缓存(Cache)技术在互联网系统的开发过程中应用非常广泛,当系统中出现性能瓶颈时,很多场景都可以使用缓存技术来重构业务处理流程,从而获取性能的提升。缓存的实现方法可以有很多变化,但业界也存在一些主流的设计思想和工程实践。今天,我们就将讨论其中具有代表性的多级缓存技术。
那么,什么是多级缓存呢?接下来,让我们先从多级缓存的基本结构开始说起。
多级缓存的基本结构
缓存的作用在于减少数据的访问时间和计算时间,具体表现上,通常是把来自持久化或其它外部系统的数据转变为一系列可以直接从内存获取的数据结构的过程。在学习互联网系统中的主流架构时,我们经常会看到类似如下所示的架构图。

在上图中,在Nginx、Redis、Tomcat等组件中都可以存在缓存机制,我们无意对所有缓存机制进行展开,今天关注的是上图中应用程序层的缓存。这里的应用程序泛指诸如Tomcat等应用程序容器,也包括像Spring、Dubbo、Mybatis等的开源框架,以及我们自己开发的业务系统。
如果我们分析应用层所具备的缓存实现技术,都可以抽象出通用的缓存结构,下图就是一种常见的缓存的表现形式。

在上图中,数据表示为Key-Value对,然后对Key施加一定的算法获取其HashCode,再根据该HashCode所对应的索引找到Value在内存中的位置并获取该Value值。
各类缓存实现工具,尽管其支持的数据结构以及数据在内存中的分配和查找方式有所不同,但基本结构模型都与上图类似,从该图中,我们也认识到缓存本质上是一种时间换空间的做法。
现在,我们已经明确了单级缓存的基本结构,让我们对上图进行扩展和延伸,把讨论范围扩大到多级缓存。如果对应用程序层的缓存进行进一步分析,我们发现同样存在分级模式,这种分级模式通常包括两级,即一级缓存和二级缓存。
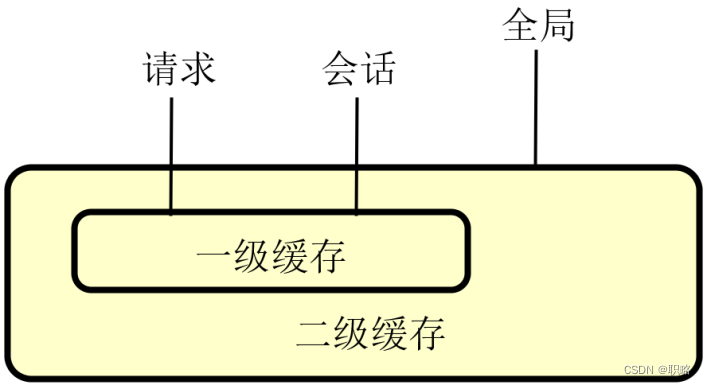
简单讲,所谓的一级缓存就是指一次请求(Request)级别或者说会话(Session)级别的缓存。针对每次查询操作,一级缓存会把数据放在会话中,如果再次进行查询的话,就会直接从会话的缓存中获取数据,而不会去查询数据库。
而二级缓存的范围则更大一点,它是一种全局作用域的缓存。只要应用程序处于运行状态,那么所有请求和会话都可以使用。
多级缓存代表着一种架构设计的方法论,在多款开源框架中都有对应的事项方案。接下来,我们将基于Mybatis框架来分析它的一级缓存和二级缓存。
Mybatis多级缓存解析
在Mybatis中,缓存对应的接口是Cache,同时还提供了针对该接口的众多实现类。
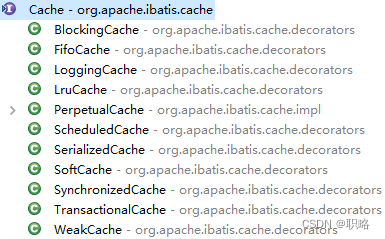
上图中,除了PerpetualCache类之外,其他的实现类都是Cache的装饰器。PerpetualCache是Mybatis中默认使用的缓存类型,其暴露的访问入口如下所示:
