朴素贝叶斯(Naive Bayesian)是一种基于贝叶斯定理和特征条件独立假设的分类方法,它是基于概率论的一种有监督学习方法,被广泛应用于自然语言处理,并在机器学习领域中占据了非常重要的地位。在之前做过的一个项目中,就用到了朴素贝叶斯分类器,将它应用于情感词的分析处理,并取得了不错的效果,本文我们就来介绍一下朴素贝叶斯分类的理论基础和它的实际使用。
在学习朴素贝叶斯分类以及正式开始情感词分析之前,我们首先需要了解一下贝叶斯定理的数学基础。
贝叶斯定理
贝叶斯定理是关于随机事件A和B的条件概率的定理,公式如下:
P ( A ∣ B ) = P ( A ) P ( B ∣ A ) P ( B ) P(A|B)=\frac{P(A)P(B|A)}{P(B)} P(A∣B)=P(B)P(A)P(B∣A)
在上面的公式中,每一项表示的意义如下:
P(A):先验概率(prior probability),是在没有任何条件限制下事件A发生的概率,也叫基础概率,是对A事件概率的一个主观判断P(A|B):在B发生的情况下A发生的可能性,也被称为A的后验概率(posterior probability)P(B|A):似然性,也被称为条件似然(conditional likelihood)P(B):不论A是否发生,在所有情况下B发生的概率,它被称为整体似然或归一化常量(normalizing constant)
按照上面的解释,贝叶斯定理可以表述为:
后验概率 = 先验概率 * 似然性 / 归一化常量
通俗的来说,可以理解为当我们不能确定某一个事件发生的概率时,可以依靠与该事件本质属性相关的事件发生的概率去推测该事件发生的概率。用数学语言来表达就是,支持某项属性的事件发生得愈多,则该事件发生的的可能性就愈大,这个推理过程也被叫做贝叶斯推理。
在查阅的一些文档中,P(B|A)/P(B) 可以被称为可能性函数,它作为一个调整因子,表示新信息B对事件A带来的调整,作用是将先验概率(主观判断)调整到更接近真实的概率。那么,贝叶斯定理也可以理解为:
新信息出现后A的概率 = A的先验概率 * 新信息带来的调整
举一个例子,方便大家更直观的理解这一过程。假设统计了一段时间内天气和气温对于运动情况的影响,如下所示:
天气 气温 运动
晴天 非常高 游泳
晴天 高 足球
阴天 中 钓鱼
阴天 中 游泳
晴天 低 游泳
阴天 低 钓鱼
现在请计算在晴天,气温适中的情况下,去游泳的概率是多少?根据贝叶斯定理,计算过程如下:
P(游泳|晴天,中温)=P(晴天,中温|游泳)*P(游泳)/P(晴天,中温)
=P(晴天|游泳)*P(中温|游泳)*P(游泳)/[P(晴天)*P(中温)]
=2/3 * 1/3 *1/2 / (1/2 *1/3 )
=2/3
最终得出去游泳的概率时2/3,上面就是基于贝叶斯定理,根据给定的特征,计算事件发生概率大小的过程。
贝叶斯分析的思路对于由证据的积累来推测一个事物的发生的概率具有重大作用,当我们要预测一个事物,首先会根据已有的经验和知识推断一个先验概率,然后在新证据不断的积累的情况下调整这个概率。整个通过累积证据来得到一个事件发生概率的过程我们称为贝叶斯分析。这样,贝叶斯底层的思想就可以概括为,如果能够掌握一个事情的全部信息,就能够计算出它的一个客观概率。
另外,在贝叶斯公式的基础上进行变形,可以得到下面的公式:
P
(
B
i
∣
A
)
=
P
(
B
i
)
P
(
A
∣
B
i
)
∑
j
=
1
n
P
(
B
j
)
P
(
A
∣
B
j
)
P(B_i|A)= \frac {P(B_i)P(A|B_i)} {\sum_{j=1}^n P(B_j)P(A|B_j)}
P(Bi∣A)=∑j=1nP(Bj)P(A∣Bj)P(Bi)P(A∣Bi)
其中B1,B2,…,Bj是一个完备事件组,上面的公式可以表示在事件A已经发生的条件下,寻找导致A发生的各种“原因”的Bi的概率。
朴素贝叶斯
在学习朴素贝叶斯之前,首先需要对贝叶斯分类进行一下了解,贝叶斯分类通过预测一个对象属于某个类别的概率,通过比较不同类别概率的大小预测其最可能从属的类别,是基于贝叶斯定理而构成出来的。在处理大规模数据集时,贝叶斯分类器表现出较高的分类准确性。
贝叶斯分类在处理一个未知类型的样本X时,可以先算出X属于每一个类别Ci的概率 P(Ci|X),然后选择其中概率最大的类别。假设有两个特征变量x和y,并且存在两个分类类别C1和C2,结合贝叶斯定理:
