欢迎大家订阅【Python从入门到精通】专栏,一起探索Python的无限可能!
前言
Python作为一种高效且易于学习的编程语言,提供了一系列强大的文件操作功能,使得用户能够轻松地实现文件的读取、写入和管理。本章将详细讲解文件的编码以及读取操作。
本篇文章参考:黑马程序员
一、文件的编码
思考:计算机只能识别0和1,那么我们丰富的文本文件是如何被计算机识别并存储在硬盘中呢?
答案:使用编码技术(密码本)将内容翻译成0和1存入。
编码技术,即翻译的规则,记录了内容和二进制间进行相互转换的逻辑。
计算机中存在多种编码格式,如UTF-8、GBK和Big5等。这些编码将文本内容转换为二进制数据,不同的编码会产生不同的二进制表示,因此在进行文件读写操作时,使用正确的编码非常重要。UTF-8作为一种全球通用的编码格式,因其兼容性和灵活性,已成为互联网和现代应用中最广泛采用的编码方式。

二、文件的读取
内存中存放的数据在计算机关机后就会消失。要长久保存数据,就要使用硬盘、光盘、U 盘等设备。为了便于数据的管理和检索,计算机引入了“文件”的概念。
一篇文章、一段视频、一个可执行程序,都可以被保存为一个文件,并赋予一个文件名。操作系统以文件为单位管理磁盘中的数据。一般来说,文件可分为文本文件、视频文件、音频文件、图像文件、可执行文件等多种类别。
在日常生活中,文件操作主要包括打开、关闭、读、写等操作。我们平常对文件的基本操作大概可以分为打开文件、读写文件、关闭文件这三个步骤 。

1.打开文件
open()打开函数:
在Python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件。
基本语法:
open(name,mode,encoding)
- name:指定了要打开的文件的完整路径或相对路径(可包含文件的目录、文件名以及文件扩展名)
- mode:设置打开文件的访问模式(只读、写入、追加等)
- encoding:编码格式(推荐使用UTF-8)

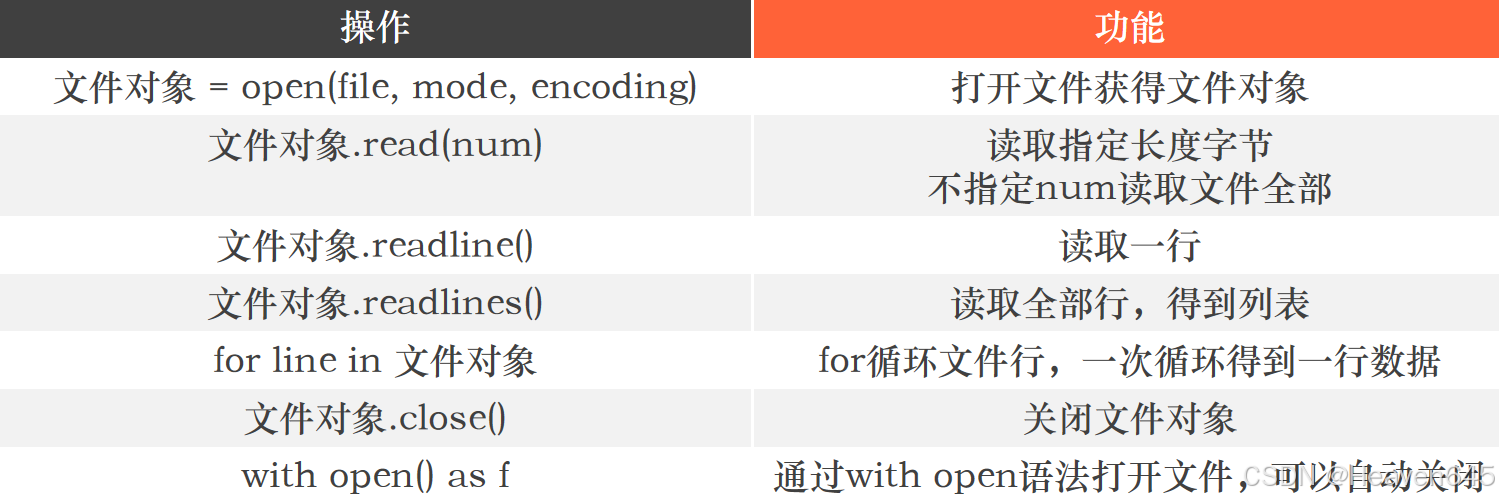
在电脑的D盘中新建一个test.txt的文本文件,并输入如下内容:
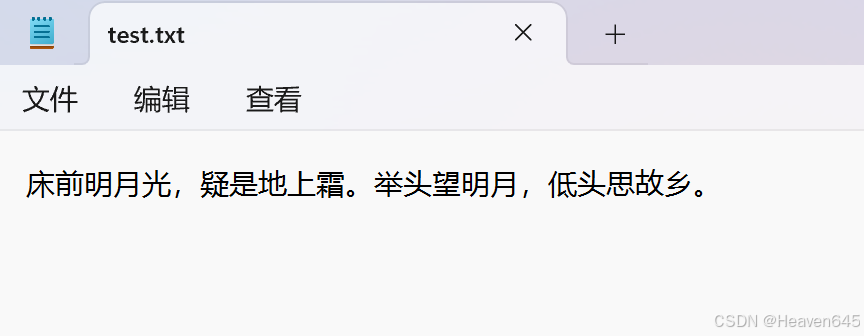
# "D:/test.txt" 是test.txt的文本文件的绝对路径
f=open("D:/test.txt","r",encoding="UTF-8")
print(type(f))
<class ‘_io.TextIOWrapper’>
注意:
- 此时的
f是open函数的文件对象,对象是Python中一种特殊的数据类型,拥有属性和方法,可以使用对象.属性或对象.方法对其进行访问 - Python中
open函数的参数签名通常为open(name, mode='r', buffering=-1, encoding=None,errors=None,newline=None, closefd=True, opener=None)