public class PerpetualCache {
getId()//获取缓存Id
getSize()//获取缓存对象数量
putObject()//添加缓存对象
getObject()//获取缓存对象
removeObject()//移除缓存对象
clear()//清空缓存
}
在PerpetualCache的内部,保存缓存数据的只是一个HashMap,因此是一种典型的基于内存的缓存实现方案。这里的几个方法也比较简单,所有对缓存的操作实际上就是对HashMap的操作。
在Mybatis中,所有的一级缓存和二级缓存的背后用到的都是这个PerpetualCache。让我们一起来看一下。
Mybatis一级缓存解析
Mybatis中存在一个配置项,用于指定一级缓存默认开启的级别,如下所示。代码1。
<setting name="localCacheScope" value="SESSION"/>
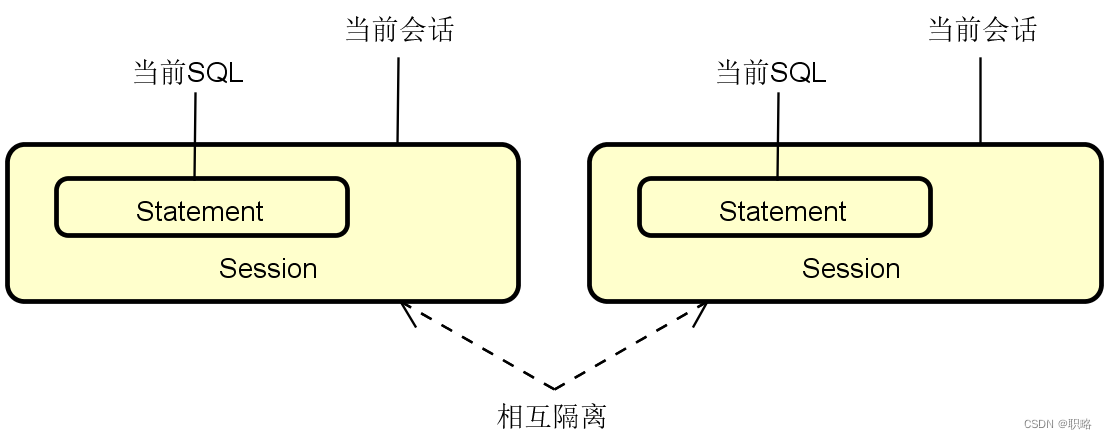
在Mybatis中一级缓存存在两个级别,即SESSION级和STATEMENT级,默认采用的是SESSION。如果将其设置为STATEMENT级,可以理解为缓存只对当前SQL语句有效,SESSION当中的缓存每次查询之后就会被清空。而如果是SESSION级,则查询结果一直会位于该Session中。但是,要注意由于一级缓存是独立存在于每个Session内部的,因此,如果我们创建了不同的Session,那么他们之间会使用不同的缓存。例如,完全一样的一个操作,如果在两个不同的Session中进行执行,那就意味着存在两份一样的缓存数据,但分别位于两个Session中,彼此之间不会共享。
在Mybatis中,存在一个如下所示的queryFromDatabase()方法,该方法负责从数据库中查询数据,这个过程就用到了一级缓存。代码2。
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
//从缓存中移除对象
localCache.removeObject(key);
}
//添加对象到缓存中
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
可以看到,一旦完成数据库查询,会将从数据库中获取的数据保存在localCache中。通过查看定义,我们发现这个localCache就是一个PerpetualCache对象。
如果我们查看针对SQL的update()、commit()和close()等方法,会发现这些方法在执行完毕之后都会清空一级缓存。
通过前面的介绍,我们可以看到Mybatis的一级缓存是一个粗粒度的缓存,设计的比较简单。本质上它就是一个HashMap,Mybatis没有对HashMap的大小进行管理,也没有缓存更新和过期的概念。这是因为一级缓存的生命周期很短,不会存活多长时间。