- 如果
P(C1|x,y) > P(C2|x,y),说明在x和y发生的条件下,C1比C2发生的概率要大,那么它应该属于类别C1 - 反之如果
P(C1|x,y) < P(C2|x,y),那么它应该属于类别C2
而朴素贝叶斯模型(Naive Bayesian Model)作为一种强大的预测建模算法,它在贝叶斯定理的基础上进行了简化,假定了目标的特征属性之间相互独立,这也是它被形容为“朴素”的原因。在实际情况中如果属性之间存在关联,那么分类准确率会降低,不过对于解决绝大部分的复杂问题非常有效。
设在样本数据集D上,样本数据的特征属性集为
X
=
{
x
1
,
x
2
,
…
,
x
d
}
X=\{x_1,x_2,…,x_d\}
X={x1,x2,…,xd},类变量可被分为
Y
=
{
y
1
,
y
2
,
…
,
y
m
}
Y=\{y_1,y_2,…,y_m\}
Y={y1,y2,…,ym},即数据集D可以被分为
y
m
y_m
ym个类别。我们假设
x
1
,
x
2
,
…
,
x
d
x_1,x_2,…,x_d
x1,x2,…,xd相互独立,那么由贝叶斯定理可得:
P
(
y
i
∣
x
1
,
x
2
,
⋯
,
x
d
)
=
P
(
x
1
,
x
2
,
⋯
,
x
d
∣
y
i
)
⋅
P
(
y
i
)
P
(
x
1
,
x
2
,
⋯
,
x
d
)
=
P
(
x
1
∣
y
i
)
⋅
P
(
x
2
∣
y
i
)
⋯
P
(
x
d
∣
y
i
)
⋅
P
(
y
i
)
P
(
x
1
,
x
2
,
⋯
,
x
d
)
=
∏
i
=
1
d
P
(
x
j
∣
y
i
)
⋅
P
(
y
i
)
∏
j
=
1
d
P
(
x
j
)
\begin{array}{l} P(y_i|x_1,x_2,\cdots,x_d)= \frac{P(x_1,x_2,\cdots,x_d|y_i) \cdot P(y_i)}{P(x_1,x_2,\cdots,x_d)} \\ = \frac{P(x_1|y_i)\cdot P(x_2|y_i)\cdots P(x_d|y_i) \cdot P(y_i)}{P(x_1,x_2,\cdots,x_d)} \\ = \frac{\prod_{i=1}^{d}{P(x_j|y_i) \cdot P(y_i)}}{\prod_{j=1}^{d}{P(x_j)}} \\ \end{array}
P(yi∣x1,x2,⋯,xd)=P(x1,x2,⋯,xd)P(x1,x2,⋯,xd∣yi)⋅P(yi)=P(x1,x2,⋯,xd)P(x1∣yi)⋅P(x2∣yi)⋯P(xd∣yi)⋅P(yi)=∏j=1dP(xj)∏i=1dP(xj∣yi)⋅P(yi)
对于相同的测试样本,分母P(X)的大小是固定不变的,因此在比较后验概率时,我们可以只比较分子的大小即可。
在这里解释一下贝叶斯定理、贝叶斯分类和朴素贝叶斯之间的区别,贝叶斯定理作为理论基础,解决了概率论中的逆概率问题,在这个基础上人们设计出了贝叶斯分类器,而朴素贝叶斯是贝叶斯分类器中的一种,也是最简单和常用的分类器,可以使用下面的图来表示它们之间的关系:

在实际应用中,朴素贝叶斯有广泛的应用,在文本分类、垃圾邮件过滤、情感预测及钓鱼网站的检测方面都能够起到良好的效果。为了训练朴素贝叶斯模型,我们需要先在训练集的基础上对分类好的数据进行训练,计算出先验概率和每个属性的条件概率,计算完成后,概率模型就可以使用贝叶斯原理对新数据进行预测。
贝叶斯推断与人脑的工作机制很像,这也是它为什么能够成为机器学习的基础,大脑的决策过程就是先对事物进行主观判断,然后搜集新的信息,优化主观判断,如果新的信息符合这个主观判断,那就提高主观判断的可信度,如果不符合,就降低主观判断的可信度。
代码实现
在对理论有了基本的了解后,我们开始分析怎样将朴素贝叶斯应用于我们文本处理的情感词分析中。主要步骤如下:
- 对训练集和测试集完成文本分词,并通过主观判断标注所属的分类
- 对训练集进行训练,统计每个词汇出现在分类下的次数,计算每个类别在训练样本中的出现频率、及每个特征属性对每个类别的条件概率(即似然概率)
- 将训练好的模型应用于测试集的样本上,根据贝叶斯分类计算样本在每个分类下的概率大小
- 比较在各个分类情况下的概率大小,推测文本最可能属于的情感分类
使用流程图表示:
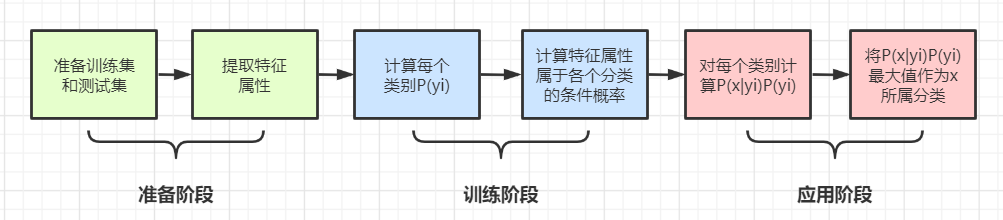
1、准备阶段
首先准备数据集,这里使用了对某酒店的评论数据,根据主观态度将其分为“好评”或“差评”这两类待分类项,对每行分词后的语句打好了情感标签,并且已经提前对完整语句完成了对分词,数据格式如下:

在每行的数据的头部,是添加的“好评”或“差评”标签,标签与分词采用tab分割,词语之间使用空格分割。按照比例,将数据集的80%作为训练集,剩余20%作为测试集,分配过程尽量保证随机原则。
2、训练阶段
在训练阶段,主要完成词频的统计工作。读取训练集,统计出每个词属于该分类下出现的次数,用于后续求解每个词出现在各个类别下的概率,即词汇与主观分类情感之间的关系:
private static void train(){
Map<String,Integer> parameters = new HashMap<>();
try(BufferedReader br = new BufferedReader(new FileReader(trainingData))){ //训练集数据
String sentence;
while(null!=(sentence=br.readLine())){
String[] content = sentence.split("\t| "); //以tab或空格分词
parameters.put(content[0],parameters.getOrDefault(content[0],0)+1);
for (int i = 1; i < content.length; i++) {
parameters.put(content[0]+"-"+content[i], parameters.getOrDefault(content[0]+"-"+content[i], 0)+1);
}
}
}catch (IOException e){
e.printStackTrace();
}
saveModel(parameters);
}
将训练好的模型保存到文件中,可以方便在下次使用时不用重复进行模型的训练:
private static void saveModel(Map<String,Integer> parameters){
try(BufferedWriter bw =new BufferedWriter(new FileWriter(modelFilePath))){
parameters.keySet().stream().forEach(key->{
try {
bw.append(key+"\t"+parameters.get(key)+"\r\n");
} catch (IOException e) {
e.printStackTrace();
}
});
bw.flush();
}catch (IOException e){
e.printStackTrace();
}
}
查看保存好的模型,数据的格式如下:
好评-免费送 3
差评-真烦 1
好评-礼品 3
差评-脏乱差 6
好评-解决 15
差评-挨宰 1
……
这里对训练的模型进行保存,所以如果后续有同样的分类任务时,可以直接在训练集的基础上进行计算,对于分类速度要求较高的任务,能够有效的提高计算的速度。
3、加载模型
加载训练好的模型:
private static HashMap<String, Integer> parameters = null; //用于存放模型
private static Map<String, Double> catagory=null;
private static String[] labels = {"好评", "差评", "总数","priorGood","priorBad"};
private static void loadModel() throws IOException {
parameters = new HashMap<>();
List<String> parameterData = Files.readAllLines(Paths.get(modelFilePath));
parameterData.stream().forEach(parameter -> {
String[] split = parameter.split("\t");
String key = split[0];