由于encoding参数不是open函数的第三个位置参数,所以不能使用位置参数传递,需用关键字参数直接指定,以避免潜在的混淆和错误 <class '_io.TextIOWrapper'>是 Python 中一个类的表示形式,表示当前对象是一个文本文件的包装器
2.读取文件
①read()方法:
基本语法:
文件对象.read(num)
num表示要从文件中读取的数据的长度(单位是字节)。
f=open("D:/test.txt","r",encoding="UTF-8")
# 读取文件——read()
print(f"读取10个字节的结果:{f.read(10)}")
输出结果:
读取10个字节的结果:床前明月光,疑是地上
如果没有传入num,那么就表示读取文件中所有的数据。
f=open("D:/test.txt","r",encoding="UTF-8")
# 读取文件——read()
print(f"读取全部内容的结果:{f.read()}")
输出结果:
读取全部内容的结果:床前明月光,疑是地上霜。举头望明月,低头思故乡。
连续调用read()方法来读取文件时,每次调用都会从上次读的位置继续往下读取。
f=open("D:/test.txt","r",encoding="UTF-8")
# 读取文件——read()
print(f"读取10个字节的结果:{f.read(10)}")
print(f"读取全部内容的结果:{f.read()}")
输出结果:
读取10个字节的结果:床前明月光,疑是地上
读取全部内容的结果:霜。举头望明月,低头思故乡。
【分析】
第一次调用read():
f.read(10) 文件指针会从文件的开头读取10个字节,并将文件指针移动到第11个字节处,即读取“床前明月光,疑是地上”。
第二次调用read():
它将从文件指针当前位置(即第11个字节)开始读取,直到文件结束。因此f.read() 会读取从当前文件指针位置到文件末尾的所有内容“霜。 举头望明月,低头思故乡。”
②readlines()方法:
基本语法:
文件对象.readlines()
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
在test.txt文本文件中输入如下内容:
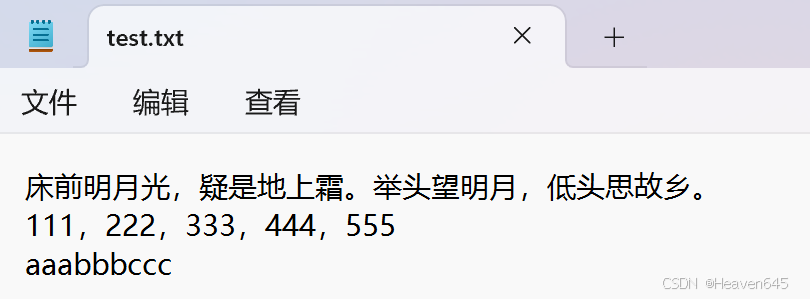
f=open("D:/test.txt","r",encoding="UTF-8")
# 读取文件——readlines():读取文件全部行,封装到列表中
lines=f.readlines()
print(f"lines对象的类型:{type(lines)}")
print(f"lines对象的内容:{lines}")
输出结果:
lines对象的类型:<class ‘list’>
lines对象的内容:[‘床前明月光,疑是地上霜。举头望明月,低头思故乡。\n’, ‘111,222,333,444,555\n’, ‘aaabbbccc’]
在文本文件中,不同的行是通过换行符\n 来分隔的。当你在文本编辑器中输入文本并按下 Enter 键时,实际上是在文本中插入了一个换行符。使用 readlines() 方法从文件中读取所有行时,每行的内容也包括结束时的换行符\n。
