1. Java虚拟机垃圾回收调优的背景
如果在持久化RDD的时候,持久化了大量的数据,那么Java虚拟机的垃圾回收就可能成为一个性能瓶颈。因为Java虚拟机会定期进行垃圾回收,此时就会追踪所有的java对象,并且在垃圾回收时,找到那些已经不在使用的对象,然后清理旧的对象,来给新的对象腾出内存空间。
垃圾回收的性能开销,是跟内存中的对象的数量,成正比的。所以,对于垃圾回收的性能问题,首先要做的就是,使用更高效的数据结构,比如array和string;其次就是在持久化rdd时,使用序列化的持久化级别,而且用Kryo序列化类库,这样,每个partition就只是一个对象——一个字节数组。
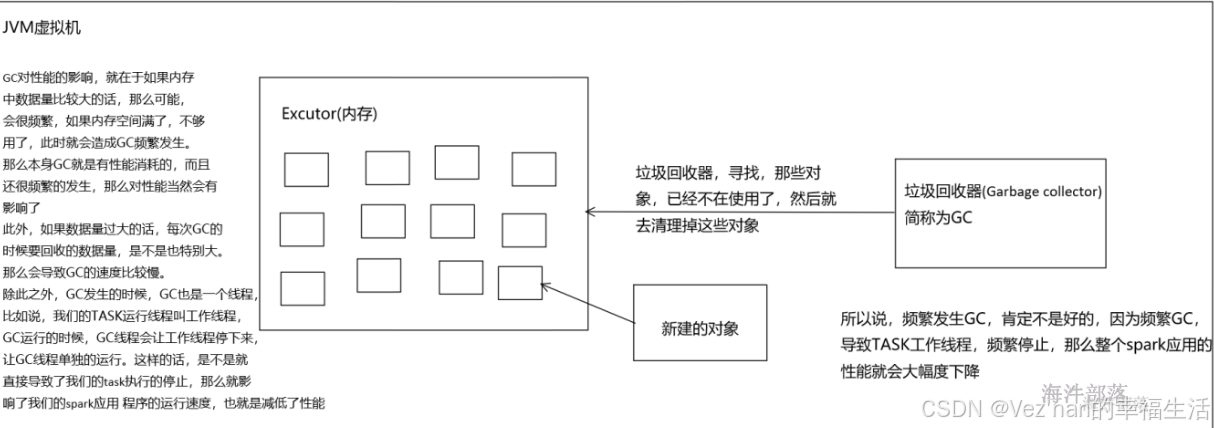
我们可以对垃圾回收进行监测,包括多久进行一次垃圾回收,以及每次垃圾回收耗费的时间。只要在spark-submit脚本中,增加一个配置即可,–conf “spark.executor.extraJavaOptions=-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps”。
但是要记住,这里虽然会打印出Java虚拟机的垃圾回收的相关信息,但是是输出到了worker上的日志中,而不是driver的日志中。
其实完全可以通过SparkUI(4040端口)来观察每个stage的垃圾回收的情况。
spark.executor.extraJavaOptions是配置executor的jvm参数
spark.driver.extraJavaOptions是配置driver的jvm参数
2. 垃圾回收机制
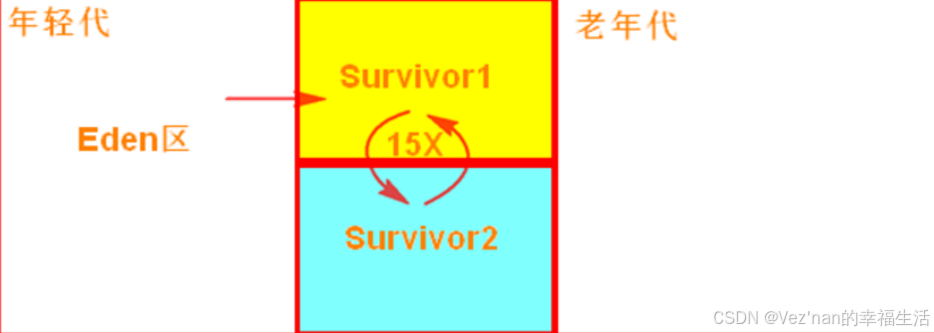
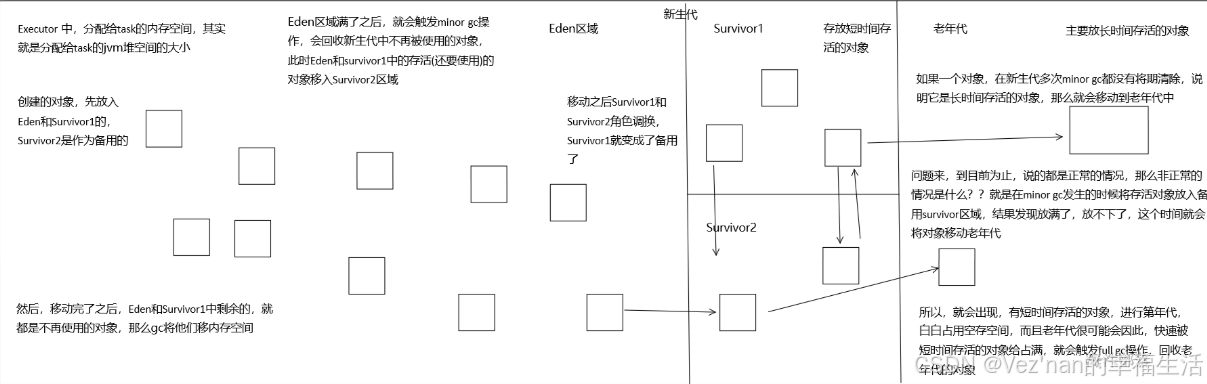
首先,Eden区域和Survivor1区域用于存放对象,Survivor2区域备用。创建的对象,首先放入Eden区域和Survivor1区域,如果Eden区域满了,那么就会触发一次Minor GC,进行年轻代的垃圾回收。Eden和Survivor1区域中存活的对象,会被移动到Survivor2区域中。然后Survivor1和Survivor2的角色调换,Survivor1变成了备用。