int value = Integer.parseInt(split[1]);
parameters.put(key, value);
});
calculateCatagory(); //分类
}
对词进行分类,统计出好评及差评的词频总数,并基于它们先计算得出先验概率:
//计算模型中类别的总数
public static void calculateCatagory() {
catagory = new HashMap<>();
double good = 0.0; //好评词频总数
double bad = 0.0; //差评的词频总数
double total; //总词频
for (String key : parameters.keySet()) {
Integer value = parameters.get(key);
if (key.contains("好评-")) {
good += value;
} else if (key.contains("差评-")) {
bad += value;
}
}
total = good + bad;
catagory.put(labels[0], good);
catagory.put(labels[1], bad);
catagory.put(labels[2], total);
catagory.put(labels[3],good/total); //好评先验概率
catagory.put(labels[4],bad/total); //差评先验概率
}
查看执行完后的统计值:
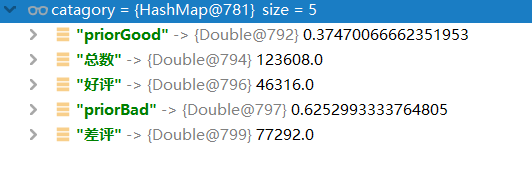
“好评”对应的词汇出现的总次数是46316个,“差评”对应的词汇出现的总次数是77292个,训练集词频总数为123608个,并可基于它们计算出它们的先验概率:
该文档属于某个类别的条件概率= 该类别的所有词条词频总数 / 所有词条的词频总数
4、测试阶段
测试阶段,加载我们提前准备好的测试集,对每一行分词后的评论语句进行主观情感的预测:
private static void predictAll() {
double accuracyCount = 0.;//准确个数
int amount = 0; //测试集数据总量
try (BufferedWriter bw = new BufferedWriter(new FileWriter(outputFilePath))) {
List<String> testData = Files.readAllLines(Paths.get(testFilePath)); //测试集数据
for (String instance : testData) {
String conclusion = instance.substring(0, instance.indexOf("\t")); //已经打好的标签
String sentence = instance.substring(instance.indexOf("\t") + 1);
String prediction = predict(sentence); //预测结果
bw.append(conclusion + " : " + prediction + "\r\n");
if (conclusion.equals(prediction)) {
accuracyCount += 1.;
}
amount += 1;
}
//计算准确率
System.out.println("accuracyCount: " + accuracyCount / amount);
} catch (Exception e) {
e.printStackTrace();
}
}
在测试中,调用下面的predict方法进行分类判断。在计算前,再来回顾一下上面的公式,在程序中进行简化运算:
P
(
y
i
∣
x
1
,
x
2
,
⋯
,
x
d
)
=
∏
i
=
1
d
P
(
x
j
∣
y
i
)
⋅
P
(
y
i
)
∏
j
=
1
d
P
(
x
j
)
P(y_i|x_1,x_2,\cdots,x_d)= \frac{\prod_{i=1}^{d}{P(x_j|y_i) \cdot P(y_i)}}{\prod_{j=1}^{d}{P(x_j)}}
P(yi∣x1,x2,⋯,xd)=∏j=1dP(xj)∏i=1dP(xj∣yi)⋅P(yi)
