1. 单应用缓存:cache
1.1 cache算子
cache算子能够缓存中间结果数据到各个executor中,后续的任务如果需要这部分数据就可以直接使用避免大量的重复执行和运算。

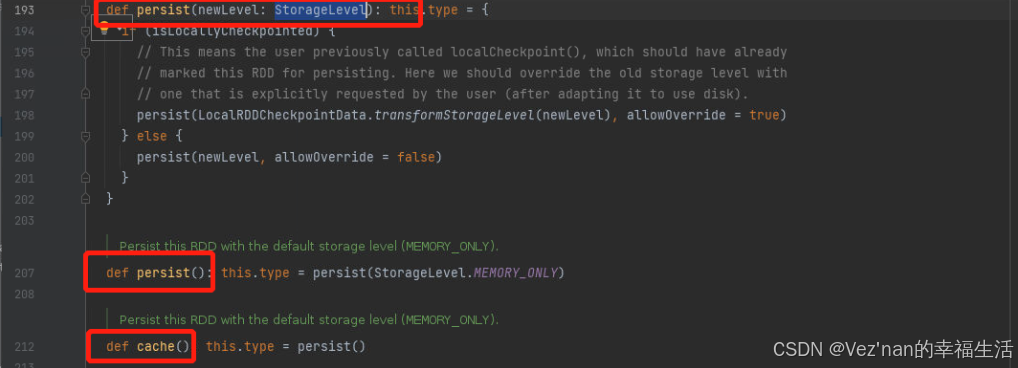
rdd 存储级别中默认使用的算子cache算子,cache算子的底层调用的是persist算子,persist算子底层使用的是persist(storageLevel)默认存储级别是memoryOnly。
scala> sc.textFile("/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res101: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[78] at reduceByKey at <console>:25
scala> res101.cache()
res102: res101.type = ShuffledRDD[78] at reduceByKey at <console>:25
scala> res102.count
res103: Long = 3
scala> res102.first
res104: (String, Int) = (tom,8)
scala> res102.collect
res105: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8))cache算子是转换类算子,不会触发执行运算,count算子触发运算,后续的算子的使用就可以直接从内存中取出值了。
1.2 cache算子的存储位置
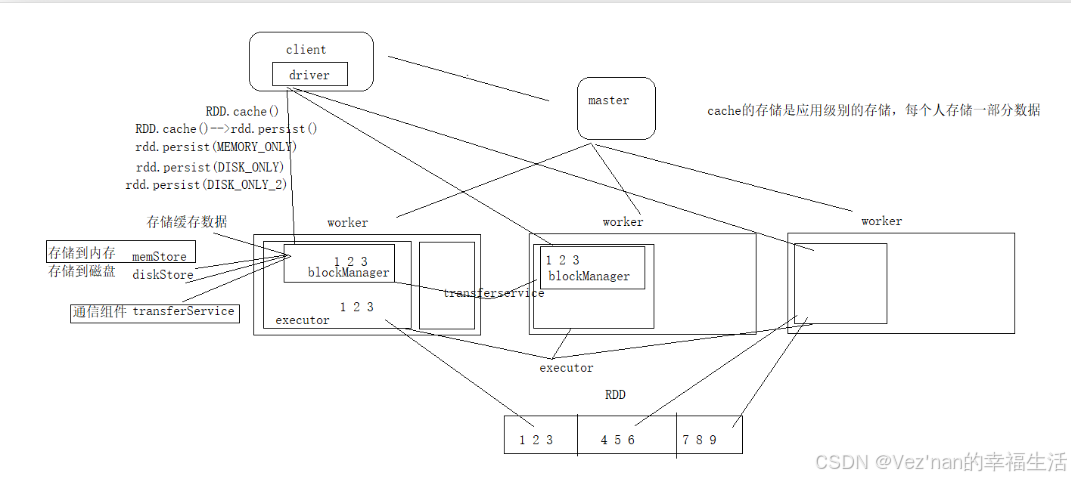
每个executor中都存在一个blockManager的组件,这个组件主要是executor缓存数据用的,并且是job级别.
每个blockManager中存在三个组成部分 memstore diskStore transferService
组件memstore 用于缓存存储级别有内存的数据。
组件diskStore 用于缓存存储级别有磁盘的数据。
组件transferService用于存储级别为磁盘的且副本大于1的数据,用于将数据从该executor传输到另一个executor进行存储。
1.3 rdd的缓存级别
rdd的存储级别选项
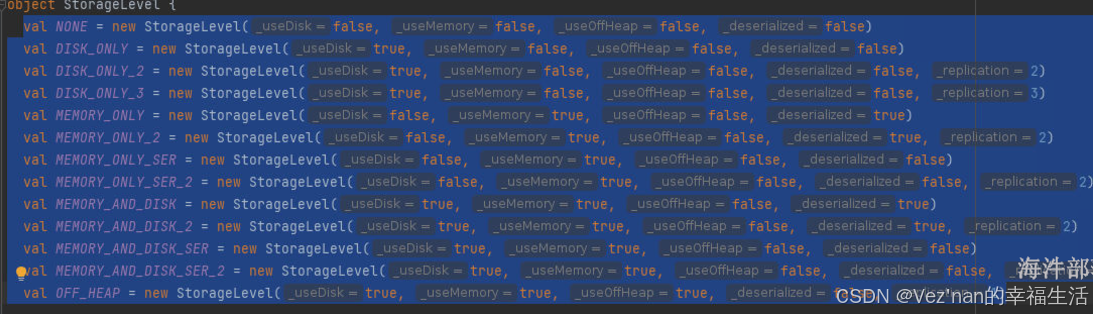
存储级别分为12种。
分别根据构造器的参数不同。
none 不存储。
DISK_ONLY 仅磁盘方式,必然序列化 _deserialized = false。
DISK_ONLY_2 存储磁盘并且备份数量2。
MEMORY_ONLY 仅内存_deserialized = true 不序列化,executor就是一个jvm,使用的内存是jvm的内存,可以直接存储对象数据。
MEMORY_ONLY_SER 仅内存并且是序列化的方式 _deserialized = true,将存储的jvm中的对象进行二进制byte[],存储起来,以内存的方式,序列化完毕的数据更能够减少存储空间。
MEMORY_AND_DISK 先以内存为主,然后再使用磁盘,存储空间不够不会报错,会存储一部分数据,可以不序列化,不序列化指的时候内存的部分。
MEMORY_AND_DISK_SER 存储的时候将存储的内容先序列化然后存储。
OFF_HEAP 堆外内存,一个机器中除了jvm以外的内存,又叫做直接内存。
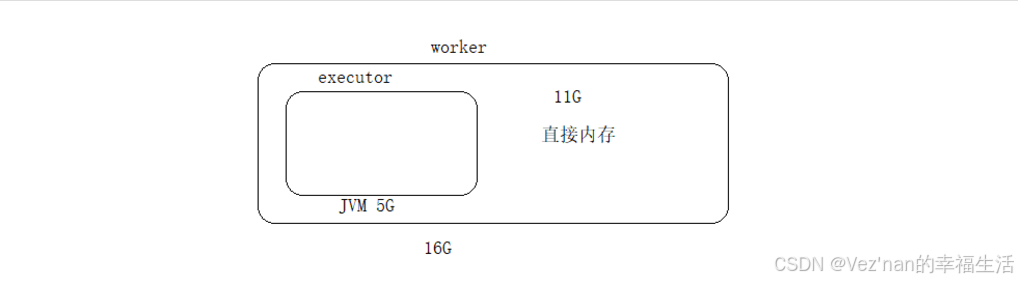
首先存储到直接内存中,可以使得jvm的内存使用量减少,效率更高,但是比较危险,jvm中存在GC,可以清空垃圾,但是如果使用直接内存的话,垃圾多了我们可以删除,但是如果应用程序异常退出,这个时候内存是没有人可以管理的。
1.4 缓存的使用
scala> sc.textFile("/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res106: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[83] at reduceByKey at <console>:25
scala> res106.cache()
res107: res106.type = ShuffledRDD[83] at reduceByKey at <console>:25
scala> res107.count
res108: Long = 3
scala> res107.collect
res109: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8))res107已经被缓存了,下次进行执行的时候可以从这个缓存数据中读取