③readline()方法:
一次读取一行内容。
基本语法:
文件对象.readline()
在test.txt文本文件中输入如下内容:
# 读取文件——readline():一次读取一行内容
f=open("D:/test.txt","r",encoding="UTF-8")
line1=f.readline()
line2=f.readline()
print(f"第一行数据:{line1}")
print(f"第二行数据:{line2}")
输出结果:
第一行数据:床前明月光,疑是地上霜。举头望明月,低头思故乡。
第二行数据:111,222,333,444,555
使用 readline() 方法读取文件时,返回的每一行都包含行末的换行符\n。当你打印输出时,行末的换行符\n会导致内容之间多出一个空行。
为了避免这种情况,可以在打印时使用 strip() 方法从字符串中去除多余的换行符和其他空白字符。
f=open("D:/test.txt","r",encoding="UTF-8")
line1=f.readline()
line2=f.readline()
print(f"第一行数据:{line1.strip()}")
print(f"第二行数据:{line2.strip()}")
输出结果:
第一行数据:床前明月光,疑是地上霜。举头望明月,低头思故乡。
第二行数据:111,222,333,444,555
④for循环读取文件行:
在test.txt文本文件中输入如下内容:
f=open("D:/test.txt","r",encoding="UTF-8")
# for循坏读取文件行
# 每一个line临时变量,就记录了文件的一行数据
i=0
for line in f:
i+=1
print(f"第{i}行数据:{line.strip()}")
输出结果:
第1行数据:床前明月光,疑是地上霜。举头望明月,低头思故乡。
第2行数据:111,222,333,444,555
第3行数据:aaabbbccc
3.关闭文件
①close语法:
基本语法:
close() 关闭文件对象
f=open("D:/test.txt","r",encoding="UTF-8")
# 调用 time 模块中的 sleep 函数,用于让程序暂停执行一段时间
# 500000 是暂停的时间,单位是秒
time.sleep(500000)
运行该段代码,发现test.txt文本文件不能被删除或者重命名,并且显示test.txt文本文件正在被Python占用。
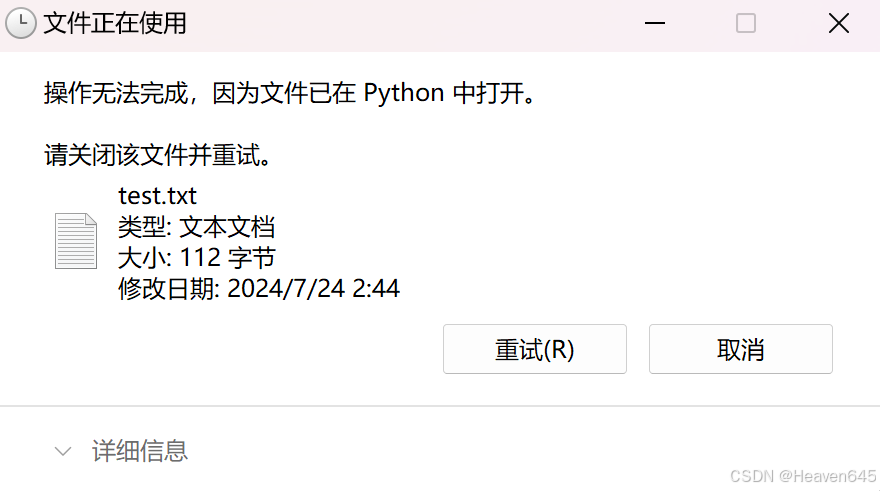
【分析】
在调用 time.sleep(500000) 之前,文件 test.txt 处于打开状态。由于文件在打开后没有被关闭,所以操作系统将该文件标记为“正在使用中”。此时操作系统会阻止对文件的删除操作,防止数据损坏以及不一致性。因此,无法删除 test.txt 文件,系统会提示该文件正在被 Python 占用。
f=open("D:/test.txt","r",encoding="UTF-8")