对于同一个预测样本,分母相同,所以我们可以只比较分子
∏
i
=
1
d
P
(
x
j
∣
y
i
)
⋅
P
(
y
i
)
\prod_{i=1}^{d}{P(x_j|y_i) \cdot P(y_i)}
∏i=1dP(xj∣yi)⋅P(yi) 的大小。对分子部分进行进一步简化,对于连乘预算,我们可以对其进行对数操作,变成各部分相加:
log
2
[
∏
i
=
1
d
P
(
x
j
∣
y
i
)
⋅
P
(
y
i
)
]
=
∑
i
=
1
d
log
2
P
(
x
j
∣
y
i
)
+
log
2
P
(
y
i
)
\log_2[\prod_{i=1}^{d}{P(x_j|y_i) \cdot P(y_i)}] = \sum_{i=1}^{d}{\log_2P(x_j|y_i)} + \log_2P(y_i)
log2[i=1∏dP(xj∣yi)⋅P(yi)]=i=1∑dlog2P(xj∣yi)+log2P(yi)
这样对于概率的大小比较,就可以简化为比较 先验概率和各个似然概率分别取对数后相加的和。先验概率我们在之前的步骤中已经计算完成并保存,所以这里只计算各词汇在分类条件下的似然概率即可。predict方法的实现如下:
private static String predict(String sentence) {
String[] features = sentence.split(" ");
String prediction;
//分别预测好评和差评
double good = likelihoodSum(labels[0], features) + Math.log(catagory.get(labels[3]));
double bad = likelihoodSum(labels[1], features) + Math.log(catagory.get(labels[4]));
return good >= bad?labels[0]:labels[1];
}
在其中调用likelihood方法计算似然概率的对数和:
//似然概率的计算
public static double likelihoodSum(String label, String[] features) {
double p = 0.0;
Double total = catagory.get(label) + 1;//分母平滑处理
for (String word : features) {
Integer count = parameters.getOrDefault(label + "-" + word, 0) + 1;//分子平滑处理
//计算在该类别的情况下是该词的概率,用该词的词频除以类别的总词频
p += Math.log(count / total);
}
return p;
}
在计算似然概率的方法中,如果出现在训练集中没有包括的词汇,那么会出现它的似然概率为0的情况,为了防止这种情况,对分子分母进行了分别加一的平滑操作。
最后在主函数中调用上面的步骤,最终如果计算出基于样本的好评概率大于等于差评概率,那么将它分类划入“好评”,反之划入“差评”类别,到此就完成了训练和测试的全过程:
public static void main(String[] args) throws IOException {
train();
loadModel();
predictAll();
}
执行全部代码,结果如下,可以看到获取了93.35%的准确率。
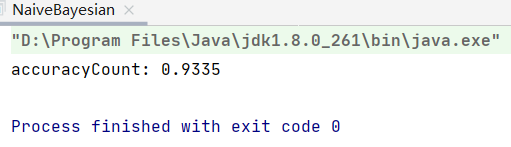
对比最后输出的文档中的标签与预测结果,可以看到,预测结果的准确度还是非常高的。
5、总结
在上面的例子中,还有一些可以进行改进的地方,例如可以在前期建立情感词库,在特征值提取的过程中只提取情感词,去除其余无用词汇(如介词等)对分类的影响,只选取关键的代表词作为特征提取,达到更高的分类效率。另外,可以在建立词库时,将测试集的情感词也放入词库,避免出现在某个分类条件下似然概率为零的情况,简化平滑步骤。
此外,朴素贝叶斯的分类对于追加训练集的情况有很好的应用,如果训练集不断的增加,可以在现有训练模型的基础上添加新的样本值、或对已有的样本值的属性进行修改,在此基础上,可以实现增量的模型修改。
如果文章对您有所帮助,欢迎关注公众号 码农参上