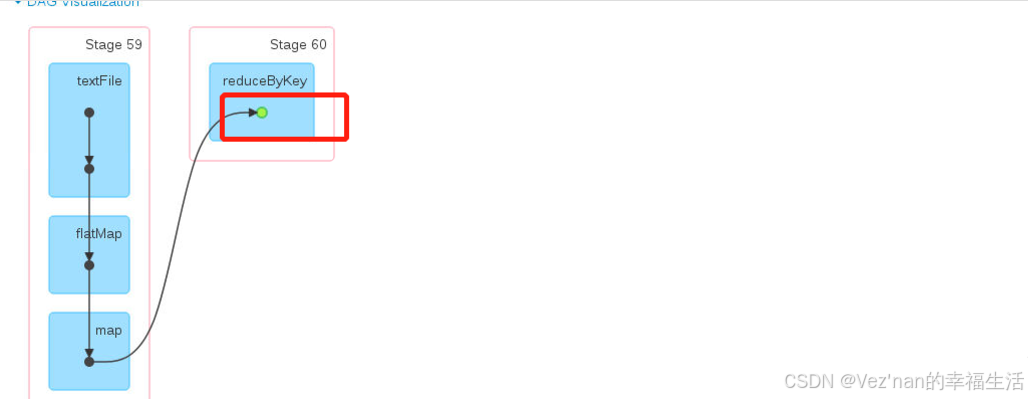
绿色的RDD代表已经存储完毕

前面的应用计算已经跳过。
查看缓存数据。

缓存的位置,可以点进去查看

去重缓存
rdd.unpersist()
缓存是应用级别的,spark-shell它启动完毕的所有job都可以使用,关闭应用缓存也会失效
2. checkpoint
cache是应用级别的,spark-submit或者是spark-shell提交完毕都会启动一套executor。
在这个应用中执行的所有job任务都可以共享cache的缓存数据,当然是单个应用的。
多个应用共享一份数据怎么进行实现?
checkpoint就是实现多应用共享数据的一种方式,原理就是一个应用将数据存储到外部,一个大家都能访问的位置,然后就可以直接使用了,使用的存储是hdfs,saveAsTextFile存储起来。
存储的hdfs的文件

使用的时候和cache一样


我们发现数据是直接从ckpt中读取的,前面的计算逻辑都被跳过了。
首先就是数据共享,现在数据已经存储到hdfs中了,我们直接从hdfs中拿,实现多应用共享。
cache数据缓存完毕,下次使用的时候逻辑是不截断的,ckpt是截断的,前面什么都没有了。
checkpoint是存储数据到hdfs的共享盘中,cache是存储到内存的缓存中,所以ckpt需要另外触发一次计算才可以。


一次性调用collect,但是spark会执行两个任务
第一次的任务是collect,第二次的任务是为了存储数据到外部
所以为了优化任务的执行
rdd.cache()
rdd.checkpoint()
cache和checkpoint连用,这样的话,第二次执行的时候就可以直接从缓存中读取数据了,不需要进行第二次计算。