# 文件的关闭
f.close()
time.sleep(500000)
运行后,可以正常删除test.txt文本文件。
【分析】
通过调用 f.close(),显式地关闭了文件,释放了文件的资源,并通知操作系统该文件不再被程序占用。由于文件已经被关闭,操作系统不再将其标记为“正在使用中”,因此可以正常删除 test.txt 文件。
f = open("D:/test.txt", "r", encoding="UTF-8")
f.close()
time.sleep(500000)
运行该段代码,发现test.txt文本文件不能被删除或者重命名,并且显示test.txt文本文件正在被Python占用。
【分析】
time.sleep(500000)使程序暂停大约139小时(500000秒)。在这段时间内文本文件 test.txt 会处于打开状态。只有在 time.sleep(500000) 完成后,程序才会继续执行并调用 f.close(),此时文件才会被关闭。
②with open语法:
通过在with open的语句块中对文件进行操作,可以在操作完成后自动关闭close文件,避免遗忘掉close方法。
基本语法:
with open(“文件路径”,“模式”) as 文件对象:
# 在这里进行文件操作
…
#文件在这里自动关闭
#with open语法操作文件:执行完后自动将文件关闭
with open("D:/test.txt","r",encoding="UTF-8") as f:
for line in f:
print(f"每一行数据:{line}")
time.sleep(500000)
运行后,可以正常删除test.txt文本文件。
【例题】
通过Windows的文本编辑器软件,将如下内容复制并保存到test.txt文本文件中,文件可以存储在任意位置。通过文件读取操作读取此文件,统计itheima单词出现的次数。
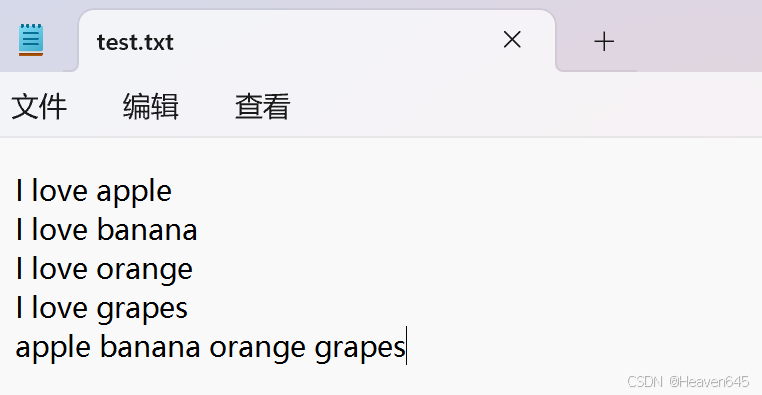
f=open("D:/test.txt","r",encoding="UTF-8")
# 方式一:读取全部内容,通过字符串count方法统计apple单词数量
content=f.read()
num=content.count("apple")
print(f"apple出现了{num}次")
# 关闭文件
f.close()
输出结果:
apple出现了2次
f=open("D:/test.txt","r",encoding="UTF-8")
# 方式二:一行行地读取内容
count=0 # 使用count变量来累计apple出现的次数
for line in f:
# 通过strip方法去除换行符
line=line.strip()
# 通过split方法按空格切分
words=line.split(" ")
for word in words:
if word=="apple":
# 进行数量的累加
count+=1
print(f"apple出现了{count}次")
# 关闭文件
f.close()
输出结果:
apple出现了2次