如果一个对象,在年轻代中,撑过了多次垃圾回收,都没有被回收掉,那么会被认为是长时间存活的,此时就会被移入老年代。此外,如果在将Eden和Survivor1中的存活对象,尝试放入Survivor2中时,发现Survivor2放满了,那么会直接放入老年代。此时就出现了,短时间存活的对象,进入老年代的问题。
如果老年代的空间满了,那么就会触发Full GC,进行老年代的垃圾回收操作。
3. 高级垃圾回收调优
Spark如果发现,在task执行期间,大量full gc发生了,那么说明,年轻代的Eden区域,给的空间不够大。此时可以执行一些操作来优化垃圾回收行为:
1)包括降低存储内存的比例(spark.memory.storageFraction),给年轻代更多的空间,来存放短时间存活的对象;
2)当大对象很多,但minorGC少,说明大对象都进入了老年代,此时给Eden区域分配更大的空间,使用-Xmn(年轻代的heap大小)即可,通常建议给Eden区域,预计大小的4/3;
3)如果使用的是HDFS文件,那么很好估计Eden区域大小,如果每个executor有4个task,然后每个hdfs压缩块解压缩后是该压缩块大小的3倍,每个hdfs块的大小是128M,那么Eden区域的预计大小就是:4 * 3 * 128MB,然后呢,再通过-Xmn参数,将Eden区域大小设置为4 * 3 * 128* 4/3。
4. 总结
根据经验来看,对于垃圾回收的调优,因为jvm的调优是非常复杂和敏感的。除非真的到了万不得已的地步,并且,自己本身又对jvm相关的技术很了解,那么此时进行Eden区域的调节是可以的。
一些高级的参数:
-XX:SurvivorRatio=4:
设置年轻代中Eden区与Survivor区的大小比值。如果值为4,那么就是Eden跟两个Survivor的比例是4:2,也就是说每个Survivor占据的年轻代的比例是1/6,所以,你其实也可以尝试调大Survivor区域的大小。
-XX:NewRatio=4:
调节新生代和老年代的比例。如果为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5。
其它设置内存大小的参数:
-Xms:为jvm启动时分配的内存,比如-Xms200m,表示分配200M。
-Xmx:为jvm运行过程中分配的最大内存,比如-Xms500m,表示jvm进程最多只能够占用500M内存。
-Xmn:年轻代的heap大小
-Xss:为jvm启动的每个线程分配的内存大小