提升很大;(4)本研究初步计划同时根据三叶青的叶片照片进行产地分类。然而,由于时间限制,这部分功能未能实现。尽管如此,在web端和移动端仍保留了叶片分类的接口,以便于未来研究和开发。
五、参考文献:
[1] 刘加峰,高子啸,段元民,等. 基于深度学习的中药材饮片图像识别[J].北京生物医学工程,2021,40( 4) : 605-608.
[2] A. Howard et al., “Searching for MobileNetV3,” 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019, pp. 1314-1324, doi: 10.1109/ICCV.2019.00140.