Mybatis二级缓存解析
接下来让我们继续研究Mybatis中的另一种缓存表现形式,即二级缓存。相较一级缓存,Mybatis的二级缓存使用方法有所不同,内部的实现逻辑也更为复杂。
与一级缓存不同,Mybatis的二级缓存默认是不启用的,如果需要启动,则应该在配置文件中添加如下配置项。代码3。
<setting name="cacheEnabled" value="true"/>
上述配置方法是全局级别的,我们也可以在特定的查询级别使用二级缓存。Mybatis专门提供了一个<cache/>配置节点用于实现这一目标,这个配置节点可以定义缓存回收策略、最多缓存多少个对象等参数。
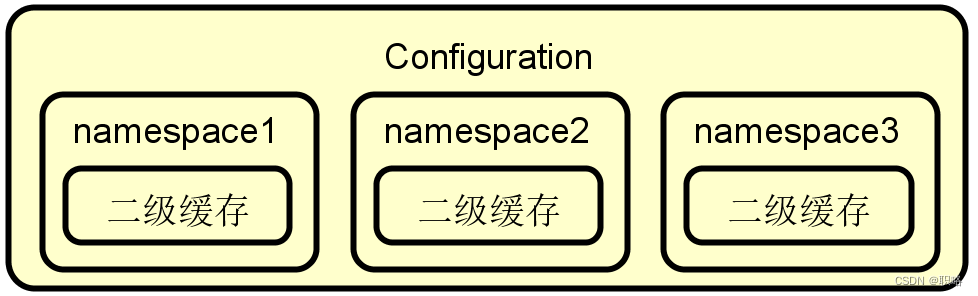
下图展示了Mybatis中二级缓存的生效范围。请注意,二级缓存是与命名空间(namespace)强关联的,即如果在不同的命名空间下存在相同的查询SQL,这两者之间也是不共享缓存数据的。我们知道在Mybatis中,Configuration管理者所有的配置信息,所以所有的二级缓存相当于全部位于Configuration之内。
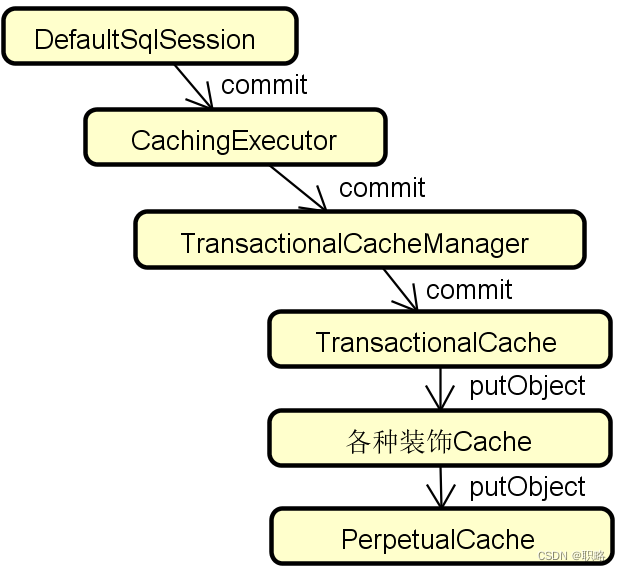
首先明确一点,在Mybatis中,如果开启了二级缓存,不管配置的是哪种类型执行过程,都会将该这个执行过程嵌套到CachingExecutor类中。
然后,我们注意到CachingExecutor中持有一个新的类TransactionalCacheManager。当我们执行查询方法时,我们首先会通过TransactionalCacheManager获取到Cache对象,如果获取到的Cache对象为空,那么就执行查询操作,并把查询得到的放入TransactionalCacheManager中。
那么这里的Cache对象究竟是什么呢?实际上它是一个TransactionalCache对象。该对象中使用了Mybatis中的各种装饰器Cache,并最终使用PerpetualCache完成具体数据的缓存操作。
至此,整个二级缓存的使用过程得到了详细的解释,以SQL的commit()操作流程为例,整个过程的处理流程如下图所示。
本讲内容系统分析了日常开发过程中都会使用到的缓存机制,我们讨论了作为一个单级缓存应该具备的基本结构,也分析了应用程序级别常用的多级缓存机制。多级缓存设计思想在大量开源框架中都得到了应用,本讲我们基于Mybatis这款主流的ORM框架分析了Mybatis的一级缓存和二级缓存,并给出了对应的实现过程。尽管Mybatis所提供的二级缓存机制面向的是数据库访问领域,但我们可以借鉴背后的设计思想和方法,并应用到日常开发中。